








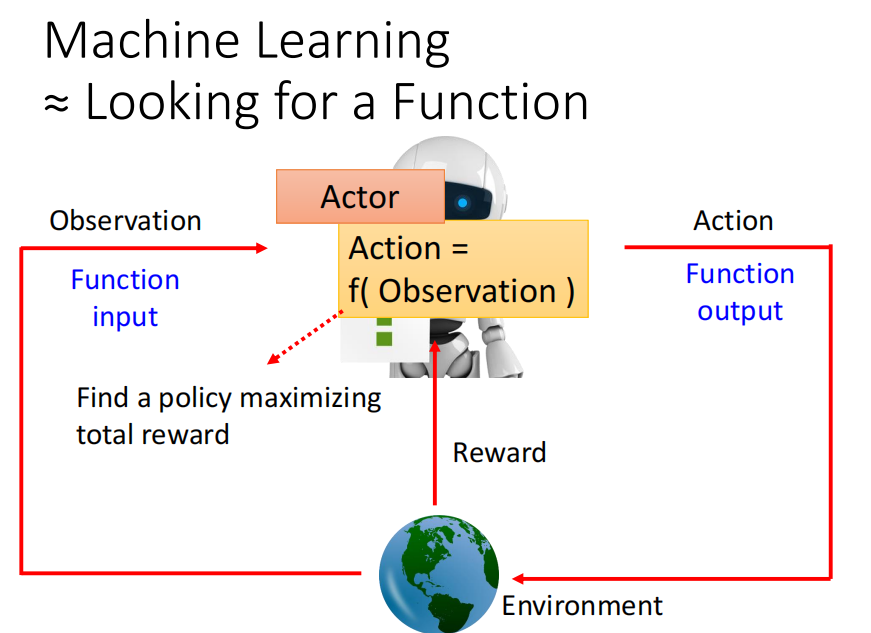

sample: 如 70% 的概率向左 20%的概率向右 10% 的概率开火
不是left 分数最高,就直接向左。而是随机sample
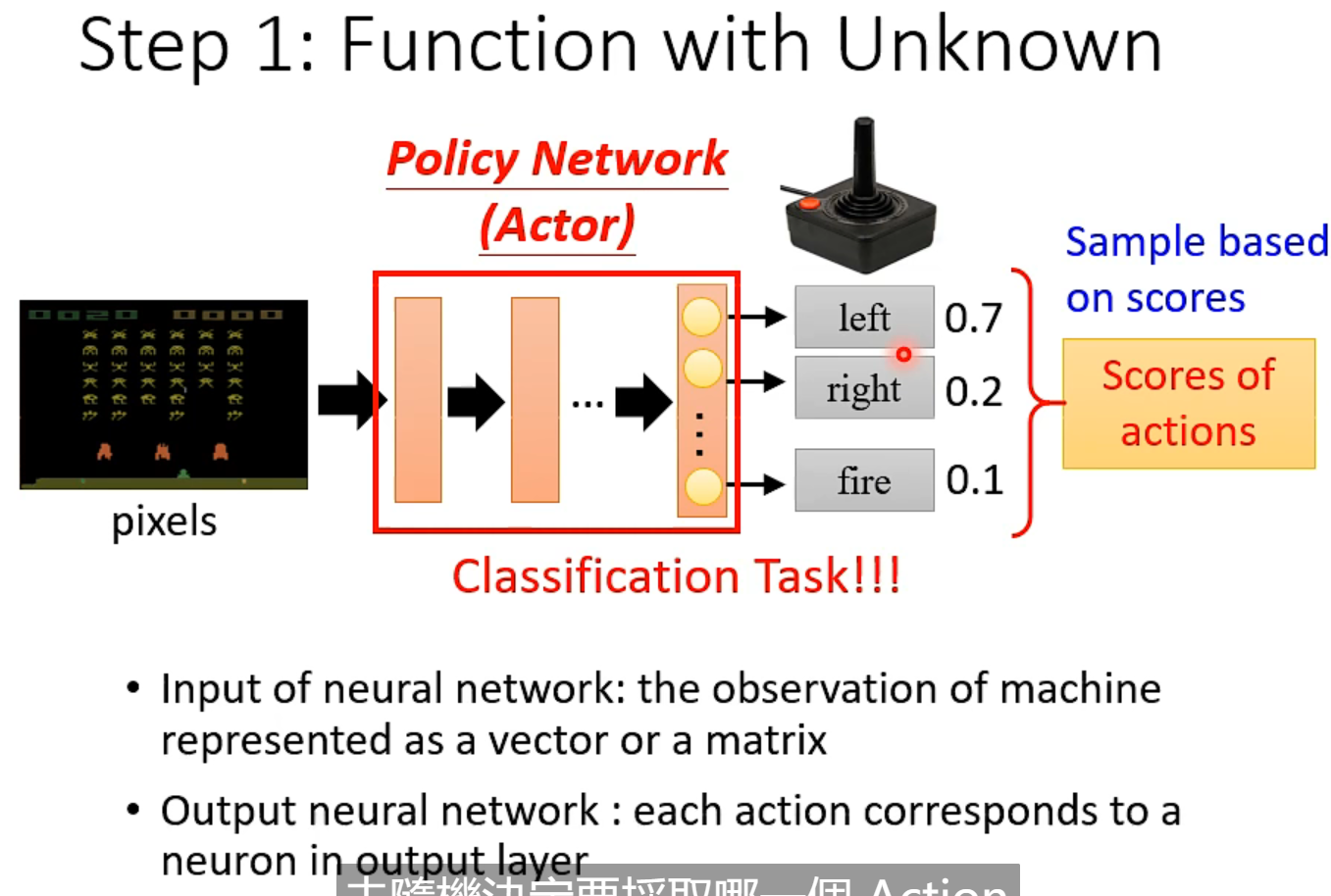
total reward (return) R 就是优化的目标,分数越高约好
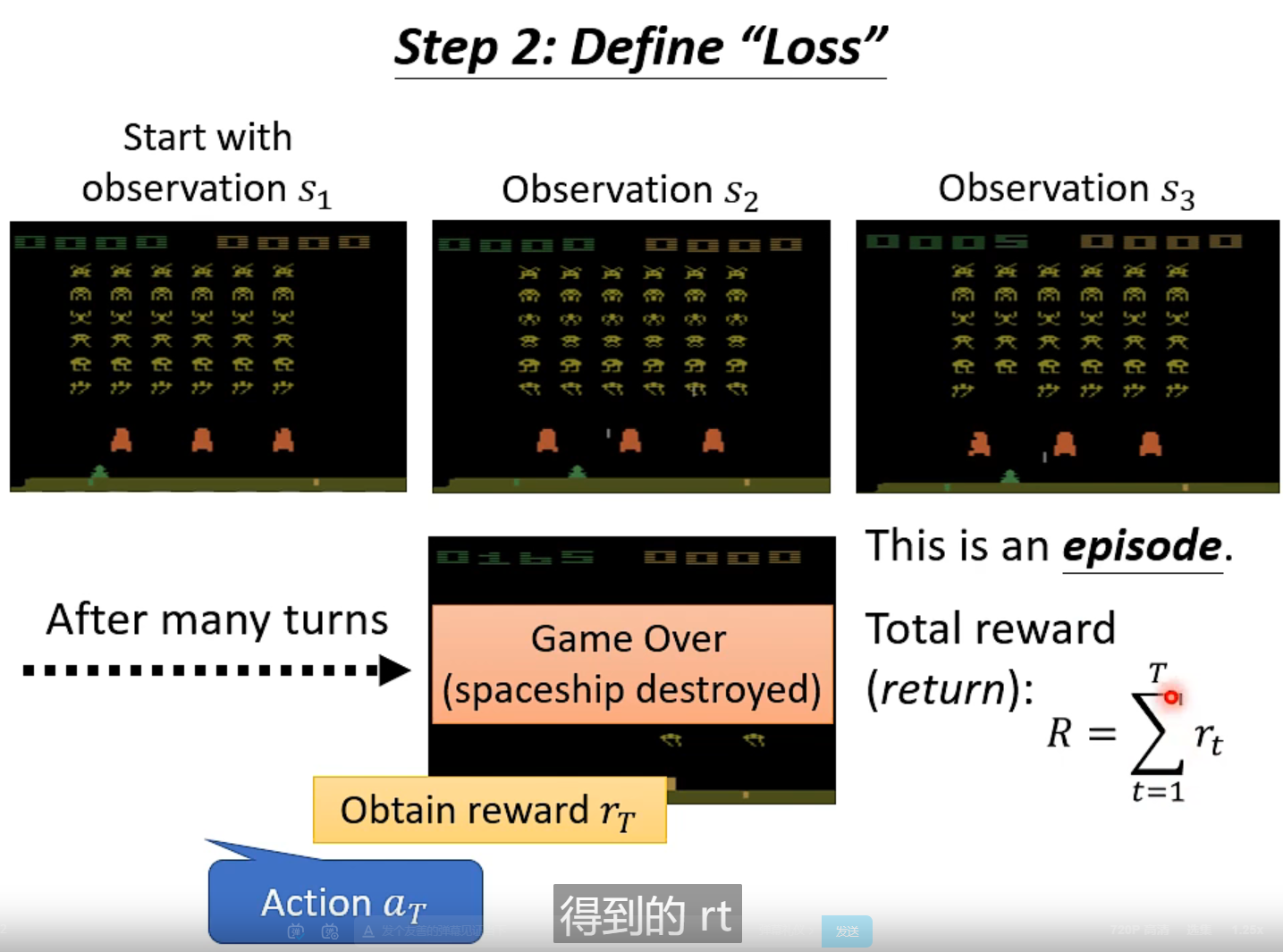
-total reward= loss
Policy Gradient
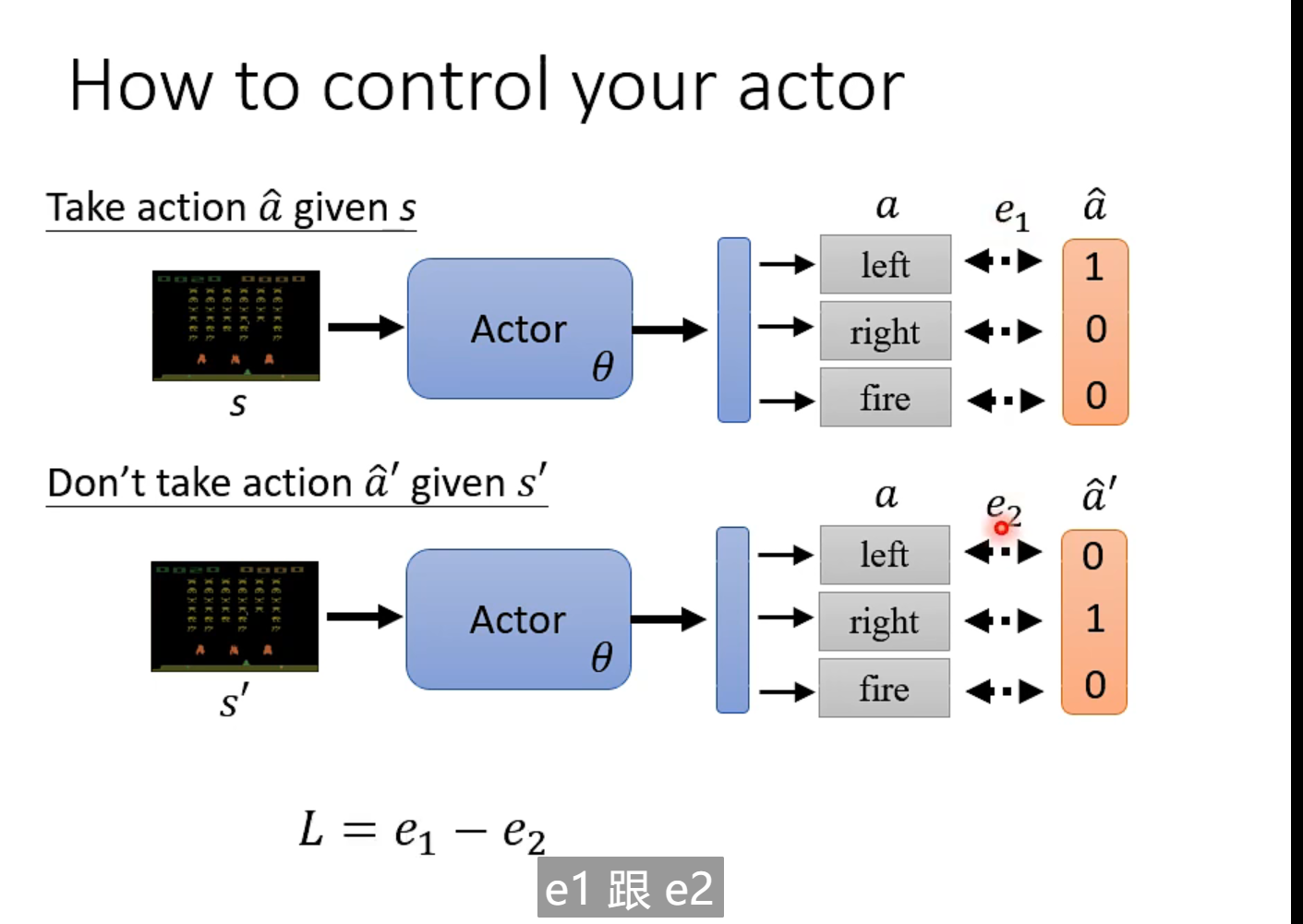
当环境是s 时采取 a 措施。 当出现 ss 时,不能采取aa

出现s1时,执行a1 , 分数为正,代表推荐执行该动作,分数越高,越推荐
version 0
拿每一步的得分作为评估, 因为左转或者右转时不得分,只有射击击中才得分。 会导致,一直进行射击,其他动作不推荐。


改进:
version 1 :
将后续之后所有的得分加起来作为评估


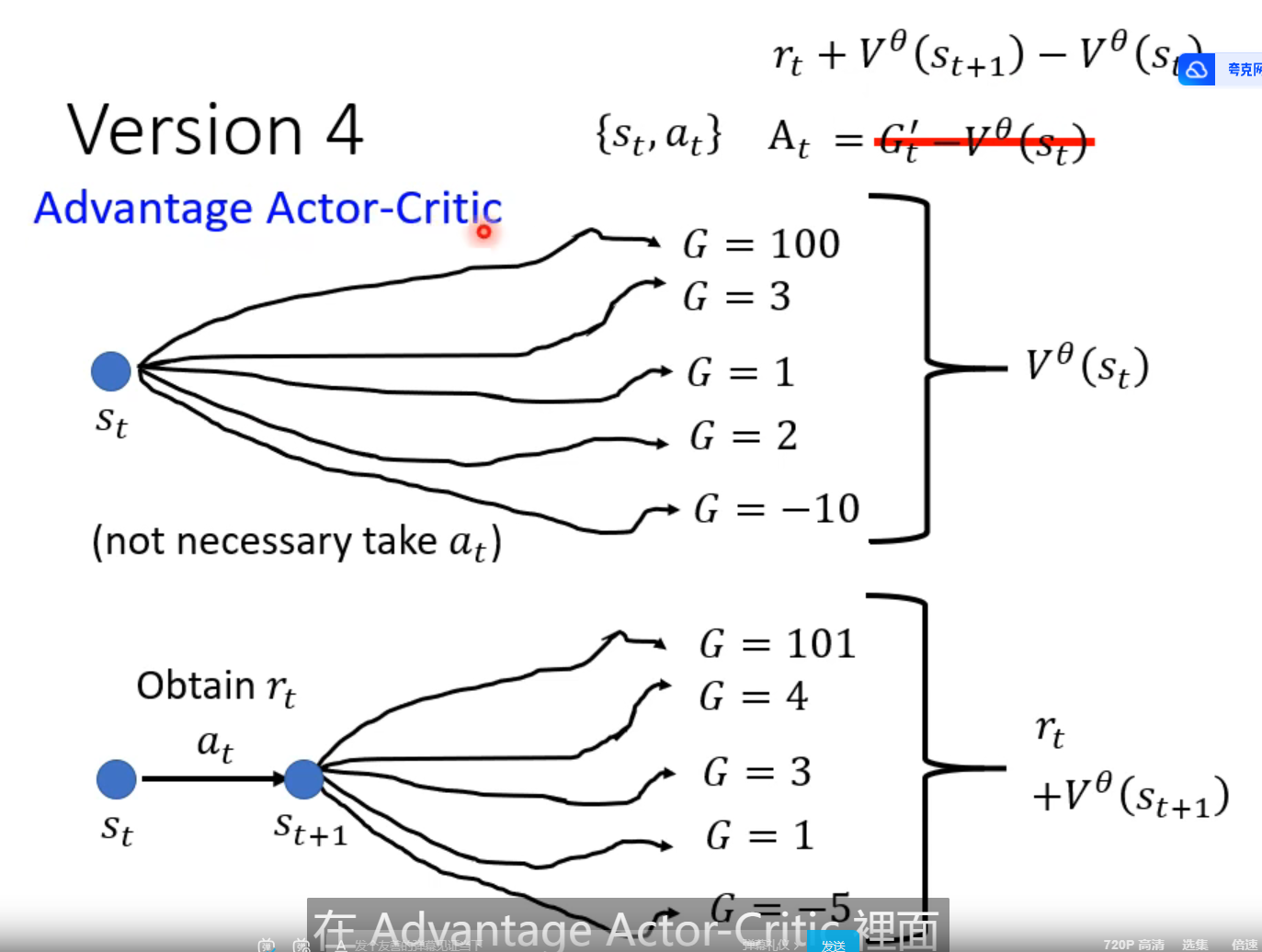
version3]
好坏是相对的
如果每个行为都能得到正分,但分数有高有低
进行标准化
简单方法是,所有的 G’ 减掉一个b b 是一个基础分
怎么设置b 呢

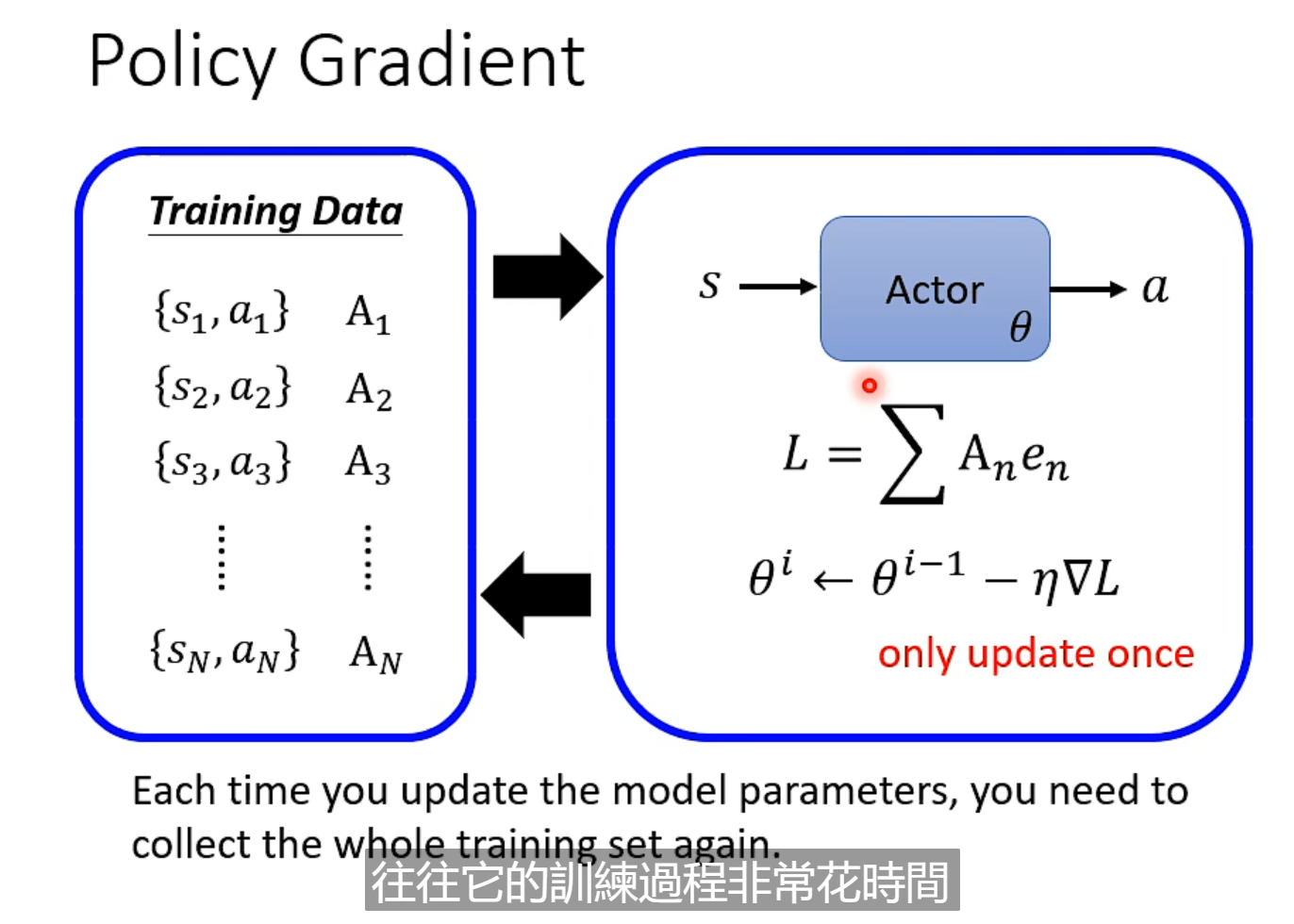
RL 训练非常花时间,收集资料的行为在for 循环里面, 收集一次资料,更新一次参数
Actor Critic
Critic : 评估

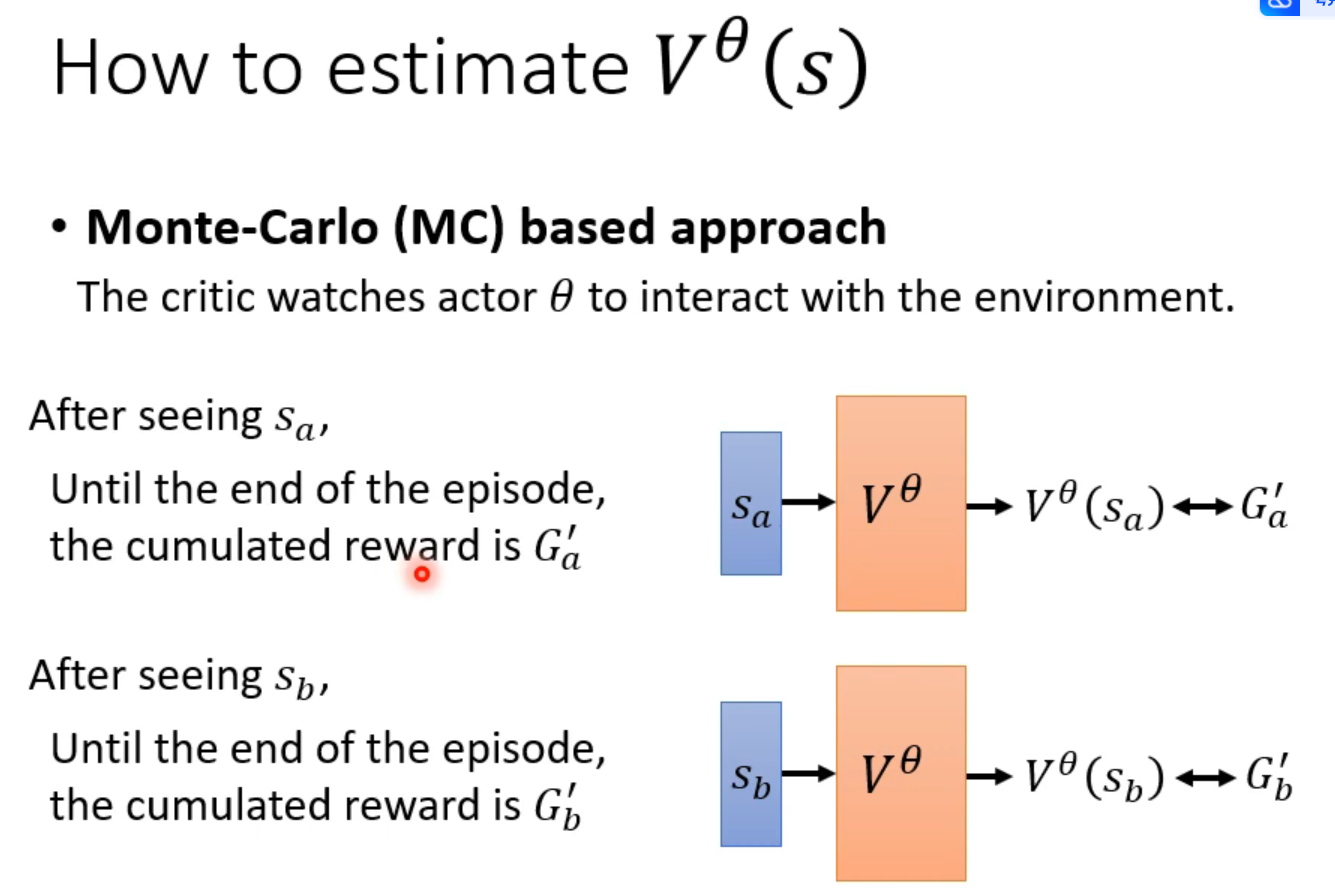
使用MC: 必须等一场游戏全都玩结束才能得到一笔训练集

TD 方法不用等一场游戏全部玩结束
前后两个Observation S 的得分差
用MC 或者 TD 计算有差别
但是结果都算合理,因为假设条件不一样。 一种是前后无关,一种是前后相关


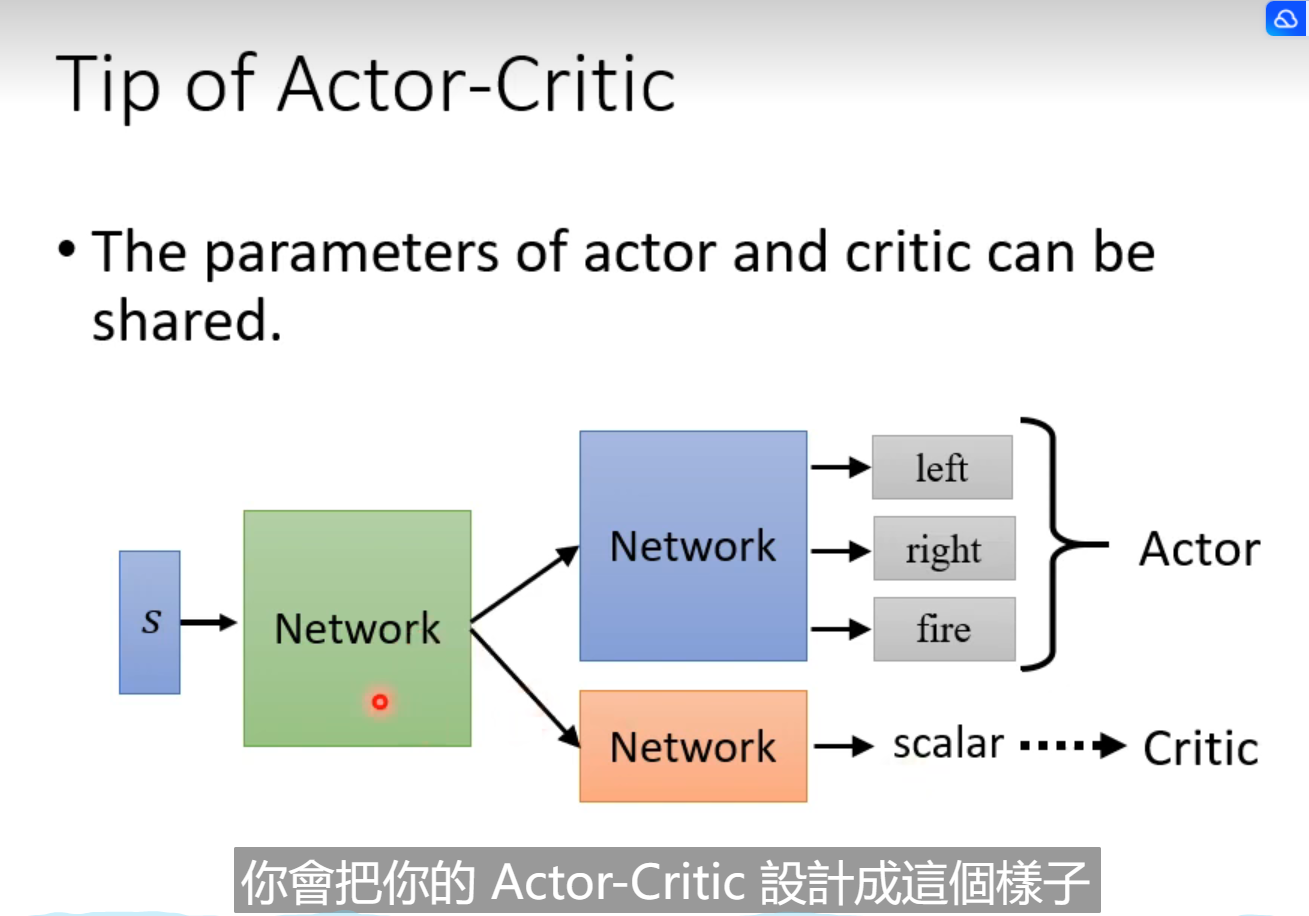
共用大部分的net,最后一点不一样
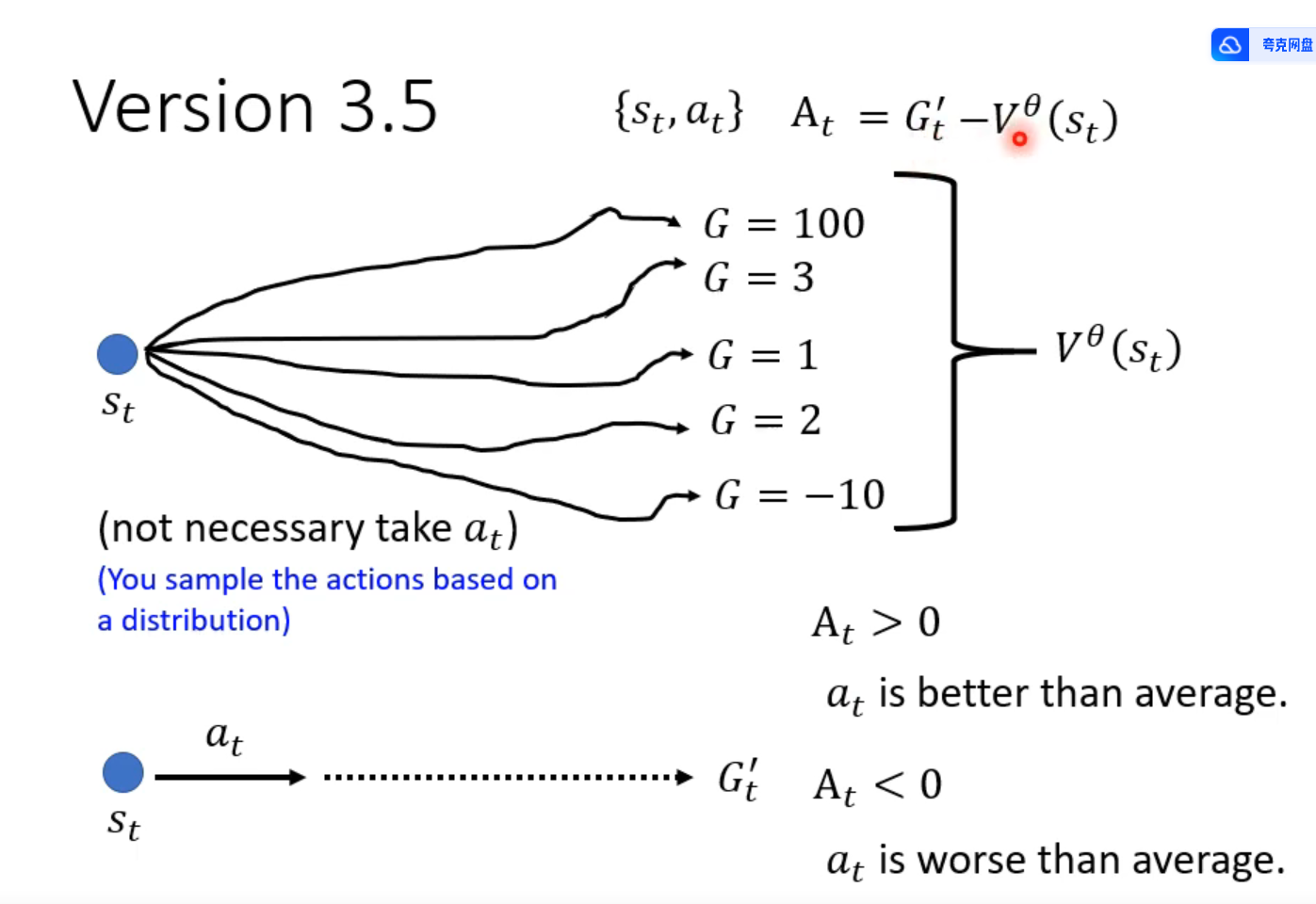
V就是平均实力,超过就是好,低于就是烂
Reward Shaping
reward 非常sparse , 做reward shaping
定额外的reward 指导模型
也就是中间过程中增加一些 reward ,一步一步往前走
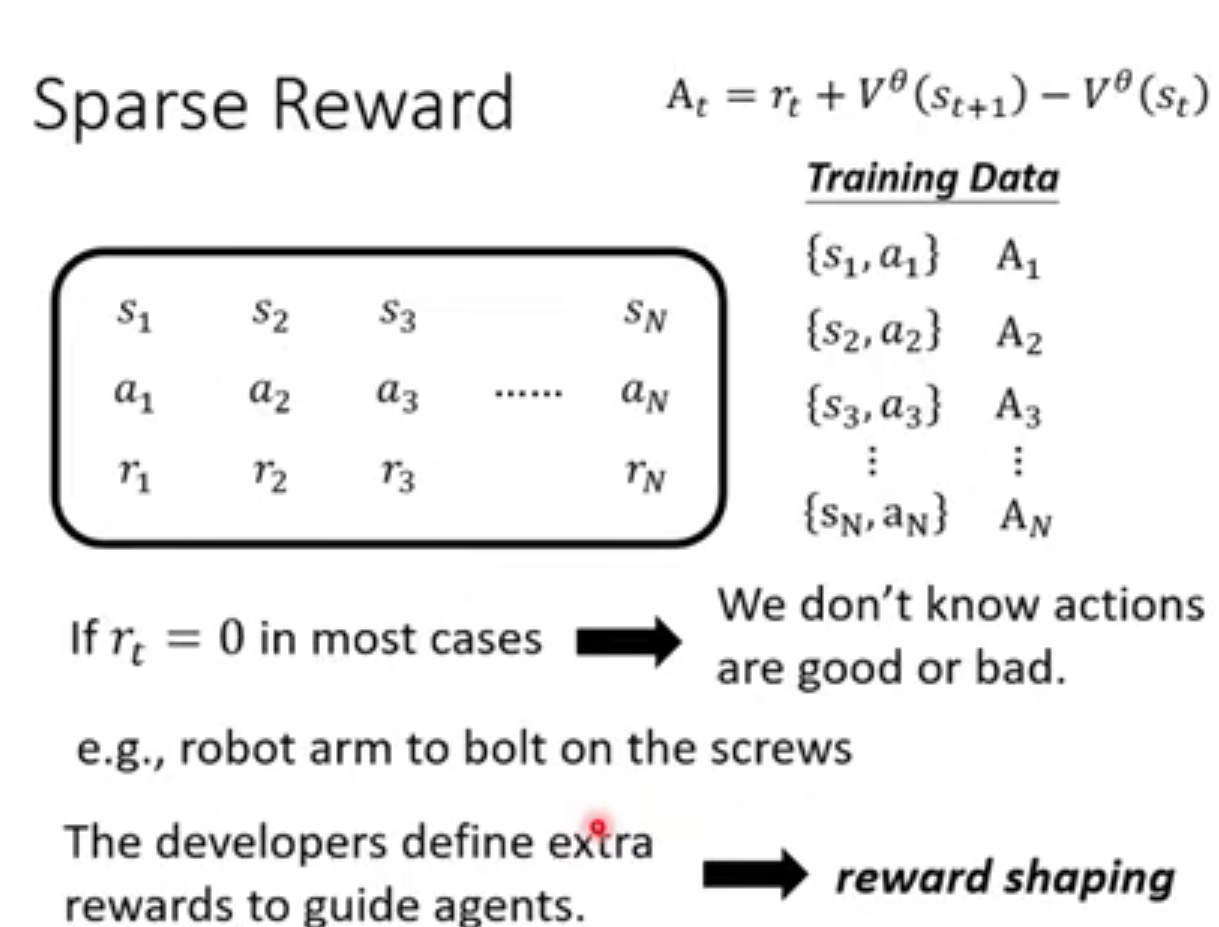

有时候没有reward
一般在游戏里,reward 有
而在真实情况下,reward 不确定怎么计算
要想一些reward 让机器学
没有reward,怎么学呢
imitation learning
比如自动驾驶中,以人类的驾驶记录为训练资料
比如机械臂,人拿着机械臂示范
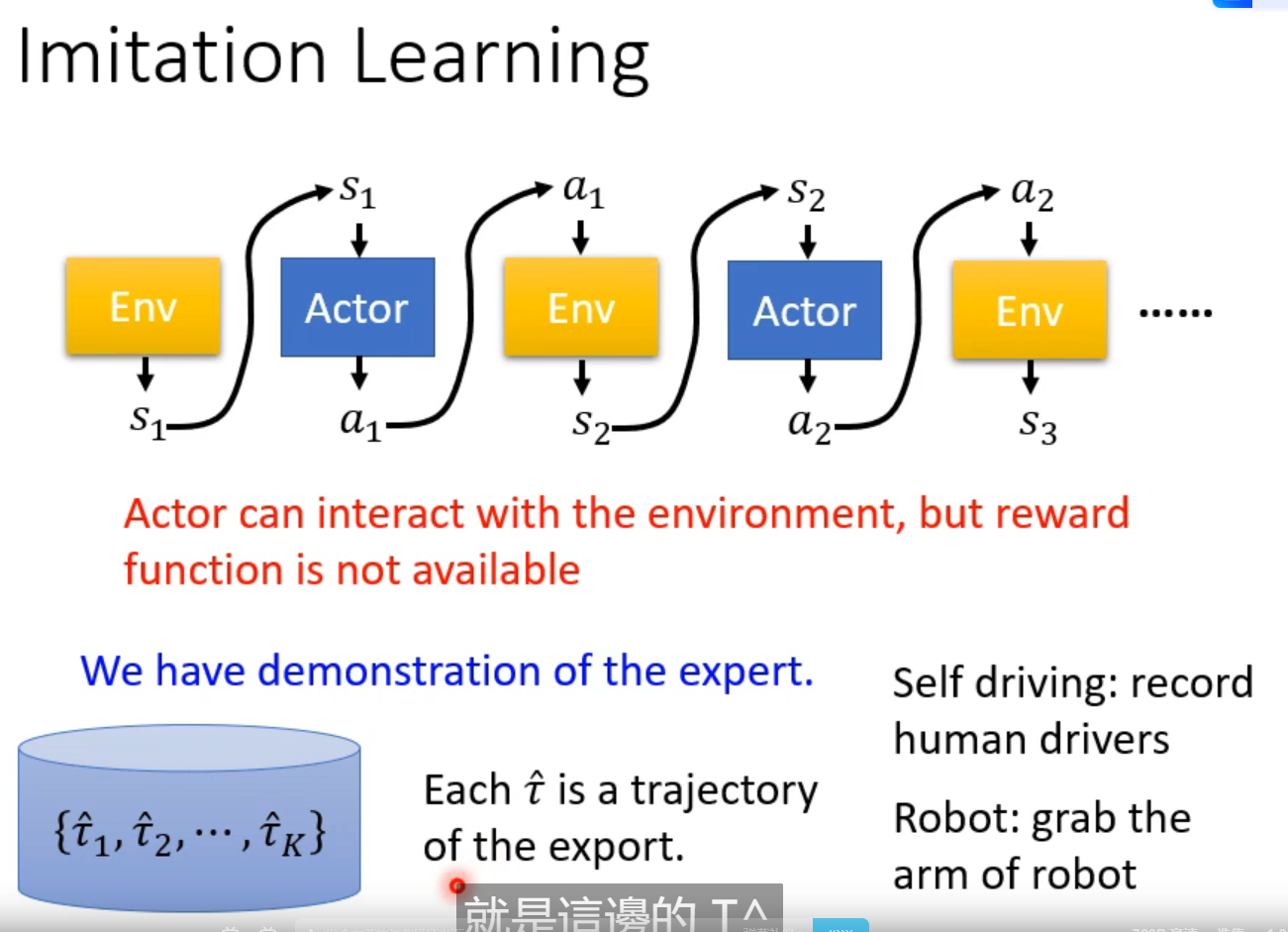
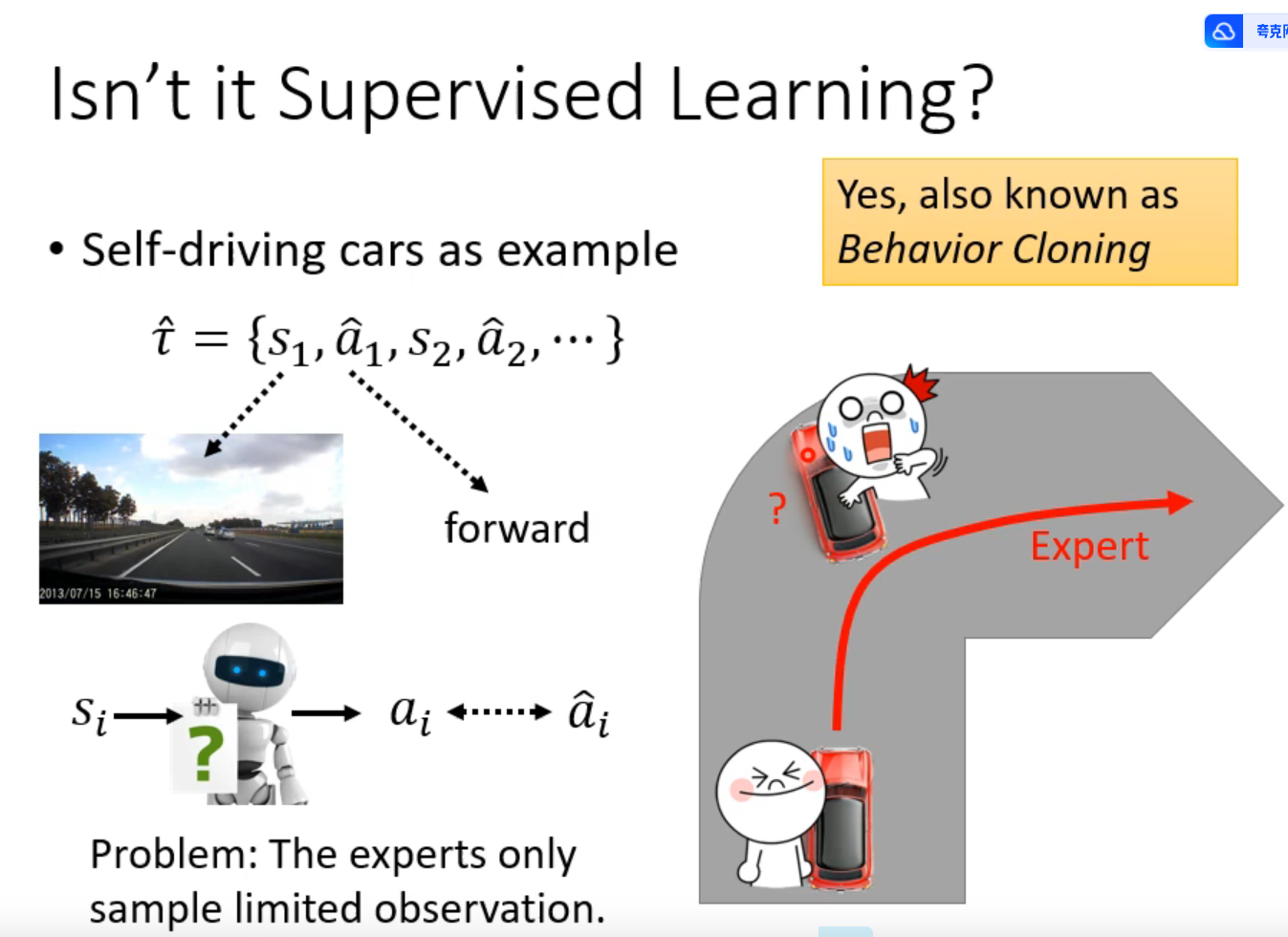
问题:当出现没有学习到过的情景咋办
















 268
268











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











