






上次分享了非常牛逼的不需要介质就能进行团伙挖掘的算法,大家都说是个好算法,但是实现细节还是有些问题。文章传送门:SynchroTrap-基于松散行为相似度的欺诈账户检测算法
由此可见,风控的实践大于算法,就像绘画,给我同样的材料,打死我都成不了梵高。所以风控一定要多看多试验。我这里用一个简单的数据集,具体的把实现过程分享出来,并图解每一步的原理,希望对大家有帮助。【有问题加我咨询,尽量解答】
一、梳理已有或者想应用的场景
首先需要梳理满足该算法数据条件的场景,最少的条件就是:用户+时间戳。举例一些具体的场景,大家感官更明显。
用户下单环节(A、B用户多天总是在较短的时间内购买商家A,然后是商家B)
用户A 2021-11-16 21:22:02 商家A
用户B 2021-11-16 21:32:02 商家A
······
用户A 2021-11-18 11:18:02 商家B
用户B 2021-11-18 11:54:01 商家B
某个领券环节(A、B用户多天总是在较短的时间内去领券)
用户A 2021-11-16 21:22:02 活动A
用户B 2021-11-16 21:32:02 活动A
······
用户A 2021-11-18 11:18:02 活动B
用户B 2021-11-18 11:54:01 活动B
还有更多的环节,都可能存在这种同步行为
电商的评价环节
拼多多的砍价活动
抖音的点赞/关注
微信的投票
上述一系列的活动,存在一些利益群体,控制大量的账号,并且在不同的时间,同时去完成上述的任务,则可能存在同步行为,我们就可以构建图网络,把他们一网打尽。
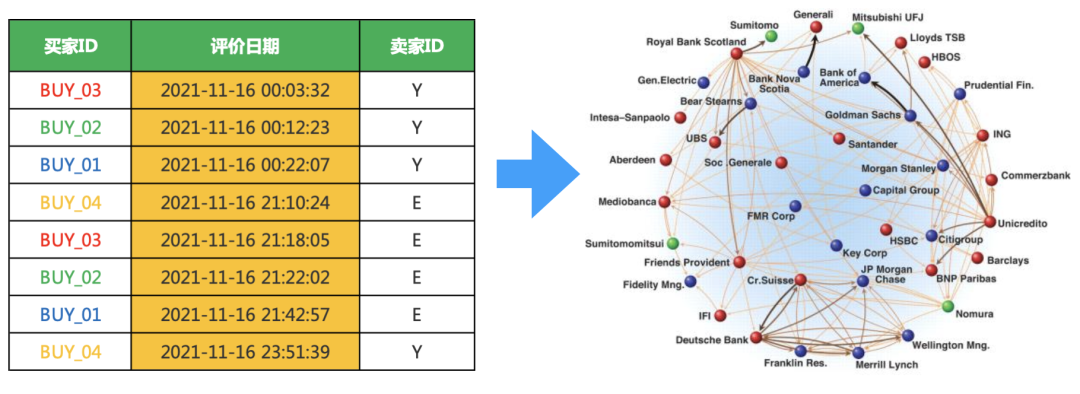
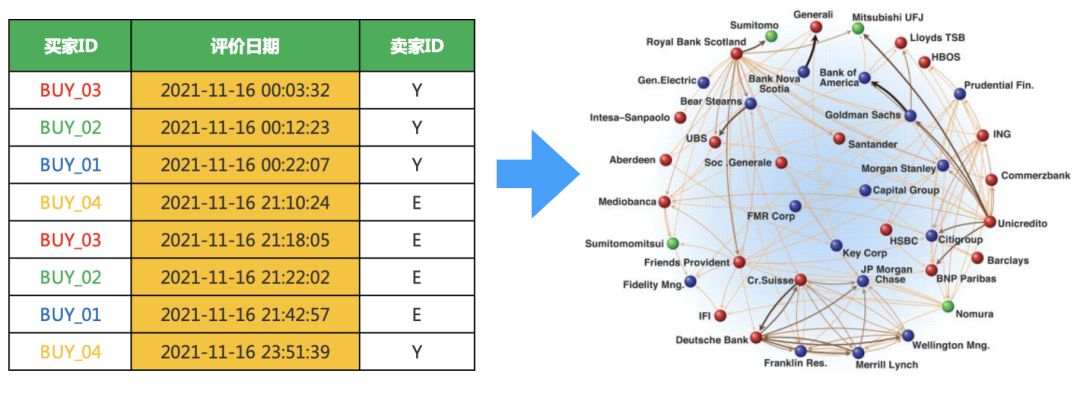
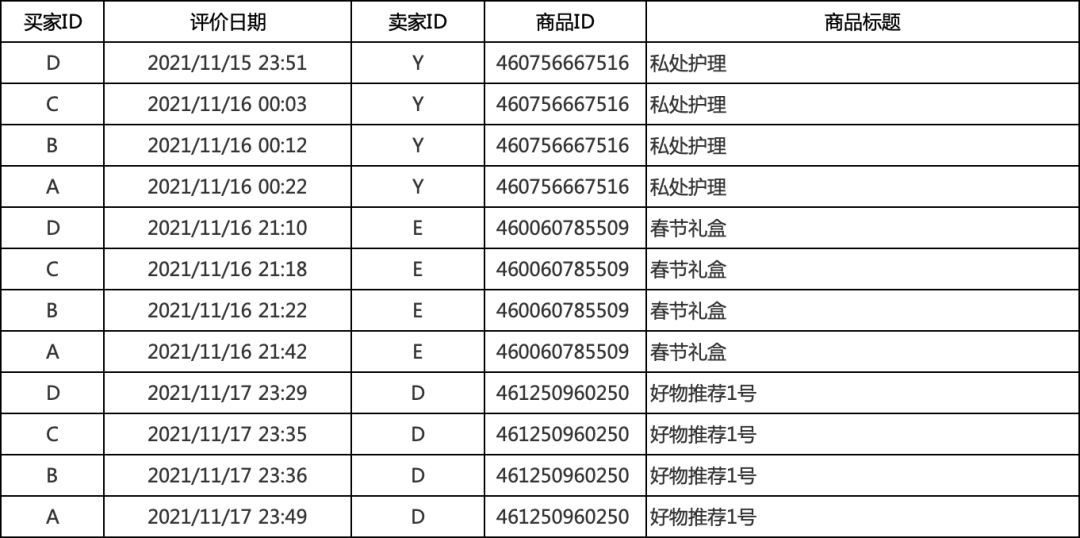
我们本次使用评价数据进行讲解,数据格式如下
![]()
二、数据处理环节
面对大规模的数据,我一般都是按场景-天进行拆分,然后天-场景进行合并,最后得出一个更大规模的图。可以多场景日志数据聚合到一起进行挖掘,也可以单一场景计算完了在聚合,我建议第二种方法,计算量更小,并且算完一个场景就能够落地应用了,项目时间不会太长。
最难处理的就是时间差这个环节,下面我们开始:
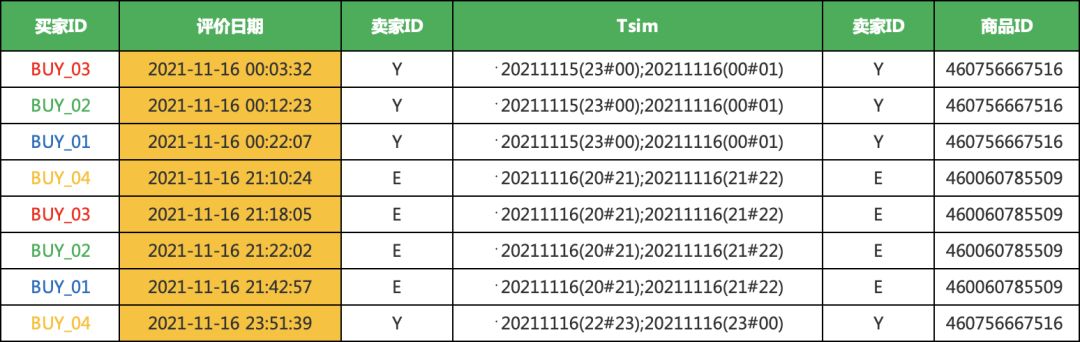
1、首先我们需要做的就是把时间离散化(我按小时计算)
具体的就是以当前小时为中心,向前一小时,向后一小,我写了函数,可以直接使用。如下的例子。0点分为了(23,0)(0,1),23为前一天的。
2021-11-16 00:03:32
20211115(23#00) 20211116(00#01)
函数写好了后,对每个时间应用。
import datetimedef Time2Str(tsm):t1 = datetime.datetime.fromisoformat(tsm)t0 = t1-datetime.timedelta(days=0, hours=1)t2 = t1+datetime.timedelta(days=0, hours=1)str1 = t0.strftime("%Y%m%d")+'(' +str(t0.hour).rjust(2,'0')+'#'+str(t1.hour).rjust(2,'0')+')'str2 = t1.strftime("%Y%m%d")+'(' +str(t1.hour).rjust(2,'0')+'#'+str(t2.hour).rjust(2,'0')+')'return str1+';'+str2Time2Str('2021-11-16 15:51:39')#测试下'20211116(14#15);20211116(15#16)'
![]()
我们把上面的数据系统化,后面的案例好用
import pandas as pddf = pd.DataFrame({'Buy':['BUY_03','BUY_02','BUY_01','BUY_04','BUY_03','BUY_02','BUY_01','BUY_04'],'Times':['2021-11-16 00:03:32','2021-11-16 00:12:23','2021-11-16 00:22:07','2021-11-16 21:10:24',\'2021-11-16 21:18:05','2021-11-16 21:22:02','2021-11-16 21:42:57','2021-11-16 23:51:39'],'Seller':['Y','Y','Y','E','E','E','E','Y']})# 时间离散化df['tsm'] = df['Times'].apply(Time2Str)
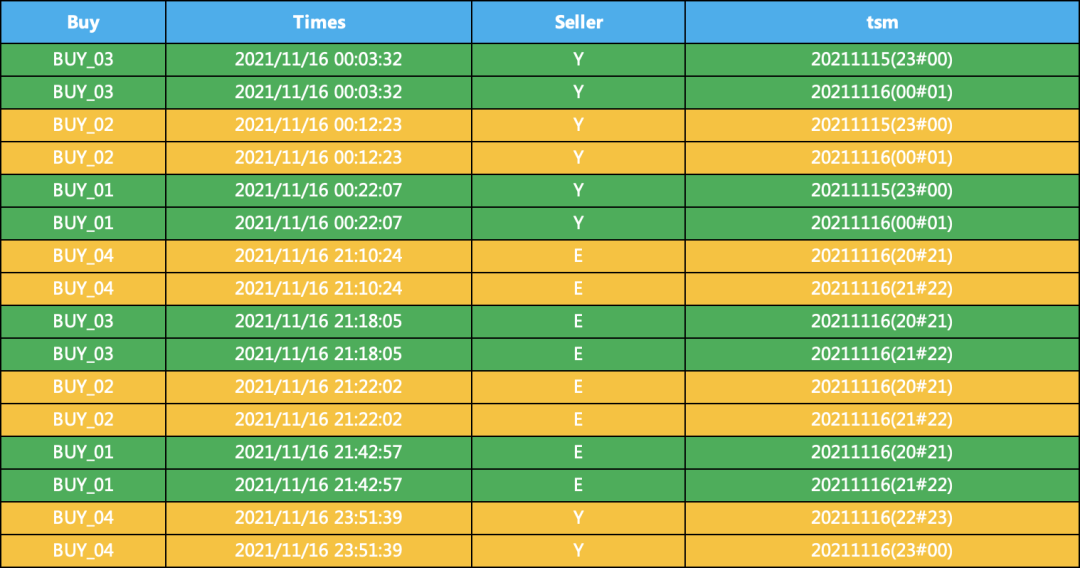
2、对数据进行裂变,一行变两行,这一步是关键,需要重点理解
离散化以后,需要一行变多行,为的就是同一个小时内的两个对象能够匹配,一行变多行的代码如下。SQL的话,也是对应的函数的,比Pandas简单很多
df = df.set_index(["Buy", "Times",'Seller'])["tsm"].str.split(";", expand=True)\.stack().reset_index(drop=True, level=-1).reset_index().rename(columns={0: "tsm"})print(df)
3、数据表进行自我匹配,并还需要作差,时间限定小于自己的阈值
对于变完之后的数据,进行匹配,加了时间约束和商家约束,['Seller','tsm'],当然你也可以只加时间约束,不加商家约束。约束计算完了,还需要进一步计算,其实匹配完的是2小时内的,还需要作差计算一小时内的,不满足条件的排除,并且把自己和自己匹配的也要排除,没啥意义。计算完了得到下面的结果。
df_0 = pd.merge(df,df,on =['Seller','tsm'],how='inner')df_1 = df_0[df_0['Buy_x']!=df_0['Buy_y']]df_1['diff'] = (pd.to_datetime(df_0['Times_x'])-\pd.to_datetime(df_0['Times_y'])).dt.seconds/3600/24
![]()
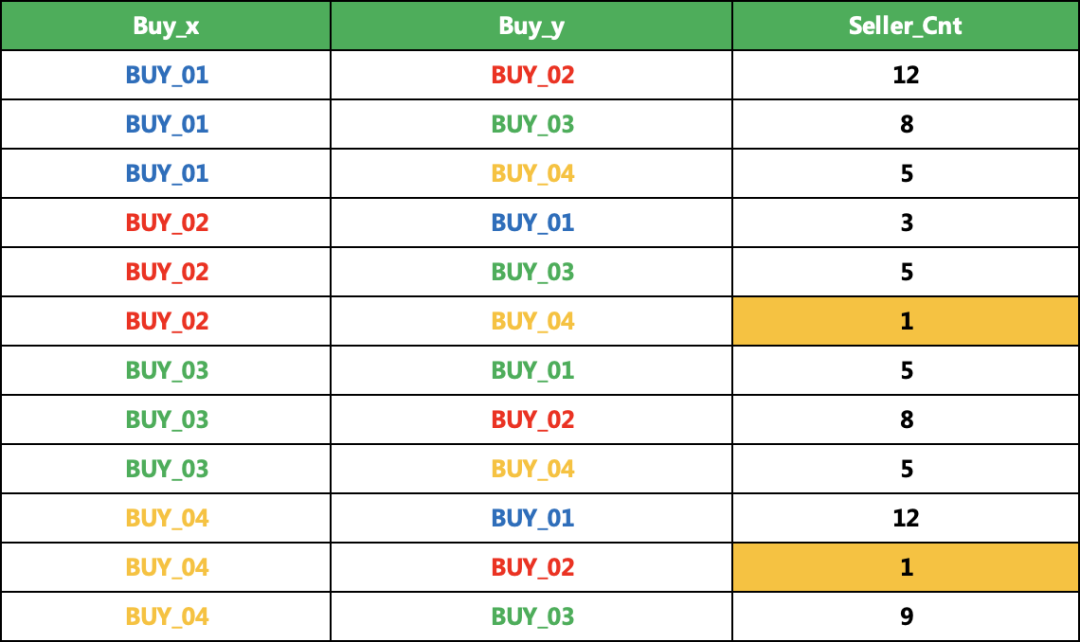
4、一天的数据聚合就得到下面的结果了
匹配得到的是明细数据,还需要进行聚合,得到两个用户相交的次数,就可以得到再当天的一个关联情况了。如下图所示:
# 数据聚合df_1.groupby(['Buy_x','Buy_y']).agg({'Seller': pd.Series.nunique}).reset_index()
![]()
![]()
5、多天的数据聚合
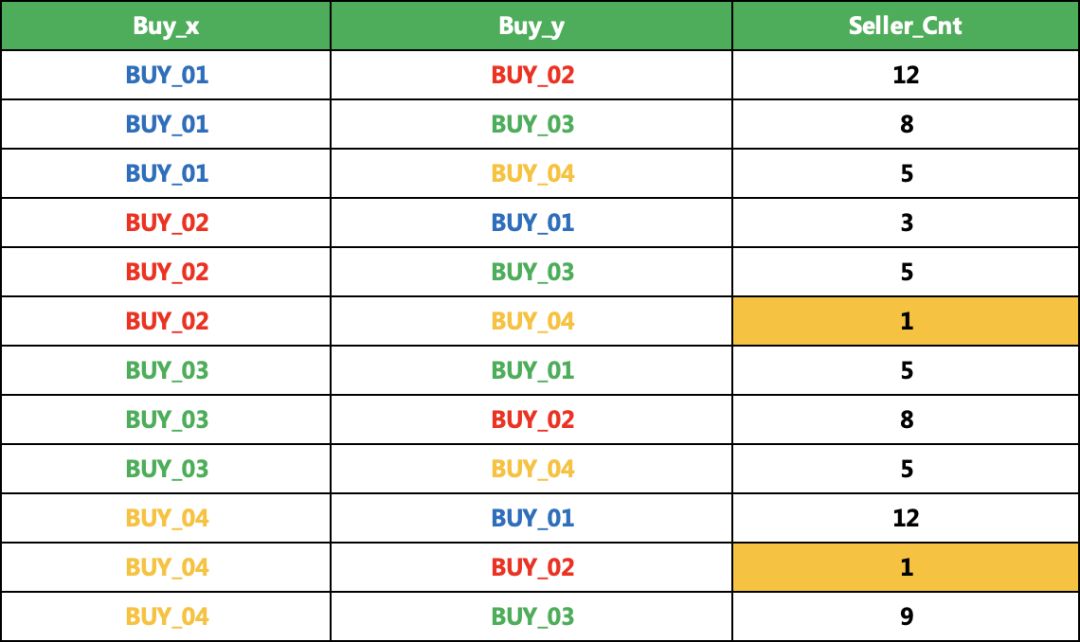
多天数据进行聚合,假如我们的阈值是大于2,那标黄的部分,就将被舍弃掉
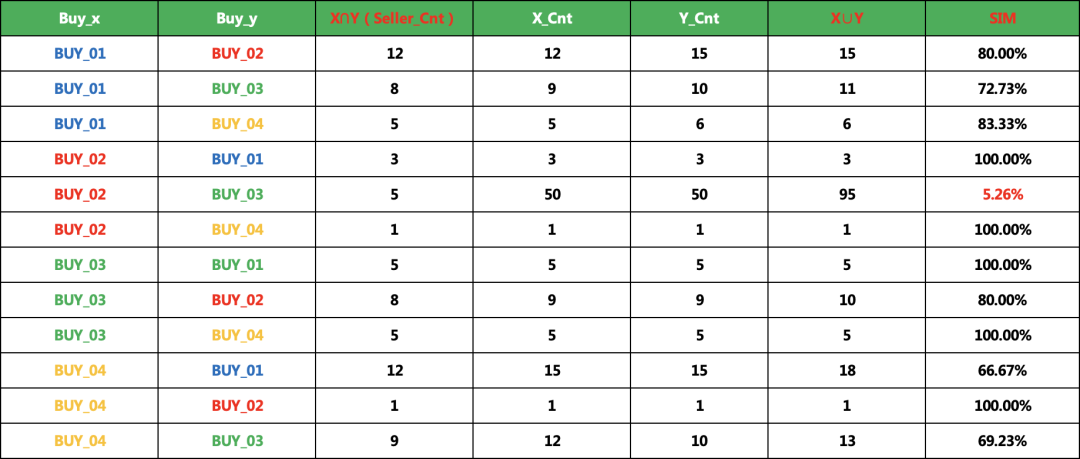
6、总体相似度计算
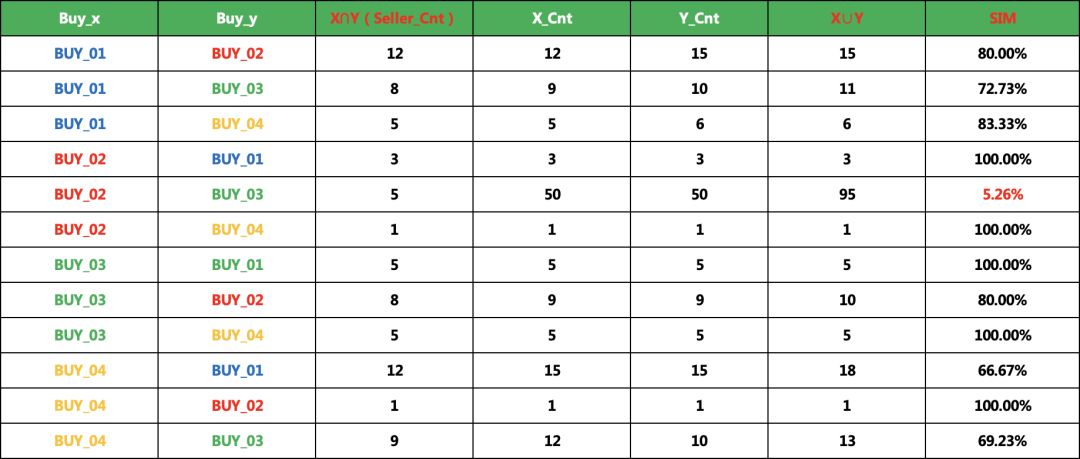
聚合了,还要进行相似度计算,分别计算每个用户出现的总次数。为什么要计算这个呢,举一个极端的例子,假如用户A自己出现了一万次,与B共同出现了5次,那这可能是巧合,但是如果A总共出现了5次,且5次都和B出现,那他俩是团伙的概率要大很多。
按上面的数据,我们还要单独计算X出现的次数,Y出现的次数,并且X+Y-X∩Y求出并集,就可以用杰卡德算法进行相似度计算了,把相似度低的排除即可
到此计算完了之后,就可以构图环节就算完成了,下一步是如何进行分群,我们这里采用LPA标签传播算法就可以。今天先讲到这里了,分群的下次再讲,比较简单。
往期精彩:
长按关注公众号 长按加好友
上次分享了非常牛逼的不需要介质就能进行团伙挖掘的算法,大家都说是个好算法,但是实现细节还是有些问题。文章传送门:SynchroTrap-基于松散行为相似度的欺诈账户检测算法
由此可见,风控的实践大于算法,就像绘画,给我同样的材料,打死我都成不了梵高。所以风控一定要多看多试验。我这里用一个简单的数据集,具体的把实现过程分享出来,并图解每一步的原理,希望对大家有帮助。
一、梳理已有或者想应用的场景
首先需要梳理满足该算法数据条件的场景,最少的条件就是:用户+时间戳。举例一些具体的场景,大家感官更明显。用户下单环节(A、B用户多天总是在较短的时间内购买商家A,然后是商家B)
用户A 2021-11-16 21:22:02 商家A用户B 2021-11-16 21:32:02 商家A······用户A 2021-11-18 11:18:02 商家B用户B 2021-11-18 11:54:01 商家B
某个领券环节(A、B用户多天总是在较短的时间内去领券)
用户A 2021-11-16 21:22:02 活动A
用户B 2021-11-16 21:32:02 活动A
······
用户A 2021-11-18 11:18:02 活动B
用户B 2021-11-18 11:54:01 活动B
还有更多的环节,都可能存在这种同步行为
电商的评价环节
拼多多的砍价活动
抖音的点赞/关注
微信的投票
上述一系列的活动,存在一些利益群体,控制大量的账号,并且在不同的时间,同时去完成上述的任务,则可能存在同步行为,我们就可以构建图网络,把他们一网打尽。我们本次使用评价数据进行讲解,数据格式如下
二、数据处理环节
面对大规模的数据,我一般都是按场景-天进行拆分,然后天-场景进行合并,最后得出一个更大规模的图。可以多场景日志数据聚合到一起进行挖掘,也可以单一场景计算完了在聚合,我建议第二种方法,计算量更小,并且算完一个场景就能够落地应用了,项目时间不会太长。最难处理的就是时间差这个环节,下面我们开始:
1、首先我们需要做的就是把时间离散化(我按小时计算)
具体的就是以当前小时为中心,向前一小时,向后一小,我写了函数,可以直接使用。如下的例子。0点分为了(23,0)(0,1),23为前一天的。
2021-11-16 00:03:32
20211115(23#00) 20211116(00#01)
函数写好了后,对每个时间应用。
import datetime
def Time2Str(tsm):
t1 = datetime.datetime.fromisoformat(tsm)
t0 = t1-datetime.timedelta(days=0, hours=1)
t2 = t1+datetime.timedelta(days=0, hours=1)
str1 = t0.strftime("%Y%m%d")+'(' +str(t0.hour).rjust(2,'0')+'#'+str(t1.hour).rjust(2,'0')+')'
str2 = t1.strftime("%Y%m%d")+'(' +str(t1.hour).rjust(2,'0')+'#'+str(t2.hour).rjust(2,'0')+')'
return str1+';'+str2
Time2Str('2021-11-16 15:51:39')#测试下
'20211116(14#15);20211116(15#16)'
我们把上面的数据系统化,后面的案例好用
import pandas as pd
df = pd.DataFrame({
'Buy':['BUY_03','BUY_02','BUY_01','BUY_04','BUY_03','BUY_02','BUY_01','BUY_04'],
'Times':['2021-11-16 00:03:32','2021-11-16 00:12:23','2021-11-16 00:22:07','2021-11-16 21:10:24',\
'2021-11-16 21:18:05','2021-11-16 21:22:02','2021-11-16 21:42:57','2021-11-16 23:51:39'],
'Seller':['Y','Y','Y','E','E','E','E','Y']
})
# 时间离散化
df['tsm'] = df['Times'].apply(Time2Str)2、对数据进行裂变,一行变两行,这一步是关键,需要重点理解
离散化以后,需要一行变多行,为的就是同一个小时内的两个对象能够匹配,一行变多行的代码如下。SQL的话,也是对应的函数的,比Pandas简单很多
df = df.set_index(["Buy", "Times",'Seller'])["tsm"].str.split(";", expand=True)\
.stack().reset_index(drop=True, level=-1).reset_index().rename(columns={0: "tsm"})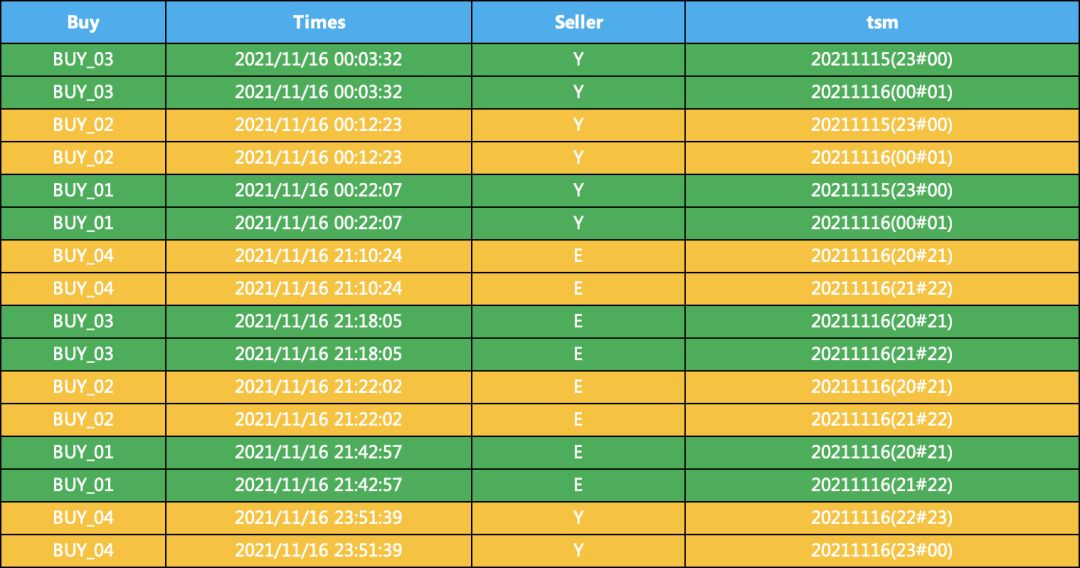
3、数据表进行自我匹配,并还需要作差,时间限定小于自己的阈值
对于变完之后的数据,进行匹配,加了时间约束和商家约束,['Seller','tsm'],当然你也可以只加时间约束,不加商家约束。约束计算完了,还需要进一步计算,其实匹配完的是2小时内的,还需要作差计算一小时内的,不满足条件的排除,并且把自己和自己匹配的也要排除,没啥意义。计算完了得到下面的结果。
df_0 = pd.merge(df,df,on =['Seller','tsm'],how='inner')
df_1 = df_0[df_0['Buy_x']!=df_0['Buy_y']]
df_1['diff'] = (pd.to_datetime(df_0['Times_x'])-\
pd.to_datetime(df_0['Times_y'])).dt.seconds/3600/24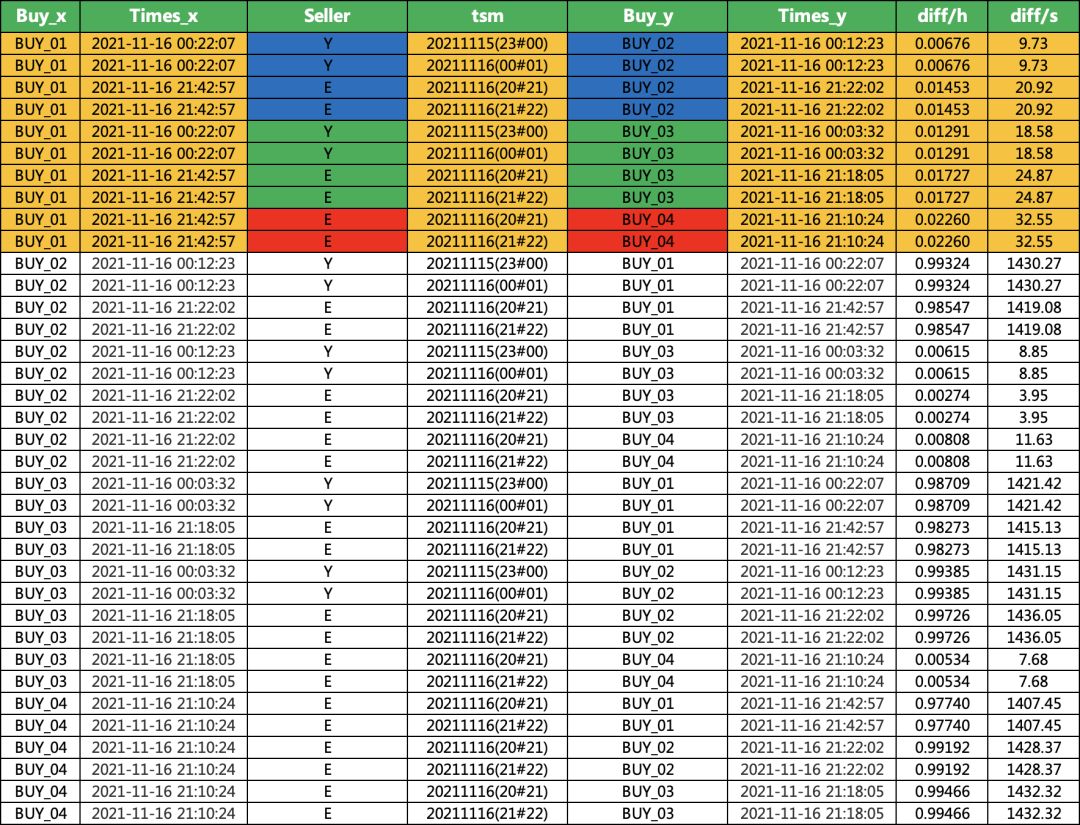
4、一天的数据聚合就得到下面的结果了
匹配得到的是明细数据,还需要进行聚合,得到两个用户相交的次数,就可以得到再当天的一个关联情况了。如下图所示:
# 数据聚合
df_1.groupby(['Buy_x','Buy_y']).agg({'Seller': pd.Series.nunique}).reset_index()
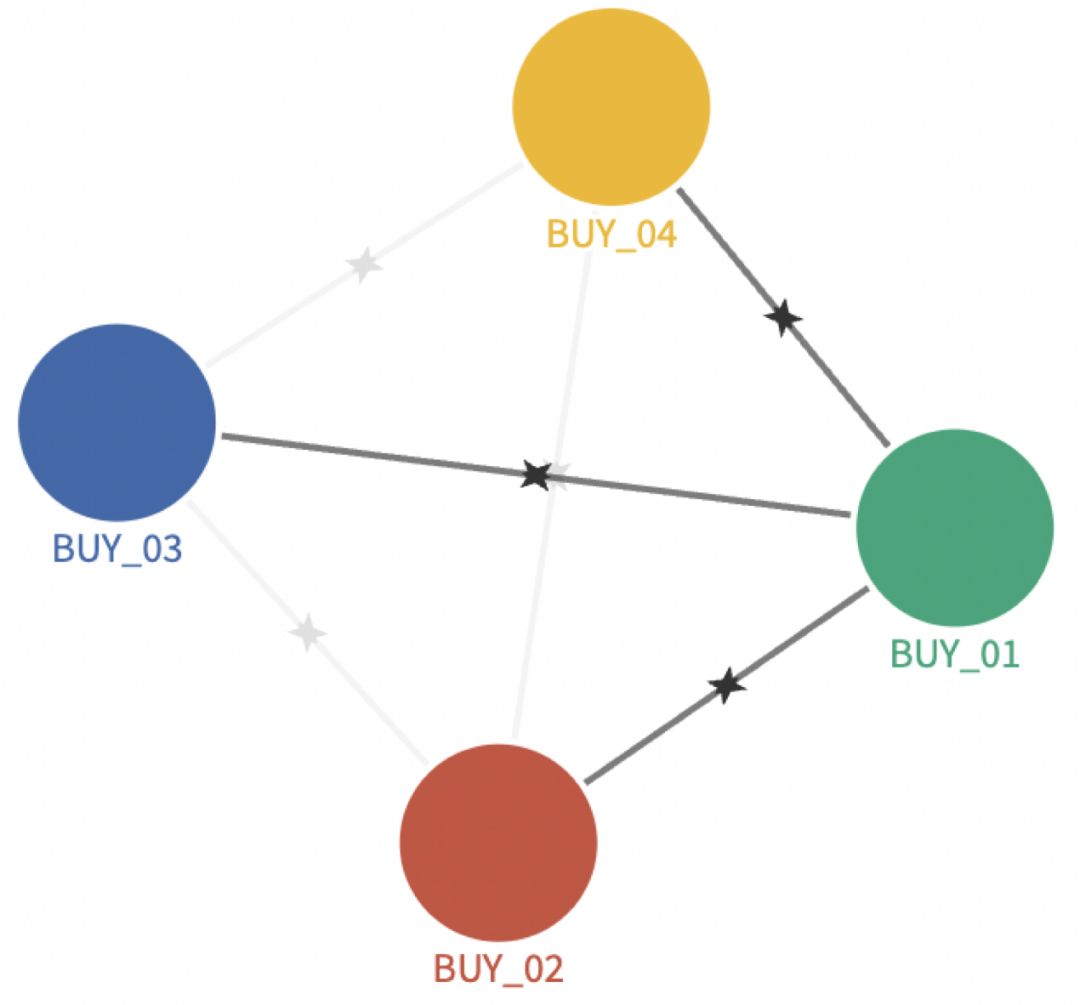
5、多天的数据聚合
多天数据进行聚合,假如我们的阈值是大于2,那标黄的部分,就将被舍弃掉
6、总体相似度计算
聚合了,还要进行相似度计算,分别计算每个用户出现的总次数。为什么要计算这个呢,举一个极端的例子,假如用户A自己出现了一万次,与B共同出现了5次,那这可能是巧合,但是如果A总共出现了5次,且5次都和B出现,那他俩是团伙的概率要大很多。按上面的数据,我们还要单独计算X出现的次数,Y出现的次数,并且X+Y-X∩Y求出并集,就可以用杰卡德算法进行相似度计算了,把相似度低的排除即可
到此计算完了之后,就可以构图环节就算完成了,下一步是如何进行分群,我们这里采用LPA标签传播算法就可以。今天先讲到这里了,分群的下次再讲,比较简单。















 6207
6207











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









