







大家好,我是小伍哥。
基于介质的关系构建,文章挺多的,但是基于内容的关系构建,相对比较少的。
这周恰好给同济大学的学生讲了一节课,今天分享下,这是周二讲义的一小部分内容。不是最优方法,但是简单粗暴,提供个思路给大家参考。
背景是用户有很多内容集合,但是每个内容集合的东西很凌乱。咋一看,很多东西都差不多,细看又不一样。
比如商家,很多黑灰产商家,店铺很相似,但是每次都会变换点内容。
比如短视频用户,黑灰产起号的文案也是大差不差的。
比如刷评论的用户,文案也是很相似。
很多人说,很相似,为哈不用有监督呢?正常情况是可以的,但是现在黑灰产变化太快,快到甚至都来不及分析黑样本,这一波就结束了,又开始下一波了。所以基于图的方法,有更好的鲁棒性,更好的对抗性。
可以采用无监督+属性监控
也可以采用弱监督,比如输入一个关键词,然后找到对应的商品集合,再找到商家集合,就能拔出萝卜带出泥。经过大量的实战,这个方法还是非常有效的。
title_lsit1 = {'title1':'自助购买 自动发货 秒发货45','title2':'老客户 直接拍 全天 秒发货554','title3':'差价链接'}
title_lsit2 = {'title1':'全天 自动 24h 秒发货 44544','title2':'顾客 链接 补拍 秒 发5548','title3':'差价链接'}
看起来大差不差的,用户只是做少量的调整,面对这种情况,我但是第一反应就是做文本相似构图,但是发现用户量太多,随便就是上亿的。算了很久也没解决。后面想到个更粗暴的办法,直接用关键词匹配就能计算非常大的量。并且关键词匹配后,可以用相似度算法进一步校准。这样相当与做了个降维。
并且在匹配的时候,可以考虑假如属性进一步降维,比如是否都是低星级,注册时间是否都低于3个月、是否都是小卖家等等,降维的同时提高精度,非常适合大量文本做相似度构图。虽然大规模文本处理的方法很多,我还是喜欢这种高效粗暴的办法,大家可以参考下。
先来读取下数据。试验数据获取方法,关注【小伍哥聊风控】后台回复「商品数据」大家也可以去网站上找些样本或者自己手里有数据集的话测试下。
# 数据读取 数据获取,关注【小伍哥聊风控】后台回复「商品数据」import osos.chdir('/Users/wuzhengxiang/Documents/同济大学')data = pd.read_csv('商品样本.csv')data.head(20)
构建关键词提取函数
# 加载需要的包 这里用的结巴 jiebafrom jieba import analyse'''通过 jieba.analyse.extract_tags()方法可以基于 TF-IDF 算法进行关键词提取,该方法共有 4 个参数:sentence:为待提取的文本topK:为返回几个 TF/IDF 权重最大的关键词,默认值为 20withWeight:是否一并返回关键词权重值,默认值为 FalseallowPOS:仅包括指定词性的词,默认值为空通过这个函数可以知道有多少种分析方法print(dir(analyse))'''# 查看下测试结果s = "自助购买 自动发货 秒发货45 老客户 直接拍 全天 秒发货554 差价链接"analyse.extract_tags(s,topK=10,withWeight=False)['发货', '45', '554', '老客户', '自助', '差价', '链接', '全天', '自动', '购买']# 构建关键词提取函数def KeyWord(s):return ';'.join(sorted(analyse.extract_tags(s,topK=10,withWeight=False)))# 测试下KeyWord(s)['发货', '45', '554', '老客户', '自助', '差价', '链接', '全天', '自动', '购买']
进行行转多列
# 行转列,按商家进行合并,多行转换成一行df = data.groupby(['商家名称']).agg({'商品标题':[' '.join]}).reset_index()df.columns = ['商家名称','商品标题']df.head(20)
可以看到下面的结果,我们把多个商品合并成一行了

对每个商家进行关键词提取
# 每个商家的商品关键词进行提取df['KeyWord'] = df['商品标题'].apply(KeyWord)df['KeyWord1'] = df['KeyWord'] #留一行备用df.head(12)
看看提取关键词后的格式

# 按关键词进行分列,行转列,好用关键词当主键进行关联da = df.set_index(["商家名称", "商品标题","KeyWord"])["KeyWord1"].str.split(";", expand=True).stack().reset_index(drop=True, level=-1).reset_index().rename(columns={0: "word"})da.head()
转换后的结果如下
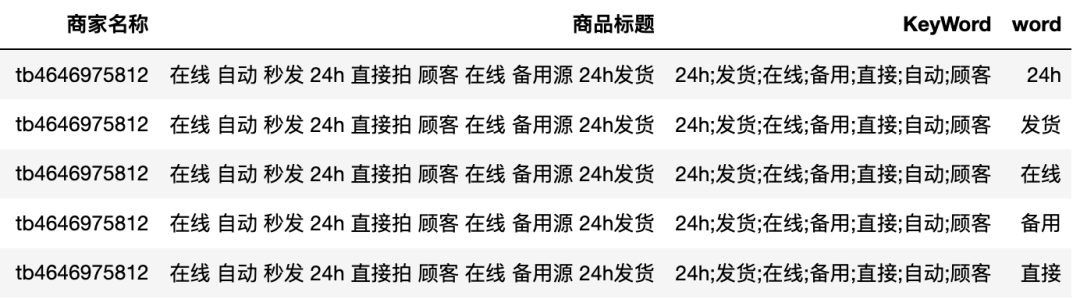
# 通过关键词进行匹配df_join = da.merge(da,on='word')df_join
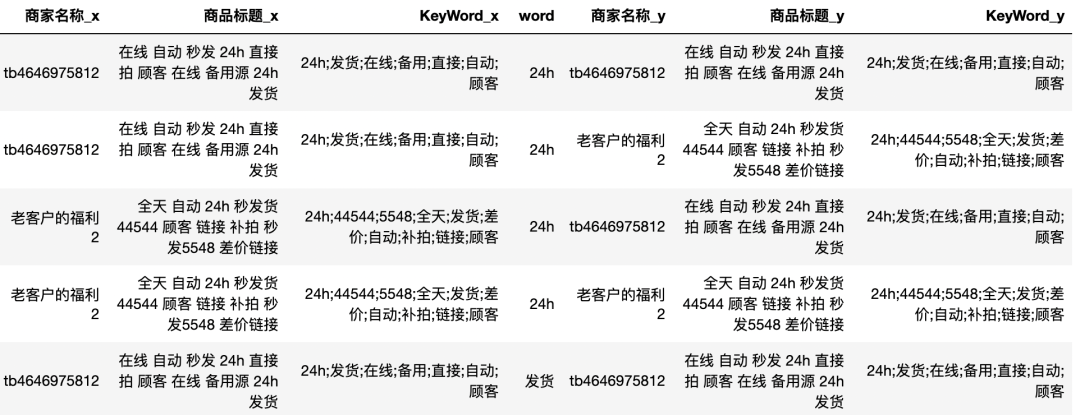
# 聚合统计da_groupby = df_join.groupby(['商家名称_x','商家名称_y','KeyWord_x','KeyWord_y']).agg({'word': pd.Series.nunique}).reset_index().copy()da_groupby = da_groupby[da_groupby['商家名称_x']!=da_groupby['商家名称_y']]# 对关联次数进行筛选,根据自己的关联强度,设置恰当的阈值last = da_groupby[da_groupby['word']>=2]last
做了上面的,我们就得到了一张图
'''Create Oct 15 09:37:54 2023@公众号:小伍哥聊风控'''#先简单的,整体的可视化我们的数据集,如果样本比较多,这一步是无法完成的,需要社群划分后再进行可视化。import networkx as nximport matplotlib.pyplot as plt# 设置不同的阈值last = da_groupby[da_groupby['word']>=3]# 构建成图数据格式d_g = last[['商家名称_x','商家名称_y']].valuesG = nx.Graph()for num in range(len(d_g)):G.add_edge(str(d_g[num,0]),str(d_g[num,1]))#节点大小设置,与度关联node_size = [G.degree(i)**0.5*25 for i in G.nodes()]#设置颜色 随机来点colors = ['#43CD80','DeepPink','orange','#008B8B','purple','#63B8FF','#BC8F8F',\'#3CB371','b','orange','y','c','#838B8B','purple','olive','#A0CBE2','#4EEE94']*500colors = colors[0:len(G.nodes())]#设置显示图片大小plt.figure(figsize=(3,2),dpi=800)## 图像显示中文的问题plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']plt.rcParams['axes.unicode_minus'] = False#可以替换两种不同的布局看看效果,kamada_kawai_layout spring_layoutnx.draw_networkx(G,pos = nx.spring_layout(G,iterations=12),node_color = colors,edge_color = '#2E8B57',font_size = 2.1,node_size = node_size,alpha = 0.98,width = 0.1)plt.axis('off')plt.show()
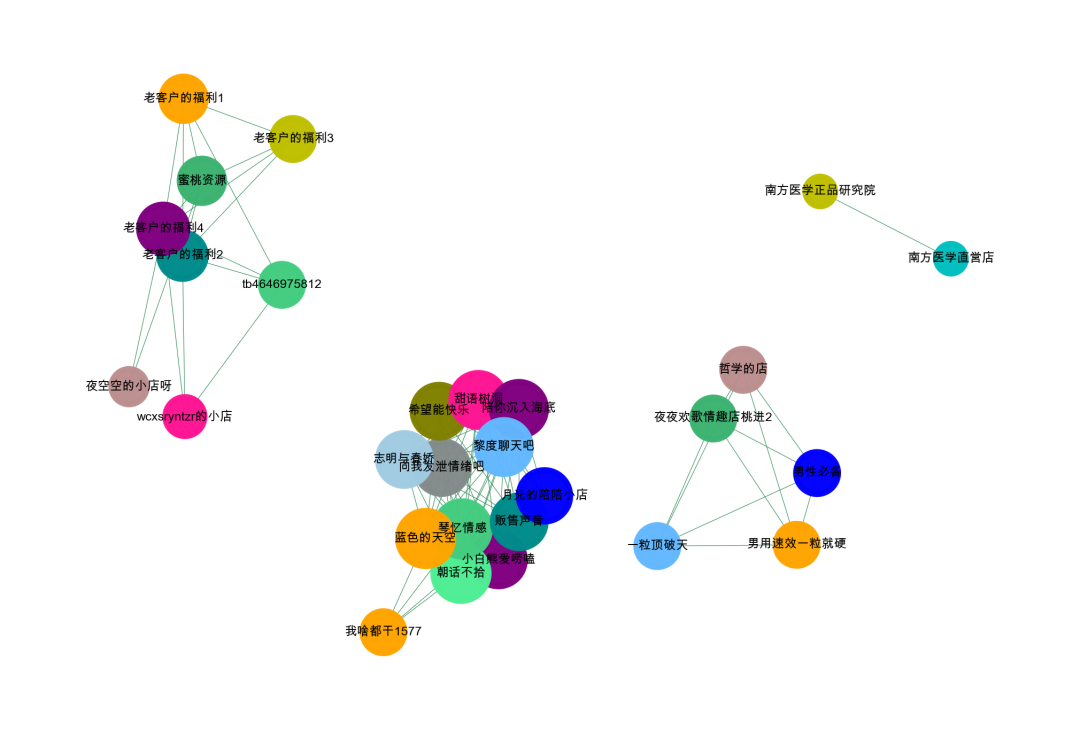
社群挖掘
# 用极大连通子图算法com = list(nx.connected_components(G))# 将 列表-集合 整理成数据表格形式df_com = pd.DataFrame()for i in range(0, len(com)):d = pd.DataFrame({'group_id': [i] * len(com[i]), 'user_id': list(com[i])})df_com = pd.concat([df_com,d])# 查看数据结果df_com#单个社群可视化,可以看看我之前的文章
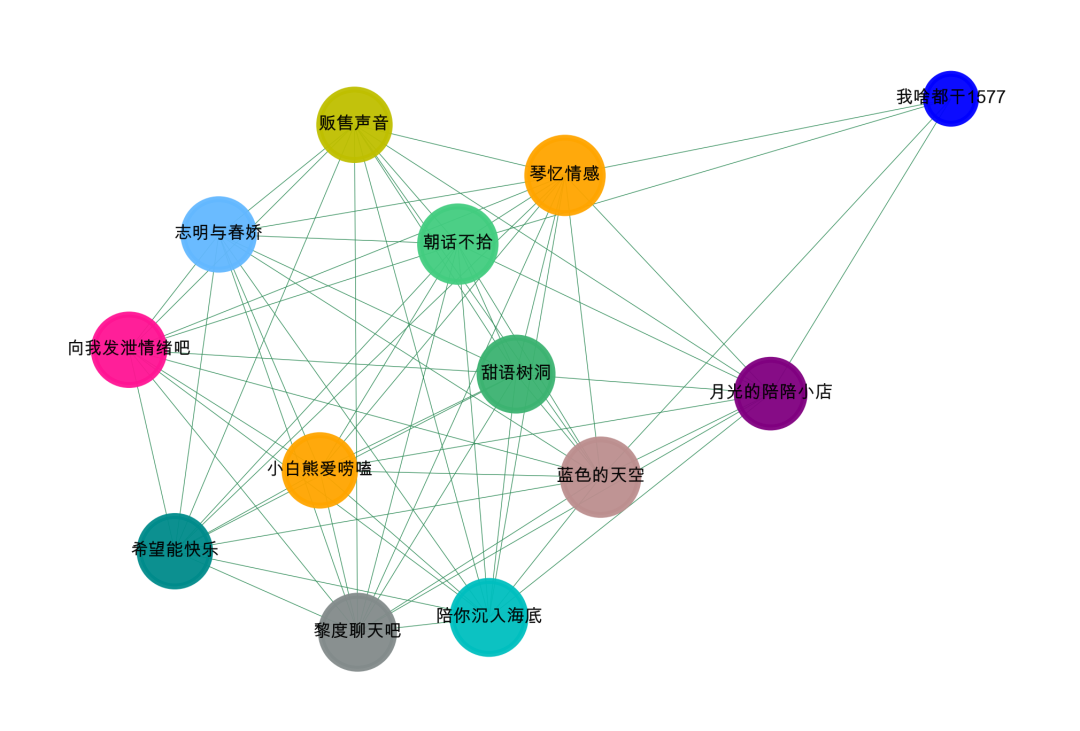
可视化的时候加上关键词
#先简单的,整体的可视化我们的数据集,如果样本比较多,这一步是无法完成的,需要社群划分后再进行可视化。import networkx as nximport matplotlib.pyplot as plt# 设置不同的阈值last = da_groupby[da_groupby['word']>=3]# 构建成图数据格式d_g = pd.DataFrame()d_g['商家名称_x'] = 'name: '+last['商家名称_x']+'\n'+'word: '+last['KeyWord_x']d_g['商家名称_y'] = 'name: '+last['商家名称_y']+'\n'+'word: '+last['KeyWord_y']d_b = d_g[['商家名称_x','商家名称_y']].valuesG = nx.Graph()for num in range(len(d_b)):G.add_edge(str(d_b[num,0]),str(d_b[num,1]))# 用极大连通子图算法com = list(nx.connected_components(G))#提取某一个群组进行可视化,根据每个社群的节点,去找边。i = 0edges = []for k,v in zip((d_g['商家名称_x']).tolist(),(d_g['商家名称_y']).tolist()):if k in com[i] or v in com[i]:edges.append((k,v))#转换成图结构,可以从元组列表直接构建图G = nx.Graph(edges)#节点大小设置,与度关联node_size = [G.degree(i)**1.45*20 for i in G.nodes()]#设置颜色 随机来点colors = ['#43CD80','DeepPink','orange','#008B8B','purple','#63B8FF','#BC8F8F','#3CB371','b',\'orange','y','c','#838B8B','purple','olive','#A0CBE2','#4EEE94']*50colors = colors[0:len(G.nodes())]import randomcolors = random.sample(colors, len(G.nodes()))#设置显示图片大小fig = plt.figure(figsize=(3,3),dpi=1200)fig.set_facecolor("w") #设置背景颜色,可以换成red、yellow、blue## 图像显示中文的问题plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']plt.rcParams['axes.unicode_minus'] = False#可以替换两种不同的布局看看效果 kamada_kawai_layout spring_layoutnx.draw_networkx(G,pos = nx.spring_layout(G),node_color = colors,edge_color = '#2E8B57',font_size = 2.5,node_size = node_size,alpha = 0.9,width = 0.1)plt.axis('off')#plt.savefig( "keyword.png", format="PNG")plt.show()
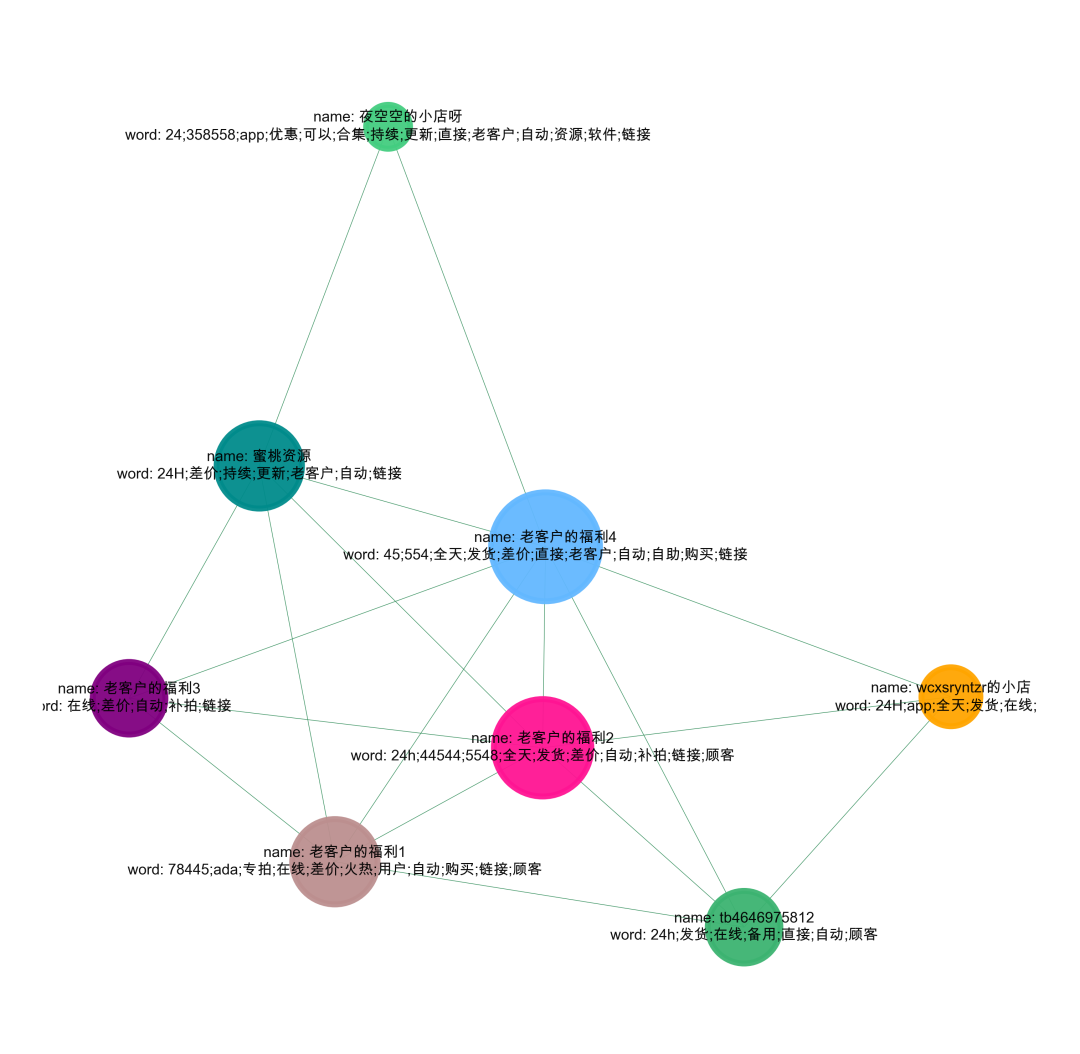
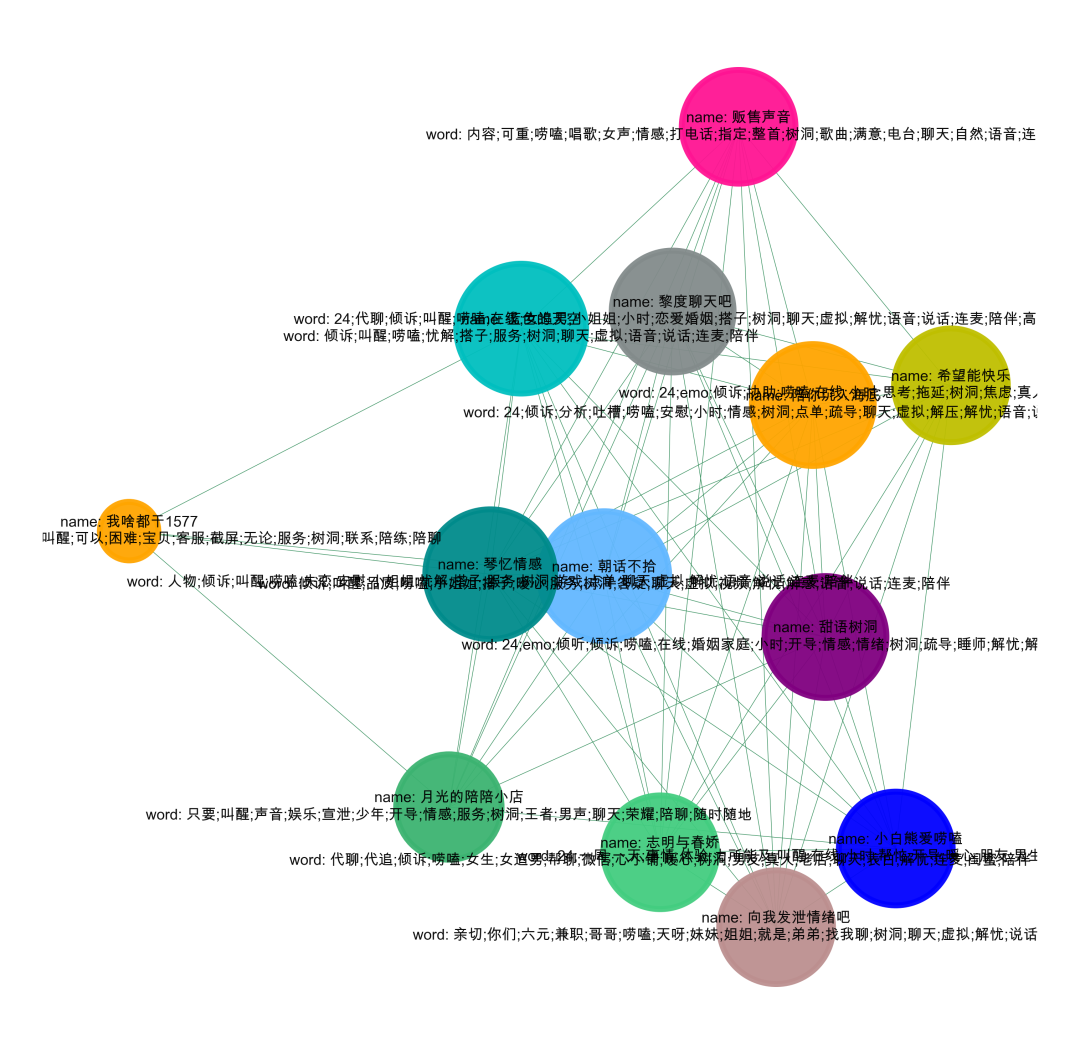
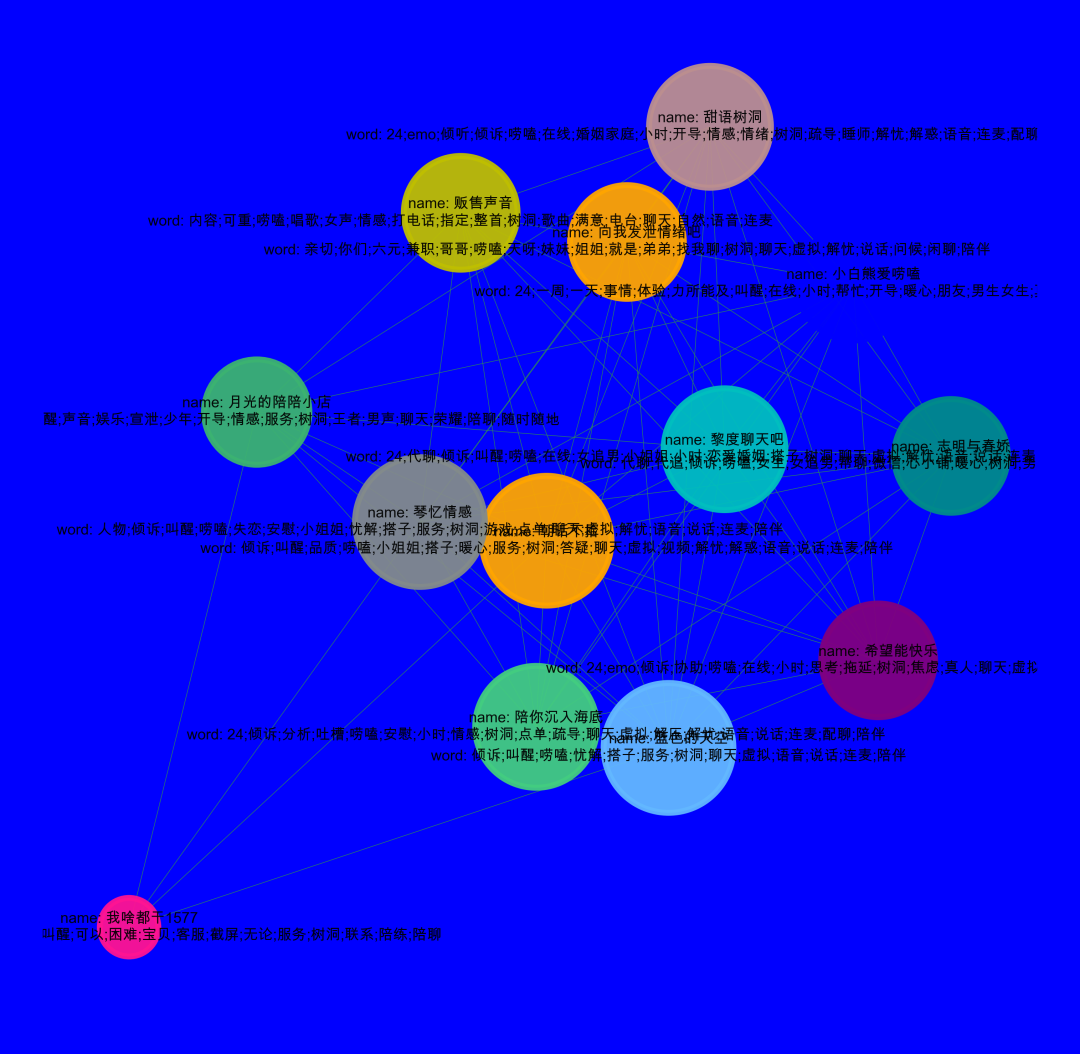
















 560
560











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









