







量子计算有望成为解决AI算力瓶颈的颠覆性力量。与传统计算相比,量子计算能够带来更强的并行计算能力和更低的能耗,同时量子计算的运算能力根据量子比特数量指数级增长,在AI领域具有较大潜力。海外科技巨头带动量子计算产业发展,IBM、微软、谷歌等公司先后发布量子计算路线图,与此同时,国内量子计算产业与海外科技巨头差距不断缩小。
量子计算软硬件基础设施不断成熟,为商业化落地打下良好基础。当前全球范围内针对量子计算机,已经形成超导、离子阱、光量子、中性原子、半导体量子等主要技术路线,以及以量子门数量、量子体积、量子比特数量等核心指标构成的性能评价体系。
量子计算云平台将量子计算机硬件或量子计算模拟器与经典云计算软件工具、通信设备及 IT 基础设施相结合,为用户提供直观化及实例化的量子计算接入访问与算力服务。软件方面,量子算法不断发展中,在当前硬件条件下重点是综合考虑NISQ算法的容错代价与算法性能之间的平衡,量子软件体系处于开放研发和生态建设早期阶段,正在不断成熟。
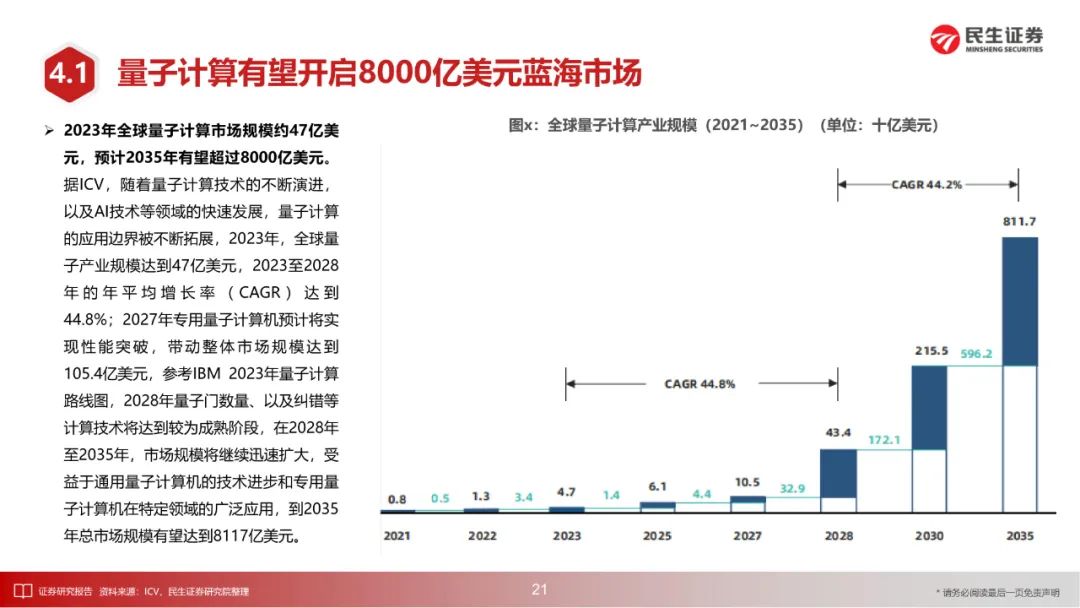
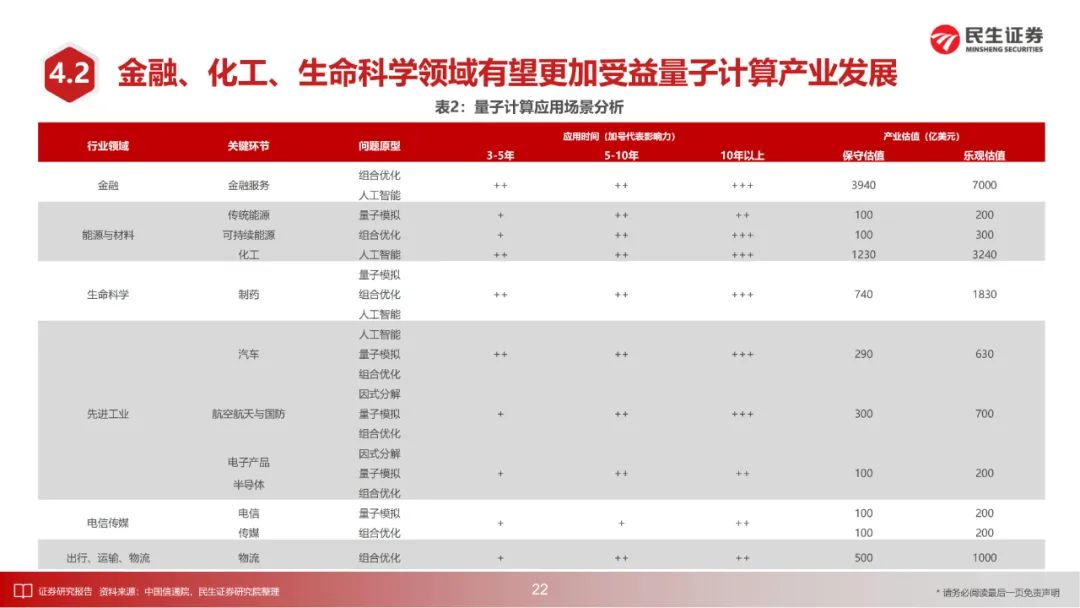
据ICV数据,2023年全球量子计算市场规模约47亿美元,预计2035年有望超过8000亿美元;其中,金融、化工、生命科学领域有望更加受益量子计算产业发展。


























 2273
2273

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









