









1.背景
公司最近的项目开发中有一个数据库表,在给甲方部署试运行阶段发现有一个接口查询速度特别慢,然后经过排查发现,这个数据库表的的数据每天以6000-9000条的量激增,两个多月的时间已经60多万条。然后经过开会讨论,决定从两方面下手,一方面就是优化数据库结构,另一方面就是分库分表。虽然最终采用的是优化数据库的方式解决问题,在这之前,研究学习了大概一上午时间也简单实现了分库分表的方式解决了问题,查询速度得到了明显的提高。在此做一个简单的记录。
2.技术路线
目前比较流行的就是Mycat,经过查阅资料发现,Mycat虽然很技术成熟,社区也很完善,但是需要单独启动一个Mycat的服务,稍微有重,况且我们只是一个单体项目,不需要分布式的事务,读写分离等等比较复杂的操作,我们就是做一个简单的分库分表,最后经过查找,发现了一个比较轻量级的框架ShardingSphere,只需要引入第三方依赖,再进行配置基本就可以实现分库分表。ShardingSphere的中文官网地址:https://shardingsphere.apache.org/index_zh.html
3.数据库设计

上图就是我们需要进行分库分表的数据库,由于平时代码中我们查询的时候几乎必须用到的两个字段date和type,基本每个月的数据量就是20万左右,type(0、1)字段中0和1的比例大概是1:2,所以最终我们决定按照type来进行分库,然后按照date字段中的月份来进行分表,每个月分一张数据库表。
4.引入依赖
<!--shardingsphere--> <dependency> <groupId>org.apache.shardingsphere</groupId> <artifactId>sharding-jdbc-spring-boot-starter</artifactId> <version>4.0.0-RC1</version> </dependency> <!-- guava--> <!-- 由于项目中其他依赖包(swagger和easypoi-base)guava版本过低,所以需要单独引入高版本guava--> <dependency> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> <version>29.0-jre</version> </dependency> <!--swagger--> <dependency> <groupId>io.springfox</groupId> <artifactId>springfox-swagger2</artifactId> <version>${swagger.version}</version> </dependency> <!--easypoi 此处guava有冲突需要exclusion guava--> <dependency> <groupId>cn.afterturn</groupId> <artifactId>easypoi-base</artifactId> <version>${easypoi.version}</version> <exclusions> <exclusion> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> </exclusion> </exclusions> </dependency>
我们使用的是4.0.1版本,此处额外引入了guava,因为我的项目中还引入了swagger和easypoi-base这两个依赖包中也有guava,但是由于有冲突所以需要在easypoi-base排除guava,但是引入shardingsphere以后会报错,如下所示:

这是由于找不到com.google.common.collect.FluentIterable.concat方法导致的,我们只要引入高版本29.0-jre的guava依赖就可以。
5.yml配置
main:
allow-bean-definition-overriding: true
#shardingsphere配置
shardingsphere:
#数据源配置,也就是分几个数据库就有几个数据源
datasource:
#逻辑数据源 名字可以自己取
names: ds0,ds1
ds0:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.100.197:3306/gen_back_sharding_0?allowMultiQueries=true&useUnicode=true&characterEncoding=UTF-8&serverTimezone=GMT%2B8&rewriteBatchedStatements=true
username: root
password: root
type: com.alibaba.druid.pool.DruidDataSource
initialSize: 5 #初始化大小
maxActive: 200 #最大值
maxWait: 2000 #最大等待时间,配置获取连接等待超时,时间单位都是毫秒ms
ds1:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.100.197:3306/gen_back_sharding_1?allowMultiQueries=true&useUnicode=true&characterEncoding=UTF-8&serverTimezone=GMT%2B8&rewriteBatchedStatements=true
username: root
password: root
type: com.alibaba.druid.pool.DruidDataSource
initialSize: 5 #初始化大小
maxActive: 200 #最大值
maxWait: 2000 #最大等待时间,配置获取连接等待超时,时间单位都是毫秒ms
sharding:
tables:
#逻辑数据表名
must_boot_stop_genset:
# 按照2021和2022年每个月一个分表配置的实际数据节点
# actual-data-nodes: ds0.must_boot_stop_genset_$->{2021..2022}_$->{1..12}
#由于我们目前只有2021年4-7月的数据所以实际节点(实际数据库配置)按照如下配置
actual-data-nodes: ds$->{0..1}.must_boot_stop_genset_2021_$->{4..7}
#分库策略
database-strategy:
##行内算法
inline:
#分库列 type (type%2 0则保存在第一个数据库 1则保存在第二个数据库)
shardingColumn: type
algorithmExpression: ds$->{type % 2}
#分表策略
table-strategy:
#标准分片策略必须自己实现逻辑
standard:
# 分表字段
sharding-column: date
#自定义分表策略方法需要自己实现逻辑
precise-algorithm-class-name: com.fp.epower.sharding.TableShardingAlgorithm
#id 生成策略雪花算法 由于我项目目前使用uuid所以此处注释
# key-generator:
# column: id
# type: SNOWFLAKE
#控制台打印sql日志
props:
sql:
show: true下面展示按照date中的年和月份进行分表的自定义策略的方法
/**
* @ClassName TableShardingAlgorithm
* @Description 自定义逻辑实现按照date的年和月份进行分表
* @Author amx
* @Date 2021/7/19 3:31 下午
**/
@Slf4j
public class TableShardingAlgorithm implements PreciseShardingAlgorithm<String> {
@Override
public String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<String> shardingValue) {
try {
String tb_name = null;
// 根据当前日期 来 分库分表
DateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd");
Date date = null;
date = dateFormat.parse(shardingValue.getValue());
String year = String.format("%tY", date);
String mon =String.valueOf(Integer.parseInt(String.format("%tm", date))); // 去掉前缀0
// 选择表
tb_name = "must_boot_stop_genset_" + year + "_" + mon;
for (String each : availableTargetNames) {
if (each.equals(tb_name)) {
return each;
}
}
} catch (ParseException e) {
e.printStackTrace();
}
throw new IllegalArgumentException();
}
}6.更新数据库
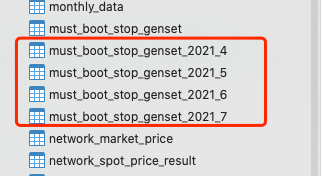
根据我们上面的配置,我们需要提前新建两个数据库gen_back_sharding_0和gen_back_sharding_1,每个数据库里面需要建4张表分别是must_boot_stop_genset_2021_4、must_boot_stop_genset_2021_5、must_boot_stop_genset_2021_6、
must_boot_stop_genset_2021_7
如下面图片所示:

7.启动测试
到这一步的时候我之前使用4.0.0-RC1的版本会报错如下:
The bean 'dataSource', defined in class path resource [org/apache/shardingsphere/shardingjdbc/spring/boot/SpringBootConfiguration.class], could not be registered. A bean with that name has already been defined in class path resource [org/springframework/boot/autoconfigure/jdbc/DataSourceConfiguration$Hikari.class] and overriding is disabled.
Action:
Consider renaming one of the beans or enabling overriding by setting spring.main.allow-bean-definition-overriding=true
这日志信息其实也已经给出了解决方案就是在application.yml中加配置:
spring:
main:
allow-bean-definition-overriding: true
至此,我们所有的准备工作已经做完,项目可以启动,用我们提前开发好的导入数据接口和查询接口进行测试,首先,数据可以根据type保存到相应的数据库,可以根据date保存到相应的数据库表中,数据已经相对很均匀的分布到这些数据库和数据表中,根据我们之前的查询接口,在未引入shardingsphere的时候同样的查询条件,查询大概需要10s+,加入分库分表以后,查询时间大概可以维持在1s左右。
由于学习时间短,有写不好的地方,欢迎留言讨论,批评指正















 325
325











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









