







1、Deep Residual Learning for Image Recognition
简介:
残差网络ResNet是近年来最有效的base model之一。过去,叠加神经网络层数会导致网络退化(degradation)的问题,当层数达到30层之后,精度不升反降。可以从作者的实验数据来感受这一现象:

这不是过拟合,因为训练集误差也很大。这也不是梯度消失和梯度爆炸,因为使用了BN,这两个问题已经很大程度上解决了。
这是网络是否容易被优化的问题。举个例子,假如我们在已经训练好的VGG16网络上面再额外添加很多层,然后把这些层的权重都设为1,也就是让后面的每一层都相当于一次恒等变换。那么新的网络的结果应该和VGG16完全一样。这意味着似乎更深层次的网络至少应该达到和浅层网络一样的效果。但事实并非如此,如果我们从头开始训练,后面这些层根本无法学到恒等变换,也就是说,恒等变换对于神经网络来说并不是一个易学的特征。
ResNet用学习残差解决了这个问题。既然网络无法直接学习到恒等变换,那就把每一层的输出改造为恒等变换加残差的形式。网络只需要学习残差,当残差为0时,这一层就成为恒等变换。相对于恒等变换,0变换显然更容易学习(大概是因为0变换相当于什么特征都没有)。作者在文中也提到了VLAD的设计理念,用到与聚类中心的残差替代原始特征,可以使特征的表述更明显。ResNet的思想与之异曲同工。于是,ResNet每一层长这个样子:
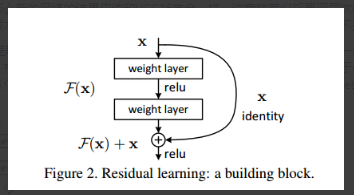
与原本的网络相比,恒等变换的shortcut连接不带来额外的参数,只是简单叠加到卷积层的输出上。因此,ResNet的计算量与同深度的其它网络相比并没有显著增加(只是多了个element-wise加法)。
这样,ResNet可以构造出非常深的神经网络,而且不会发生退化现象。以上就是ResNet的核心思想。
具体实现方面,有一些细节值得关注。
首先,当残差块的输入输出维度不一致时,恒等变换就行不通了。文中尝试了三种做法,第一种是用0填充缺失的维度,第二种是额外做一次线性变换(其实就是1×1卷积),第三种是在所有情况下(包括输入输出维度一致时)都额外做一次线性变换。实验证明,三略好于二略好于一。但第三种做法会导致参数量和计算量多出大约一倍,因此作者建议使用第二种方式。
其次,对于更深层次的神经网络,作者设计了一种三层的称为bottleneck架构的残差块,如下图所示:

之所以叫bottleneck,是因为中间层的输入输出通道数都为64,而上下层的输入或者输出通道数为256。作者意图通过1×1卷积降低feature map维度,以减小3×3卷积的计算量,最后再使用1×1卷积恢复输入的feature map维度。
最后,作者在CIFAR-10数据集上评估了每一层的响应的标准差,如下图所示:

这张图表明了网络越深,每一层学到的特征越接近于0,很符合残差网络的设计理念。
ResNet在各大公开数据集上的评估结果这里就不贴了,在当年自然是横扫所有榜单。之后的各类网络,无论是识别、检测、分割等不同任务,还是AlphaGo,抑或是MobileNet等轻量级网络,都或多多少借鉴了ResNet的设计思路。
2、Dynamic Routing Between Capsules
简介:
在卷积神经网络已经如此流行的今天,Hinton仍然极富创造力地提出了全新的网络架构——Capsule。
传统神经网络对于输入图像的旋转、变形和仿射变换是无能为力的,除非训练集中做了充分的数据增强。之所以传统神经网络不行,是因为feature map中的每个元素都是标量,各个元素之间是分离的,无法表征特征的方向信息。而在Capsule中,每层的任何一个特征都用向量表示,向量的方向表示该特征的属性,向量的长度表示该特征存在的概率。以MNIST手写体数字识别为例,最后一层共有10个Capsule,每个Capsule的长度代表输入图片中是否有对应的数字,而每个Capsule的方向则相当于对该数字的一个编码。在Hinton的论文中,输出层的Capsule向量维度为16,这16个数在不同角度上刻画了手写体数字的特征,比如某一维刻画数字的粗细,某一维刻画笔势的顿挫等。下图展示了一层Capsule的计算过程:
u为上一层Capsule的输出向量,通过变换矩阵W传递给下一层。下一层的输入s是所有上一层输出u经过W变换,再经过c加权后得到的。这两步代替了传统神经网络的线性变换。接下来,squashing函数替代了传统神经网络的激活函数,并将输出v控制到0~1之间。初看上去,Capsule的架构似乎和全连接神经网络没什么区别,但Hinton引入了动态路由的概念。u虽然连接到了所有输出v,但是权重c的动态调整使得某些线路的权重降得很低,某些线路的权重提得很高,使得网络具有了更为高级的复杂度,能够从所有特征中选择其需要的特征,摒弃无用的特征。在训练阶段,反向传播负责更新除c外的所有其它参数。而c则通过动态路由的方式更新,具体做法为,提高与输出向量内积最大的输入分支的权重,因为内积大说明该输入向量对输出有积极作用。
基于上述Capsule工作原理,Hinton构造了一个简单的CapsNet:
该网络共三层。第一层是普通的卷积层。第二层是Capsule层,由第一层的输出卷积得到。第三层也是Capsule层,由第二层通过前述计算规则得出。第三层的输出为10个Capsule向量,损失函数为:
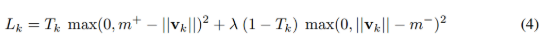
这是第k个输出Capsule的损失,总损失为10个Capsule的损失之和。
此外
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4136
4136











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









