







文章目录
- ~~~~~~~~~~~~数组和矩阵~~~~~~~~~~~~
- 27. 移除元素
- 相似题目:283. 移动零
- 相似题目:26. 删除有序数组中的重复项
- 36. 有效的数独
- 48. 旋转图像
- 498. 对角线遍历
- 54. 螺旋矩阵
- 59. 螺旋矩阵 II
- 73. 矩阵置零
- 相似题目:289. 生命游戏
- 1109. 航班预订统计
- 56. 合并区间
- 相似题目:406. 根据身高重建队列
- 41. 缺失的第一个正数
- 169. 多数元素
- 相似题目:229. 多数元素 II
- 240. 搜索二维矩阵 II
- 152. 乘积最大子数组
- ~~~~~~~~~~~~贪心算法~~~~~~~~~~~~
- 134. 加油站
- 860. 柠檬水找零
- 135. 分发糖果
- 452. 用最少数量的箭引爆气球
- 相似题目:435. 无重叠区间
- 56. 合并区间
- 670. 最大交换
- ~~~~~~~~~~~~哈希表~~~~~~~~~~~~
- 3. 无重复字符的最长子串
- 350. 两个数组的交集 II
- 187. 重复的DNA序列
- 1044. 最长重复子串
- 1995. 统计特殊四元组
- 846. 一手顺子
- 2013. 检测正方形
- 128. 最长连续序列
- 560. 和为 K 的子数组
数组和矩阵
27. 移除元素
力扣链接
给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素,并返回移除后数组的新长度。
不要使用额外的数组空间,你必须仅使用 O(1) 额外空间并 原地 修改输入数组。
元素的顺序可以改变。你不需要考虑数组中超出新长度后面的元素。
说明:
为什么返回数值是整数,但输出的答案是数组呢?
请注意,输入数组是以「引用」方式传递的,这意味着在函数里修改输入数组对于调用者是可见的。
你可以想象内部操作如下:
// nums 是以“引用”方式传递的。也就是说,不对实参作任何拷贝
int len = removeElement(nums, val);
// 在函数里修改输入数组对于调用者是可见的。
// 根据你的函数返回的长度, 它会打印出数组中 该长度范围内 的所有元素。
for (int i = 0; i < len; i++) {
print(nums[i]);
}
示例 1:
输入:nums = [3,2,2,3], val = 3
输出:2, nums = [2,2]
解释:函数应该返回新的长度 2, 并且 nums 中的前两个元素均为 2。你不需要考虑数组中超出新长度后面的元素。例如,函数返回的新长度为 2 ,而 nums = [2,2,3,3] 或 nums = [2,2,0,0],也会被视作正确答案。
示例 2:
输入:nums = [0,1,2,2,3,0,4,2], val = 2
输出:5, nums = [0,1,4,0,3]
解释:函数应该返回新的长度 5, 并且 nums 中的前五个元素为 0, 1, 3, 0, 4。注意这五个元素可为任意顺序。你不需要考虑数组中超出新长度后面的元素。
提示:
0 <= nums.length <= 100
0 <= nums[i] <= 50
0 <= val <= 100
解法1:数组+双指针
思路:
(1)有的同学可能说了,多余的元素,删掉不就得了。要知道数组的元素在内存地址中是连续的,不能单独删除数组中的某个元素,只能覆盖。
数组的基础知识可以看这里程序员算法面试中,必须掌握的数组理论知识 (opens new window)。
暴力解法
这个题目暴力的解法就是两层for循环,一个for循环遍历数组元素 ,第二个for循环更新数组。
删除过程如下:

很明显暴力解法的时间复杂度是O(n^2),这道题目暴力解法在leetcode上是可以过的。
代码如下:
// 时间复杂度:O(n^2)
// 空间复杂度:O(1)
class Solution {
public:
int removeElement(vector<int>& nums, int val) {
int size = nums.size();
for (int i = 0; i < size; i++) {
if (nums[i] == val) { // 发现需要移除的元素,就将数组集体向前移动一位
for (int j = i + 1; j < size; j++) {
nums[j - 1] = nums[j];
}
i--; // 因为下标i以后的数值都向前移动了一位,所以i也向前移动一位
size--; // 此时数组的大小-1
}
}
return size;
}
};
时间复杂度:
O
(
n
2
)
O(n^2)
O(n2)
空间复杂度:
O
(
1
)
O(1)
O(1)
(2) 双指针法
双指针法(快慢指针法): 通过一个快指针和慢指针在一个for循环下完成两个for循环的工作。
删除过程如下:

双指针法(快慢指针法)在数组和链表的操作中是非常常见的,很多考察数组、链表、字符串等操作的面试题,都使用双指针法。
代码:
// 时间复杂度:O(n)
// 空间复杂度:O(1)
class Solution {
public:
int removeElement(vector<int>& nums, int val) {
int slowIndex = 0;
for (int fastIndex = 0; fastIndex < nums.size(); fastIndex++) {
if (val != nums[fastIndex]) {
nums[slowIndex++] = nums[fastIndex];
}
}
return slowIndex;
}
};
注意这些实现方法并没有改变元素的相对位置!
时间复杂度:
O
(
n
)
O(n)
O(n)
空间复杂度:
O
(
1
)
O(1)
O(1)
相似题目:283. 移动零
力扣链接
给定一个数组 nums,编写一个函数将所有 0 移动到数组的末尾,同时保持非零元素的相对顺序。
示例:
输入: [0,1,0,3,12]
输出: [1,3,12,0,0]
说明:
必须在原数组上操作,不能拷贝额外的数组。
尽量减少操作次数。
解法1:数组+双指针
class Solution {
public:
void moveZeroes(vector<int>& nums) {
int slowIndex = 0, fastIndex = 0;
for(;fastIndex<nums.size();fastIndex++){
if(nums[fastIndex] != 0){
nums[slowIndex++] = nums[fastIndex];
}
}
while(slowIndex<nums.size()){
nums[slowIndex++] = 0;
}
}
};
相似题目:26. 删除有序数组中的重复项
力扣链接
给你一个有序数组 nums ,请你 原地 删除重复出现的元素,使每个元素 只出现一次 ,返回删除后数组的新长度。
不要使用额外的数组空间,你必须在 原地 修改输入数组 并在使用 O(1) 额外空间的条件下完成。
说明:
为什么返回数值是整数,但输出的答案是数组呢?
请注意,输入数组是以「引用」方式传递的,这意味着在函数里修改输入数组对于调用者是可见的。
你可以想象内部操作如下:
// nums 是以“引用”方式传递的。也就是说,不对实参做任何拷贝
int len = removeDuplicates(nums);
// 在函数里修改输入数组对于调用者是可见的。
// 根据你的函数返回的长度, 它会打印出数组中 该长度范围内 的所有元素。
for (int i = 0; i < len; i++) {
print(nums[i]);
}
示例 1:
输入:nums = [1,1,2]
输出:2, nums = [1,2]
解释:函数应该返回新的长度 2 ,并且原数组 nums 的前两个元素被修改为 1, 2 。不需要考虑数组中超出新长度后面的元素。
示例 2:
输入:nums = [0,0,1,1,1,2,2,3,3,4]
输出:5, nums = [0,1,2,3,4]
解释:函数应该返回新的长度 5 , 并且原数组 nums 的前五个元素被修改为 0, 1, 2, 3, 4 。不需要考虑数组中超出新长度后面的元素。
提示:
0 <= nums.length <= 3 * 104
-104 <= nums[i] <= 104
nums 已按升序排列
解法1:数组+双指针
(1)
class Solution {
public:
int removeDuplicates(vector<int>& nums) {
if(nums.size()==0) return 0;
int slowIndex = 0;
for(int fastIndex = 1;fastIndex<nums.size();fastIndex++){
if(nums[fastIndex]>nums[slowIndex]){
slowIndex++;
nums[slowIndex] = nums[fastIndex];
}
}
return slowIndex+1;
}
};
(2)
class Solution {
public:
int removeDuplicates(vector<int>& nums) {
if (nums.empty()) return 0; // 别忘记空数组的判断
int slowIndex = 0;
for (int fastIndex = 0; fastIndex < (nums.size() - 1); fastIndex++){
if(nums[fastIndex] != nums[fastIndex + 1]) { // 发现和后一个不相同
nums[++slowIndex] = nums[fastIndex + 1]; //slowIndex = 0 的数据一定是不重复的,所以直接 ++slowIndex
}
}
return slowIndex + 1; //别忘了slowIndex是从0开始的,所以返回slowIndex + 1
}
};
复杂度分析:
时间复杂度:O(n),其中 n 是数组的长度。快指针和慢指针最多各移动 n 次。
空间复杂度:O(1)。只需要使用常数的额外空间。
36. 有效的数独
力扣链接
请你判断一个 9 x 9 的数独是否有效。只需要 根据以下规则 ,验证已经填入的数字是否有效即可。
数字 1-9 在每一行只能出现一次。
数字 1-9 在每一列只能出现一次。
数字 1-9 在每一个以粗实线分隔的 3x3 宫内只能出现一次。(请参考示例图)
注意:
一个有效的数独(部分已被填充)不一定是可解的。
只需要根据以上规则,验证已经填入的数字是否有效即可。
空白格用 ‘.’ 表示。
示例 1:
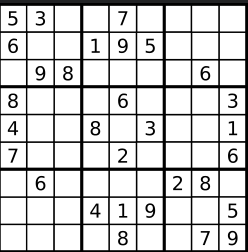
输入:board =
[[“5”,“3”,“.”,“.”,“7”,“.”,“.”,“.”,“.”]
,[“6”,“.”,“.”,“1”,“9”,“5”,“.”,“.”,“.”]
,[“.”,“9”,“8”,“.”,“.”,“.”,“.”,“6”,“.”]
,[“8”,“.”,“.”,“.”,“6”,“.”,“.”,“.”,“3”]
,[“4”,“.”,“.”,“8”,“.”,“3”,“.”,“.”,“1”]
,[“7”,“.”,“.”,“.”,“2”,“.”,“.”,“.”,“6”]
,[“.”,“6”,“.”,“.”,“.”,“.”,“2”,“8”,“.”]
,[“.”,“.”,“.”,“4”,“1”,“9”,“.”,“.”,“5”]
,[“.”,“.”,“.”,“.”,“8”,“.”,“.”,“7”,“9”]]
输出:true
示例 2:
输入:board =
[[“8”,“3”,“.”,“.”,“7”,“.”,“.”,“.”,“.”]
,[“6”,“.”,“.”,“1”,“9”,“5”,“.”,“.”,“.”]
,[“.”,“9”,“8”,“.”,“.”,“.”,“.”,“6”,“.”]
,[“8”,“.”,“.”,“.”,“6”,“.”,“.”,“.”,“3”]
,[“4”,“.”,“.”,“8”,“.”,“3”,“.”,“.”,“1”]
,[“7”,“.”,“.”,“.”,“2”,“.”,“.”,“.”,“6”]
,[“.”,“6”,“.”,“.”,“.”,“.”,“2”,“8”,“.”]
,[“.”,“.”,“.”,“4”,“1”,“9”,“.”,“.”,“5”]
,[“.”,“.”,“.”,“.”,“8”,“.”,“.”,“7”,“9”]]
输出:false
解释:除了第一行的第一个数字从 5 改为 8 以外,空格内其他数字均与 示例1 相同。 但由于位于左上角的 3x3 宫内有两个 8 存在, 因此这个数独是无效的。
提示:
board.length == 9
board[i].length == 9
board[i][j] 是一位数字(1-9)或者 ‘.’
解法1:数组
思路:

代码:
class Solution {
public:
bool isValidSudoku(vector<vector<char>>& board) {
int row[9][10] = {0};
int col[9][10] = {0};
int box[9][10] = {0};
for(int i = 0;i<9;i++){
for(int j = 0;j<9;j++){
if(board[i][j] == '.') continue;
int curNum = board[i][j] - '0';
//先判断是否出现过
if(row[i][curNum]) return false;
if(col[j][curNum]) return false;
if(box[(i/3)*3+j/3][curNum]) return false;
row[i][curNum]++;
col[j][curNum]++;
box[(i/3)*3+j/3][curNum]++;
}
}
return true;
}
};
复杂度分析:
时间复杂度:在固定 99 的问题里,计算量不随数据变化而变化。复杂度为 O(1)
空间复杂度:在固定 99 的问题里,存储空间不随数据变化而变化。复杂度为 O(1)
48. 旋转图像
给定一个 n × n 的二维矩阵 matrix 表示一个图像。请你将图像顺时针旋转 90 度。
你必须在 原地 旋转图像,这意味着你需要直接修改输入的二维矩阵。请不要 使用另一个矩阵来旋转图像。
示例 1:
输入:matrix = [[1,2,3],[4,5,6],[7,8,9]]
输出:[[7,4,1],[8,5,2],[9,6,3]]
示例 2:
输入:matrix = [[5,1,9,11],[2,4,8,10],[13,3,6,7],[15,14,12,16]]
输出:[[15,13,2,5],[14,3,4,1],[12,6,8,9],[16,7,10,11]]
示例 3:
输入:matrix = [[1]]
输出:[[1]]
示例 4:
输入:matrix = [[1,2],[3,4]]
输出:[[3,1],[4,2]]
提示:
matrix.length == n
matrix[i].length == n
1 <= n <= 20
-1000 <= matrix[i][j] <= 1000
解法1:原地旋转+迭代

思路:
自外向内一共有不超过 n/2 层(单个中心元素不算一层)矩形框。对于第 times 层矩形框,其框边长 len=nums-(times*2),将其顺时针分为 4 份len−1 的边,对四条边进行元素的循环交换即可。

代码:
class Solution {
public:
void rotate(vector<vector<int>>& matrix) {
if(matrix.size() <= 1) return;
int n = matrix.size();
int layer = 0;
while(layer <= n/2){
int len = n - 2*layer;
for(int i = 0;i<len-1;i++){
int temp = matrix[layer][layer+i];
matrix[layer][layer+i] = matrix[layer+len-i-1][layer];
matrix[layer+len-i-1][layer] = matrix[layer+len-1][layer+len-i-1];
matrix[layer+len-1][layer+len-i-1] = matrix[layer+i][layer+len-1];
matrix[layer+i][layer+len-1] = temp;
}
layer++;
}
}
};
复杂度分析:

解法2:原地旋转+递归
思路:

代码:
class Solution {
public:
void rotate(vector<vector<int>>& matrix) {
rot(matrix,0,matrix.size());
}
void rot(vector<vector<int>>& matrix,int level,int rank){
if(rank > 1){
for(int i = 0;i<rank-1;i++){
int temp = matrix[level][level+i];
matrix[level][level+i] = matrix[level+rank-i-1][level];
matrix[level+rank-i-1][level] = matrix[level+rank-1][level+rank-1-i];
matrix[level+rank-1][level+rank-1-i] = matrix[level+i][level+rank-1];
matrix[level+i][level+rank-1] = temp;
}
rot(matrix,level+1,rank-2);
}
}
};
解法3:两次翻转
代码:
class Solution {
public:
void rotate(vector<vector<int>>& matrix) {
int n = matrix.size();
//水平翻转
for(int i = 0;i<n/2;i++){
for(int j = 0;j<n;j++){
swap(matrix[i][j],matrix[n-i-1][j]);
}
}
//对角线翻转
for(int i = 0;i<n;i++){
for(int j = 0;j<i;j++){
swap(matrix[i][j],matrix[j][i]);
}
}
}
};
复杂度分析:
时间复杂度:O(N^2),其中 N 是 matrix 的边长。对于每一次翻转操作,我们都需要枚举矩阵中一半的元素。
空间复杂度:O(1)。为原地翻转得到的原地旋转。
498. 对角线遍历
力扣链接
给你一个大小为 m x n 的矩阵 mat ,请以对角线遍历的顺序,用一个数组返回这个矩阵中的所有元素。
示例 1:
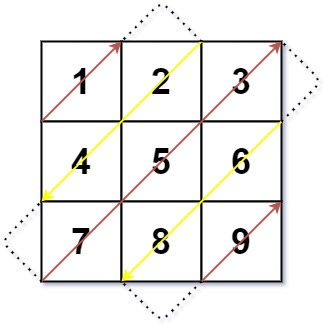
输入:mat = [[1,2,3],[4,5,6],[7,8,9]]
输出:[1,2,4,7,5,3,6,8,9]
示例 2:
输入:mat = [[1,2],[3,4]]
输出:[1,2,3,4]
提示:
m == mat.length
n == mat[i].length
1 <= m, n <= 104
1 <= m * n <= 104
-105 <= mat[i][j] <= 105
解法1:模拟
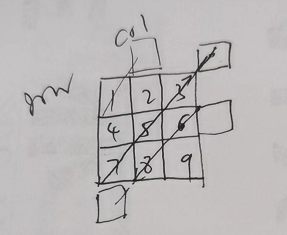
class Solution {
public:
vector<int> findDiagonalOrder(vector<vector<int>>& mat) {
int m = mat.size(), n = mat[0].size();
vector<int> res(m*n);
const int dir[2][2] = {{-1,1},{1,-1}};//左上 右下
int d = 0, row = 0, col = 0;
for(int i = 0;i<m*n;i++){
res[i] = mat[row][col];
row += dir[d][0];
col += dir[d][1];
if(row >= m){
d = 1-d;
row = m-1;
col +=2;
}
if(col >= n){
d = 1-d;
col = n -1;
row += 2;
}
if(row < 0){
d = 1-d;
row = 0;
}
if(col < 0){
d = 1-d;
col = 0;
}
}
return res;
}
};
54. 螺旋矩阵
力扣链接
给你一个 m 行 n 列的矩阵 matrix ,请按照 顺时针螺旋顺序 ,返回矩阵中的所有元素。
示例 1:
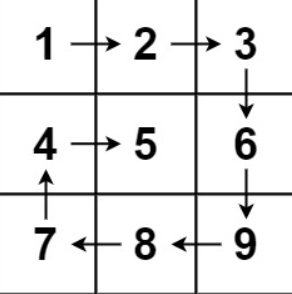
输入:matrix = [[1,2,3],[4,5,6],[7,8,9]]
输出:[1,2,3,6,9,8,7,4,5]
示例 2:

输入:matrix = [[1,2,3,4],[5,6,7,8],[9,10,11,12]]
输出:[1,2,3,4,8,12,11,10,9,5,6,7]
提示:
m == matrix.length
n == matrix[i].length
1 <= m, n <= 10
-100 <= matrix[i][j] <= 100
解法1:矩阵+模拟
思路:

代码:
class Solution {
public:
vector<int> spiralOrder(vector<vector<int>>& matrix) {
vector<int> res;
int m = matrix.size(), n = matrix[0].size();
int l = 0, r = n-1;
int u = 0, d = m - 1;
while(true){
for(int i = l;i<=r;i++) res.push_back(matrix[u][i]);
if(++u>d) break;
for(int i = u;i<=d;i++) res.push_back(matrix[i][r]);
if(--r<l) break;
for(int i = r;i>=l;i--) res.push_back(matrix[d][i]);
if(--d<u) break;
for(int i = d;i>=u;i--) res.push_back(matrix[i][l]);
if(++l>r) break;
}
return res;
}
};
59. 螺旋矩阵 II
给你一个正整数 n ,生成一个包含 1 到 n2 所有元素,且元素按顺时针顺序螺旋排列的 n x n 正方形矩阵 matrix 。
示例 1:
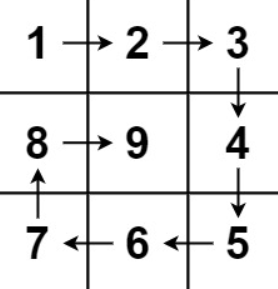
输入:n = 3
输出:[[1,2,3],[8,9,4],[7,6,5]]
示例 2:
输入:n = 1
输出:[[1]]
提示:
1 <= n <= 20
解法1:矩阵+模拟
思路:
这道题目可以说在面试中出现频率较高的题目,本题并不涉及到什么算法,就是模拟过程,但却十分考察对代码的掌控能力。要如何画出这个螺旋排列的正方形矩阵呢?相信很多同学刚开始做这种题目的时候,上来就是一波判断猛如虎。结果运行的时候各种问题,然后开始各种修修补补,最后发现改了这里哪里有问题,改了那里这里又跑不起来了。
大家还记得我们在这篇文章数组:每次遇到二分法,都是一看就会,一写就废中讲解了二分法,提到如果要写出正确的二分法一定要坚持循环不变量原则。
而求解本题依然是要坚持循环不变量原则。
模拟顺时针画矩阵的过程:
填充上行从左到右
填充右列从上到下
填充下行从右到左
填充左列从下到上
由外向内一圈一圈这么画下去。
可以发现这里的边界条件非常多,在一个循环中,如此多的边界条件,如果不按照固定规则来遍历,那就是一进循环深似海,从此offer是路人。这里一圈下来,我们要画每四条边,这四条边怎么画,每画一条边都要坚持一致的左闭右开,或者左开又闭的原则,这样这一圈才能按照统一的规则画下来。
那么我按照左闭右开的原则,来画一圈,大家看一下:

这里每一种颜色,代表一条边,我们遍历的长度,可以看出每一个拐角处的处理规则,拐角处让给新的一条边来继续画。
这也是坚持了每条边左闭右开的原则。
代码:
class Solution {
public:
vector<vector<int>> generateMatrix(int n) {
vector<vector<int>> result(n,vector<int>(n,0));
int startx = 0, starty = 0;// 定义每循环一个圈的起始位置
int loop = n/2;// 每个圈循环几次,例如n为奇数3,那么loop = 1 只是循环一圈,矩阵中间的值需要单独处理
int mid = n/2;// 矩阵中间的位置,例如:n为3, 中间的位置就是(1,1),n为5,中间位置为(2, 2)
int offset = 1;// 每一圈循环,需要控制每一条边遍历的长度
int count = 1;// 用来给矩阵中每一个空格赋值
int i,j;
while(loop--){
// 下面开始的四个for就是模拟转了一圈
// 模拟填充上行从左到右(左闭右开)
for(j = starty;j<starty+n-offset;j++){
result[startx][j] = count++;
}
// 模拟填充右列从上到下(左闭右开)
for(i = startx;i<startx+n-offset;i++){
result[i][j] = count++;
}
// 模拟填充下行从右到左(左闭右开)
for(;j>starty;j--){
result[i][j] = count++;
}
// 模拟填充左列从下到上(左闭右开)
for(;i>startx;i--){
result[i][j] = count++;
}
// 第二圈开始的时候,起始位置要各自加1, 例如:第一圈起始位置是(0, 0),第二圈起始位置是(1, 1)
startx++, starty++;
// offset 控制每一圈里每一条边遍历的长度
offset+=2;
}
// offset 控制每一圈里每一条边遍历的长度
if(n%2){
result[mid][mid] = count++;
}
return result;
}
};
复杂度分析:
时间复杂度:O(n^2),其中n 是给定的正整数。矩阵的大小是n×n,需要填入矩阵中的每个元素。
空间复杂度:O(1)。除了返回的矩阵以外,空间复杂度是常数。
73. 矩阵置零
力扣链接
给定一个 m x n 的矩阵,如果一个元素为 0 ,则将其所在行和列的所有元素都设为 0 。请使用 原地 算法。
示例 1:

输入:matrix = [[1,1,1],[1,0,1],[1,1,1]]
输出:[[1,0,1],[0,0,0],[1,0,1]]
示例 2:

输入:matrix = [[0,1,2,0],[3,4,5,2],[1,3,1,5]]
输出:[[0,0,0,0],[0,4,5,0],[0,3,1,0]]
提示:
m == matrix.length
n == matrix[0].length
1 <= m, n <= 200
-231 <= matrix[i][j] <= 231 - 1
进阶:
一个直观的解决方案是使用 O(mn) 的额外空间,但这并不是一个好的解决方案。
一个简单的改进方案是使用 O(m + n) 的额外空间,但这仍然不是最好的解决方案。
你能想出一个仅使用常量空间的解决方案吗?
解法1:使用两个标记变量
思路:
我们可以用矩阵的第一行和第一列代替两个标记数组,以达到O(1) 的额外空间。但这样会导致原数组的第一行和第一列被修改,无法记录它们是否原本包含 0。因此我们需要额外使用两个标记变量分别记录第一行和第一列是否原本包含 0。
在实际代码中,我们首先预处理出两个标记变量,接着使用其他行与列去处理第一行与第一列,然后反过来使用第一行与第一列去更新其他行与列,最后使用两个标记变量更新第一行与第一列即可。
代码:
class Solution {
public:
void setZeroes(vector<vector<int>>& matrix) {
bool rowFlag = false, colFlag = false;
int m = matrix.size(), n = matrix[0].size();
for(int i = 0;i<m;i++){
if(!matrix[i][0]){
colFlag = true;
break;
}
}
for(int i = 0;i<n;i++){
if(!matrix[0][i]){
rowFlag = true;
break;
}
}
for(int i = 1;i<m;i++){
for(int j = 1;j<n;j++){
if(matrix[i][j] == 0){
matrix[i][0] = 0;
matrix[0][j] = 0;
}
}
}
for(int i = 1;i<m;i++){
for(int j = 1;j<n;j++){
if(matrix[i][0] == 0 || matrix[0][j] == 0){
matrix[i][j] = 0;
}
}
}
if(colFlag){
for(int i = 0;i<m;i++) matrix[i][0] = 0;
}
if(rowFlag){
for(int i = 0;i<n;i++) matrix[0][i] = 0;
}
}
};
复杂度分析:
时间复杂度:O(mn),其中 m 是矩阵的行数,n 是矩阵的列数。我们至多只需要遍历该矩阵两次。
空间复杂度:O(1)。我们只需要常数空间存储若干变量。
相似题目:289. 生命游戏
根据 百度百科 , 生命游戏 ,简称为 生命 ,是英国数学家约翰·何顿·康威在 1970 年发明的细胞自动机。
给定一个包含 m × n 个格子的面板,每一个格子都可以看成是一个细胞。每个细胞都具有一个初始状态: 1 即为 活细胞 (live),或 0 即为 死细胞 (dead)。每个细胞与其八个相邻位置(水平,垂直,对角线)的细胞都遵循以下四条生存定律:
如果活细胞周围八个位置的活细胞数少于两个,则该位置活细胞死亡;
如果活细胞周围八个位置有两个或三个活细胞,则该位置活细胞仍然存活;
如果活细胞周围八个位置有超过三个活细胞,则该位置活细胞死亡;
如果死细胞周围正好有三个活细胞,则该位置死细胞复活;
下一个状态是通过将上述规则同时应用于当前状态下的每个细胞所形成的,其中细胞的出生和死亡是同时发生的。给你 m x n 网格面板 board 的当前状态,返回下一个状态。
示例 1:

输入:board = [[0,1,0],[0,0,1],[1,1,1],[0,0,0]]
输出:[[0,0,0],[1,0,1],[0,1,1],[0,1,0]]
示例 2:
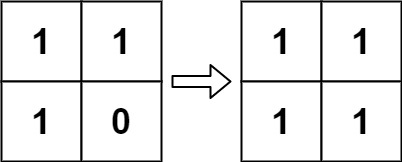
输入:board = [[1,1],[1,0]]
输出:[[1,1],[1,1]]
提示:
m == board.length
n == board[i].length
1 <= m, n <= 25
board[i][j] 为 0 或 1
进阶:
你可以使用原地算法解决本题吗?请注意,面板上所有格子需要同时被更新:你不能先更新某些格子,然后使用它们的更新后的值再更新其他格子。
本题中,我们使用二维数组来表示面板。原则上,面板是无限的,但当活细胞侵占了面板边界时会造成问题。你将如何解决这些问题?
解法1:位运算+矩阵
思路:
一个 int 有 32 bit,输入数据只用了一个 bit,所以我们可以利用其他空闲的bit位进行“原地修改”。
代码:
class Solution {
public:
const int dx[8] = {1,1,1,-1,-1,-1,0,0};
const int dy[8] = {0,-1,1,0,-1,1,1,-1};
void gameOfLife(vector<vector<int>>& board) {
int m = board.size(), n = board[0].size();
for(int i = 0;i<m;i++){
for(int j = 0;j<n;j++){
int cnt = 0;
for(int k = 0;k<8;k++){
int x = i + dx[k];
int y = j + dy[k];
if(x < 0|| y<0 || x>= m || y>=n) continue;
cnt += board[x][y] & 1;// 只累加最低位
}
if((board[i][j] & 1) > 0){
if(cnt == 2 || cnt == 3){
board[i][j] |= 2; // 使用第二个bit标记是否存活
}
}else if(cnt == 3){
board[i][j] |= 2;// 使用第二个bit标记是否存活
}
}
}
for(int i = 0;i<m;i++){
for (int j = 0;j<n;j++){
board[i][j] >>= 1;//右移一位,用第二bit覆盖第一个bit。
}
}
}
};
1109. 航班预订统计
力扣链接
这里有 n 个航班,它们分别从 1 到 n 进行编号。
有一份航班预订表 bookings ,表中第 i 条预订记录 bookings[i] = [firsti, lasti, seatsi] 意味着在从 firsti 到 lasti (包含 firsti 和 lasti )的 每个航班 上预订了 seatsi 个座位。
请你返回一个长度为 n 的数组 answer,里面的元素是每个航班预定的座位总数。

提示:
1 <= n <= 2 * 104
1 <= bookings.length <= 2 * 104
bookings[i].length == 3
1 <= firsti <= lasti <= n
1 <= seatsi <= 104
解法1:数组+前缀和
思路:
暴力解法超时

(上下公交车)
代码:
class Solution {
public:
vector<int> corpFlightBookings(vector<vector<int>>& bookings, int n) {
vector<int> res(n);
for(auto& b:bookings){
res[b[0]-1] += b[2];
if(b[1] < n){
res[b[1]] -= b[2];
}
}
for(int i = 1;i<n;i++){
res[i] += res[i-1];
}
return res;
}
};
56. 合并区间
力扣链接
以数组 intervals 表示若干个区间的集合,其中单个区间为 intervals[i] = [starti, endi] 。请你合并所有重叠的区间,并返回 一个不重叠的区间数组,该数组需恰好覆盖输入中的所有区间 。
示例 1:
输入:intervals = [[1,3],[2,6],[8,10],[15,18]]
输出:[[1,6],[8,10],[15,18]]
解释:区间 [1,3] 和 [2,6] 重叠, 将它们合并为 [1,6].
示例 2:
输入:intervals = [[1,4],[4,5]]
输出:[[1,5]]
解释:区间 [1,4] 和 [4,5] 可被视为重叠区间。
提示:
1 <= intervals.length <= 104
intervals[i].length == 2
0 <= starti <= endi <= 104
解法1:排序
class Solution {
public:
vector<vector<int>> merge(vector<vector<int>>& intervals) {
sort(intervals.begin(),intervals.end(),[&](const vector<int>& a, const vector<int>& b){
return a[0] < b[0];
});
vector<vector<int>> res;
res.push_back(intervals[0]);
for(int i = 1;i<intervals.size();i++){
if(intervals[i][0] <= res.back()[1]){
res.back()[1] = max(intervals[i][1],res.back()[1]);
}else{
res.push_back(intervals[i]);
}
}
return res;
}
};

相似题目:406. 根据身高重建队列
假设有打乱顺序的一群人站成一个队列,数组 people 表示队列中一些人的属性(不一定按顺序)。每个 people[i] = [hi, ki] 表示第 i 个人的身高为 hi ,前面 正好 有 ki 个身高大于或等于 hi 的人。
请你重新构造并返回输入数组 people 所表示的队列。返回的队列应该格式化为数组 queue ,其中 queue[j] = [hj, kj] 是队列中第 j 个人的属性(queue[0] 是排在队列前面的人)。
示例 1:
输入:people = [[7,0],[4,4],[7,1],[5,0],[6,1],[5,2]]
输出:[[5,0],[7,0],[5,2],[6,1],[4,4],[7,1]]
解释:
编号为 0 的人身高为 5 ,没有身高更高或者相同的人排在他前面。
编号为 1 的人身高为 7 ,没有身高更高或者相同的人排在他前面。
编号为 2 的人身高为 5 ,有 2 个身高更高或者相同的人排在他前面,即编号为 0 和 1 的人。
编号为 3 的人身高为 6 ,有 1 个身高更高或者相同的人排在他前面,即编号为 1 的人。
编号为 4 的人身高为 4 ,有 4 个身高更高或者相同的人排在他前面,即编号为 0、1、2、3 的人。
编号为 5 的人身高为 7 ,有 1 个身高更高或者相同的人排在他前面,即编号为 1 的人。
因此 [[5,0],[7,0],[5,2],[6,1],[4,4],[7,1]] 是重新构造后的队列。
示例 2:
输入:people = [[6,0],[5,0],[4,0],[3,2],[2,2],[1,4]]
输出:[[4,0],[5,0],[2,2],[3,2],[1,4],[6,0]]
提示:
1 <= people.length <= 2000
0 <= hi <= 106
0 <= ki < people.length
题目数据确保队列可以被重建
解法1:排序
思路:



代码:
class Solution {
public:
vector<vector<int>> reconstructQueue(vector<vector<int>>& people) {
sort(people.begin(),people.end(),[&](const vector<int>& a, const vector<int>& b){
return a[0] > b[0] || (a[0] == b[0] && a[1] < b[1]);
});
vector<vector<int>> res;
for(auto p:people){
res.insert(res.begin()+p[1],p);
}
return res;
}
};
41. 缺失的第一个正数
力扣链接
给你一个未排序的整数数组 nums ,请你找出其中没有出现的最小的正整数。
请你实现时间复杂度为 O(n) 并且只使用常数级别额外空间的解决方案。
示例 1:
输入:nums = [1,2,0]
输出:3
示例 2:
输入:nums = [3,4,-1,1]
输出:2
示例 3:
输入:nums = [7,8,9,11,12]
输出:1
提示:
1 <= nums.length <= 5 * 105
-231 <= nums[i] <= 231 - 1
解法1:二次遍历
遍历一次数组把大于等于1的和小于数组大小的值放到原数组对应位置,然后再遍历一次数组查当前下标是否和值对应,如果不对应那这个下标就是答案,否则遍历完都没出现那么答案就是数组长度加1。
class Solution {
public:
int firstMissingPositive(vector<int>& nums) {
int n = nums.size();
for(int i = 0;i<n;i++){
while(nums[i] > 0 && nums[i] <= n && nums[i] != nums[nums[i]-1]){
swap(nums[i], nums[nums[i]-1]);
}
}
for(int i = 0;i<n;i++){
if(nums[i] != i+1) return i+1;
}
return n+1;
}
};
169. 多数元素
力扣链接
给定一个大小为 n 的数组 nums ,返回其中的多数元素。多数元素是指在数组中出现次数 大于 ⌊ n/2 ⌋ 的元素。
你可以假设数组是非空的,并且给定的数组总是存在多数元素。
示例 1:
输入:nums = [3,2,3]
输出:3
示例 2:
输入:nums = [2,2,1,1,1,2,2]
输出:2
提示:
n == nums.length
1 <= n <= 5 * 104
-109 <= nums[i] <= 109
进阶:尝试设计时间复杂度为 O(n)、空间复杂度为 O(1) 的算法解决此问题。
解法1:

class Solution {
public:
int majorityElement(vector<int>& nums) {
if(nums.size() == 0) return -1;
int n = nums.size();
int cnt = 1, res = nums[0];
for(int i = 1;i<n;i++){
if(cnt == 0) res = nums[i];
if(nums[i] == res) cnt++;
else cnt--;
}
return res;
}
};
相似题目:229. 多数元素 II
给定一个大小为 n 的整数数组,找出其中所有出现超过 ⌊ n/3 ⌋ 次的元素。
示例 1:
输入:nums = [3,2,3]
输出:[3]
示例 2:
输入:nums = [1]
输出:[1]
示例 3:
输入:nums = [1,2]
输出:[1,2]
提示:
1 <= nums.length <= 5 * 104
-109 <= nums[i] <= 109
进阶:尝试设计时间复杂度为 O(n)、空间复杂度为 O(1)的算法解决此问题。
解法1:投票法

class Solution {
public:
vector<int> majorityElement(vector<int>& nums) {
vector<int> res;
int cand1 = 0, cnt1 = 0;
int cand2 = 0, cnt2 = 0;
for(int num:nums){
if(cnt1 > 0 && cand1 == num){
cnt1++;
}else if(cnt2 > 0 && cand2 == num){
cnt2++;
}else if(cnt1 == 0){
cand1 = num;
cnt1 = 1;
}else if(cnt2 == 0){
cand2 = num;
cnt2 = 1;
}else{
cnt1--;
cnt2--;
}
}
//再次统计两个候选者的总票数
cnt1 = cnt2 = 0;
for(int num:nums){
if(cand1 == num) cnt1++;
else if(cand2 == num) cnt2++;
}
if(cnt1 > int(nums.size() / 3)) res.push_back(cand1);
if(cnt2 > int(nums.size() / 3)) res.push_back(cand2);
return res;
}
};
240. 搜索二维矩阵 II
编写一个高效的算法来搜索 m x n 矩阵 matrix 中的一个目标值 target 。该矩阵具有以下特性:
每行的元素从左到右升序排列。
每列的元素从上到下升序排列。
示例 1:
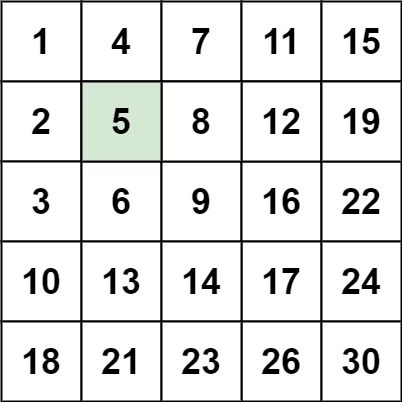
输入:matrix = [[1,4,7,11,15],[2,5,8,12,19],[3,6,9,16,22],[10,13,14,17,24],[18,21,23,26,30]], target = 5
输出:true
示例 2:
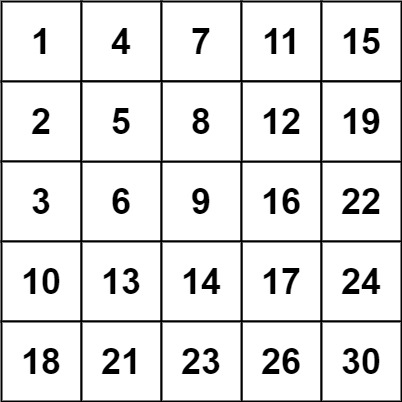
输入:matrix = [[1,4,7,11,15],[2,5,8,12,19],[3,6,9,16,22],[10,13,14,17,24],[18,21,23,26,30]], target = 20
输出:false
提示:
m == matrix.length
n == matrix[i].length
1 <= n, m <= 300
-109 <= matrix[i][j] <= 109
每行的所有元素从左到右升序排列
每列的所有元素从上到下升序排列
-109 <= target <= 109
解法1:模拟二叉搜索树
从右上角看是一颗二叉搜索树
class Solution {
public:
bool searchMatrix(vector<vector<int>>& matrix, int target) {
int m = matrix.size(), n = matrix[0].size();
int row = 0, col = n-1;
while(row < m && col >= 0){
int x = matrix[row][col];
if(x == target) return true;
else if( x < target) row++;
else col--;
}
return false;
}
};
152. 乘积最大子数组
力扣链接
给你一个整数数组 nums ,请你找出数组中乘积最大的非空连续子数组(该子数组中至少包含一个数字),并返回该子数组所对应的乘积。
测试用例的答案是一个 32-位 整数。
子数组 是数组的连续子序列。
示例 1:
输入: nums = [2,3,-2,4]
输出: 6
解释: 子数组 [2,3] 有最大乘积 6。
示例 2:
输入: nums = [-2,0,-1]
输出: 0
解释: 结果不能为 2, 因为 [-2,-1] 不是子数组。
提示:
1 <= nums.length <= 2 * 104
-10 <= nums[i] <= 10
nums 的任何前缀或后缀的乘积都 保证 是一个 32-位 整数
解法1:
思路:
C++,数组,我觉得不算动态规划。
这个题目感觉不像动态规划,更像“最大子列和”的那种“在线处理”的解法。
如果之前有理解过“在线处理”算法的话,就能比较容易地解出这道题了。
首先假设存在某个最大乘积,然后对数组遍历,在经过每个元素的时候,有以下四种情况:
如果该元素为正数:
- 如果到上一个元素为止的最大乘积也是正数,那么直接乘上就好了,同样的最大乘积也会变得更大
- 如果到上一个元素为止的最大乘积是负数,那么最大乘积就会变成该元素本身,且连续性被断掉
如果该元素为负数: - 如果到上一个元素为止的最大乘积也是负数,那么直接乘上就好了,同样的最大乘积也会变得更大
- 如果到上一个元素为止的最大乘积是正数,那么最大乘积就会不变,且连续性被断掉
以上四种情况中说到的最大乘积都是临时最大乘积,每遍历新的元素都需要进行比较来确定真正的最大乘积。
如果细心的话就可以发现,如果要得到乘以当前元素以后的最大乘积,需要记录最大乘积,也要记录最小乘积,因为最小值可能翻身变最大值。
代码:
class Solution {
public:
int maxProduct(vector<int>& nums) {
int n = nums.size();
int max_v = nums[0], min_v = nums[0], res = nums[0];
for(int i = 1;i<n;i++){
int max_tmp = max_v, min_tmp = min_v;
max_v = max(max_tmp*nums[i],max(min_tmp*nums[i],nums[i]));
min_v = min(max_tmp*nums[i],min(min_tmp*nums[i],nums[i]));
res = max(res,max_v);
}
return res;
}
};
解法2:动态规划
class Solution {
public:
int maxProduct(vector<int>& nums) {
//动态规划
int n = nums.size();
vector<int> maxDp(nums), minDp(nums);
int res = nums[0];
for(int i = 1;i<n;i++){
maxDp[i] = max(maxDp[i-1]*nums[i],max(minDp[i-1]*nums[i],nums[i]));
minDp[i] = min(maxDp[i-1]*nums[i],min(minDp[i-1]*nums[i],nums[i]));
res = max(res,maxDp[i]);
}
return res;
}
};
贪心算法
134. 加油站
力扣链接
在一条环路上有 n 个加油站,其中第 i 个加油站有汽油 gas[i] 升。
你有一辆油箱容量无限的的汽车,从第 i 个加油站开往第 i+1 个加油站需要消耗汽油 cost[i] 升。你从其中的一个加油站出发,开始时油箱为空。
给定两个整数数组 gas 和 cost ,如果你可以绕环路行驶一周,则返回出发时加油站的编号,否则返回 -1 。如果存在解,则 保证 它是 唯一 的。
示例 1:
输入: gas = [1,2,3,4,5], cost = [3,4,5,1,2]
输出: 3
解释:
从 3 号加油站(索引为 3 处)出发,可获得 4 升汽油。此时油箱有 = 0 + 4 = 4 升汽油
开往 4 号加油站,此时油箱有 4 - 1 + 5 = 8 升汽油
开往 0 号加油站,此时油箱有 8 - 2 + 1 = 7 升汽油
开往 1 号加油站,此时油箱有 7 - 3 + 2 = 6 升汽油
开往 2 号加油站,此时油箱有 6 - 4 + 3 = 5 升汽油
开往 3 号加油站,你需要消耗 5 升汽油,正好足够你返回到 3 号加油站。
因此,3 可为起始索引。
示例 2:
输入: gas = [2,3,4], cost = [3,4,3]
输出: -1
解释:
你不能从 0 号或 1 号加油站出发,因为没有足够的汽油可以让你行驶到下一个加油站。
我们从 2 号加油站出发,可以获得 4 升汽油。 此时油箱有 = 0 + 4 = 4 升汽油
开往 0 号加油站,此时油箱有 4 - 3 + 2 = 3 升汽油
开往 1 号加油站,此时油箱有 3 - 3 + 3 = 3 升汽油
你无法返回 2 号加油站,因为返程需要消耗 4 升汽油,但是你的油箱只有 3 升汽油。
因此,无论怎样,你都不可能绕环路行驶一周。
提示:
gas.length == n
cost.length == n
1 <= n <= 105
0 <= gas[i], cost[i] <= 104
解法1:贪心
思路:
首先如果总油量减去总消耗大于等于零那么一定可以跑完一圈,说明 各个站点的加油站 剩油量rest[i]相加一定是大于等于零的。
每个加油站的剩余量rest[i]为gas[i] - cost[i]。
i从0开始累加rest[i],和记为curSum,一旦curSum小于零,说明[0, i]区间都不能作为起始位置,起始位置从i+1算起,再从0计算curSum。
如图:
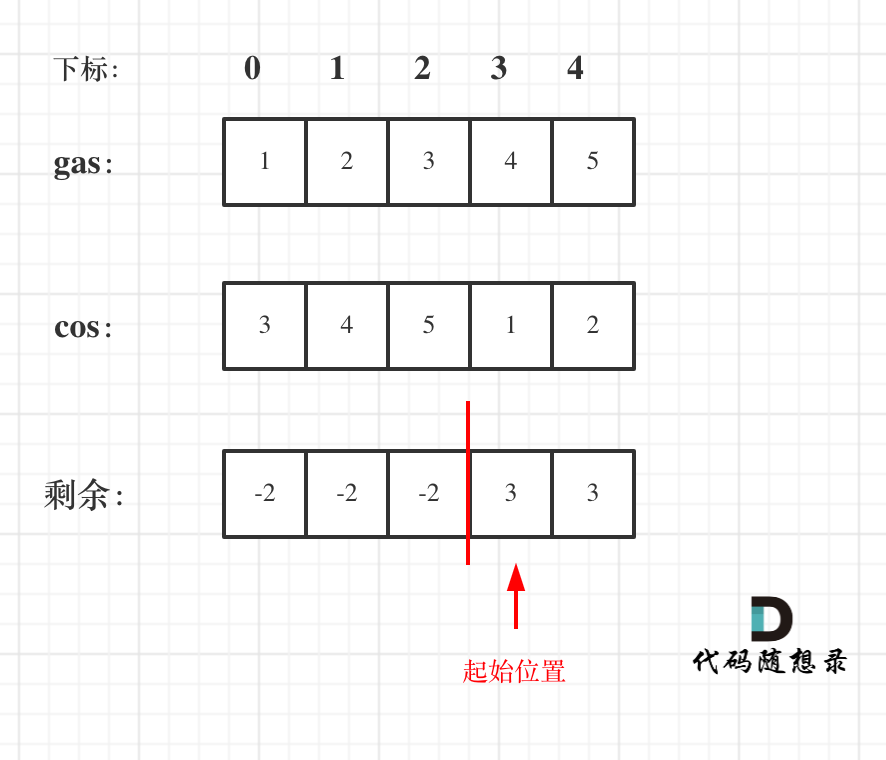
那么为什么一旦[i,j] 区间和为负数,起始位置就可以是j+1呢,j+1后面就不会出现更大的负数?
如果出现更大的负数,就是更新j,那么起始位置又变成新的j+1了。
而且j之前出现了多少负数,j后面就会出现多少正数,因为耗油总和是大于零的(前提我们已经确定了一定可以跑完全程)。
那么局部最优:当前累加rest[j]的和curSum一旦小于0,起始位置至少要是j+1,因为从j开始一定不行。全局最优:找到可以跑一圈的起始位置。
局部最优可以推出全局最优,找不出反例,试试贪心!
代码:
class Solution {
public:
int canCompleteCircuit(vector<int>& gas, vector<int>& cost) {
int curSum = 0;
int totalSum = 0;
int start = 0;
for(int i = 0;i<gas.size();i++){
curSum += gas[i] - cost[i];
totalSum += gas[i] - cost[i];
if(curSum < 0){
start = i + 1;
curSum = 0;
}
}
if(totalSum < 0) return -1;
return start;
}
};
时间复杂度:
O
(
n
)
O(n)
O(n)
空间复杂度:
O
(
1
)
O(1)
O(1)
说这种解法为贪心算法,才是是有理有据的,因为全局最优解是根据局部最优推导出来的。
860. 柠檬水找零
力扣链接
在柠檬水摊上,每一杯柠檬水的售价为 5 美元。顾客排队购买你的产品,(按账单 bills 支付的顺序)一次购买一杯。
每位顾客只买一杯柠檬水,然后向你付 5 美元、10 美元或 20 美元。你必须给每个顾客正确找零,也就是说净交易是每位顾客向你支付 5 美元。
注意,一开始你手头没有任何零钱。
给你一个整数数组 bills ,其中 bills[i] 是第 i 位顾客付的账。如果你能给每位顾客正确找零,返回 true ,否则返回 false 。
示例 1:
输入:bills = [5,5,5,10,20]
输出:true
解释:
前 3 位顾客那里,我们按顺序收取 3 张 5 美元的钞票。
第 4 位顾客那里,我们收取一张 10 美元的钞票,并返还 5 美元。
第 5 位顾客那里,我们找还一张 10 美元的钞票和一张 5 美元的钞票。
由于所有客户都得到了正确的找零,所以我们输出 true。
示例 2:
输入:bills = [5,5,10,10,20]
输出:false
解释:
前 2 位顾客那里,我们按顺序收取 2 张 5 美元的钞票。
对于接下来的 2 位顾客,我们收取一张 10 美元的钞票,然后返还 5 美元。
对于最后一位顾客,我们无法退回 15 美元,因为我们现在只有两张 10 美元的钞票。
由于不是每位顾客都得到了正确的找零,所以答案是 false。
提示:
1 <= bills.length <= 105
bills[i] 不是 5 就是 10 或是 20
解法1:贪心
思路:

代码:
class Solution {
public:
bool lemonadeChange(vector<int>& bills) {
int five = 0, ten = 0, twenty = 0;
for(int bill:bills){
if(bill == 5){
five++;
}else if(bill == 10){
if(five <= 0) return false;
ten++;
five--;
}else if(bill == 20){
if(ten > 0 && five > 0){
twenty++;
ten--;
five--;
}else if(five >= 3){
twenty++;
five -= 3;
}else{
return false;
}
}
}
return true;
}
};
135. 分发糖果
力扣链接
n 个孩子站成一排。给你一个整数数组 ratings 表示每个孩子的评分。
你需要按照以下要求,给这些孩子分发糖果:
每个孩子至少分配到 1 个糖果。
相邻两个孩子评分更高的孩子会获得更多的糖果。
请你给每个孩子分发糖果,计算并返回需要准备的 最少糖果数目 。
示例 1:
输入:ratings = [1,0,2]
输出:5
解释:你可以分别给第一个、第二个、第三个孩子分发 2、1、2 颗糖果。
示例 2:
输入:ratings = [1,2,2]
输出:4
解释:你可以分别给第一个、第二个、第三个孩子分发 1、2、1 颗糖果。
第三个孩子只得到 1 颗糖果,这满足题面中的两个条件。
提示:
n == ratings.length
1 <= n <= 2 * 104
0 <= ratings[i] <= 2 * 104
解法1:贪心
思路:
这在leetcode上是一道困难的题目,其难点就在于贪心的策略,如果在考虑局部的时候想两边兼顾,就会顾此失彼。
那么本题我采用了两次贪心的策略:
- 一次是从左到右遍历,只比较右边孩子评分比左边大的情况。
- 一次是从右到左遍历,只比较左边孩子评分比右边大的情况。
这样从局部最优推出了全局最优,即:相邻的孩子中,评分高的孩子获得更多的糖果
代码:
class Solution {
public:
int candy(vector<int>& ratings) {
vector<int> candyVec(ratings.size(), 1);
// 从前向后
for (int i = 1; i < ratings.size(); i++) {
if (ratings[i] > ratings[i - 1]) candyVec[i] = candyVec[i - 1] + 1;
}
// 从后向前
for (int i = ratings.size() - 2; i >= 0; i--) {
if (ratings[i] > ratings[i + 1] ) {
candyVec[i] = max(candyVec[i], candyVec[i + 1] + 1);
}
}
// 统计结果
int result = 0;
for (int i = 0; i < candyVec.size(); i++) result += candyVec[i];
return result;
}
};
452. 用最少数量的箭引爆气球
力扣链接
有一些球形气球贴在一堵用 XY 平面表示的墙面上。墙面上的气球记录在整数数组 points ,其中points[i] = [xstart, xend] 表示水平直径在 xstart 和 xend之间的气球。你不知道气球的确切 y 坐标。
一支弓箭可以沿着 x 轴从不同点 完全垂直 地射出。在坐标 x 处射出一支箭,若有一个气球的直径的开始和结束坐标为 xstart,xend, 且满足 xstart ≤ x ≤ xend,则该气球会被 引爆 。可以射出的弓箭的数量 没有限制 。 弓箭一旦被射出之后,可以无限地前进。
给你一个数组 points ,返回引爆所有气球所必须射出的 最小 弓箭数 。
示例 1:
输入:points = [[10,16],[2,8],[1,6],[7,12]]
输出:2
解释:气球可以用2支箭来爆破:
-在x = 6处射出箭,击破气球[2,8]和[1,6]。
-在x = 11处发射箭,击破气球[10,16]和[7,12]。
示例 2:
输入:points = [[1,2],[3,4],[5,6],[7,8]]
输出:4
解释:每个气球需要射出一支箭,总共需要4支箭。
示例 3:
输入:points = [[1,2],[2,3],[3,4],[4,5]]
输出:2
解释:气球可以用2支箭来爆破:
- 在x = 2处发射箭,击破气球[1,2]和[2,3]。
- 在x = 4处射出箭,击破气球[3,4]和[4,5]。
提示:
1 <= points.length <= 105
points[i].length == 2
-231 <= xstart < xend <= 231 - 1
解法1:排序+贪心
思路:
代码:
class Solution {
public:
int findMinArrowShots(vector<vector<int>>& points) {
sort(points.begin(),points.end(),[&](const vector<int>& a, const vector<int>& b){
return a[0] < b[0];
});
int cur = 1;
for(int i = 1;i<points.size();i++){
if(points[i][0] > points[i-1][1]) cur++;
else{
points[i][1] = min(points[i-1][1],points[i][1]);
}
}
return cur;
}
};

相似题目:435. 无重叠区间
力扣链接
给定一个区间的集合 intervals ,其中 intervals[i] = [starti, endi] 。返回 需要移除区间的最小数量,使剩余区间互不重叠 。
示例 1:
输入: intervals = [[1,2],[2,3],[3,4],[1,3]]
输出: 1
解释: 移除 [1,3] 后,剩下的区间没有重叠。
示例 2:
输入: intervals = [ [1,2], [1,2], [1,2] ]
输出: 2
解释: 你需要移除两个 [1,2] 来使剩下的区间没有重叠。
示例 3:
输入: intervals = [ [1,2], [2,3] ]
输出: 0
解释: 你不需要移除任何区间,因为它们已经是无重叠的了。
提示:
1 <= intervals.length <= 105
intervals[i].length == 2
-5 * 104 <= starti < endi <= 5 * 104
解法1:排序+贪心
class Solution {
public:
int eraseOverlapIntervals(vector<vector<int>>& intervals) {
sort(intervals.begin(),intervals.end(),[&](const vector<int>& a,const vector<int>& b){
return a[0] < b[0];
});
int cur = 1;
int n = intervals.size();
for(int i = 1;i<intervals.size();i++){
if(intervals[i][0] >= intervals[i-1][1]) cur++;
else{
intervals[i][1] = min(intervals[i][1],intervals[i-1][1]);//注意理解这里是min不是max
}
}
return n - cur;
}
};
56. 合并区间
以数组 intervals 表示若干个区间的集合,其中单个区间为 intervals[i] = [starti, endi] 。请你合并所有重叠的区间,并返回 一个不重叠的区间数组,该数组需恰好覆盖输入中的所有区间 。
示例 1:
输入:intervals = [[1,3],[2,6],[8,10],[15,18]]
输出:[[1,6],[8,10],[15,18]]
解释:区间 [1,3] 和 [2,6] 重叠, 将它们合并为 [1,6].
示例 2:
输入:intervals = [[1,4],[4,5]]
输出:[[1,5]]
解释:区间 [1,4] 和 [4,5] 可被视为重叠区间。
提示:
1 <= intervals.length <= 104
intervals[i].length == 2
0 <= starti <= endi <= 104
解法1:排序+贪心
class Solution {
public:
vector<vector<int>> merge(vector<vector<int>>& intervals) {
sort(intervals.begin(),intervals.end(),[&](const vector<int>& a, const vector<int>& b){
return a[0] < b[0];
});
vector<vector<int>> res;
res.push_back(intervals[0]);
for(int i = 1;i<intervals.size();i++){
if(intervals[i][0] <= res.back()[1]){
res.back()[1] = max(res.back()[1],intervals[i][1]);
}else{
res.push_back(intervals[i]);
}
}
return res;
}
};
670. 最大交换
力扣链接
给定一个非负整数,你至多可以交换一次数字中的任意两位。返回你能得到的最大值。
示例 1 :
输入: 2736
输出: 7236
解释: 交换数字2和数字7。
示例 2 :
输入: 9973
输出: 9973
解释: 不需要交换。
解法1:贪心+数学
class Solution {
public:
int maximumSwap(int num) {
string strNum = to_string(num);
int n = strNum.size();
int index = n, maxNum = -1;
vector<int> res(n,n);
for(int i = n-1;i>=0;i--){
if(strNum[i]-'0' > maxNum){
index = i;
maxNum = strNum[i]-'0';
}else if(strNum[i]-'0' < maxNum){
res[i] = index;
}
}
for(int i = 0;i<n;i++){
if(res[i] != n){
swap(strNum[i],strNum[res[i]]);
break;
}
}
return stoi(strNum);
}
};
哈希表
本段参考 代码随想录
一.什么是哈希表?
首先什么是 哈希表,哈希表(英文名字为Hash table,国内也有一些算法书籍翻译为散列表,大家看到这两个名称知道都是指hash table就可以了)。
哈希表是根据关键码的值而直接进行访问的数据结构。
这么这官方的解释可能有点懵,其实直白来讲其实数组就是一张哈希表。
哈希表中关键码就是数组的索引下表,然后通过下表直接访问数组中的元素,如下图所示:

二.哈希表能解决什么问题?
(1)一般哈希表都是用来快速判断一个元素是否出现集合里。
(2)例如要查询一个名字是否在这所学校里。要枚举的话时间复杂度是O(n),但如果使用哈希表的话, 只需要O(1) 就可以做到。
我们只需要初始化把这所学校里学生的名字都存在哈希表里,在查询的时候通过索引直接就可以知道这位同学在不在这所学校里了。
(3)将学生姓名映射到哈希表上就涉及到了hash function ,也就是哈希函数。
三.常见的三种哈希结构
当我们想使用哈希法来解决问题的时候,我们一般会选择如下三种数据结构。
数组
set (集合)
map(映射)
在C++中,set 和 map 分别提供以下三种数据结构,其底层实现以及优劣如下表所示:

(1)当我们要使用集合来解决哈希问题的时候,优先使用unordered_set,因为它的查询和增删效率是最优的,如果需要集合是有序的,那么就用set,如果要求不仅有序还要有重复数据的话,那么就用multiset。
(2)那么再来看一下map ,在map 是一个key value 的数据结构,map中,对key是有限制,对value没有限制的,因为key的存储方式使用红黑树实现的。
3. 无重复字符的最长子串
力扣链接
给定一个字符串 s ,请你找出其中不含有重复字符的 最长子串 的长度。
示例 1:
输入: s = “abcabcbb”
输出: 3
解释: 因为无重复字符的最长子串是 “abc”,所以其长度为 3。
示例 2:
输入: s = “bbbbb”
输出: 1
解释: 因为无重复字符的最长子串是 “b”,所以其长度为 1。
示例 3:
输入: s = “pwwkew”
输出: 3
解释: 因为无重复字符的最长子串是 “wke”,所以其长度为 3。
请注意,你的答案必须是 子串 的长度,“pwke” 是一个子序列,不是子串。
示例 4:
输入: s = “”
输出: 0
提示:
0 <= s.length <= 5 * 104
s 由英文字母、数字、符号和空格组成
解法1:滑动窗口+哈希表
思路:
(1)这道题主要用到思路是:滑动窗口
(2)什么是滑动窗口?
其实就是一个队列,比如例题中的 abcabcbb,进入这个队列(窗口)为 abc 满足题目要求,当再进入 a,队列变成了 abca,这时候不满足要求。所以,我们要移动这个队列!
如何移动?我们只要把队列的左边的元素移出就行了,直到满足题目要求!
一直维持这样的队列,找出队列出现最长的长度时候,求出解!
代码:
class Solution {
public:
int lengthOfLongestSubstring(string s) {
if (s.size() == 0) return 0;
unordered_set<char> uset;
int left = 0;
int count = 0;
for(int right = 0;right<s.size();right++){
while(uset.find(s[right])!=uset.end()) {
uset.erase(s[left]);
left++;
}
count = max(count,right-left+1);
uset.insert(s[right]);
}
return count;
}
};
复杂度分析:
时间复杂度:O(n)
350. 两个数组的交集 II
力扣链接
给你两个整数数组 nums1 和 nums2 ,请你以数组形式返回两数组的交集。返回结果中每个元素出现的次数,应与元素在两个数组中都出现的次数一致(如果出现次数不一致,则考虑取较小值)。可以不考虑输出结果的顺序。
示例 1:
输入:nums1 = [1,2,2,1], nums2 = [2,2]
输出:[2,2]
示例 2:
输入:nums1 = [4,9,5], nums2 = [9,4,9,8,4]
输出:[4,9]
提示:
1 <= nums1.length, nums2.length <= 1000
0 <= nums1[i], nums2[i] <= 1000
进阶:
如果给定的数组已经排好序呢?你将如何优化你的算法?
如果 nums1 的大小比 nums2 小,哪种方法更优?
如果 nums2 的元素存储在磁盘上,内存是有限的,并且你不能一次加载所有的元素到内存中,你该怎么办?
解法1:哈希表
思路:
(1)由于同一个数字在两个数组中都可能出现多次,因此需要用哈希表存储每个数字出现的次数。对于一个数字,其在交集中出现的次数等于该数字在两个数组中出现次数的最小值。
(2)首先遍历第一个数组,并在哈希表中记录第一个数组中的每个数字以及对应出现的次数,然后遍历第二个数组,对于第二个数组中的每个数字,如果在哈希表中存在这个数字,则将该数字添加到答案,并减少哈希表中该数字出现的次数。
代码:
class Solution {
public:
vector<int> intersect(vector<int>& nums1, vector<int>& nums2) {
if(nums1.size()>nums2.size()) return intersect(nums2,nums1);
unordered_map<int,int> umap;
vector<int> result;
for(auto num:nums1) umap[num]++;
for(auto num:nums2){
if(umap[num]){
result.push_back(num);
umap[num]--;
}
}
return result;
}
};
复杂度分析:
时间复杂度:O(m+n),其中 m 和 n 分别是两个数组的长度。需要遍历两个数组并对哈希表进行操作,哈希表操作的时间复杂度是 O(1),因此总时间复杂度与两个数组的长度和呈线性关系。
空间复杂度:O(min(m,n)),其中 m 和 n 分别是两个数组的长度。对较短的数组进行哈希表的操作,哈希表的大小不会超过较短的数组的长度。为返回值创建一个数组 intersection,其长度为较短的数组的长度。
解法2:排序+双指针
思路:
(1)如果两个数组是有序的,则可以使用双指针的方法得到两个数组的交集。
(2)首先对两个数组进行排序,然后使用两个指针遍历两个数组。
(3)初始时,两个指针分别指向两个数组的头部。每次比较两个指针指向的两个数组中的数字,如果两个数字不相等,则将指向较小数字的指针右移一位,如果两个数字相等,将该数字添加到答案,并将两个指针都右移一位。当至少有一个指针超出数组范围时,遍历结束。
代码:
class Solution {
public:
vector<int> intersect(vector<int>& nums1, vector<int>& nums2) {
//排序+双指针
sort(nums1.begin(),nums1.end());
sort(nums2.begin(),nums2.end());
vector<int> result;
int ptr1=0,ptr2=0;
while(ptr1<nums1.size() && ptr2<nums2.size()){
if(nums1[ptr1] < nums2[ptr2]) ptr1++;
else if(nums1[ptr1] > nums2[ptr2]) ptr2++;
else{
result.push_back(nums1[ptr1]);
ptr1++;
ptr2++;
}
}
return result;
}
};
复杂度分析:
时间复杂度:O(mlogm+nlogn),其中 m 和 n 分别是两个数组的长度。对两个数组进行排序的时间复杂度是 O(mlogm+nlogn),遍历两个数组的时间复杂度是 O(m+n),因此总时间复杂度是O(mlogm+nlogn)。
空间复杂度:O(1)。

总结:
如果nums 2的元素存储在磁盘上,磁盘内存是有限的,并且你不能一次加载所有的元素到内存中。那么就无法高效地对 nums2进行排序,因此推荐使用方法一而不是方法二。在方法一中,nums2只关系到查询操作,因此每次读取 nums2中的一部分数据,并进行处理即可。
187. 重复的DNA序列
所有 DNA 都由一系列缩写为 ‘A’,‘C’,‘G’ 和 ‘T’ 的核苷酸组成,例如:“ACGAATTCCG”。在研究 DNA 时,识别 DNA 中的重复序列有时会对研究非常有帮助。
编写一个函数来找出所有目标子串,目标子串的长度为 10,且在 DNA 字符串 s 中出现次数超过一次。
示例 1:
输入:s = “AAAAACCCCCAAAAACCCCCCAAAAAGGGTTT”
输出:[“AAAAACCCCC”,“CCCCCAAAAA”]
示例 2:
输入:s = “AAAAAAAAAAAAA”
输出:[“AAAAAAAAAA”]
提示:
0 <= s.length <= 105
s[i] 为 ‘A’、‘C’、‘G’ 或 ‘T’
解法1:哈希表+滑动窗口
思路:
我们可以用一个哈希表统计 ss 所有长度为 10 的子串的出现次数,返回所有出现次数超过10 的子串。
代码实现时,可以一边遍历子串一边记录答案,为了不重复记录答案,我们只统计当前出现次数为 2 的子串。
代码:
class Solution {
public:
vector<string> findRepeatedDnaSequences(string s) {
int n = s.size();
unordered_map<string, int> umap;
vector<string> result;
if(n<10) return {};
for(int i = 0;i<n-10+1;i++){
string strTemp = s.substr(i,10);
if(++umap[strTemp] == 2) result.push_back(strTemp);
}
return result;
}
};
class Solution {
public:
vector<string> findRepeatedDnaSequences(string s) {
int n = s.size();
unordered_map<string, int> umap;
vector<string> result;
if(n<10) return {};
for(int i = 0;i<n-10+1;i++){
string strTemp = s.substr(i,10);
umap[strTemp]++;
}
for(auto it = umap.begin();it != umap.end();it++){
if(it->second > 1) result.push_back(it->first);
}
return result;
}
};
复杂度分析:
时间复杂度:O(NL),其中 N 是字符串s 的长度,L=10 即目标子串的长度。
空间复杂度:O(NL)
1044. 最长重复子串
力扣链接
给你一个字符串 s ,考虑其所有 重复子串 :即,s 的连续子串,在 s 中出现 2 次或更多次。这些出现之间可能存在重叠。
返回 任意一个 可能具有最长长度的重复子串。如果 s 不含重复子串,那么答案为 “” 。
示例 1:
输入:s = “banana”
输出:“ana”
示例 2:
输入:s = “abcd”
输出:“”
提示:
2 <= s.length <= 3 * 104
s 由小写英文字母组成
解法1:字符串哈希
思路:
(1)
(2)

(3)Q:字符串哈希法里的s[i…j]这段字符串的哈希值为什么可以由 h[j]-h[i-i]*p[j-i+1] 求得?h 数组和 p 数组都是做什么的?
A:假设你要将字符串 abcd hash化成十进制的数
则 a = 1,ab = 12,abc=123,abcd = 1234
现在要求bcd 即abcd[1,3]的哈希值,是不是1234-1000(等价于 1234-1*10^3)在计算的过程中我们会另外开一个乘方数组记录某一个位置的位数即p数组,上述情况p[0]=1,p[1]=10,p[2]=100,p[3]=1000即hash(bcd)=hash(abcd)-hash(a)*p[3-1+1]
代码:
class Solution {
public:
vector<unsigned long long> hash;
vector<unsigned long long> p;
string longestDupSubstring(string s) {
int hash_key = 1313131;
int n = s.size();
hash.resize(n+1);
p.resize(n+1);
p[0] = 1;
for(int i = 0;i<n;i++){
p[i+1] = p[i]*hash_key;
hash[i+1] = hash[i]*hash_key + s[i];
}
string result;
int l = 0;
int r = n;
while(l<r){
int mid = l+(r-l+1)/2;
string t = check(s,mid);
if(t.size()!=0) l = mid;
else r = mid -1;
result = t.size() > result.size() ? t:result;
}
return result;
}
string check(string& s, int Len){
int n = s.size();
unordered_set<unsigned long long> mySet;
for(int i = 1;i+Len-1<=n;i++){
int j = i+Len-1;
unsigned long long cur = hash[j] - hash[i-1]*p[j-i+1];
if(mySet.count(cur)) return s.substr(i-1,Len);
mySet.insert(cur);
}
return "";
}
};
复杂度分析:
时间复杂度:令 n 为字符串 s 的长度,预处理出哈希数组的复杂度为 O(n);二分最大长度的复杂度为 O(nlogn);整体复杂度为O(nlogn)
空间复杂度:O(n)
解法2:滑动窗口(超时)
class Solution {
public:
string longestDupSubstring(string s) {
string result;
int max_len = 0;
int start = 0;
int end = 1;
int n = s.size();
# 每次看s[start:end]在之后s[start+1:]是否也出现,因为在s[start:]肯定出现一次,所以总共出现次数>=2
# 出现的话,更新max_len,同时end后移,看更长的是否满足
# 不出现的话,表明以start开头的子串不可能出现>=2次,start后移
。
while(end < n){
string str = s.substr(start,end-start);
string sNext = s.substr(start+1,n-start-1);
# 判断子串出现至少两次
if (s.find(str) != s.npos && sNext.find(str) != sNext.npos){
if(max_len < end-start){
max_len = end-start;
result = str;
}
end++;
continue;
}
start++;
}
return result;
}
};
1995. 统计特殊四元组
力扣链接
给你一个 下标从 0 开始 的整数数组 nums ,返回满足下述条件的 不同 四元组 (a, b, c, d) 的 数目 :
nums[a] + nums[b] + nums[c] == nums[d] ,且
a < b < c < d
示例 1:
输入:nums = [1,2,3,6]
输出:1
解释:满足要求的唯一一个四元组是 (0, 1, 2, 3) 因为 1 + 2 + 3 == 6 。
示例 2:
输入:nums = [3,3,6,4,5]
输出:0
解释:[3,3,6,4,5] 中不存在满足要求的四元组。
示例 3:
输入:nums = [1,1,1,3,5]
输出:4
解释:满足要求的 4 个四元组如下:
- (0, 1, 2, 3): 1 + 1 + 1 == 3
- (0, 1, 3, 4): 1 + 1 + 3 == 5
- (0, 2, 3, 4): 1 + 1 + 3 == 5
- (1, 2, 3, 4): 1 + 1 + 3 == 5
提示:
4 <= nums.length <= 50
1 <= nums[i] <= 100
解法1:哈希表
思路:

代码:
class Solution {
public:
int countQuadruplets(vector<int>& nums) {
unordered_map<int, int> umap;
int result = 0;
for(int b = nums.size()-3;b>0;b--){
for(int d=nums.size()-1;d>=b+2;d--){
umap[nums[d]-nums[b+1]]++;
}
for(int a=0;a<b;a++){
result+=umap[nums[b]+nums[a]];
}
}
return result;
}
};
复杂度分析:
时间复杂度:O(n^2)
空间复杂度:O©
846. 一手顺子
力扣链接
Alice 手中有一把牌,她想要重新排列这些牌,分成若干组,使每一组的牌数都是 groupSize ,并且由 groupSize 张连续的牌组成。
给你一个整数数组 hand 其中 hand[i] 是写在第 i 张牌,和一个整数 groupSize 。如果她可能重新排列这些牌,返回 true ;否则,返回 false 。
示例 1:
输入:hand = [1,2,3,6,2,3,4,7,8], groupSize = 3
输出:true
解释:Alice 手中的牌可以被重新排列为 [1,2,3],[2,3,4],[6,7,8]。
示例 2:
输入:hand = [1,2,3,4,5], groupSize = 4
输出:false
解释:Alice 手中的牌无法被重新排列成几个大小为 4 的组。
提示:
1 <= hand.length <= 104
0 <= hand[i] <= 109
1 <= groupSize <= hand.length
解法1:哈希表+排序
思路:

代码:
class Solution {
public:
bool isNStraightHand(vector<int>& hand, int groupSize) {
if(hand.size() % groupSize != 0 ) return false;
sort(hand.begin(),hand.end());
unordered_map<int,int> hash;
for(int &n:hand){
hash[n]++;
}
for(int i = 0;i<hand.size();i++){
if(hash[hand[i]] == 0) continue;
//else{
for(int j = 0;j<groupSize;j++){
if(hash[hand[i]+j]==0) return false;
hash[hand[i]+j]--;
}
//for(int j = 0;j<groupSize;j++){
//hash[hand[i]+j]--;
//}
//}
}
return true;
}
};

2013. 检测正方形
力扣链接
给你一个在 X-Y 平面上的点构成的数据流。设计一个满足下述要求的算法:
添加 一个在数据流中的新点到某个数据结构中。可以添加 重复 的点,并会视作不同的点进行处理。
给你一个查询点,请你从数据结构中选出三个点,使这三个点和查询点一同构成一个 面积为正 的 轴对齐正方形 ,统计 满足该要求的方案数目。
轴对齐正方形 是一个正方形,除四条边长度相同外,还满足每条边都与 x-轴 或 y-轴 平行或垂直。
实现 DetectSquares 类:
DetectSquares() 使用空数据结构初始化对象
void add(int[] point) 向数据结构添加一个新的点 point = [x, y]
int count(int[] point) 统计按上述方式与点 point = [x, y] 共同构造 轴对齐正方形 的方案数。
示例:

输入:
[“DetectSquares”, “add”, “add”, “add”, “count”, “count”, “add”, “count”]
[[], [[3, 10]], [[11, 2]], [[3, 2]], [[11, 10]], [[14, 8]], [[11, 2]], [[11, 10]]]
输出:
[null, null, null, null, 1, 0, null, 2]
解释:
DetectSquares detectSquares = new DetectSquares();
detectSquares.add([3, 10]);
detectSquares.add([11, 2]);
detectSquares.add([3, 2]);
detectSquares.count([11, 10]); // 返回 1 。你可以选择:
// - 第一个,第二个,和第三个点
detectSquares.count([14, 8]); // 返回 0 。查询点无法与数据结构中的这些点构成正方形。
detectSquares.add([11, 2]); // 允许添加重复的点。
detectSquares.count([11, 10]); // 返回 2 。你可以选择:
// - 第一个,第二个,和第三个点
// - 第一个,第三个,和第四个点
提示:
point.length == 2
0 <= x, y <= 1000
调用 add 和 count 的 总次数 最多为 5000
解法1:哈希表
思路:
先考虑如何实现 int count(int[] point),记输入的 point 的横纵坐标分别为 x和 y。则形成的正方形的上下两条边中,其中一条边的纵坐标为 y, 我们枚举另一条边的纵坐标为 col,则正方形的边长 d 为 |y - col| 且大于 0。有了其中一个点的坐标 (x, y) 和一条横边的纵坐标 col,我们可以得到正方形的四个点的坐标分别为 (x,y),(x,col),(x+d, y),(x+d,col) 或 (x,y),(x, col),(x-d, y),(x-d, col)。
据此,我们可以用一个哈希表来存储 void add(int[] point) 函数中加入的点。先把点按照行来划分,键为行的纵坐标,值为另一个哈希表,其中键为该行中的点的横坐标,值为这样的点的个数。因为点会重复出现,所以计算正方形的个数时需要把另外三个坐标出现的次数相乘。

代码:
class DetectSquares {
public:
unordered_map<int,unordered_map<int,int>> counts;//x->(y,count)
DetectSquares() {
}
void add(vector<int> point) {
int x = point[0], y = point[1];
counts[x][y]++;
}
int count(vector<int> point) {
int result = 0;
int x = point[0], y = point[1];
if(counts.count(x)){
for(auto& [ny,c]:counts[x]){
int d = ny - y;
if(!d) continue;
if(counts.count(x+d) && counts[x+d].count(y) && counts[x+d].count(ny))
result += c*counts[x+d][y]*counts[x+d][ny];
if(counts.count(x-d) && counts[x-d].count(y) && counts[x-d].count(ny))
result += c*counts[x-d][y]*counts[x-d][ny];
}
}
return result;
}
};
/**
* Your DetectSquares object will be instantiated and called as such:
* DetectSquares* obj = new DetectSquares();
* obj->add(point);
* int param_2 = obj->count(point);
*/

128. 最长连续序列
力扣链接
给定一个未排序的整数数组 nums ,找出数字连续的最长序列(不要求序列元素在原数组中连续)的长度。
请你设计并实现时间复杂度为 O(n) 的算法解决此问题。
示例 1:
输入:nums = [100,4,200,1,3,2]
输出:4
解释:最长数字连续序列是 [1, 2, 3, 4]。它的长度为 4。
示例 2:
输入:nums = [0,3,7,2,5,8,4,6,0,1]
输出:9
提示:
0 <= nums.length <= 105
-109 <= nums[i] <= 109
解法1:哈希表
思路:
题目要求 O(n) 复杂度。
- 用哈希表存储每个端点值对应连续区间的长度
- 若数已在哈希表中:跳过不做处理
- 若是新数加入:
3.1. 取出其左右相邻数已有的连续区间长度 left 和 right
3.2. 计算当前数的区间长度为:cur_length = left + right + 1
3.3. 根据 cur_length 更新最大长度 max_length 的值
3.4. 更新区间两端点的长度值
代码:
class Solution {
public:
int longestConsecutive(vector<int>& nums) {
unordered_map<int,int> umap;//端点 - 对应连续长度
int leftLen, rightLen , res=0;
for(auto& num:nums){
if(!umap[num]){
leftLen = umap.count(num-1) ? umap[num-1] : 0;
rightLen = umap.count(num+1) ? umap[num+1] : 0;
res = max(res,leftLen + 1 + rightLen);
umap[num] = leftLen + 1 + rightLen;
umap[num - leftLen] = leftLen + 1 + rightLen;
umap[num + rightLen] = leftLen + 1 + rightLen;
}
}
return res;
}
};

560. 和为 K 的子数组
力扣链接
给你一个整数数组 nums 和一个整数 k ,请你统计并返回 该数组中和为 k 的子数组的个数 。
示例 1:
输入:nums = [1,1,1], k = 2
输出:2
示例 2:
输入:nums = [1,2,3], k = 3
输出:2
提示:
1 <= nums.length <= 2 * 104
-1000 <= nums[i] <= 1000
-107 <= k <= 107
解法1:前缀和+哈希表
class Solution {
public:
int subarraySum(vector<int>& nums, int k) {
vector<int> sumArr(nums.size()+1,0);//记录前缀和的数组
int sum= 0;
for (int i = 0;i<nums.size();i++){
sumArr[i+1] = sumArr[i] + nums[i];
}
unordered_map<int,int> sumArrMap;//key为前缀和,value为次数
int result = 0;
sumArrMap[0] = 1;
for (int i = 0;i<nums.size();i++){//[j,i]区间的前缀和为k,sumArr[i+1]-sumArr[j] = k
if(sumArrMap.find(sumArr[i+1] - k) != sumArrMap.end()){
result+=sumArrMap[sumArr[i+1] - k];
}
sumArrMap[sumArr[i+1]]++;
}
return result;
}
};


















 243
243











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











