






一、安装 Hadoop 和 Scala
我的Hadoop安装地址为:
/Users/guo151/Library/hadoop-3.4.0
我的 Scala 安装地址为:
/Users/guo151/Library/scala-2.13.6
二、安装 Spark
1. 下载地址
选择需要的版本,我选择“3.5.3”,带 hadoop 版本:

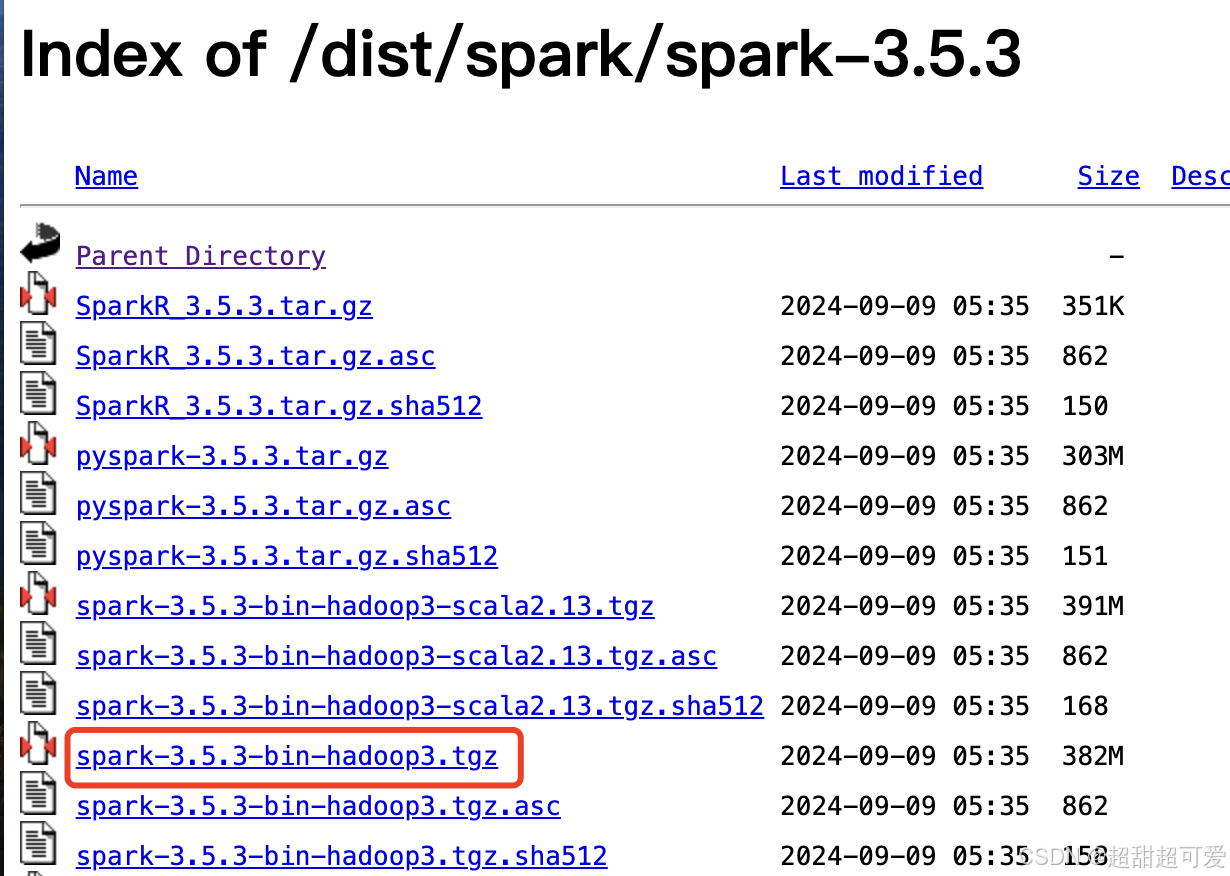
2. 下载到本地,解压后,放入:
/Users/guo151/Library/spark-3.5.3
三、配置 Spark
1. 配置 spark-env.sh:
1)进入 Spark 安装目录,进入 /conf 目录,新建一个 “spark-env.sh”:
vim spark-env.sh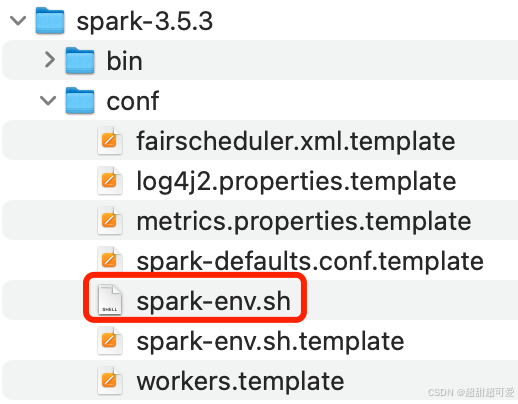
2)查找 java 安装目录:
/usr/libexec/java_home -V3)在 “spark-env.sh” 中,添加:
# 替换为自己的 java 安装目录
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk-1.8.jdk/Contents/Home
# 替换为自己的 scala 安装目录
export SCALA_HOME=/Users/guo151/Library/scala-2.13.6
# 替换为自己的 hadoop 安装目录 + /etc/hadoop
export HADOOP_CONF_DIR=/Users/guo151/Library/hadoop-3.4.0/etc/hadoop
2. 配置环境变量
1)terminal打开,输入:
vim ~/.bash_profile2)将 Spark 安装目录配置在环境变量中:
# Spark
# Spark安装目录
export SPARK_HOME=/Users/guo151/Library/spark-3.5.3
export PATH=$PATH:$SPARK_HOME/bin3)使之生效:
source ~/.bash_profile四、测试 Spark
1. 测试是否安装成功:
terminal 输入:
run-example SparkPi成功安装的结果:

2. 启动 Spark Shell:
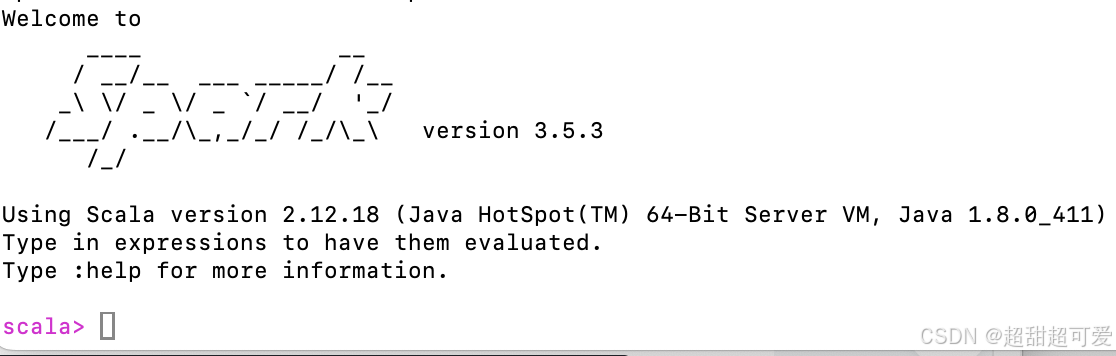
terminal输入:
spark-shell启动成功,显示:

















 1359
1359

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









