







每个机器学习模型模型不论大小,都有它的三要素:模型、策略和算法。所以主要从这三个方面的学习来认知逻辑回归模型。
本次学习参考资料是李航老师的《统计学方法》。
模型
逻辑回归可以与之前的感知机模型比较学习,它们之间的唯一区别便是激活函数的不同,逻辑回归采用的是logistic函数:
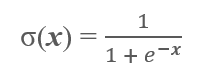
虽说名字是“回归”,但是通常我们也将逻辑回归应用于分类的任务,那它是怎么实现的呢?通过对logistic函数的理解,这是一个将输入值压缩到(0,1)区间的函数,这样我们就可以以0.5为分离超平面,使得计算的概率值结果趋向哪一个概率更大就将其归于哪一类,举例如:
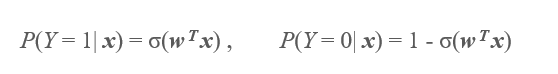
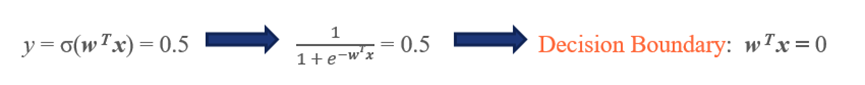

思考一下为什么逻辑回归比感知机模型相对来说更好?
第一,最后计算出的值是一趋于(0,1)之间的值,可以看作是概率值,具有更强的解释性,一个值不再是简单的非此即彼的分类,而是通过概率值来表达这个值更趋向于的分类。
第二,logistic函数是一个单调上升的连续函数,可以直接求导,方便我们之后的梯度下降操作。
策略
同样的,我们需要找到逻辑回归模型模型的损失函数,这里要提到一个概念——最大似然估计(Maximum Likelihood Estimate)(这一部分又感觉没有理解透彻,最大似然一两句感觉讲不清,留到另一个博客详细讲讲)。首先,推到得到我们的似然函数。
两个类别的概率分别如下:
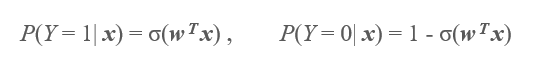
进一步得到我们的似然函数
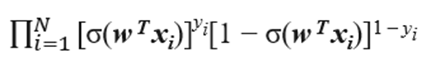
N是我们的数据集
OK,到这一步,我们的目的很明确,就是使得我们的似然函数越大越好! 接下来我们再通过一系列操作来转换这个似然函数。
对似然函数取对数,得到对数似然函数:
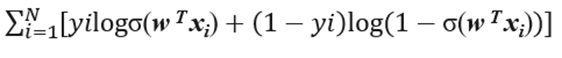
最后,为了和损失函数对应,我们取负值,得到了交叉熵损失函数(这个地方,从极大似然推导的方式,是《统计学方法》里面的方式,而最后的结果也只是得到了上面的对数似然函数,交叉熵函数应当是另一套推导流程,注意辨析)
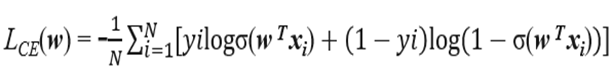
至此,我们就得到了我们逻辑回归模型的损失函数——交叉熵损失函数。
算法
同样的,在这里我们运用梯度下降来最小化我们的损失函数。
第一步同样是求得我们的梯度:
 j代表的的是一个参数/特征向量里面的第j个参数/特征
j代表的的是一个参数/特征向量里面的第j个参数/特征
i指代第i个数据或标签
代码
class Logistic:
def __init__(self, xMat: ndarray, yMat: ndarray):
self.xMat = np.mat(xMat)
self.yMat = np.mat(yMat)
def sigmoid(self, x):
return 1.0 / (1 + np.exp(-x))
def cost(self, w): # 计算cost
left = np.multiply(self.yMat, np.log(self.sigmoid(self.xMat * w)))
right = np.multiply(1 - self.yMat, np.log(1 - self.sigmoid(self.xMat * w)))
return np.sum(left + right) / -(len(self.xMat))
def gradAscent(self, lr, epochs):
costList = []
m, n = np.shape(self.xMat)
ws = np.mat(np.ones((n, 1)))
for i in range(epochs + 1):
h = self.sigmoid(self.xMat * ws)
w_grad = self.xMat.T * (h - self.yMat) / m
ws = ws - lr * w_grad
costList.append(self.cost(ws))
return ws, costList
效果图:

loss值变化图:















 1723
1723











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









