







分享嘉宾:王志勇 贝壳 架构师
编辑整理:戴稚晖 陆金所
出品平台:DataFunTalk
导读:贝壳从房产领域的产业互联网角度介绍智能广告投放的挑战、实践和思考。房产互联网是典型的高价值、长周期转化领域,本次分享重点介绍了贝壳CVR转化率预估模型在延时反馈问题上的实战经验;贝壳设计了一套实验机制评估RTA策略算法带来的增量价值,通过优化出价系数预估模型,转化率相对直投提升10%+,产业互联网广告主可以借鉴相关经验。
本文将围绕以下三个方面展开:
贝壳广告投放业务介绍和痛点分析
智能投放关键技术
智能预算分配关键技术
01
贝壳效果广告
1. 贝壳广告业务背景介绍
效果广告的目标是最大化业务目标效果,如月活MAU、总销量GMV、线上成交转化率。
贝壳构建了全域智能采买平台(泛DSP平台),从流量平台如字节跳动巨量引擎、腾讯广点通等接入流量,DSP业务方向涉及拉新和拉活,核心功能包括智能出价、增量价值预估、优化用户定向(用户分层和用户偏好分析)、RTA策略优化,通过数据采买和媒体合作方式实现数据共享来提升广告效果。
贝壳也有媒体直投业务,建设的灵犀系统提供了一系列直投工具,包括DPA、oCPX归因、数据回传等。DPA是Dynamic Products Ads简称,动态千人千面的商品广告,主要原理是基于用户之前与商品的互动行为,针对该用户展开该商品的再营销。oCPX,包括oCPC、oCPM等,以优化广告主的转化目标为目的,通过预估转化率来调整出价,为广告主选择转化率更高的流量,帮助广告主控制成本。oCPC出价模式主要分两个阶段,第一阶段为CPC投放-数据积累阶段;第二阶段为智能投放,当转化量积累到一定数值时系统根据转化率动态调整出价,控制转化成本接近目标成本。
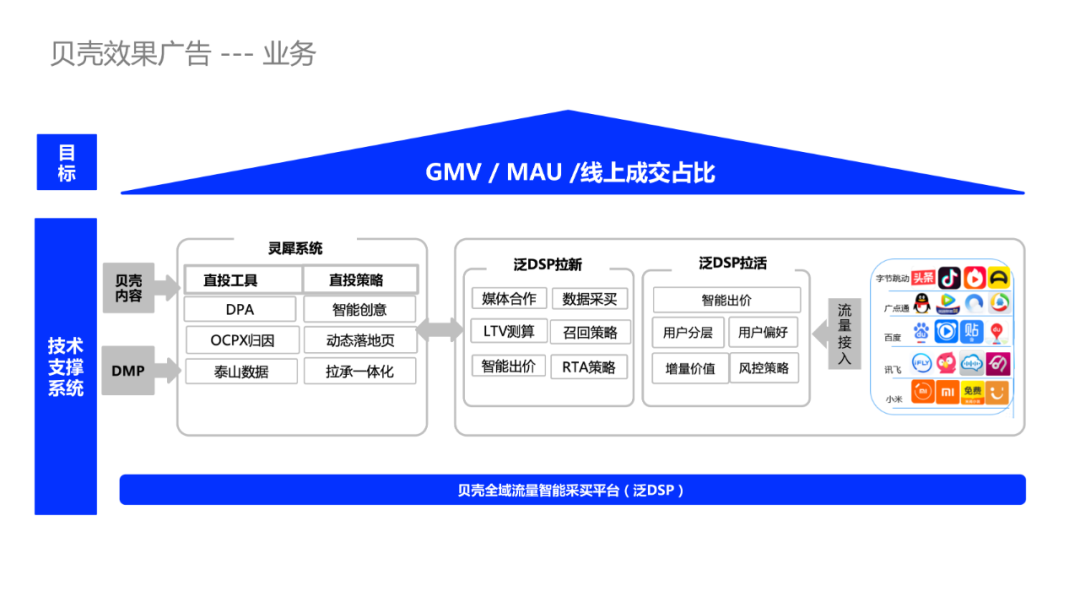
贝壳广告业务的核心背景特点如下:
复购比例小:低频高价值,在高议价空间上提升算法带来的收益也是很大的。
转化周期长:开始看房到成交要历经数月以上,和一般消费互联网(电商和资讯内容)有很大区别,后者决策和转化周期短。
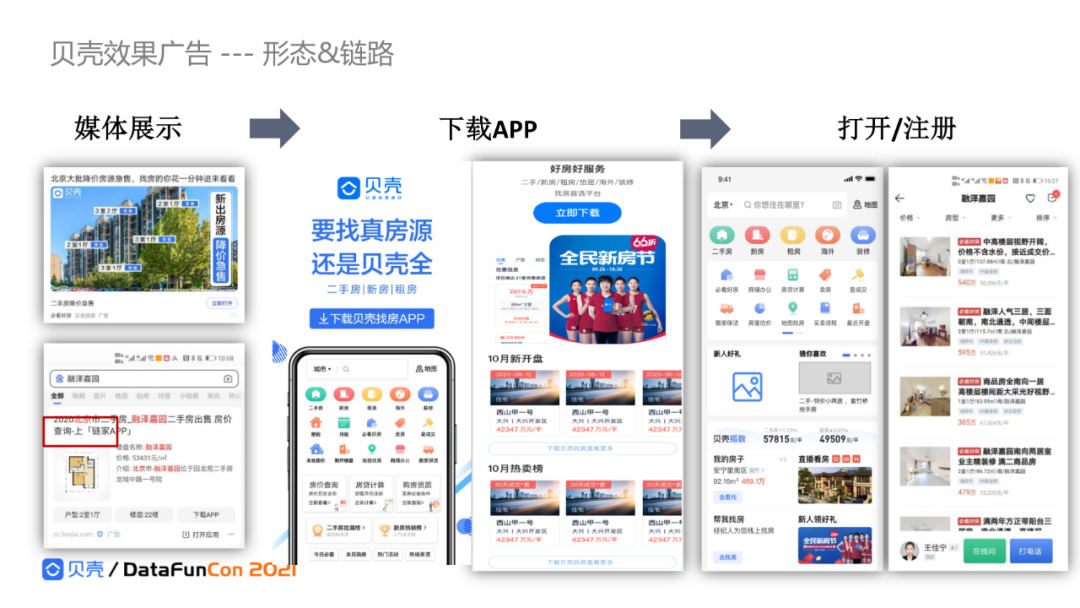
2. 贝壳效果广告--形态和链路
下图是贝壳广告的一个事例,通过各个媒体,包括信息流、应用商店、搜索引擎优化SEM等方式投放贝壳的广告。在拉新过程中,会涉及注册App的过程;在拉活时,通过广告唤起贝壳app。
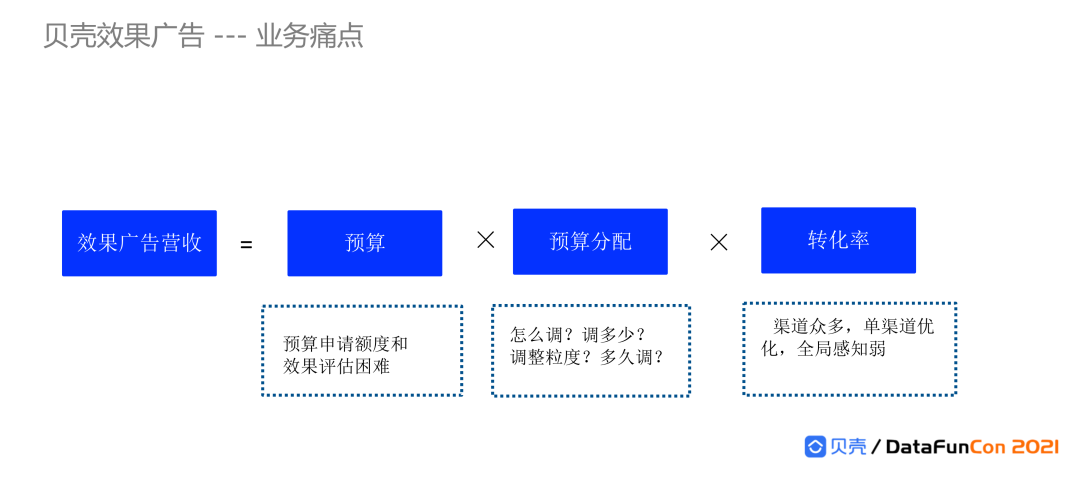
3. 贝壳效果广告--业务痛点
广告效果营收可分解为三大重要因子,一是广告预算额度,二是预算分配,三是转化率。三大部分各自的特点和痛点说明如下:
核心重点关注的是转化率指标:广告渠道众多分散,渠道之间差异很大,如果仅仅对单渠道进行优化,达不到全局优化的效果,需要整体上进行优化。
预算分配问题:分配涉及很多维度,包括渠道维度、计划维度、推广单元维度,还需要考虑分配的调整频次和粒度。相对传统凭借市场经验判断的方式,智能自动化计算分配有很大提升空间。
预算申请预估和效果评估:业务运营会从获客成本和新客数量等角度评估,确认预算申请额度,评估广告投放带来的效果收益。除了获客数量,线上广告投放需要能为经纪人产生商机,为经纪人派发商机,所以需要对商机的成本、商机数量、商机转化带来的收入提前进行评估和预测,确保投放ROI达到业务目标。
02
智能投放关键技术
1. 智能投放流量漏斗和核心技术概览
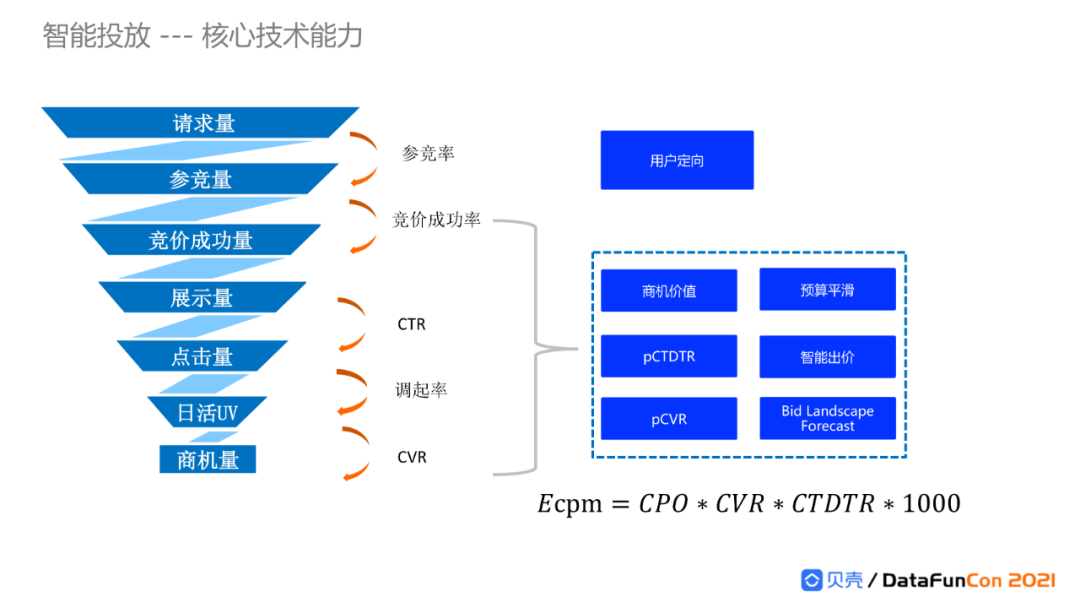
我们先来看智能投放的7层流量漏斗。
第1层是来自流量媒体的请求,在用户访问媒体时,将对应的请求发给DSP。第2层是参与竞价,DSP需要评估是否参与竞价以及出价价格。后面5层分别是竞价成功、曝光展示、点击、调起app、成交转化。这些环节的转化率都需要提前预估。
这7层漏斗涉及哪些技术呢?
参竞率涉及到的关键技术是用户定向,例如,对于城市定向,哪些城市的特定画像人群会对贝壳这个平台产生大的增量价值。
参与竞价需要对各层转化率进行预估。考虑到漏斗各个环节之间不是完全独立的,来自不同渠道的流量漏斗转化也不一样,高点击率的客户调起率可能很低,高调起率的客户可能商机率和价值很低,所以为每层转化率单独训练模型学习效果不够好,在建模的时候采取多任务优化联合建模。智能出价预估公式:eCPM=CPO*CVR*CTDTR*1000,涉及pCTDTR预估(点击率和调起率联合预估)、pCVR预估(登录成交转化率预估)。其中,pCTDTR通过采取MMoE(Google团队发表的Multi-gate Mixture-of-Experts)多任务学习模型进行联合优化建模;pCVR预估采用DFM(Delayed feedback model)模型。
除了转化率预估,贝壳还设计了预算平滑机制,对每天的广告投放预算进行有效的流量预估和控制。
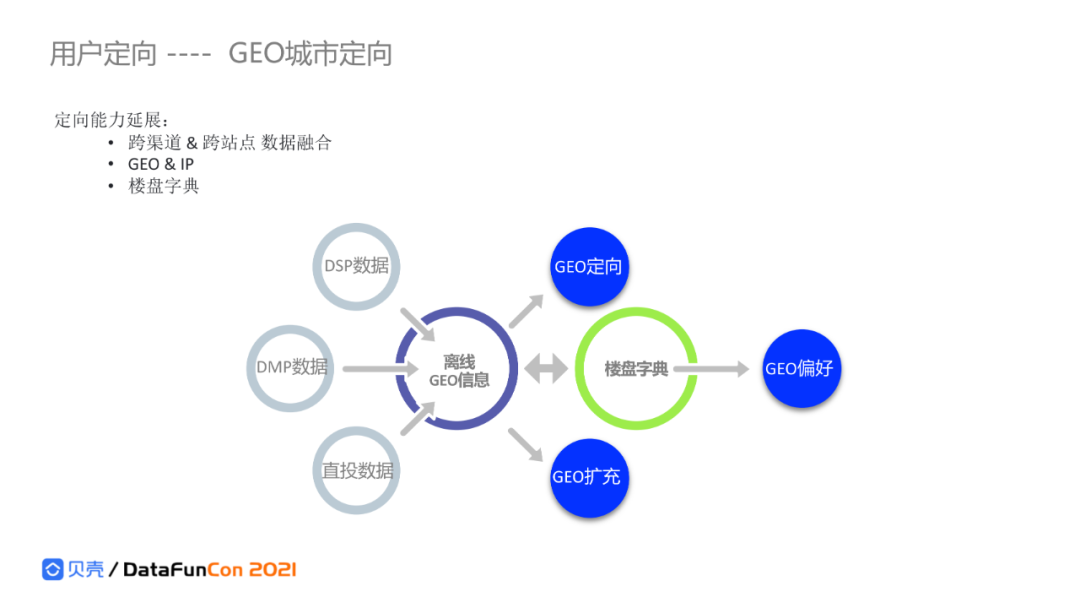
2. 用户定向之GEO城市定向
为了扩展用户定向能力,贝壳将内外部数据、跨渠道跨站点进行数据融合,构建更全面的用户画像。
这里特别分享下地理位置定向。有很多用户在媒体请求层,未打开位置信息,如果仅仅采用ip进行位置定位,不利用跨渠道数据融合,准确率不高。贝壳房产业务有丰富的楼宇字典数据,结合直投、DMP、DSP的离线GEO信息,分析用户的地理位置偏好,进行更准确的人群和位置定位。
3. 商机转化率-反馈延时建模
互联网电商的转化周期很短,但转化周期长在贝壳是个很大的特点,对模型预估也是个大的挑战。需要对模型的新鲜度和准确率做个平衡,模型每天更新,但还在考虑中的潜在用户没有完成转化,会导致建模的label没有更新,这样预估是偏低的。这种延时label更新的问题在推荐场景影响相对小一些,因为推荐系统核心关注的是排序问题,但这个问题对广告效果影响是非常大的,因为广告预估不仅关注排序而且关注转化率的真实值,预估结果会直接影响出价。
下图右侧模型是一个反馈延时模型(dfm),把转化率和转化周期预测进行联合训练,在预测转化率的同时,模拟转化率在时间上的分布。假设转化周期分布是指数分布,通过设置不同的归因窗口进行尝试,最后选择一个合适的归因窗口。
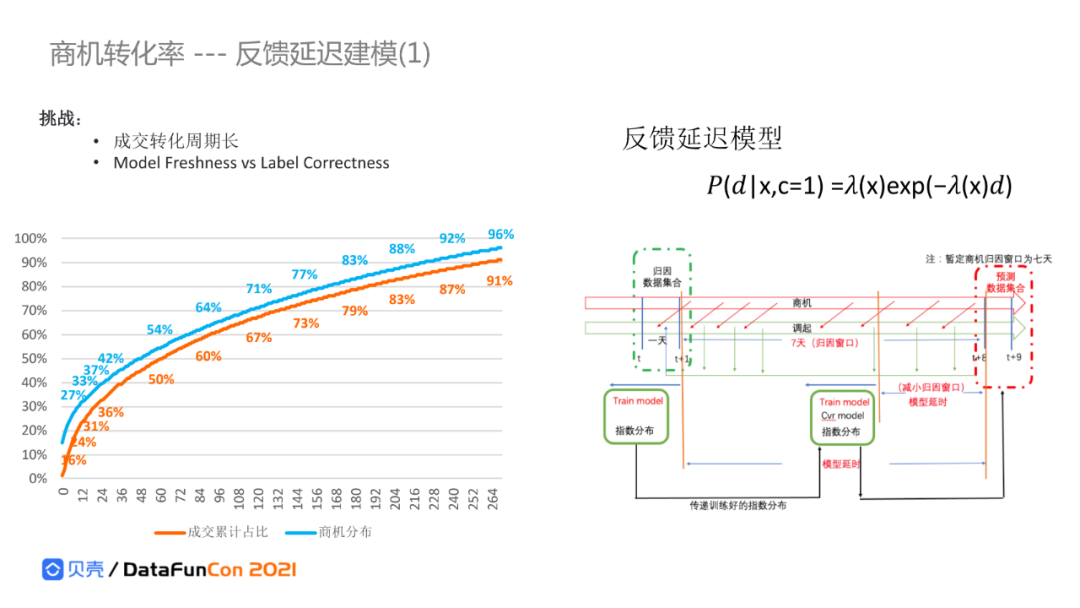
转化率的衰减分布虽然和指数分布有很大的相关性,但在实际转化中还是有差异的。因此我们做了一些其他尝试,从时间方面去建模,减少观测样本和真实样本的偏差,实时更新我们的真实样本反馈到训练样本中。采取采样纠偏的方式,类似于热点机制进行校准,这类技术对样本量规模要求很大,而且要能快速实时回传正样本。在贝壳,这种方式不太实用,原因是用户交互的数据量不够大,反馈也不够实时。
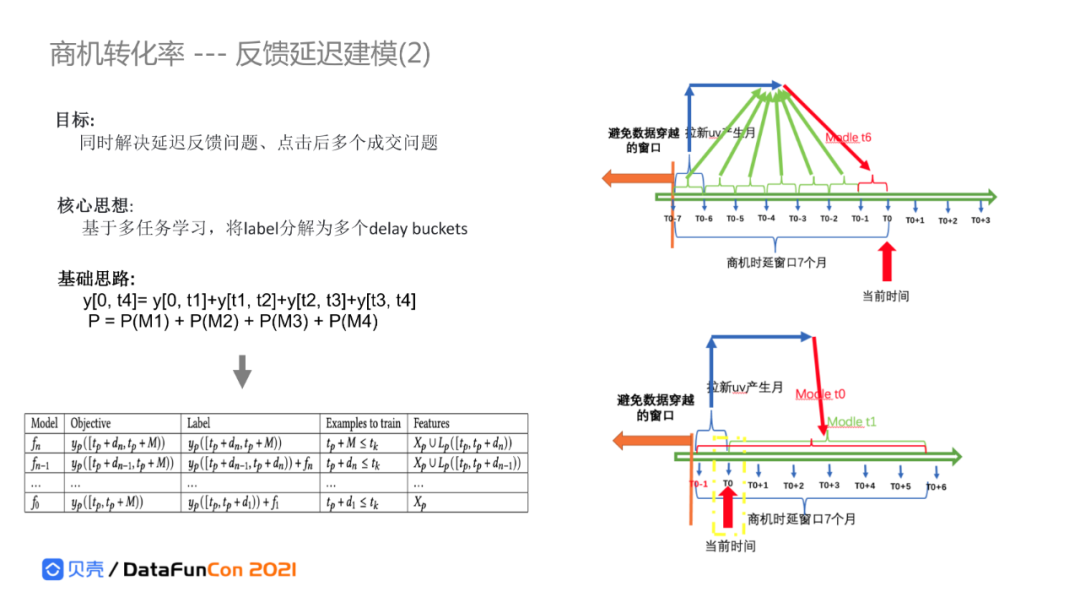
贝壳参考了谷歌在延时反馈、一个点击多次成交转化场景上的应用算法,核心是在时间维度上,把label拆成了不同的延时桶(比如,M个),不同天的转化对应不同的桶,根据未完全转化的样本对应延时桶,依次训练可以确定样本label的模型;然后将该模型的预测值和后续模型的已转化label 集成,作为后续模型的label训练,使后续模型能利用更新鲜的样本数据(延时从M天降低到1天)。
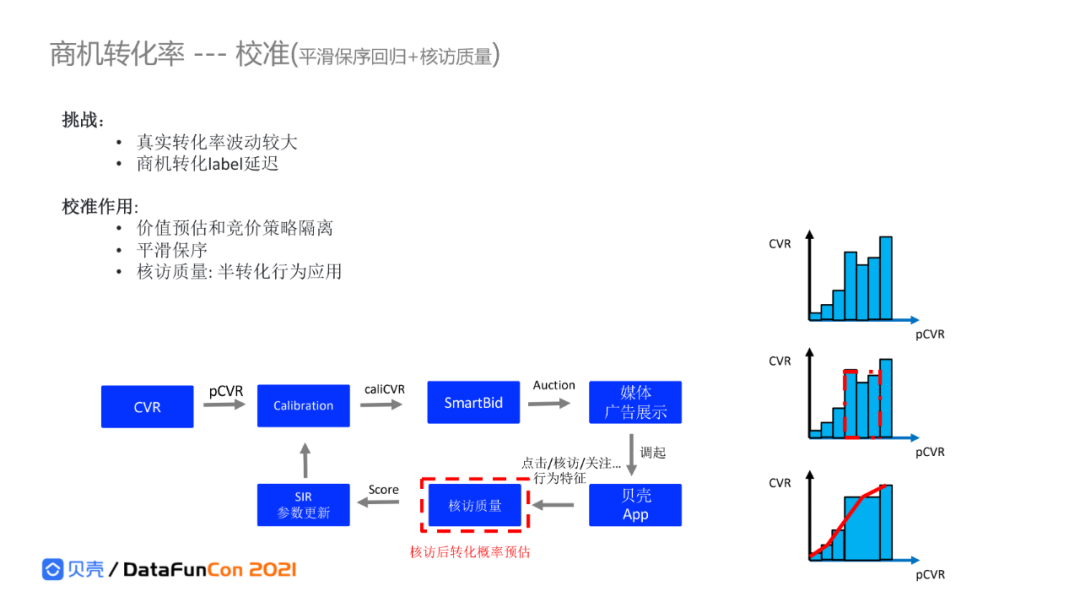
4. 商机转化率-校准
真实转化率的波动很大,对出价预估有很大的影响,需要增加一个平滑校准模块。校准的作用是将CTR预估模型和竞价策略进行解耦隔离。label的延迟,通过一些半转化行为进行建模校准。在真正产生交易的商机前,用户有很多行为数据,如搜索、详情页点击,通过统计规则,可以构建半转化模型判断用户在某些行为后产生商机转化的概率,这部分的校准能提升对效果评估的准确性和时效性。
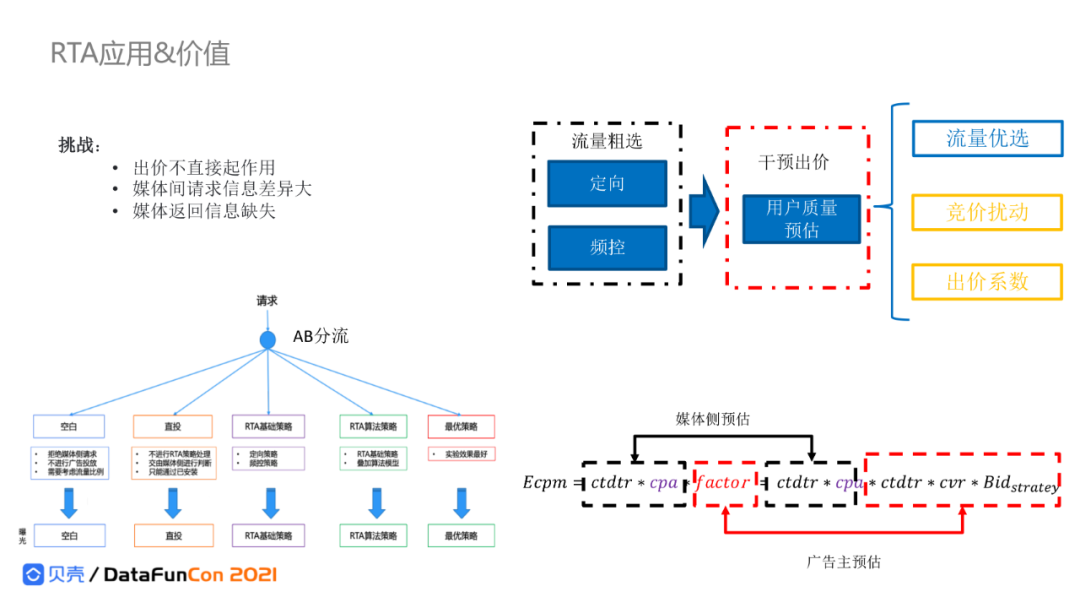
5. RTA应用和价值
最后介绍RTA的应用,RTA出价不直接起作用,媒体会对用户价值进行预估,广告主智能采用竞价扰动和调整出价系数进行效果优化。
贝壳设计了一个实验机制来评估RTA算法的增量价值,除了对比投与不投,还会对比空投、采取媒体直投、以及贝壳自己设计的不同RTA策略,对比不同分流组的效果,选出最优策略;同时也将前述的商机转化模型(CVR)和出价策略联合进行基于出价系数的智能出价。
03
智能预算分配
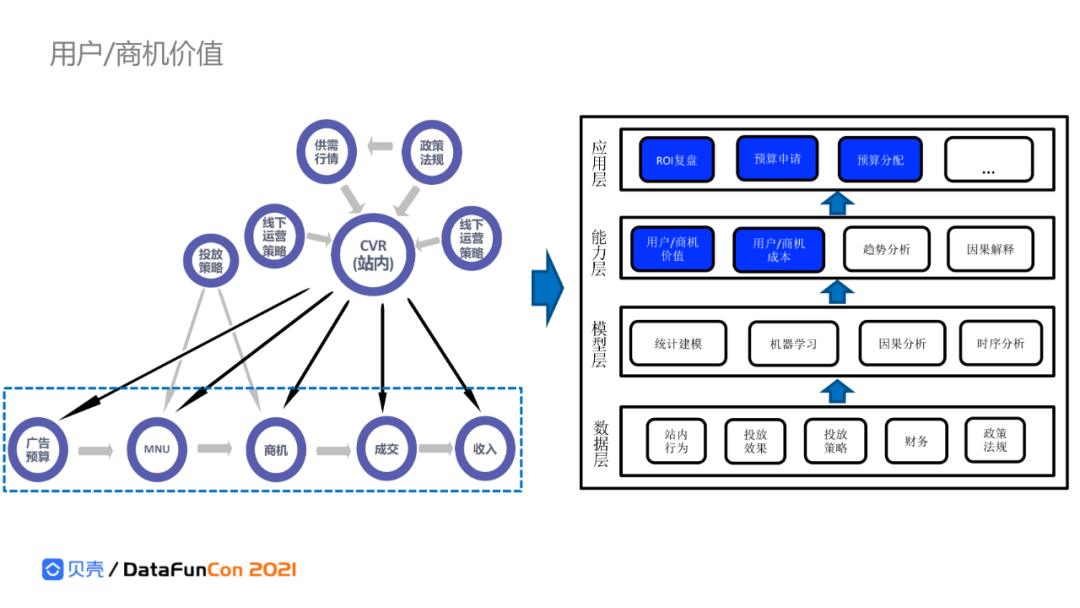
1. 用户和商机价值
我们关注拉新拉活中漏斗的转化率,在现实应用中,政策法规、供需行情和各类线上线下运营策略,对转化率有很大的影响。在做预算申请、分配时,依赖商机价值和成本评估,最大化ROI。
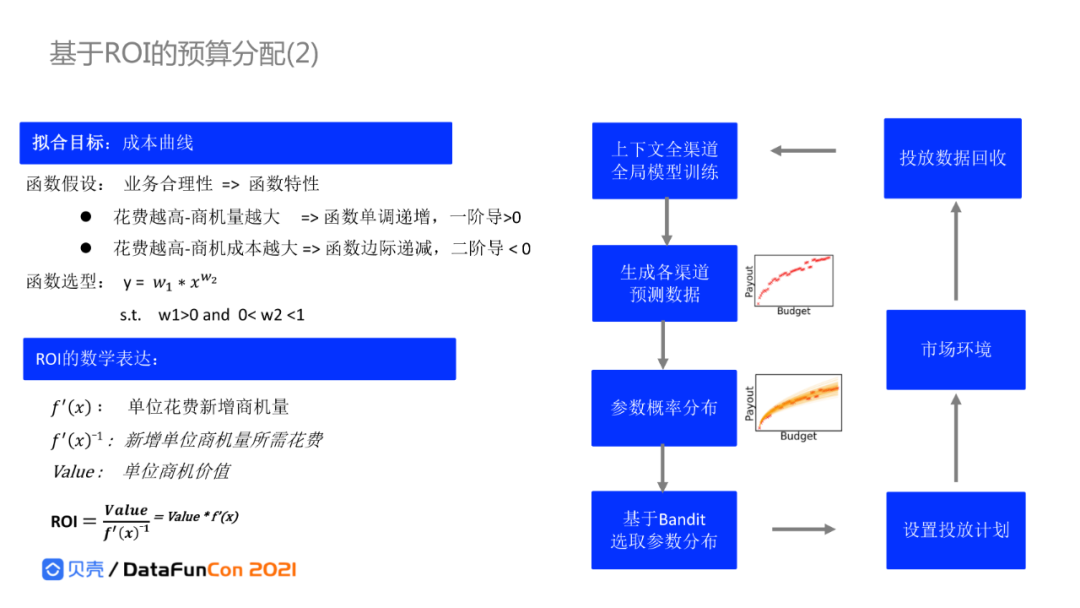
2. 基于ROI的预算分配
基于ROI的预算分配,是以最大化收入为优化目标,拟合的曲线是存在边际效应递减的业务假设,单调递增且边际递减。

单调递增的业务假设是:花费越多,商机量越大;边际递减的业务假设是:花费越多,商机成本越高。
通过在市场上进行一定的投放、收集数据。受到市场行情、定向策略以及各种上下文影响,不同渠道上相同的花费产生的效果不同。针对全渠道训练全局模型拉齐各渠道在不同上下文环境下的收益,生成与预测期相同上下文的增强样本;然后结合各特定渠道的样本,分别拟合该渠道的最优“收益-消耗”弹性曲线;接下来就可以利用这组弹性曲线进行基于全局ROI最大化的渠道间预算分配。
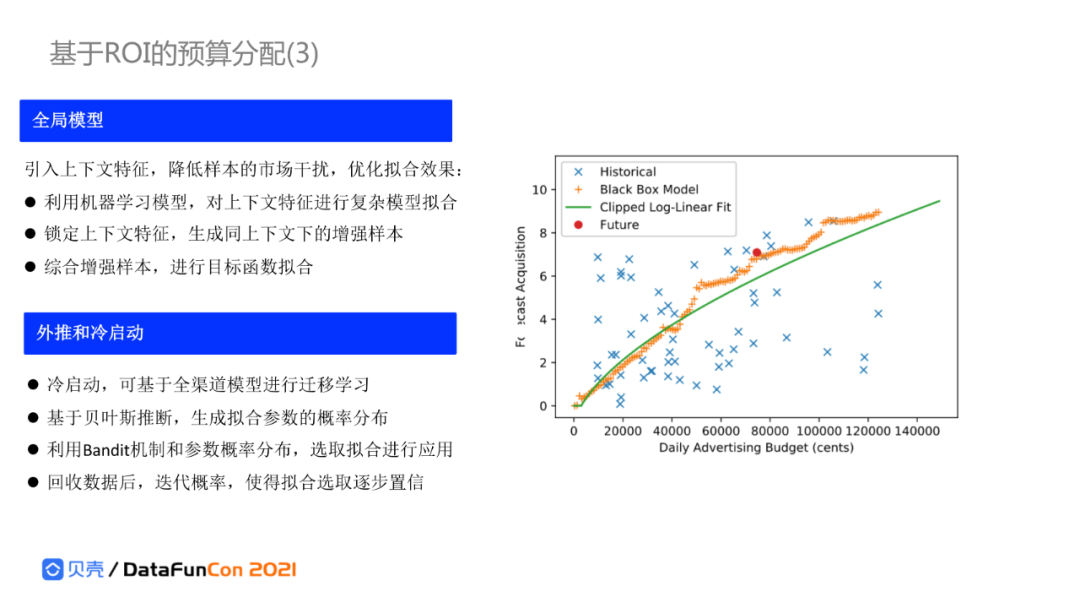
我们很容易看到这里还存在外推和冷启动的挑战:投放量少没有达到一定边界时,预估的准确率是不够的。需要做相应的外推,通过评估每一条曲线的大概置信度,在置信度空间内,采用基于Thompson采样的Bandit机制做一些外推,来探寻可能存在的最大化空间,通过不断迭代,最后得到各个渠道的真实效果。
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个3连击呗~
关注成都CDA数据分析师
获取数据分析的干货分享和岗位内推机会

















 1216
1216

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









