






首发:小伍哥聊风控 (获取分享干货!!)
编辑: 小伍哥
校稿: 小伍哥
时间: 2023-09-29
这是我在同济大学的第二次课程的课件内容,对之前的内容做了很多优化,并把算法换成了极大联通子图,发出来大家参考下。
挖掘目的:仅利用时间关系,无需其他介质,通过SynchroTrap算法思想,把经常一起行动的人找出来,并划分成一个group。
故事从校园一卡通开始,校园一卡通是集身份认证、金融消费、数据共享等多项功能于一体的信息集成系统,也就是学生卡。积累了大量的历史记录,其中蕴含着学生的消费行为和财务状况等信息。是一个数据分析比赛的数据,很多报告都是从消费金额、消费地点、消费时间等角度分析,比较常规。但是数据,其实还可以更有趣。
本次使用南京理工一卡通的消费明细,我会从一个全新的角度出发,挖掘其中的情侣、基友、渣男、单身狗,大家可以把类似的方法扩展到风控领域使用,这种挖掘思路可以用到反欺诈、反舞弊等场景,思路比较新颖,具有较大的研究价值。
一、数据集介绍
数据是某学校 2019年 4月 1 日至 4月 30日的一卡通数据,一共3个文件,数据分别如下
data1.csv:校园卡基本信息
包含的字段有:['序号', '校园卡号', '性别', '专业名称', '门禁卡号']

data2.csv:校园卡消费明细
['流水号', '校园卡号', '校园卡编号', '消费时间', '消费金额', '存储金额', '余额', '消费次数', '消费类型', '消费项目编码', '消费项目序列号', '消费操作编码', '操作编码', '消费地点']
data3.csv:进出门禁详情
['序号', '门禁卡号', '进出时间', '进出地点', '是否通过', '描述']

二、数据读取
我们先读取下数据,需要数据的,可以后台回复【校园卡】获取
# 数据读取import pandas as pdimport osos.chdir('/Users/wuzhengxiang/Documents/同步行为')os.getcwd()pd.set_option('display.max_columns', None)data1 = pd.read_csv("data1.csv", encoding="gbk")data2 = pd.read_csv("data2.csv", encoding="gbk")data3 = pd.read_csv("data3.csv", encoding="gbk")data1.columns = ['序号', '校园卡号', '性别', '专业名称', '门禁卡号']data2.columns = ['流水号', '校园卡号', '校园卡编号', '消费时间', '消费金额', '存储金额', '余额', '消费次数', '消费类型', '消费项目编码', '消费项目序列号', '消费操作编码', '操作编码', '消费地点']data3.columns = ['序号', '门禁卡号', '进出时间', '进出地点', '是否通过', '描述']print(data1.head(3))print(data2.head(3))print(data3.head(3))# 数据匹配,匹配上性别数据,分析更直观data2 = data2.merge(data1[['校园卡号','性别']],on='校园卡号')data2['校园卡号'] = data2['校园卡号'].apply(lambda x: str(x))+'-'+data2['性别']
三、数据处理
我们把数据处理成关联规则能识别的样子,每个5分钟一个数据,里面是去重后的用户明细,大家课类比,这里的用户ID就是商品ID,没个5分钟就是一个订单,这样就能和比较原始的关联规则联系起来了,初学者还是比较难理解的
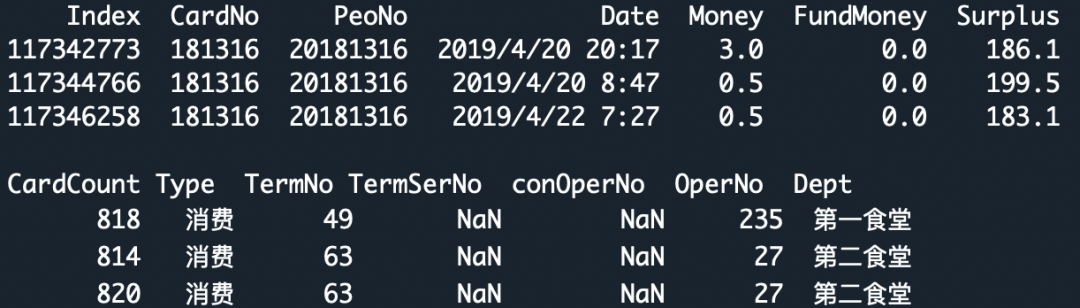
# 构建时间处理函数import datetime# 时间格式调整 函数功能 时间格式调整 '2019/4/20 20:17'=>'2019-04-20 20:17:00'def st_pt(x):return str(datetime.datetime.strptime(x, "%Y/%m/%d %H:%M"))# 时间切片'''函数功能:时间切片5分钟一个切片,且每个时间会切成两个片段Time2Str('2021-11-16 15:51:39' ) '2021-11-16 15:51:39' => '2021111615(10);2021111615(11)''''def Time2Str(tsm):t0 = datetime.datetime.fromisoformat(tsm)t1 = t0+datetime.timedelta(days=0, hours=5/60)str1 = t0.strftime("%Y%m%d%H")+'(' +str(round(int(t0.minute/5))).rjust(2,'0')+')'str2 = t1.strftime("%Y%m%d%H")+'(' +str(round(int(t1.minute/5))).rjust(2,'0')+')'return str1+';'+str2# 开始数据处理df = data2df['消费时间']= df['消费时间'].apply(st_pt)df['tsm'] = df['消费时间'].apply(Time2Str)# 数据分裂,一行变两行df = df.set_index(["校园卡号", "消费时间",'消费地点'])["tsm"].str.split(";", expand=True)\.stack().reset_index(drop=True, level=-1).reset_index().rename(columns={0: "tsm"})print(df.head())校园卡号 消费时间 消费地点 tsm0 181316-女 2019-04-20 20:17:00 第一食堂 2019042020(03)1 181316-女 2019-04-20 20:17:00 第一食堂 2019042020(04)2 181316-女 2019-04-20 08:47:00 第二食堂 2019042008(09)3 181316-女 2019-04-20 08:47:00 第二食堂 2019042008(10)4 181316-女 2019-04-22 07:27:00 第二食堂 2019042207(05)
四、同步行为构图
根据时间和地点,构建同步行为构图。
# 数据匹配,加入时间约束和地点约束df_0 = pd.merge(df,df,on =['tsm','消费地点'],how='inner')df_0.shape# 排除 自己和自己匹配的数据df_1 = df_0[df_0['校园卡号_x']!=df_0['校园卡号_y']]# 时间作差,大于5分钟的排除df_1['diff'] = (pd.to_datetime(df_1['消费时间_x'])-pd.to_datetime(df_1['消费时间_y'])).dt.seconds/60df_1 = df_1[df_1['diff']<=5]# 提取小时按共同出现的小时计数df_1['date'] = df_1['tsm'].apply(lambda x :x[0:10])#统计两两关联的次数,这里比较简单,不按天,也不计算相似度了df_2 = df_1.groupby(['校园卡号_x','校园卡号_y']).agg({'date': pd.Series.nunique}).reset_index().copy()# 降序排列df_2 = df_2.sort_values(by='date',ascending=False)df_2.shape
五、团伙挖掘
# 构图结束了,我们进行团伙挖掘import networkx as nximport matplotlib.pyplot as plt# 给关系加阈值,大于20次的算是比较强的关联了df_3 = df_2[df_2['date']>=18]# 转换成图格式da = df_3[['校园卡号_x','校园卡号_y']].valuesG = nx.Graph()for num in range(len(da)):G.add_edge(str(da[num,0]),str(da[num,1]))#极大连通子图算法print('极大连通子图...')com = list(nx.connected_components(G))#格式整理df_com_connected = pd.DataFrame()for i in range(0, len(com)):d = pd.DataFrame({'Group_id': [i] * len(com[i]), '账户代号': list(com[i])})df_com_connected = pd.concat([df_com_connected,d])print('计算结束')df_com_connected.groupby('Group_id').count().sort_values(by = '账户代号',ascending=False).head(200)
六、数据解读
数据的解读,很多时候,比算法本身要重要,要不然挖掘完了,只能机械化的得到一些结果。
1、情侣组合
# 情侣组合for i in com:if len(i)==2 and str(i).count('男') and str(i).count('女'):print(sorted(i,key=lambda x:x.split('-')[1]))['180096-女', '181113-男']['180499-女', '180433-男']['182191-女', '182873-男']['181712-女', '181699-男']['180142-女', '181889-男']['182587-女', '181831-男']['182089-女', '183076-男']['182526-女', '181975-男']['183898-女', '181774-男']['181314-女', '183095-男']['180827-女', '180751-男']['180813-女', '183062-男']['180276-女', '181532-男']['180832-女', '180759-男']
可以进一步的查看每对情侣的细节组合
# 查看细节-情侣组合result = data2[(data2['校园卡号']=='180499-女') | (data2['校园卡号']=='180433-男')].copy()result = result.sort_values(by='消费时间')result = result.groupby(['校园卡号','消费时间','消费地点']).agg({'消费金额': pd.Series.sum}).reset_index()result['期日'] = result['消费时间'].str.split(' ').str.get(0)result['时间'] = result['消费时间'].str.split(' ').str.get(1)print(result.shape)result = result.sort_values(by='消费时间')result[['期日','校园卡号','时间','消费地点','消费金额']]
如果要看更细节的,我们用每天的去看
# 单独看某一天的细节pd.set_option('display.unicode.ambiguous_as_wide', True)pd.set_option('display.unicode.east_asian_width', True)pd.set_option('display.width', 200) # 设置打印宽度(**重要**)from IPython.display import displayfor i in sorted(list(set(result['期日']))):i='2019-04-04'display(result[(result['期日']==i)][['期日','校园卡号','时间','消费地点','消费金额']])break
2、渣男组合
我能看看渣男的组合
#渣男组合for i in com:if len(i)==3 and str(i).count('男')>=2 and str(i).count('女')>=1:print(sorted(i,key=lambda x:x.split('-')[1]))
我们继续看看没对渣男的每日行为
# 查看每个组合的每日细节 -渣男result = data2[(data2['校园卡号']=='180817-女') | (data2['校园卡号']=='180872-女') | \(data2['校园卡号']=='180527-男')].copy()result = result.groupby(['校园卡号','消费时间','消费地点']).agg({'消费金额': pd.Series.sum}).reset_index()result['期日'] = result['消费时间'].str.split(' ').str.get(0)result['时间'] = result['消费时间'].str.split(' ').str.get(1)print(result.shape)result = result.sort_values(by='消费时间')result[['期日','校园卡号','时间','消费地点','消费金额']]
3、渣女组合
看完渣男,我们来看看渣女组合
#渣女组合for i in com:if len(i)==3 and str(i).count('男')>=1 and str(i).count('女')>=2:print(sorted(i,key=lambda x:x.split('-')[1]))
看看每日明细组合
# 查看每个组合的每日细节 -渣女result = data2[(data2['校园卡号']=='181042-女') | (data2['校园卡号']=='181013-女') | \(data2['校园卡号']=='180624-男')].copy()result = result.groupby(['校园卡号','消费时间','消费地点']).agg({'消费金额': pd.Series.sum}).reset_index()result['期日'] = result['消费时间'].str.split(' ').str.get(0)result['时间'] = result['消费时间'].str.split(' ').str.get(1)print(result.shape)result = result.sort_values(by='消费时间')result[['期日','校园卡号','时间','消费地点','消费金额']]
4、基友组合
我们来看看基友组合
# 基友 组合for i in com:if len(i)>=2 and str(i).count('男')>=1 and str(i).count('女')==0:print(sorted(i,key=lambda x:x.split('-')[1]))
5、闺蜜组合
如果团伙大于2,且都是女生,那就是好闺蜜组合了
# 闺蜜组合for i in com:if len(i)>=2 and str(i).count('男')==0 and str(i).count('女')>=1:print(sorted(i,key=lambda x:x.split('-')[1]))
6、单身狗组合
单身狗组合,这里其实都不用跑数据,不在团伙里面的,基本都是落单的,特例独行的。
七、更多信息
我们对挖掘出来的关系,去做可视化,也可以发现更多的关联关系,可以捕获更多的关系,我们来试试。
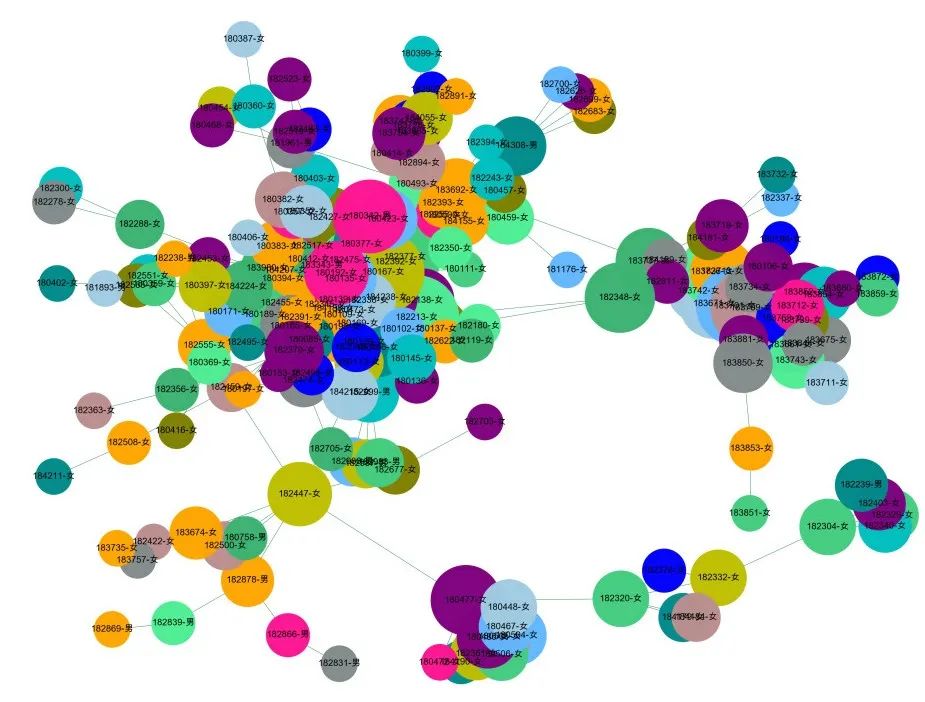
# 我们从新跑下团伙数据df_com_connected.groupby('Group_id').count().sort_values(by = '账户代号',ascending=False).head(20)Group_id1 1864 8283 1396 1324 10184 1088 8127 8#提取某一个群组进行可视化,根据每个社群的节点,去找边。i = 184edges = []for k,v in zip(df_3['校园卡号_x'].tolist(),df_3['校园卡号_y'].tolist()):if k in com[i] or v in com[i]:edges.append((k,v))#转换成图结构,可以从元组列表直接构建图G = nx.Graph(edges)#节点大小设置,与度关联node_size = [G.degree(i)**1.5*100 for i in G.nodes()]# #设置颜色 随机来点# colors = ['#43CD80','DeepPink','orange','#008B8B','purple','#63B8FF','#BC8F8F','#3CB371','b','orange','y','c','#838B8B','purple','olive','#A0CBE2','#4EEE94']*10# colors = colors[0:len(G.nodes())]# import random# colors = random.sample(colors, len(G.nodes()))# 红男绿女colors_dic = {'男':'r','女':'#008000'}node_color = [ colors_dic[i.split('-')[1]] for i in G.nodes()]#设置显示图片大小plt.figure(figsize=(4,3),dpi=400)## 图像显示中文的问题plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']plt.rcParams['axes.unicode_minus'] = False#可以替换两种不同的布局看看效果 kamada_kawai_layout spring_layoutnx.draw_networkx(G,pos = nx.kamada_kawai_layout(G),node_color = node_color,edge_color = '#2E8B57',#with_labels=False,font_size = 4,node_size = node_size,alpha = 0.92,width = 0.2)plt.axis('off')plt.show()
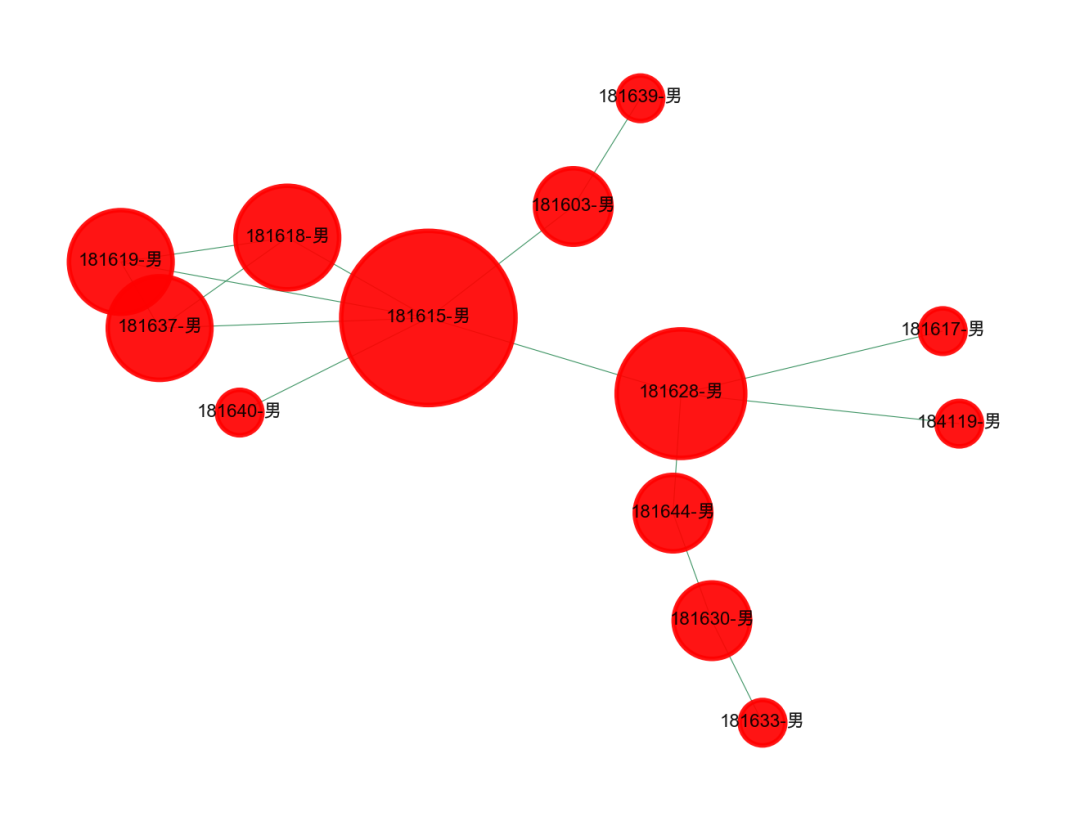
1、理科班的男生真可怜?
可以看到,下面的几个团伙,基本上都是男生,大概率是理科班的,有个别活跃的同学有女朋友,甚至还有和尚班级,一个男生都没女朋友。这就是理工大学的可怜之处。所以我们的关系网络展示,能够进一步挖掘出更多的信息。
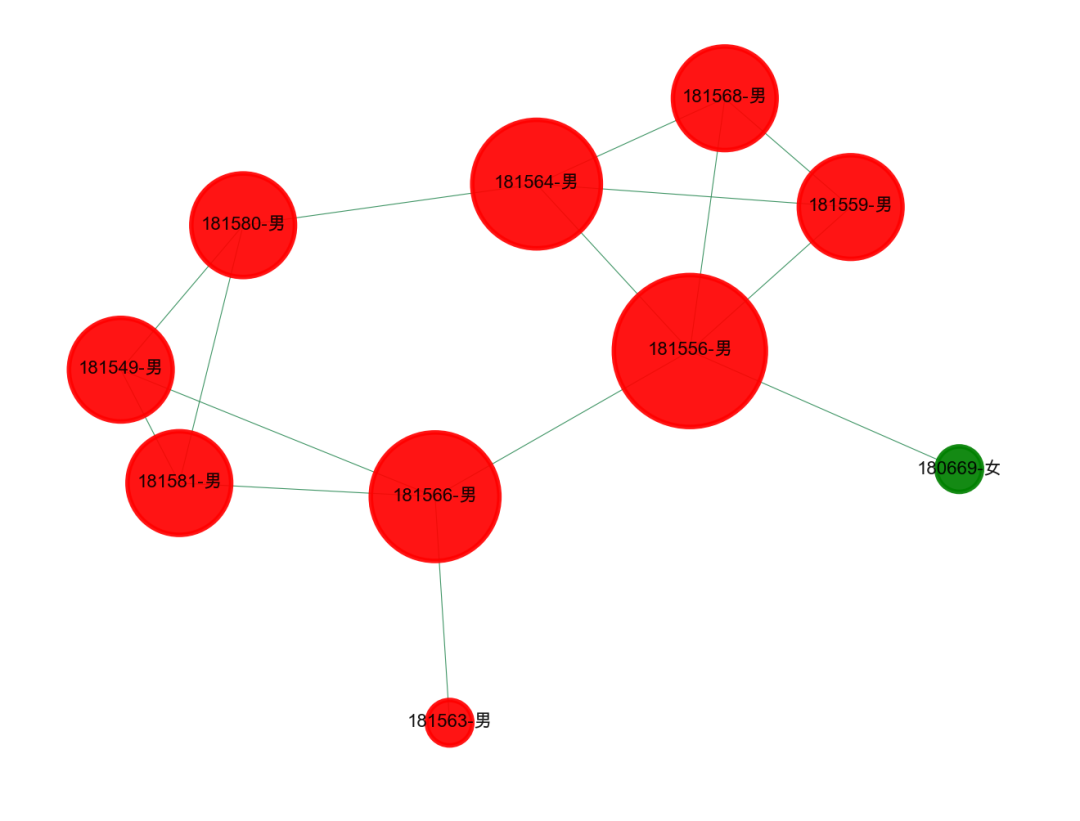
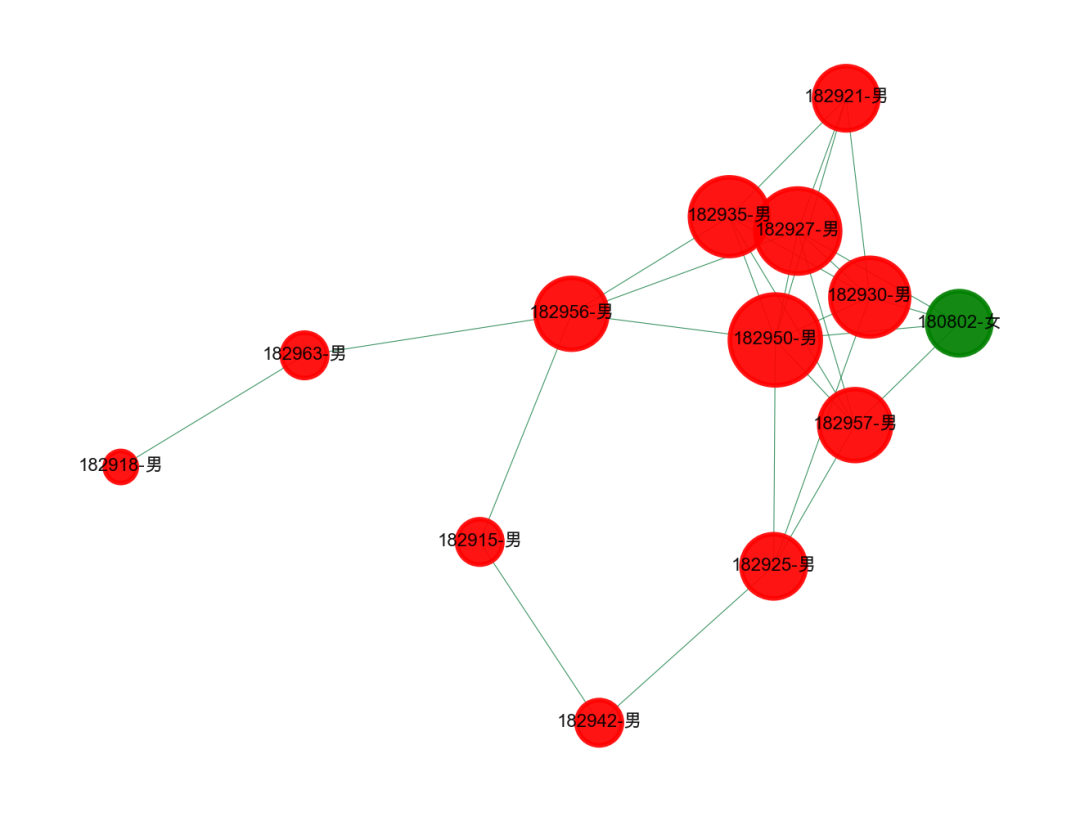
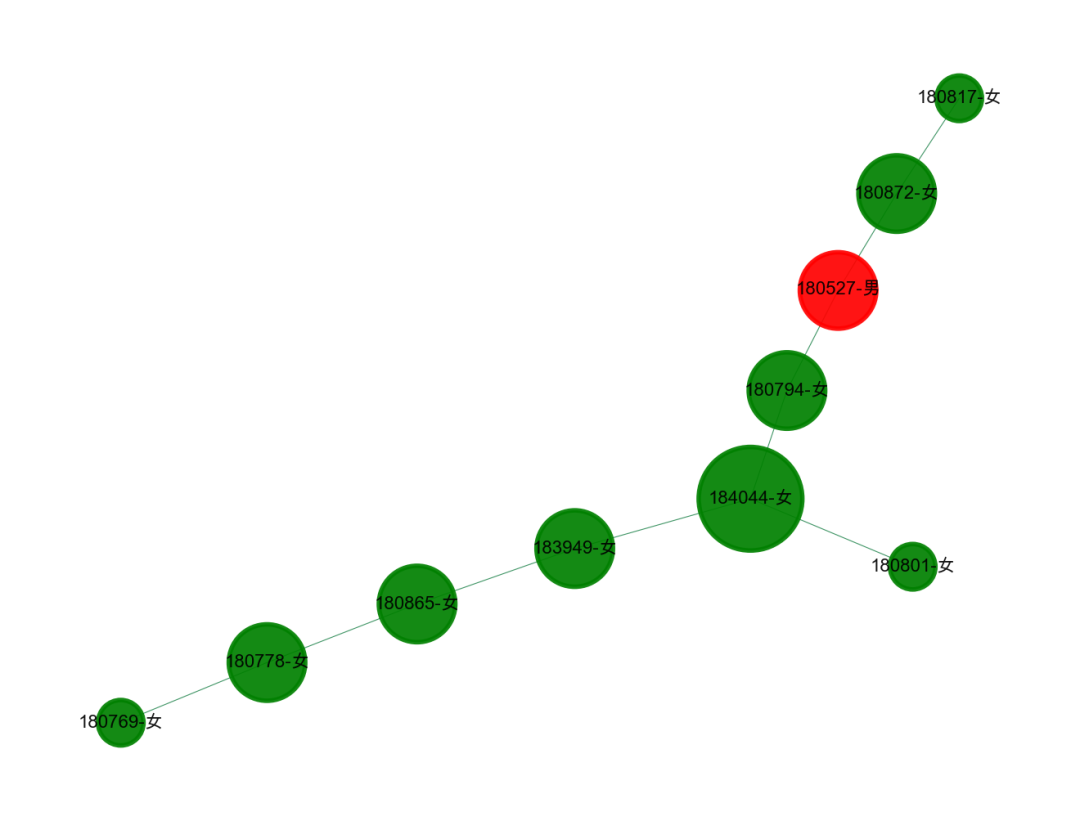
2、文科班的男生真幸福?
和刚刚不一样的,这里有个团伙,都是女生,其中只有一个男生,可以说是非常幸福了,应该是文科班的。
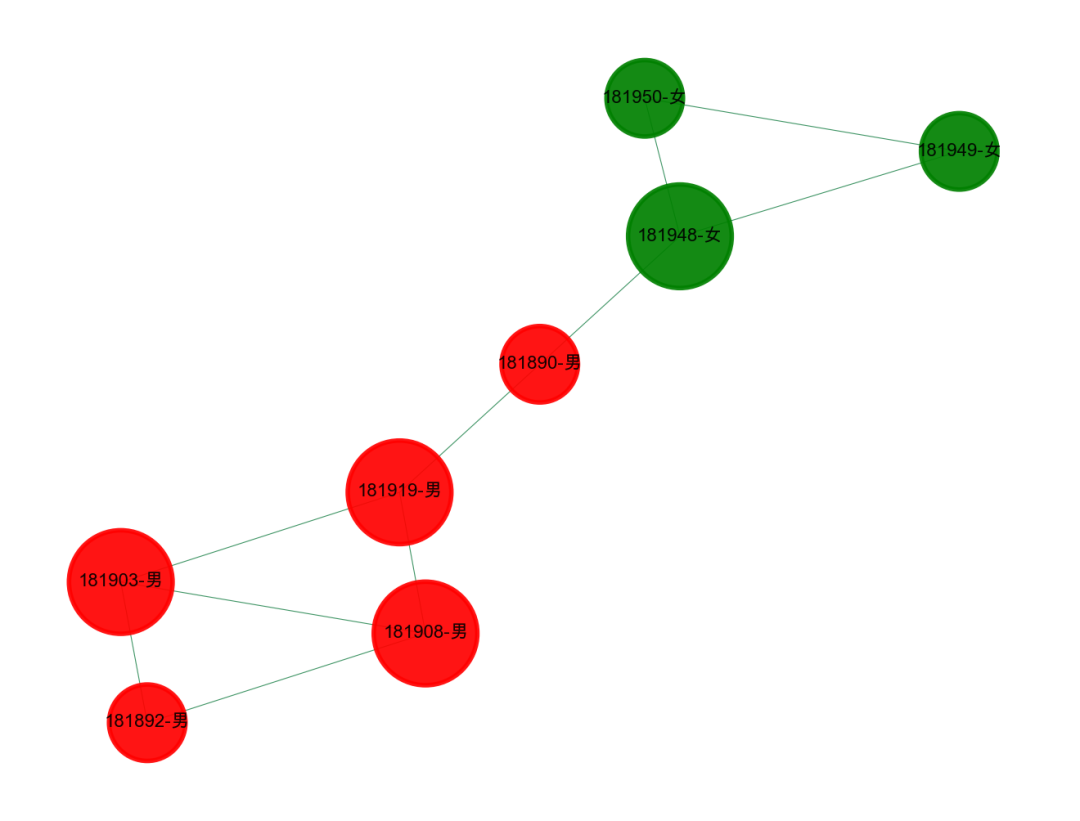
3、两个宿舍的联姻?
进一步的挖掘,发现下面这种形式,大家可以看到更多的信息,是不是两个宿舍凑成的一对情侣
我们也可以换一些颜色去标记
#提取某一个群组进行可视化,根据每个社群的节点,去找边。i = 1edges = []for k,v in zip(df_3['校园卡号_x'].tolist(),df_3['校园卡号_y'].tolist()):if k in com[i] or v in com[i]:edges.append((k,v))#转换成图结构,可以从元组列表直接构建图G = nx.Graph(edges)#节点大小设置,与度关联node_size = [G.degree(i)**0.6*50 for i in G.nodes()]#设置颜色 随机来点colors = ['#43CD80','DeepPink','orange','#008B8B','purple','#63B8FF','#BC8F8F','#3CB371','b','orange','y','c','#838B8B','purple','olive','#A0CBE2','#4EEE94']*30colors = colors[0:len(G.nodes())]import randomnode_color = random.sample(colors, len(G.nodes()))# 红男绿女# colors_dic = {'男':'r','女':'#008000'}# node_color = [ colors_dic[i.split('-')[1]] for i in G.nodes()]#设置显示图片大小plt.figure(figsize=(4,3),dpi=1400)## 图像显示中文的问题plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']plt.rcParams['axes.unicode_minus'] = False#可以替换两种不同的布局看看效果 kamada_kawai_layout spring_layoutnx.draw_networkx(G,pos = nx.spring_layout(G,iterations=30),node_color = node_color,edge_color = '#2E8B57',#with_labels=False,font_size = 2,node_size = node_size,alpha = 0.98,width = 0.1)plt.axis('off')plt.show()
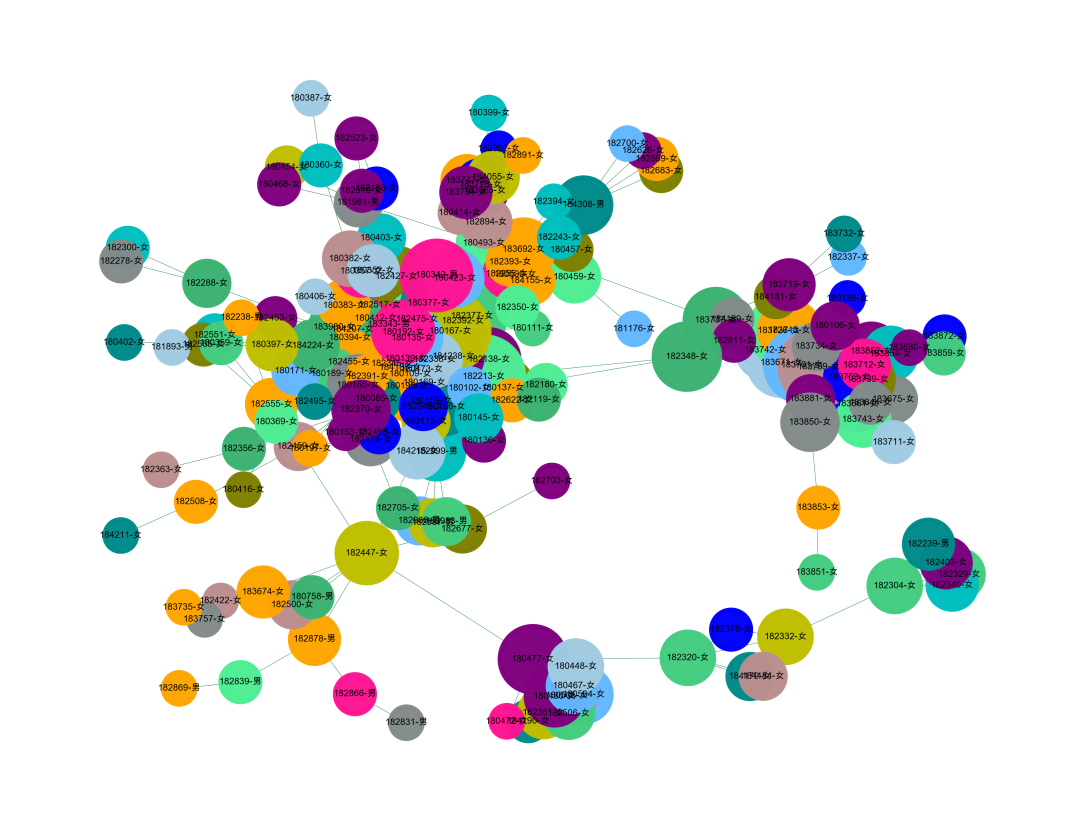

八、回到风控
我们分析用的是校园刷卡数据,这样的时序数据,在风控业务中,随处可见
订单下单明细数据
领券明细数据
信用卡刷卡数据
点赞数据
直播间登录评论数据
投票数据
微博关注数据
····
非常多的这种数据,我们可以通过时序关联的方法挖掘出来其中的时空关系,从而确定多个有一致行动的用户,达到一起打击的目的。
通过构图可以挖掘出黑灰产,通过图的连接,我们可以追踪和推理黑灰产的作案模式,甚至你知道他们账户在表格里面的存储顺序,一堆账号总是先后的顺序出现。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









