







一.快速排序介绍
快速排序的思想:在每一轮挑选一个基准元素,并让比它大的元素移动到数列一边,比它小的元素移动到数列的另一边,从而把数列拆解成两个部分。这种思路叫做分治法。
时间复杂度:假设元素是n,平均情况下需要logn轮,因此快速排序总体的时间复杂度是O(nlogn)。
基准元素(pivot)的选择:随机选择一个元素作为基准元素。
二.算法图解
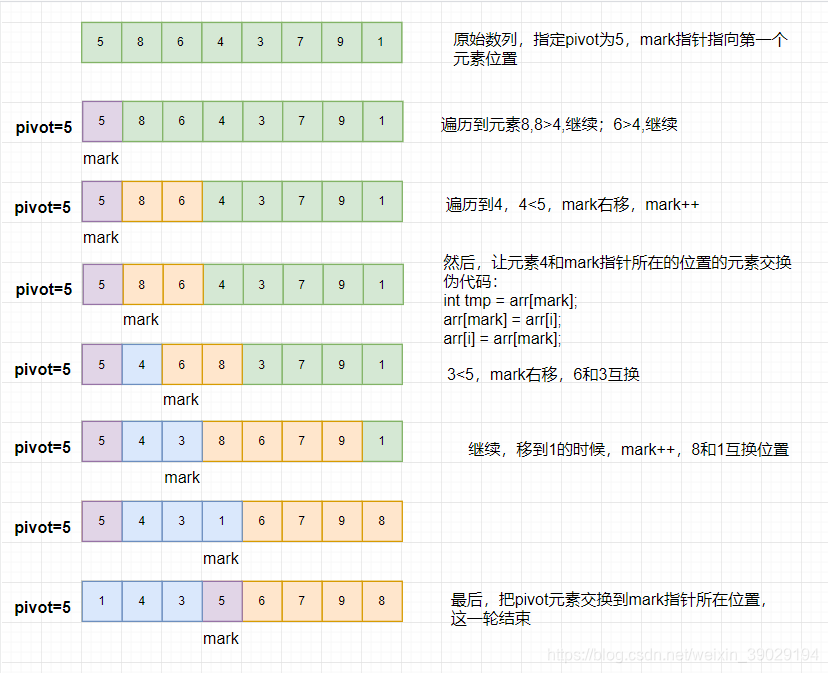
三.递归法实现快速排序
package data.structure;
import java.util.Arrays;
/**
* @author mlnk
* 快速排序(递归方式)
* 核心思想:采取分治法,指定一个基准元素,遍历数列,比基准元素大的不动,比基准元素小的放到基准元素左边。
* 如果遍历到的元素小于基准元素,做两件事:1.mark指针加1;2.将mark指针所在的元素与遍历到的元素互换位置。
* mark指针代表比pivot小的区域。
* 最后,将基准元素与mark指针所在位置的元素互换,即可将数组一分为二
*/
public class MlnkQuickSort {
static int count = 0;//第几轮遍历
public static void quickSort(int[] arr, int startIndex, int endIndex) {
//递归结束条件
if (startIndex >= endIndex) {
return;
}
//得到基准元素位置
int pivotIndex = partition(arr, startIndex, endIndex);
//根据基准元素分成两部分进行排序
quickSort(arr, startIndex, pivotIndex-1);
quickSort(arr, pivotIndex+1, endIndex);
}
/**
* 分治,单边循环法
* @param arr
* @param startIndex
* @param endIndex
* @return
*/
private static int partition(int[] arr, int startIndex, int endIndex) {
//取第一个元素的位置作为基准元素
int pivot = arr[startIndex];
//一个指针,代表小于基准元素的区域边界
int mark = startIndex;
for (int i = startIndex+1; i <= endIndex; i++) {
//小于基准元素,做了两件事:1.mark指针右移一位,因为小于pivot的区域边界增大了1
//2.让最新遍历到的元素和mark指针所在位置的元素交换位置,因为最新遍历的元素归属于小于pivot的区域
if (arr[i] < pivot) {
mark++;
int tmp = arr[mark];
arr[mark] = arr[i];
arr[i] = tmp;
}
}
arr[startIndex] = arr[mark];//最后把pivot元素交换到mark指针所在位置,这一轮结束
arr[mark] = pivot;
count++;
System.out.println("第" + count + "轮遍历:" + Arrays.toString(arr));
return mark;
}
public static void main(String[] args) {
int[] arr = new int[]{5,8,6,4,3,7,9,1};
quickSort(arr, 0, arr.length-1);
}
}
运行结果:

四.栈方式实现快速排序
绝大多数的递归逻辑,都可以用栈来实现。
代码中的调用,本身就使用了一个方法调用栈。每次进入一个新方法就相当于入栈;每次有方法返回就相当于出栈。
所以,我们可以构造一个栈,用来存储每次方法调用的参数(起止下标)。
类似下面这样:
quickSort(0,7)
{
quickSort(0,2)
quickSort(4,7)
}
下面给出具体实现:
public static void quickSort(int[] arr, int startIndex, int endIndex) {
//用一个集合来代替递归的函数栈
Stack<Map<String, Integer>> quickSortStack = new Stack<>();
//整个数列的起止下标,以哈希的形式入栈
Map rootParam = new HashMap<>();
rootParam.put("startIndex", startIndex);
rootParam.put("endIndex", endIndex);
quickSortStack.push(rootParam);
//循环结束条件:栈为空时
while (!quickSortStack.isEmpty()) {
//栈顶元素出栈,得到起止下标
Map<String, Integer> startAndEndIndex = quickSortStack.pop();
//得到基准元素位置
int pivotIndex = partition(arr, startAndEndIndex.get("startIndex"),
startAndEndIndex.get("endIndex"));
//根据基准元素分成两部分,把每部分的起止下标入栈
if (startAndEndIndex.get("startIndex") < pivotIndex - 1) {
Map<String, Integer> leftParam = new HashMap<>();
leftParam.put("startIndex", startAndEndIndex.get("startIndex"));
leftParam.put("endIndex", pivotIndex - 1);
quickSortStack.push(leftParam);
}
if (pivotIndex + 1 < startAndEndIndex.get("endIndex")) {
Map<String, Integer> rightParam = new HashMap<>();
rightParam.put("startIndex", pivotIndex+1);
rightParam.put("endIndex", startAndEndIndex.get("endIndex"));
quickSortStack.push(rightParam);
}
}
}
每次循环,让栈顶元素出栈,然后进行分治,按照基准元素分成左右两部分,再分别入栈。当栈为空时,说明排序语句完毕,退出循环。














 131
131











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









