








目录
3.4.2 memblock内存释放与buddyinfo系统的初始化
4. slab slob slub机制--buddyinfo的更精细补充
1.内存电路实现
· D触发器
... ... ...
2.内存泄露
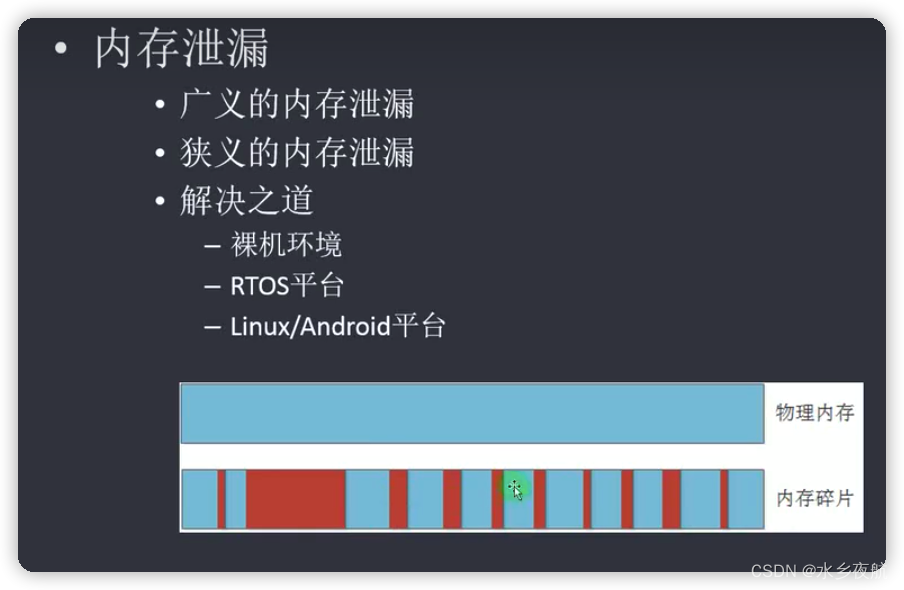
2.1物理内存碎片解决机制
思想:①划分区域权限②划分大小相同的块
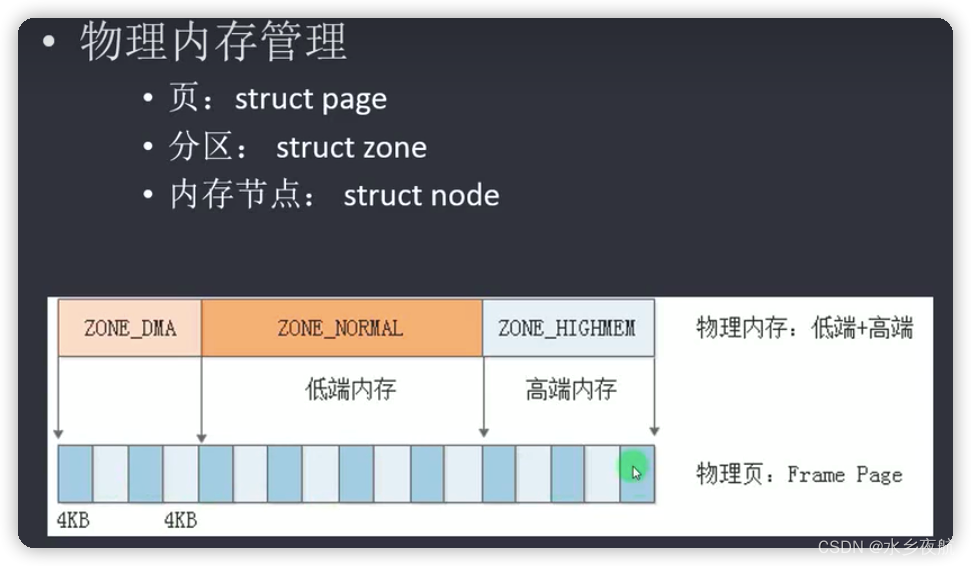
ZONE_DMA 专门为DMA划分的区域(X86使用) 防止内存碎片的影响而找不到连续内存
struct zone 同样一块内存划分权限功能的概念
struct page 针对Linux系统管理的概念
2.1.1 page结构
struct page {
/* First double word block */
unsigned long flags;
struct address_space *mapping;
struct {
union {
pgoff_t index; /* Our offset within mapping. */
void *freelist; /* slub first free object */
};
union {
/* Used for cmpxchg_double in slub */
unsigned long counters;
struct {
union {
atomic_t _mapcount;
struct {
unsigned inuse:16;
unsigned objects:15;
unsigned frozen:1;
};
};
atomic_t _count; /* Usage count, see below. */
};
};
};
/* Third double word block */
union {
struct list_head lru; /* Pageout list, eg. active_list
* protected by zone->lru_lock !
*/
struct { /* slub per cpu partial pages */
struct page *next; /* Next partial slab */
#ifdef CONFIG_64BIT
int pages; /* Nr of partial slabs left */
int pobjects; /* Approximate # of objects */
#else
short int pages;
short int pobjects;
#endif
};
};
/* Remainder is not double word aligned */
union {
unsigned long private;
//... ...
struct kmem_cache *slab; /* SLUB: Pointer to slab */
struct page *first_page; /* Compound tail pages */
};
}
//... ...
};·分类
page cache. 页缓存
page anon 匿名页
page slab slab页
... ...
·物理页帧pfn(page frame addr)和物理地址paddr
pfn=paddr>>PAGE_SHIFT

2.1.2 内存区域
·node (服务器才用的到很多node,一般的嵌入式只需要一个node)
typedef struct pglist_data {
struct zone node_zones[MAX_NR_ZONES];
struct zonelist node_zonelists[MAX_ZONELISTS];
int nr_zones;
/*平坦内存模型:把全部系统内存表示为连续的地址空间 所有指令数据和堆栈都包含在相同的地址空间*/
#ifdef CONFIG_FLAT_NODE_MEM_MAP
struct page *node_mem_map;
#endif
/* 稀疏内存模型 */
#ifdef CONFIG_MEMORY_HOTPLUG
spinlock_t node_size_lock;
#endif
unsigned long node_start_pfn; /* 该节点起始的页帧号 */
unsigned long node_present_pages; /* total number of physical pages */
unsigned long node_spanned_pages; /* total size of physical page
range, including holes */
int node_id;
wait_queue_head_t kswapd_wait;
struct task_struct *kswapd;
int kswapd_max_order;
enum zone_type classzone_idx;
} pg_data_t;·zone
struct zone {
unsigned long watermark[NR_WMARK]; /*当前管理分区的水位管理 用于物理内存碎片管理 */
unsigned long percpu_drift_mark;
unsigned long lowmem_reserve[MAX_NR_ZONES]; /* 申请内存时使用 */
unsigned long dirty_balance_reserve;
#ifdef CONFIG_NUMA
int node;
unsigned long min_unmapped_pages;
unsigned long min_slab_pages;
#endif
struct per_cpu_pageset __percpu *pageset;
/* free areas of different sizes */
spinlock_t lock;
int all_unreclaimable; /* All pages pinned */
#ifdef CONFIG_MEMORY_HOTPLUG
/* see spanned/present_pages for more description */
seqlock_t span_seqlock;
#endif
struct free_area free_area[MAX_ORDER]; /* 剩余内存 */
#ifndef CONFIG_SPARSEMEM
unsigned long *pageblock_flags;
#endif /* CONFIG_SPARSEMEM */
#ifdef CONFIG_COMPACTION
unsigned int compact_considered;
unsigned int compact_defer_shift;
int compact_order_failed;
#endif
ZONE_PADDING(_pad1_)
/* Fields commonly accessed by the page reclaim scanner */
spinlock_t lru_lock;
struct lruvec lruvec;
struct zone_reclaim_stat reclaim_stat;
unsigned long pages_scanned; /* since last reclaim */
unsigned long flags; /* zone flags, see below */
/* Zone statistics */
atomic_long_t vm_stat[NR_VM_ZONE_STAT_ITEMS];
unsigned int inactive_ratio;
ZONE_PADDING(_pad2_)
wait_queue_head_t * wait_table;
unsigned long wait_table_hash_nr_entries;
unsigned long wait_table_bits;
/* Discontig memory support fields. */
struct pglist_data *zone_pgdat;
/* zone_start_pfn == zone_start_paddr >> PAGE_SHIFT */
unsigned long zone_start_pfn;/* 这块zone管理的起始页帧号*/
unsigned long spanned_pages; /* total size, including holes */
unsigned long present_pages; /* amount of memory (excluding holes) */
const char *name;
} ____cacheline_internodealigned_in_smp;2.1.3 物理内存管理结构
综合上述,我们的物理内存整体管理结构如下:
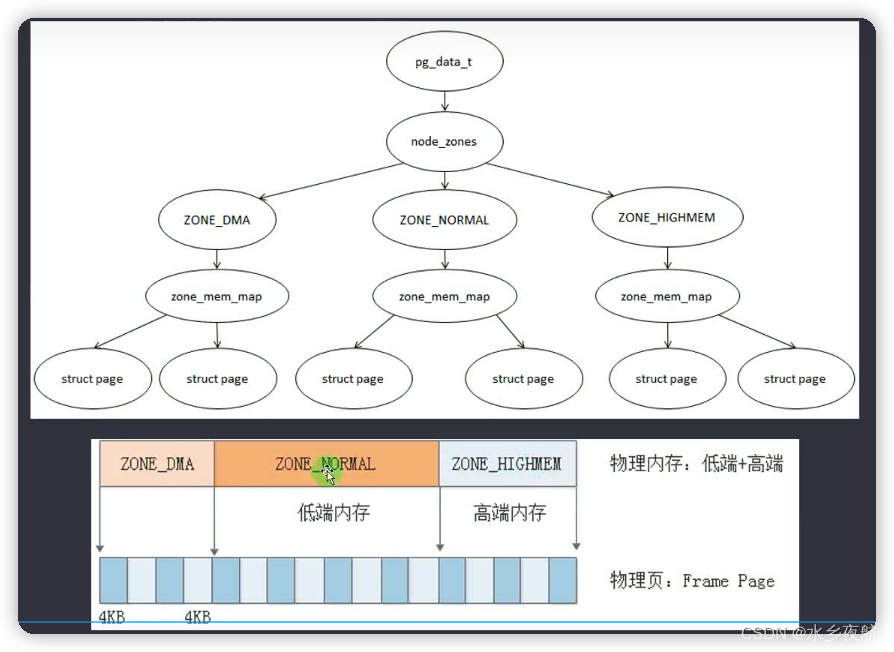
对应的数据结构关联:
3. 伙伴算法系统
3.1 基础版本
伙伴算法的接口在proc目录下:
cat /proc/buddyinfo
Node 0, zone DMA 23 15 4 5 2 3 3 2 3 1 0
Node 0, zone Normal 149 100 52 33 23 5 32 8 12 2 59
Node 0, zone HighMem 11 21 23 49 29 15 8 16 12 2 142
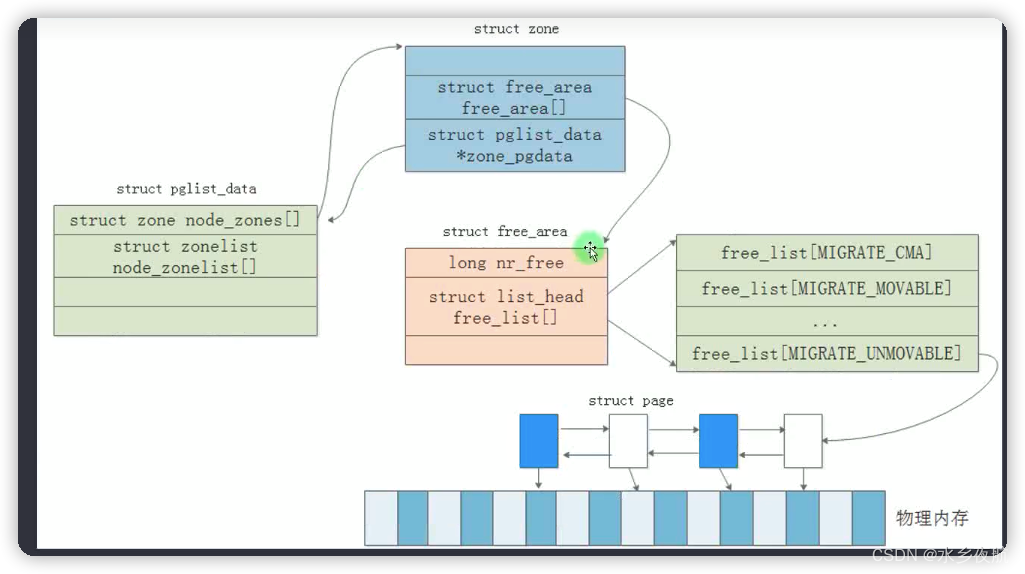
其管理原理是:按照2的阶乘大小,将连续的free page划分成不同的部分(2^0 ,2^1... ...2^10个page),并用链表组织起来。用户正式使用的时候,按照申请的大小到不同的链表中去分配,分配剩余的连续page快降级到下一级链表中去;同时,对于两块相同大小,并且相领的page块(叫做伙伴page),可以合并升级到上一级链表。这样就将不同大小的连续内存page动态的管理起来。( 当高阶链表上的没有元素,全部集中在低阶链表上的时候,表明系统的碎片化比较严重了,此时我们很难分配出大块的内存page了。伙伴系统的算法一定程度上缓解了page碎片化的问题)
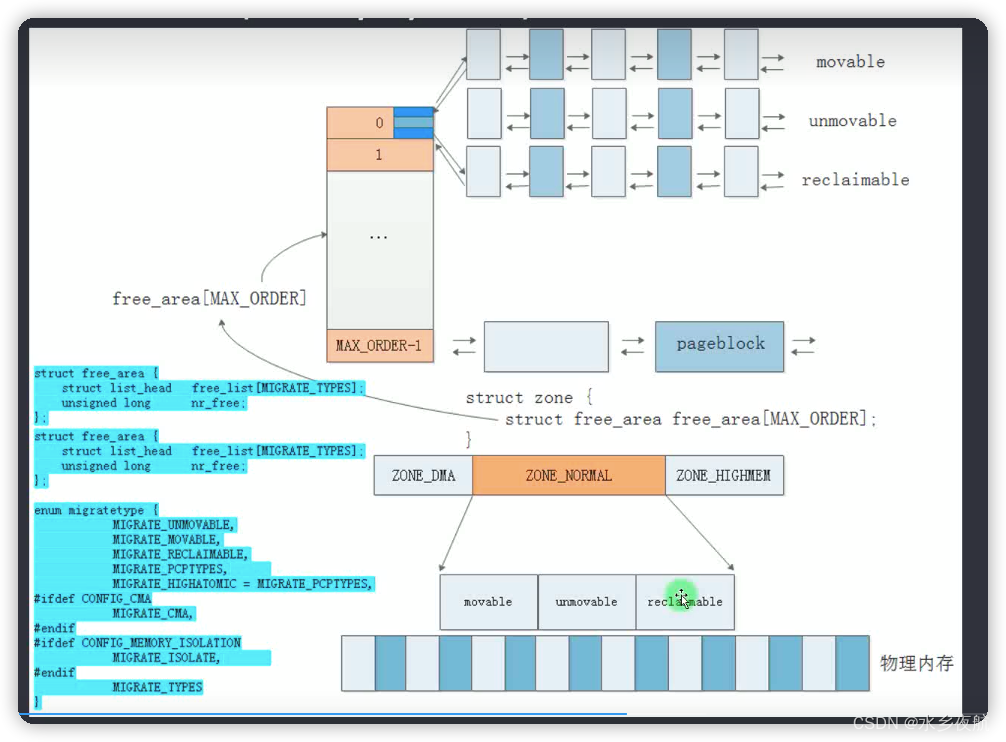
在buddyinfo中free page不同类型做管理: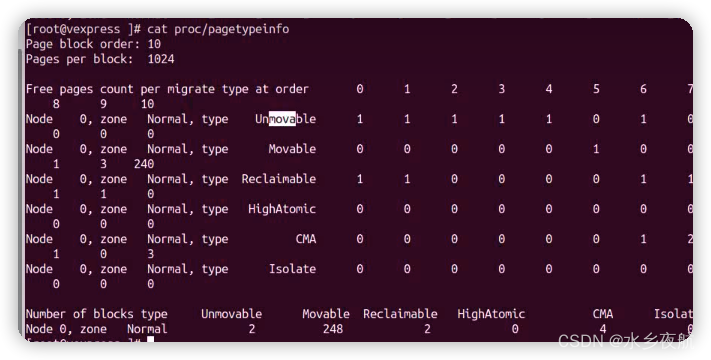
3.2 伙伴系统的改进和完善
3.2.1 页面迁移分类
从上文描述可知,内核在buddyinfo的基础上,将free页面根据不同的属性进行分类:
·可移动的(可以在需要的时候,迁移页面内容的位置来组合成新的大块内存页,但是会产生重映射的消耗)
·不可移动页面(对于内核这种静态链接地址的程序来说)
·可回收页面(发生内存不足时,可以进行内存回收)

其存在意义就是,弥补了buddyinfo 算法无法处理进程分配了不释放的缺陷,将伙伴算法的管理细化到了页面类型的层面。
3.2.2 per-CPU 页面缓存
由于内存页面属于公共资源,系统中频繁分配释放单个页面,会因为获得释放锁,CPU之间的同步操作产生无谓大量消耗。因此对于少量的页面分配,在zone结构中,给每个CPU都分配了_percpu *pageset变量,这样每个CPU都会在本地生成少量页面的副本缓存,分配的时候,先去缓存中去拿;释放也是放到缓存中。这样就提升了多核系统的性能。

3.3 伙伴分配器接口
示意图
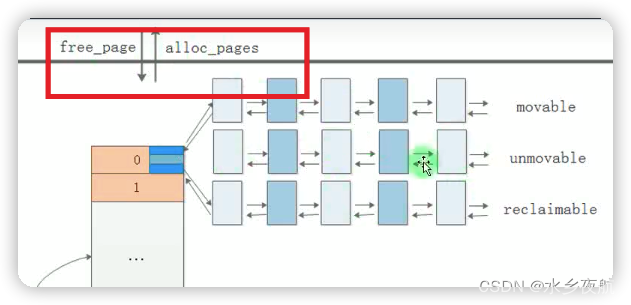
定义:
/* gfp_mask:伙伴系统管理的分区 GFP_DMA GFP_NORMAL 等
*/
#define alloc_pages(gfp_mask, order) \
alloc_pages_node(numa_node_id(), gfp_mask, order)
#define alloc_page(gfp_mask) alloc_pages(gfp_mask, 0)
extern void __free_pages(struct page *page, unsigned int order);
extern void free_pages(unsigned long addr, unsigned int order);
extern void free_hot_cold_page(struct page *page, int cold);
extern void free_hot_cold_page_list(struct list_head *list, int cold);
#define __free_page(page) __free_pages((page), 0)
#define free_page(addr) free_pages((addr), 0)使用举例:
#include <linux/mm.h>
#include <linux/init.h>
#include <linux/module.h>
#include <linux/gfp.h>
#define PAGE_ORDER 1
struct page *page;
unsigned long int virt_addr;
static int __init hello_init(void)
{
page = alloc_pages(GFP_KERNEL, PAGE_ORDER);
printk("page frame num : %lx\n", page_to_pfn(page));
printk("physical addr : %x\n", page_to_phys(page));
printk("virtual addr : %x\n", (unsigned int)page_address(page));
virt_addr = (unsigned int)page_to_virt(page);
printk("virtual addr : %lx\n", virt_addr);
return 0;
}
static void __exit hello_exit(void)
{
free_pages(virt_addr, PAGE_ORDER);
// __free_pages(page, PAGE_ORDER);
}
module_init(hello_init);
module_exit(hello_exit);
MODULE_AUTHOR("wit");
MODULE_LICENSE("GPL");结果:
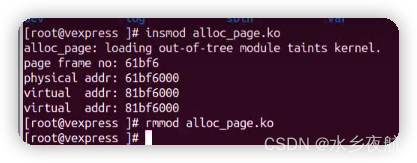
代码实现:
.........
/* First allocation attempt */
page = get_page_from_freelist(gfp_mask|__GFP_HARDWALL, nodemask, order,
zonelist, high_zoneidx, ALLOC_WMARK_LOW|ALLOC_CPUSET,
preferred_zone, migratetype); /* 快速分配,直接从buddy链表分配 */
if (unlikely(!page))
page = __alloc_pages_slowpath(gfp_mask, order,
zonelist, high_zoneidx, nodemask,
preferred_zone, migratetype);/* 慢速分配,当内存页面不足,则进行memory 压缩 合并 迁移....... */
3.4 伙伴系统的初始化
3.4.1 memblock管理器
为了让系统能够正常启动,早期的内存是预先被划分成了不同的区块的,比如系统镜像区域,程序运行区域,多媒体编解码区域,空闲区域等。
在系统启动之初,我们的内存只是一块芯片,没有人告诉系统内存的状态,大小,分配情况这些信息。内存系统要真正将内存管理起来,需要在启动过程中,获得内存的分区,大小,分配状态等信息。

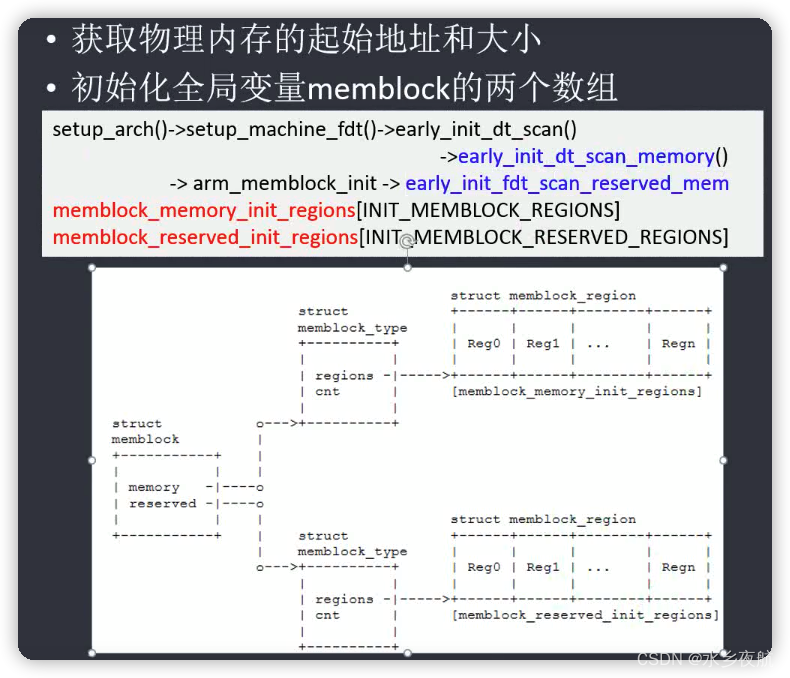
·系统早期的内存管理(buddyinfo 初始化之前)
memblock是内核在系统启动早期用于管理物理内存的机制,它从dtb中解析出物理内存信息,并通过特定的数据结构管理这些信息。同时它还在memblock初始化之后,伙伴系统启用之前,承担系统的内存分配任务。
在程序员眼中,物理内存无非就是一段段的地址空间,这些空间可以通过起始地址和地址长度来表示。Memblock模型正是基于这一思想抽象出来的,它为每段地址分配一个如下面定义的region结构,该结构包含了其起始地址、长度和一些标志信息:
struct memblock_region {
phys_addr_t base;
phys_addr_t size;
enum memblock_flags flags;
#ifdef CONFIG_NUMA
int nid;
#endif
}相关的接口和数据结构:
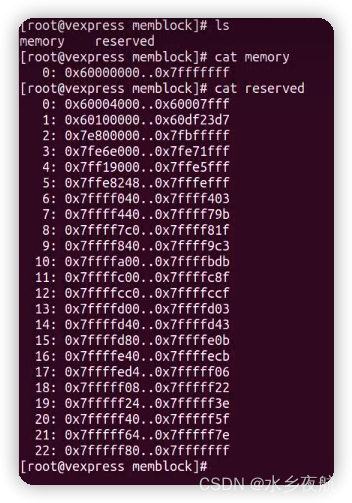
memblock包含memory类型和reserved类型两种memory region,分别表示扫描后的可用内存块和已经被使用的内存块。 它们的关系如下:
(1) memory类型
内核会为所有这种类型的内存建立线性映射,因此所有处于线性映射区且未被标记为nomap的内存都保存在memory类型中
(2) reserved类型
(a)设备树中明确标记为需要保留的内存,它们一般会有特殊的用途
(b)内核image,initrd以及dtb驻留的内存
(c)memblock内存分配器已经分配出去且未释放的内存
(d)用于contiguous dma等的cma内存 这些内存由于有特殊用途或正在使用,因此不会进入伙伴系统或被memblock分配器再次分配。

从设备上可以cat出来memory和reserved两块的信息:
初始化流程:
3.4.2 memblock内存释放与buddyinfo系统的初始化
主要在mem_init()中通过函数来扫描所有的memblock region来建立page和region的联系:
#define for_each_memblock(memblock_type, region) \
for (region = memblock.memblock_type.regions; \
region < (memblock.memblock_type.regions + memblock.memblock_type.cnt); \
region++)
/*
* mem_init() marks the free areas in the mem_map and tells us how much
* memory is free. This is done after various parts of the system have
* claimed their memory after the kernel image.
*/
void __init mem_init(void)
{
unsigned long reserved_pages, free_pages;
struct memblock_region *reg;
int i;
/* ... ... */
printk(KERN_INFO "Memory:");
num_physpages = 0;
for_each_memblock(memory, reg) {
unsigned long pages = memblock_region_memory_end_pfn(reg) -
memblock_region_memory_base_pfn(reg);
num_physpages += pages;
printk(" %ldMB", pages >> (20 - PAGE_SHIFT));
}
/* ... ... */
}3.5 CMA 分配器
伙伴算法管理的最大内存是受到限制的,在这种情况下,大块内存分配可以使用CMA去分配。
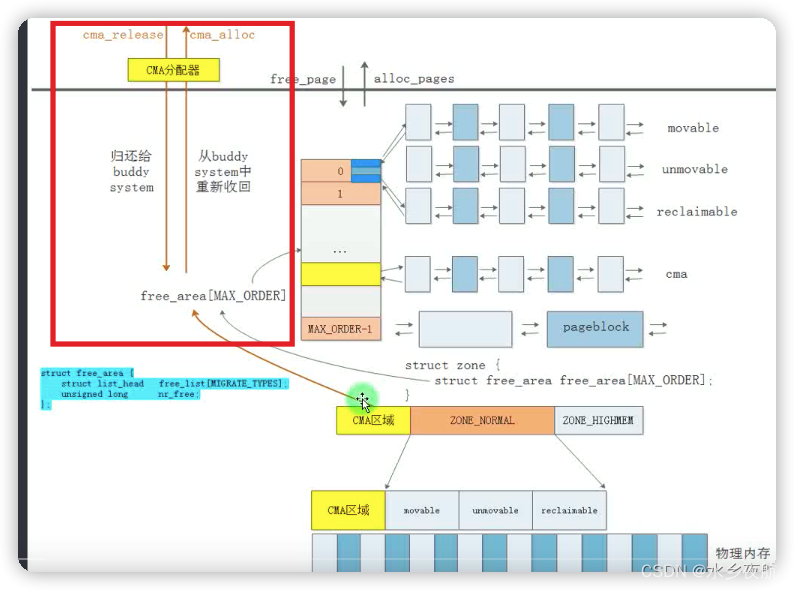
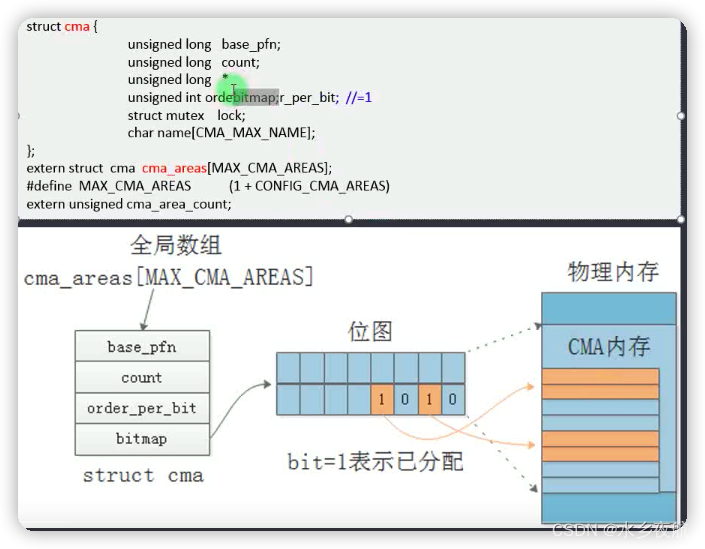
其管理使用位图,orderbitmap 的值表示位图每个bit位管理多大的连续page。
4. slab slob slub机制--buddyinfo的更精细补充
4.1 slab机制
伙伴系统是以page为单位管理的,但是实际上内存中存在大量几字节 几十字节的结构体(eg task_struct)内存分配,这样每存储一个结构体都使用一个page的话是极大地浪费,因此提出了slab机制。slab就是将一个4k的page均匀地分割成32,64,128这样的区域,用于保存匹配的结构体数据,提高内存利用率。

4.2 实现
4.2.1 结构体kmem_cache
具体是使用slab 还是slob slub由不同的系统配置决定,以slub定义为例:
/*
* Slab cache management.
*/
struct kmem_cache {
struct kmem_cache_cpu __percpu *cpu_slab; /* 每CPU变量,CPU本地缓存 */
/*... ... ... ...*/
struct list_head list; /* List of slab caches */
struct kmem_cache_node *node[MAX_NUMNODES]; /* 管理slab链表 */
};
struct kmem_cache_node {
spinlock_t list_lock; /* Protect partial list and nr_partial */
unsigned long nr_partial;
struct list_head partial;
#ifdef CONFIG_SLUB_DEBUG
atomic_long_t nr_slabs;
atomic_long_t total_objects;
struct list_head full;
#endif
};kmem_cache_node结构体管理所有的slab节点组成的链表结构,每次申请先从cpu_slab的本地缓存申请slab,其次从kmem_cache_node申请,都申请不到就调用buddyinfo的接口alloc_pages申请新的page进行分配。

4.2.2 申请接口
kmem_cache_create:
/**
* kmem_cache_create - Create a cache.
* @name: A string which is used in /proc/slabinfo to identify this cache.名称
* @size: The size of objects to be created in this cache.使用kmem_cache的结构体大小
* @align: The required alignment for the objects. 对齐长度
* @flags: SLAB flags 申请类型
* @ctor: A constructor for the objects. 结构体的构造函数,每次申请结构体内存都会调用这个函数对结构体进行初始化
*
* Returns a ptr to the cache on success, NULL on failure.
* Cannot be called within a int, but can be interrupted.
* The @ctor is run when new pages are allocated by the cache.
*
* @name must be valid until the cache is destroyed. This implies that
* the module calling this has to destroy the cache before getting unloaded.
*
* The flags are
*
* %SLAB_POISON - Poison the slab with a known test pattern (a5a5a5a5)
* to catch references to uninitialised memory.
*
* %SLAB_RED_ZONE - Insert `Red' zones around the allocated memory to check
* for buffer overruns.
*
* %SLAB_HWCACHE_ALIGN - Align the objects in this cache to a hardware
* cacheline. This can be beneficial if you're counting cycles as closely
* as davem.
*/
struct kmem_cache *
kmem_cache_create (const char *name, size_t size, size_t align,
unsigned long flags, void (*ctor)(void *))函数功能就是为我们要使用的结构体申请一个kmem_cache的节点,申请成功返回kmem_cache的指针cache_ptr,我们再使用kmem_cache_alloc(cache_ptr, GFP_KERNEL)去kmem_cache里申请slab来存放我们的结构体。
4.3 slab管理的封装----kmalloc
由于kmem_cache系列接口的易用性不是很好,也不够简洁,日常生活中用的更多的是kmalloc/kfree接口。
#define GFP_NOWAIT (GFP_ATOMIC & ~__GFP_HIGH) /* 不阻塞 立即返回 */
#define GFP_ATOMIC (__GFP_HIGH) /* 在终端中申请内存 不可以睡眠*/
#define GFP_KERNEL (__GFP_WAIT | __GFP_IO | __GFP_FS) /*内核发起的内存申请 可以睡眠*/
#define GFP_USER (__GFP_WAIT | __GFP_IO | __GFP_FS | __GFP_HARDWALL)
void *__kmalloc(size_t size, gfp_t flags)
{
return __do_kmalloc(size, flags, __builtin_return_address(0));
}
EXPORT_SYMBOL(__kmalloc);
kmalloc实现:
略














 1398
1398











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









