









无监督神经机器翻译三
Phrase-Based & Neural Unsupervised Machine Translation
这是facebook小哥哥的第三篇文章,获得了EMNLP2018的bestpaper。依然是在前两篇的基础上做的工作,粗略阅读感觉跟以前的工作没什么区别,但是作者将前面的工作灵活应用取得了很好的效果。作者所总结的无监督机器翻译通用方法,不仅在神经机器翻译上取得了很好的效果,在传统机器翻译上效果同样惊人,bestpaper实至名归啊。
【前面的一篇博客】中也是无监督机器翻译的,但他的工作是基于相似语种的,对于相差很大的语种效果应该不好。而本文所提出的模型对于任何语种都适用,只是相近语种用到的方法更简单一些,确实厉害!由于统计机器翻译不是我研究的重点,所以下面我重点介绍神经机器翻译的部分。
由于这篇文章是以前两篇文章为基础的,所以想看懂这篇文章最好要先看前面的三篇相关博客,否则很难理解。链接为:
- Word Translation without Parallel Data
- Unsupervised Machine Translation Using Monolingual Corpora Only
- Unsupervised Neural Machine Translation
技术点
本文主要总结了无监督机器翻译三个原则:
- 初始化(Initialization)
- 语言建模(Language Modeling)
- 迭代反向翻译(Iterative Back-translation)
作者说使用无监督的方式翻译,只要遵循以上三个原则,就可以实现,而不在于模型。
上面三个原则通俗点解释就是:
- 初始化:文中通过这一步获得了一个将不同语言的字嵌入空间进行了对齐,这样就产生了一个可以进行逐字翻译的模型。
- 语言模型:在有了一个逐字翻译的模型之后,使用单语言侧的语言模型,去将翻译出来的不完整的不流利的翻译进行改进,使得在当前语言下符合语法和规范。同时,这样产生的语料可以作为平行语料。这就是第二步单侧语言模型的作用。
- 反向翻译:翻译大约可以看做是A语言->B语言的过程,反向翻译则是将这一过程反向,即从B->A的过程。由于上一阶段已经产生了平行语料,这样将这个平行语料翻译回A的过程,就是反向翻译的过程,且这一成程可以看做是一个有监督的学习(已知正确的语言为A)。
通过这样的描述,大概就能明白了论文的大体思路:
1)简单的词到词的翻译模型
2)使用语言模型让他变得更流程,并获得平行语料
3)使用平行语料,进行有监督的学习。
主要思想
这篇文章在前人的基础上,总结出无监督机器翻译的三个原则,即合理的初始化,语言模型和迭代回译。通过初始化,为模型提供了先验知识和期待的解空间;单语数据蕴含了丰富的语言学知识,语言模型的应用让模型在一定程度上学习了这些知识,使生成的句子更为流畅和合理;在迭代回译中,源语到目标语的翻译和目标语到源语的翻译组成对偶任务,通过将语种A的句子翻译成语种B,再翻译回语种A,来训练目标模型,把无监督问题变为了有监督问题。

如上图所示,子图A表示两个语种的单语数据,标记表示句子(详见图例);子图B表示第一个原则:初始化,例如可通过无监督学习到的词典进行逐词翻译,以粗略的对齐两种分布;子图C表示第二个原则:语言模型,每个语种独立地训练语言模型,为模型提供语言结构等先验知识,以纠正错误的句子等;子图D表示第三个原则:迭代回译,从一个观察到的源语句子(实心红色圆圈)开始,通过源语到目标语模型进行翻译(虚线箭头),产生一个可能错误的翻译(空心蓝色圆圈附件的蓝色十字),然后进行回译,再用目标语到源语模型(连续箭头)重建源语句子,通过重建句子与初始句子之间的差异为训练目标语到源语模型提供了误差信号,反之亦然。
整体流程
下图结合无监督机器翻译的三原则,概述了无监督机器翻译的方法。首先学习语言模型,其次初始化提供初始解空间,最后通过迭代回译使模型收敛。其中S和T分别代表源语和目标语句子的空间,Ps和Pt表示在源语和目标语上训练的语言模型,Ps→t 表示源语到目标语的翻译模型,Pt→s
类似。

设计细节
神经机器翻译
初始化
无监督神经机器翻译中,通常使用对齐的词嵌入初始化编码器和解码器的Embedding或输出层。不同于之前所采用的方法,两个语种的单语数据分别训练嵌入,再通过半监督和无监督的方法对齐嵌入空间(词对齐)。对于相近的语言,作者提出了一种更加简单高效的对齐方法,即混合源语和目标语数据,训练词嵌入,这样的做法能更好的对齐分布空间。其次作者还使用了BPE减少了词汇量和消除了输出翻译中的未知单词。
词对齐
词对齐用的是第一篇博客所介绍的文章中设计的方法,下面回顾下相关内容:
Facebook无监督机器翻译的方法,首先是让系统学习双语词典,将一个词与其他语言对应的多种翻译联系起来。举个例子,就好比让系统学会“Bug”在作为名词时,既有“虫子”、“计算机漏洞”,也有“窃听器”的意思。Facebook使用了他们在之前发表于ICLR 2018的论文《Word Translation Without Parallel Data》中介绍的方法,让系统首先为每种语言中的每个单词学习词嵌入,也即单词的向量表示。
然后,系统会训练词嵌入,根据其上下文(例如,给定单词前后的各5个单词)来预测给定单词周围的单词。尽管词嵌入是一种非常简单的表示方法,但从中可以获得很有趣的语义结构。例如,与“kitty”(小猫)这个词距离最近的是“cat”(猫),并且“kitty”这个词与“animal”(动物)之间的距离要远远小于它与“rocket”(火箭)这个词的距离。换句话说,“kitty”很少出现在有“rocket”的上下文里。
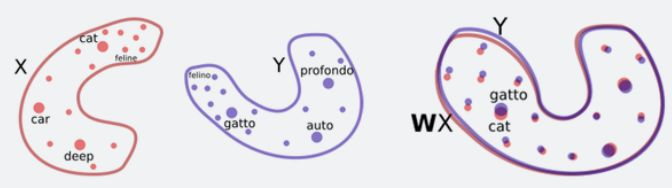
上图的gatto和cat都是猫的意思。
可以通过简单的旋转并对齐两种语言(X和Y)的二维词嵌入,然后通过最近邻搜索实现单词翻译。
鉴于这些相似之处,Facebook的研究人员提出了一种方法,让系统通过对抗训练等方法,学习将一种语言的词嵌入结构进行旋转,从而匹配另一种语言的词嵌入结构。有了这些信息以后,他们就可以推断出一个相当准确的双语词典,无需任何已经翻译好的语句,并且基本上可以做到逐字翻译。
语言模型
在神经机器翻译中,主要通过去噪自编码器实现了语言模型,类似于机器翻译任务,不同点在于编码器和解码器的输入均属于同一语种。其目标函数如下:
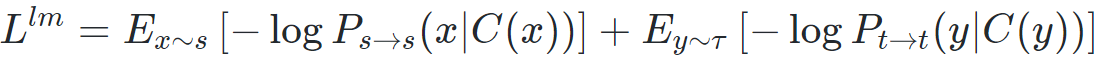
这里的语言模型的损失函数如图,(即随机的删除句子中的一些词和交换句子中词的位置,对句子进行还原)。其中C是噪声模型,对Encoder输入的词进行丢弃或交换,实验表明该方法有利于语言模型的学习;Ps→s 表示编码器、解码器输入都是源语的编码-解码模型,Pt→t 类似。
通过旋转并对齐不同语言的词嵌入结构,得到词到词的翻译。当逐词翻译实现以后,接下来就是词组乃至句子的翻译了。当然,逐词翻译的结果是无法直接用在句子翻译上的。于是,Facebook的研究人员又使用了一种方法,他们训练了一个单语种语言模型,对逐词翻译系统给出的结果打分,从而尽可能排除不符合语法规则或有语病的句子。
这个单语模型比较好获得,只要有小语种(比如乌尔都语)的大量单语数据集就可以。英语的单语模型则更好构建了。通过使用单语模型对逐词翻译模型进行优化,就得到了一个比较原始的机器翻译系统。虽然翻译结果不是很理想,但这个系统已经比逐字翻译的结果更好了,并且它可以将大量句子从源语言(比如乌尔都语)翻译成目标语言(比如英语)。
完成上面步骤后就用无监督反向翻译技术,训练句到句的机器翻译系统。
迭代回译
回译是半监督学习中利用单语数据的有效方法。在无监督机器翻译中,该过程的目标函数表示如下:
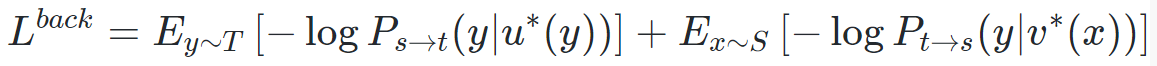
其中,u∗(y) 表示由目标语到源语模型翻译得到的源语句子,v∗(y) 表示由源语到目标语模型翻译得到的目标语句子。(u∗(y),y) 和(x, v∗(y) )组成伪平行数据,基于最大似然估计,分别用于源语到目标语模型和目标语到源语模型的训练。
接下来,Facebook研究人员再将这些机器翻译所得到的句子(从乌尔都语到英语的翻译)作为ground truth,用于训练从英语到乌尔都语的机器翻译。这种技术最先由R. Sennrich等人在ACL 2015时提出,叫做“反向翻译”,当时使用的是半监督学习方法(有大量的语言对)。这还是反向翻译技术首次应用于完全无监督的系统。
我们举例来详细说明(source:英语 target: 乌尔都语):

这里把英语看做输入x,那么输出的乌尔都语v∗(x)的表达式为:
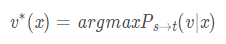
即:在输入x的情况下,当翻译模型给出v的概率最大时,即是x在乌尔都语下的翻译v,再通过由单语种语料训练的语言模型将翻译变得更符合语法和规范,这样就可以生成平行语料Pt→t(v∗(x)) 。

这样,再将Pt→t(v∗(x))的语料翻译x的过程,即为反向翻译,即为上图中多出来的部分。
而进行这一任务时,我们已知的是x是一定正确的,即是有标签的,可以认为是一个有监督的任务,即翻译由一个无监督任务转变成了一个有监督任务。
我们又可以将翻译的过程看做是:
A->B的过程,但是同样的也存在着一个由B->A的反过程。

因此必要存在一个反过程。所以将这两个过程结合在一起时,就可以使得系统形成一个闭合的回路。可以进行循环迭代提升效果。
不可否认,由于第一个系统(从乌尔都语到英语的原始机器翻译系统)的翻译错误,作为训练数据输入的英语句子质量并不高,因此第二个反向翻译系统输出的乌尔都语翻译效果可想而知。
不过,有了刚才训练好的那个乌尔都语单语模型,就可以用它来对第二个反向翻译系统输出的乌尔都语译文进行校正,从而不断优化、迭代,逐渐完善第二个反向翻译系统。
基于短语的统计机器翻译(PBSMT)
用的是文章《Statistical phrase-based translation》中的方法。和Unsupervised Statistical Machine Translation中用的方法是一样的。
PBSMT使用Moses的默认平滑ngram语言模型,并在第一次生成禁用了短语重新排序。 使用算法2以迭代方式训练PBSMT。在每次迭代中,我们翻译从源语言的单语数据集中随机抽取的500万个句子。 除初始化外,我们使用短语表,其短语长度不超过4。

模型选择
Moses实现的PBSMT有15个超参数,比如每个评分函数的相对权重、单词惩罚等。在本文中,我们考虑两种设置超参数的方法。我们可以将它们设置为工具箱中的默认值,也可以使用小型验证语句集来设置它们。结果表明,如果验证集中只有100个带标签的句子,PBSMT就会过度适合验证集。例如,在en→f r上,调优100个平行句的PBSMT在newstest 2014上获得了26.42的BLEU评分,而默认超参数下为27.09,在newstest 2013上调优3000个平行句的PBSMT获得了28.02的BLEU评分。因此,除非另有规定,本文所考虑的所有PBSMT模型都使用默认的超参数值,并且不使用任何并行资源。
对于NMT,我们还考虑了两种模型选择程序:基于“往返”翻译的BLEU分数的无监督标准(源→目标→源和目标→源→目标),如Lample等人所述。 (2018),以及使用带有100个平行句子的小型验证集进行交叉验证。在我们的实验中,我们发现使用Transformer模型时,无监督标准与测试指标高度相关,但对于LSTM并非始终如此。因此,除非另有说明,否则我们将使用100个并行语句的小型验证集来选择最佳LSTM模型,并使用无监督条件选择最佳Transformer模型。
实验结果
















 1947
1947











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









