







题目 upx
第六题 和 第七题 是困难模式,直接先跳过,先看中等的。
首先题目说的是upx ,那么就有可能是 so 进行了upx 的压缩 了,
对于菜鸟的我来讲,先不管直接先抓包分析一下
抓包 分析
真机通过 postern + Charles 结合 进行抓包
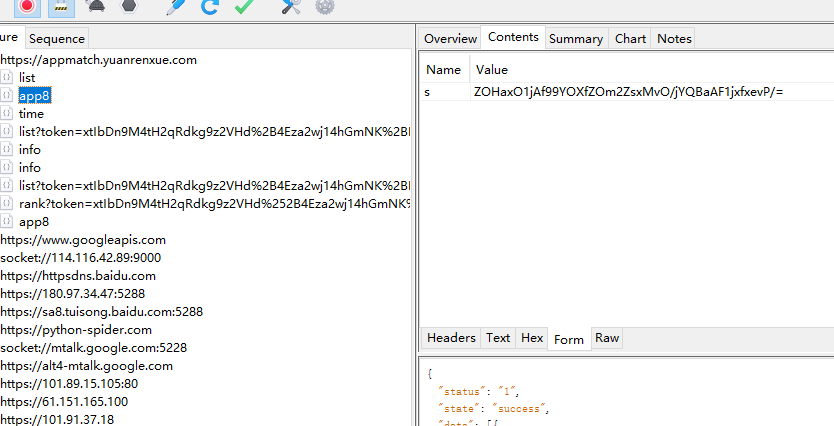
获取到抓包数据
其中form 表单中的参数 就一个 s
通过之前的题目分析,可以通过jadx 搜索url 路径可以定位到发包点
jadx 分析
打开jadx 搜索 /app8 可以匹配到一个定位点
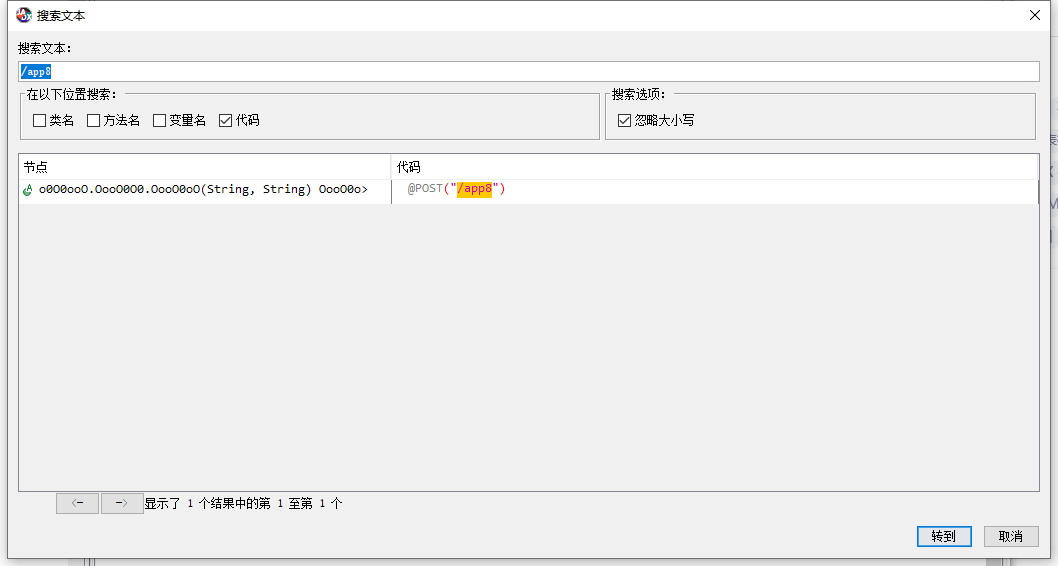
双击进入,可以确认 就是这里
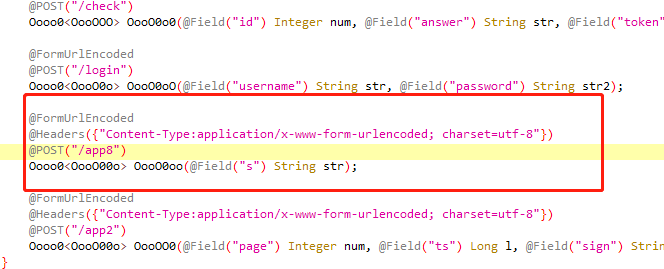
右键查找用例,点击进入,可以看到 data 的方法
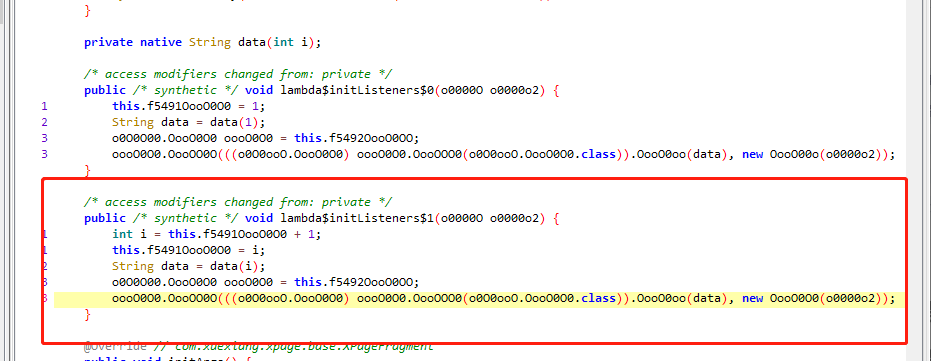
this.f5491OooO0O0 大差不差的就是page 页数 ,就直接Ctrl + 左键点击 data 函数方法 看看是啥
发现定位到 native 这里
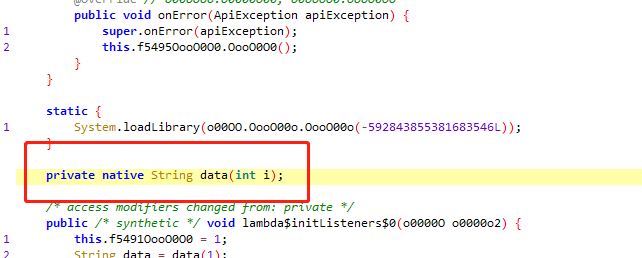
那么就直接 解压app 找到 这个so 包

其实也不需要怎么找,都给标识了
通过ida 打开,注意,这个是 arm64位的,需要用64位的IDA 打开
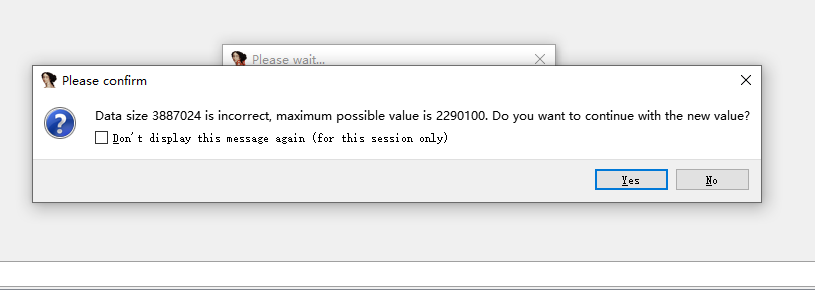
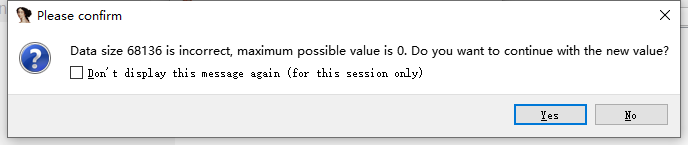
发现ida 提示这些信息,。。。。。。看不懂。。。。。直接面向百度搜索
噢。。对哦,针对题目,是不是可以得出一个结论,这个是upx加壳过的。
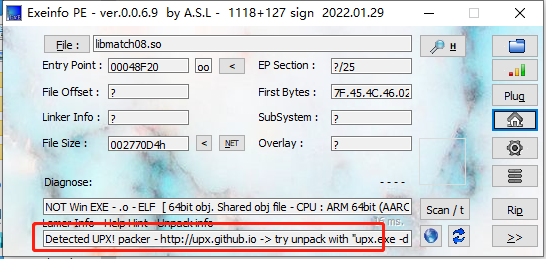
恩,通过软件监测,确实是加了upx 壳。那么就脱壳喽。。。
upx 脱壳
GitHub上面找脱壳机,
https://github.com/upx/upx
后来发现 原来 upx 支持 脱壳的
那么就 执行命令,
upx -d xxx.so
就脱下来了,ida 运行也正常了。
但是我懵逼了。。。看不懂。。。
尝试 frida rpc
没玩过ida啊,也就会ida的打开和运行,那么就尝试能不能直接使用frida 的 rpc 进行主动调用一下就行。。
代码如下
function main(){
console.log("hooking.......")
Java.perform(function(){
var data = Java.use("com.yuanrenxue.match2022.fragment.challenge.ChallengeEightFragment");
data.data.implementation = function(arg){
console.log('arg=>',arg);
// console.log("i = " + JSON.stringify(arguments[0]))
// var result = this.OooOooo.apply(this, arguments);
// console.log("res = " + JSON.stringify(result))
var result = this.data(arg);
console.log('result=>',result)
// var OooO0oo = this.OooO0oo(data)
return result
}
});
}
function invokedata(i){
var result = null;
Java.perform(function(){
Java.choose("com.yuanrenxue.match2022.fragment.challenge.ChallengeEightFragment",{
onMatch:function(ins){
console.log('ins=>',ins);
result = ins.data(i);
console.log('result=>',result)
},onComplete(){}
})
});
return result;
}
// setImmediate(main);
rpc.exports = {
invokedata:invokedata,
}
python 代码如下
import time
import frida
import requests
from requests.packages import urllib3
urllib3.disable_warnings()
def my_message_handler(message, payload):
print("message=>",message)
print("payloa=>d",payload)
# connect wifiadb
device = frida.get_device_manager().add_remote_device("192.168.0.102:8888")
print('设备=>',device)
session = device.attach("com.yuanrenxue.match2022")
print('session=>',session)
# load script
with open("app8.js") as f:
script = session.create_script(f.read())
script.on("message", my_message_handler)
script.load()
# script.exports.invokedata(1)
def get_url():
num = 0
for i in range(1,101):
url = 'https://appmatch.yuanrenxue.com/app8'
headers = {
'accept-language': 'zh-CN,zh;q=0.8',
'user-agent': 'Mozilla/5.0 (Linux; U; Android 8.1.0; zh-cn; Pixel XL Build/OPM1.171019.011) AppleWebKit/534.30 (KHTML, like Gecko) Version/4.0 Mobile Safari/534.30',
'content-type': 'application/x-www-form-urlencoded',
'accept-encoding': 'gzip',
'cache-control': 'no-cache'
}
sign = script.exports.invokedata(i)
data = {
's':sign,
}
print(data)
response = requests.post(url,headers=headers,data=data,verify=False)
print(response.json())
value_data = response.json()
for value in value_data['data']:
num += int(value['value'])
print(num)
time.sleep(1)
if __name__ == '__main__':
get_url()
一二三,点击运行,走你!!!!!!
最终答案 :4908224
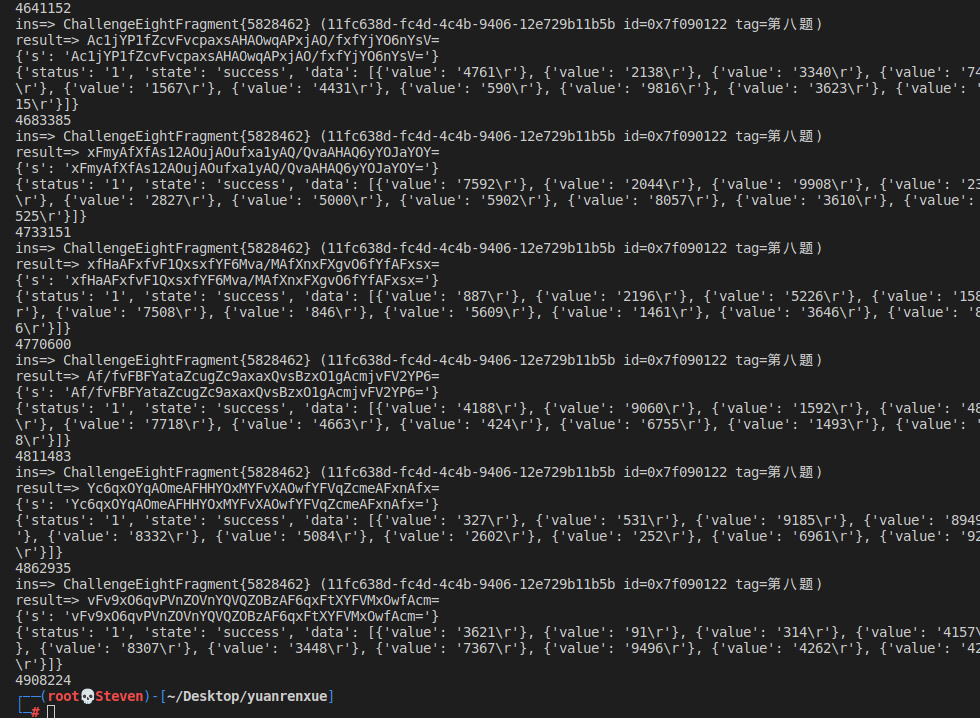
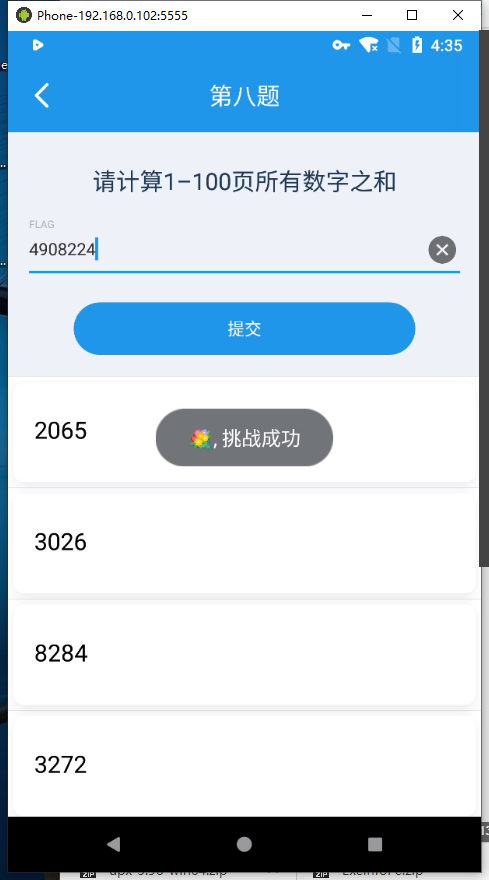
总结
emmm 我都不知道我应该怎么说了。。。我是不是违背了出题老师的意愿了。。。这里是upx 题目,考的重点应该是对upx壳的认识,还有就是对ida的使用认知吧。
不经意的去搜索看看别人的思路,发现都是在使用unidbg的方式去调用so ,然后返回数据进行python调用。
但是话又说回来,如果单纯是为了攻破题目的答案,貌似又没毛病。。。















 473
473











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









