









Selenium + Pytest + Allure 自动化测试框架实战
在阅读本文时,大家首先要掌握 python 、pytest 、selenium基础相关
项目目录简介
├───common # 公共模块
├───config # 常用的系统配置
├───data # 用于存储数据驱动是的数据
├───logs # 日志记录
├───page # selenium 封装
├───page_element # 页面元素数据配置
├───page_object # 需要测试的测试类封装
├───report # 生成的报告路径
├───script # 其他常用脚本
├───testcase # 测试的case
│ ├───interface # 接口相关
│ ├───webui # web自动化相关
├───utils # 常用工具类
├───requriment.txt # 项目相关依赖
├───pytest.ini # pytest 只配置
├───main.py # 启动类
logger 相关
主要用于日志生成,以及写入到校验报告中
import logging
from config.conf import cm
class Logger(object):
def __init__(self):
self.log_name = cm.log_file
self.logger = logging.getLogger("log")
self.logger.setLevel(logging.DEBUG)
self.formater = logging.Formatter('[%(asctime)s][%(filename)s %(lineno)d][%(levelname)s]: %(message)s')
self.filelogger = logging.FileHandler(self.log_name, mode='a', encoding="UTF-8")
self.console = logging.StreamHandler()
self.console.setLevel(logging.INFO)
self.filelogger.setLevel(logging.DEBUG)
self.filelogger.setFormatter(self.formater)
self.console.setFormatter(self.formater)
self.logger.addHandler(self.filelogger)
self.logger.addHandler(self.console)
log = Logger().logger
读取页面元素
import os
import yaml
from config.conf import cm
class Element(object):
"""获取元素"""
def __init__(self, name):
self.file_name = '%s.yaml' % name
self.element_path = os.path.join(cm.ELEMENT_PATH, self.file_name)
if not os.path.exists(self.element_path):
raise FileNotFoundError("%s 文件不存在!" % self.element_path)
with open(self.element_path, encoding='utf-8') as f:
self.data = yaml.safe_load(f)
def __getitem__(self, item):
"""获取属性"""
data = self.data.get(item)
if data:
name, value = data.split('==')
return name, value
raise ArithmeticError("{}中不存在关键字:{}".format(self.file_name, item))
if __name__ == '__main__':
search = Element('demo')
print(search['inputelment'])
seleniume 封装
seleniume 本身使用就很简便,那么为什么封装?
首先我们上述这种较为原始的方法,基本不适用于平时做UI自动化测试的,因为在UI界面实际运行情况远远比较复杂,可能因为网络原因,或者控件原因,我们元素还没有显示出来,就进行点击或者输入。所以我们需要封装selenium方法,通过内置的显式等待或一定的条件语句,才能构建一个稳定的方法。而且把selenium方法封装起来,有利于平时的代码维护。
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from common.logger import log
from config.conf import cm
from utils.times import sleep
class WebPage(object):
"""selenium基类"""
def __init__(self, driver):
# self.driver = webdriver.Chrome()
self.driver = driver
self.timeout = 20
self.wait = WebDriverWait(self.driver, self.timeout)
def get_url(self, url):
"""打开网址并验证"""
self.driver.maximize_window()
self.driver.set_page_load_timeout(60)
try:
self.driver.get(url)
self.driver.implicitly_wait(10)
log.info("打开网页:%s" % url)
except TimeoutException:
raise TimeoutException("打开%s超时请检查网络或网址服务器" % url)
@staticmethod
def element_locator(func, locator):
"""元素定位器"""
name, value = locator
return func(cm.LOCATE_MODE[name], value)
def find_element(self, locator):
"""寻找单个元素"""
return WebPage.element_locator(lambda *args: self.wait.until(
EC.presence_of_element_located(args)), locator)
def find_elements(self, locator):
"""查找多个相同的元素"""
return WebPage.element_locator(lambda *args: self.wait.until(
EC.presence_of_all_elements_located(args)), locator)
def elements_num(self, locator):
"""获取相同元素的个数"""
number = len(self.find_elements(locator))
log.info("相同元素:{}".format((locator, number)))
return number
def input_text(self, locator, txt):
"""输入(输入前先清空)"""
sleep(0.5)
ele = self.find_element(locator)
ele.clear()
ele.send_keys(txt)
log.info("输入文本:{}".format(txt))
def is_click(self, locator):
"""点击"""
self.find_element(locator).click()
sleep()
log.info("点击元素:{}".format(locator))
def element_text(self, locator):
"""获取当前的text"""
_text = self.find_element(locator).text
log.info("获取文本:{}".format(_text))
return _text
@property
def get_source(self):
"""获取页面源代码"""
return self.driver.page_source
def refresh(self):
"""刷新页面F5"""
self.driver.refresh()
self.driver.implicitly_wait(30)
基于POM模式去test
关于什么 POM 模式 大家可以参考 https://www.cnblogs.com/lym51/p/6646033.html
POM是 Page Object Model 的简写,其实简单的说,就是面向对象的封装,让代码解耦,方便维护与扩展!
这里我们以测试百度的首页搜索为案例:
搜索页面
from common.readelement import Element
from page.webpage import WebPage
search = Element('demo/demo')
class SearchPage(WebPage):
"""搜索类"""
def input_search(self, content):
"""输入搜索"""
self.input_text(search['inputelment'], txt=content)
def click_search(self):
"""点击搜索"""
self.is_click(search['click_search'])
SearchPage 继承了 WebPage 具有了错做浏览器的全部方法,Element 为我们提供了搜索所需的页面元素
测试页面功能
本测试案例围绕在百度搜素里进行搜索 selenium
- 页面搜索结果是否包含输入的内容
- 如果搜索结果是否包含指定对比的内容,如果包含,进行截图显示
import re
import allure
import pytest
from common.logger import log
from page_object.demo.baidu_test import SearchPage
from utils.load_yaml import read_config_file
url = read_config_file("base", "url")
@allure.feature("测试项目")
class TestSearch:
@pytest.fixture(scope='function', autouse=True)
def open_baidu(self, drivers):
"""打开百度"""
search = SearchPage(drivers)
with allure.step("step1:打开登录首页"):
search.get_url(url)
@allure.title("第一个测试用例")
def test_001(self, drivers):
"""搜索"""
search = SearchPage(drivers)
with allure.step("step2:输入搜索内容"):
search.input_search("selenium")
with allure.step("step3:确认搜素"):
search.click_search()
with allure.step("step4:获取反回值"):
result = re.search(r'selenium', search.get_source)
log.info("页面返回值 %s" % result)
assert result
@allure.title("测试失败后截图的操作")
def test_002(self, drivers):
"""搜索"""
search = SearchPage(drivers)
with allure.step("step2:输入搜索内容"):
search.input_search("selenium")
with allure.step("step3:确认搜素"):
search.click_search()
with allure.step("step4:获取反回值"):
result = re.search(r'Java有货交流群,联系小编', search.get_source)
log.info("页面返回值 %s" % result)
assert result
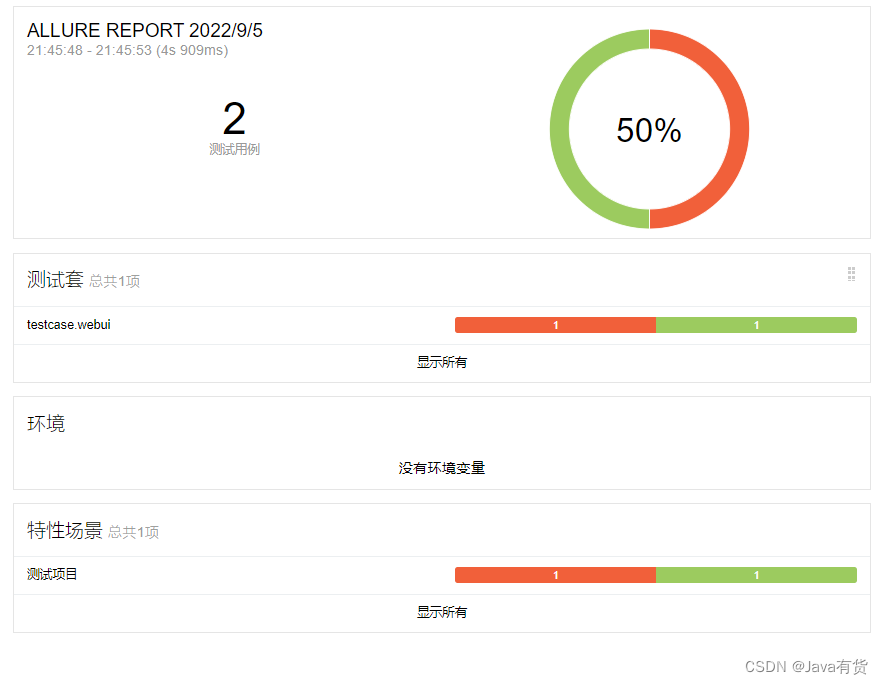
校验报告
本文采用了allure校验报告,这里就不多做介绍了,我们打开上一步结果生成的校验报告!!!
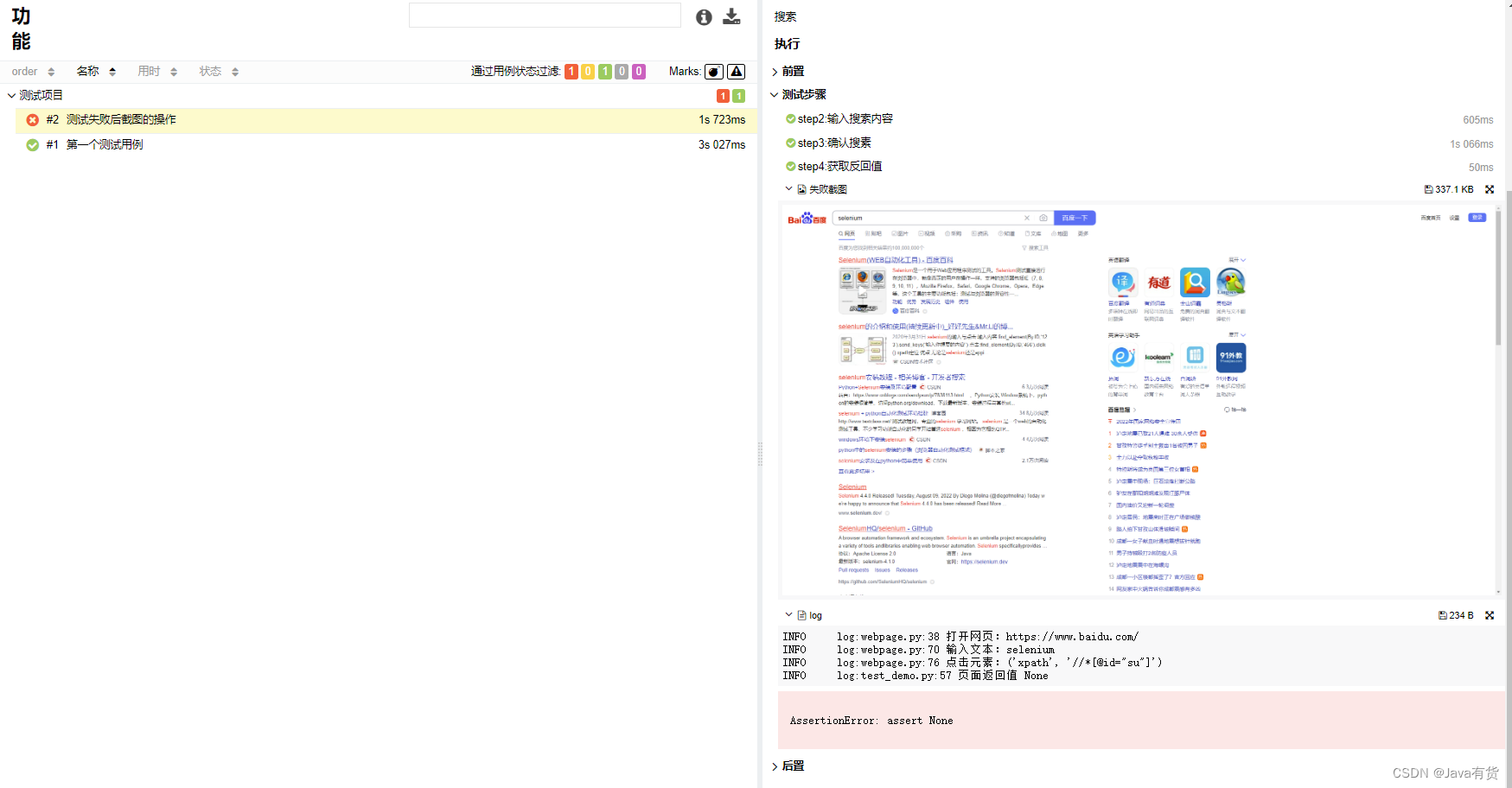
当我们打开错误的校验报告进行查看,这里包含里错误的日志,错误是的页面截图!!!
总结与源码
总体来说,这样的测试还是比较丝滑的,但是由于代码比较多,文中之阐述了一部分,大家如感兴趣,可以阅读源码!
源码地址 https://github.com/yanghaiji/qualification-test-plan 如果对您有所帮助记得star
到这里本次分享即将结束!!! 感谢您的阅读!!!
















 2240
2240











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











