







- nginx响应时间参数
upstream_response_time:从 Nginx 建立连接 到 接收完数据并关闭连接 request_time:从接受用户请求的第一个字节 到 发送完响应数据
upstream_response_time和request_time的单位为秒
如果把整个过程补充起来的话 应该是:
[1用户请求]
[2建立 Nginx 连接]
[3发送响应]
[4接收响应]
[5关闭 Nginx 连接]
那么 upstream_response_time 就是 2+3+4+5 但是 一般这里面可以认为 [5关闭 Nginx 连接]的耗时接近 0 所以 upstream_response_time 实际上就是 2+3+4 而 request_time 是1+2+3+4 二者之间相差的就是[1用户请求] 的时间。
- http Headers中的Content-Type
POST请求的两种编码格式:
application/x-www-urlencoded:是浏览器默认的编码格式,用于键值对参数,参数之间用&间隔;
multipart/form-data:常用于文件等二进制,也可用于键值对参数,最后连接成一串字符传输。除了这两个编码格式,还有application/json也经常使用。
application/x-www-urlencoded: 对参数进行了编码
multipart/form-data: 不需要对参数编码
- linux上启动jmeter时指定jdk
在jmeter文件最上边加 export
JAVA_HOME=/home/yyj/jmeter_performance/jdk1.8.0_201
注意:如果是windows需要在jmeter.bat文件里设置
- jmeter的post请求
post请求,请求体为json时需要添加“HTTP信息管理头”
key: Content-Type
value : application/json

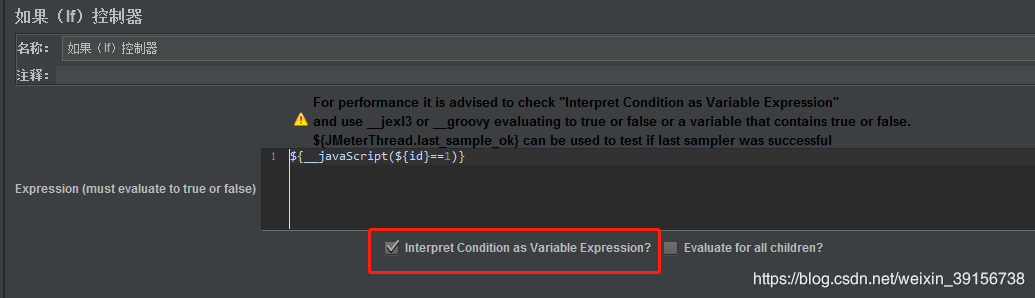
- jmeter if或while表达式
KaTeX parse error: Expected group after '_' at position 2: {_̲_groovy("{ip}" == “”,)}
KaTeX parse error: Expected group after '_' at position 2: {_̲_javaScript(“{id}”==1)}
KaTeX parse error: Expected group after '_' at position 2: {_̲_jexl3(“{ip}”!="")}
前提条件:需要先选中如图
- TPS和QPS
TPS:每秒通过的事务数或交易数
QPS:每秒通过的请求数(request) QPS=并发数/响应时间
PV访问量(Page View),即页面访问量,每打开一次页面PV计数+1,刷新页面也是。
UV访问数(Unique Visitor)指独立访客访问数,一台电脑终端为一个访客
例如:打开京东首页,如果发送了20个request,则QPS为20,TPS为1
- CPU LOAD
load average=正在运行的线程数+可运行(就绪状态)的线程数 load average < cpu个数核数0.7 理解:
https://blog.csdn.net/canot/article/details/78079085
cpu高原因排查*
第一步:用top命令找cpu高的进程
第二步:top -Hp pid 找cpu高的线程
第三步:把线程pid转为16进程
第四步:jstack -l 进程pid |grep 16进程线程 分析线程日志线程运行状态(full gc次数的增大或死循环导致cpu load过高原因比较多)
- jmeter里TPS、线程数、响应时间的公式和曲线
TPS=(1000ms/响应时间ms)* 线程数
-
并发用户数(TPS)、在线用户数、并发度?
并发度=并发用户数(TPS)/在线用户数

如上图所示,总共有 32 个用户进入了系统,但是绿色的用户并没有任何动作,那么显然,在线用户数是 32 个,并发用户数是 16 个,这时的并发度就是 50%。 -
TPS和响应时间关系图

10. 对新系统压测,场景改如何设计?
建议用上图的线程递增方式加压,一次就能压出拐点。(梯度不宜过大)

- 场景设计的重点是什么?
场景设计的重要点在于可以把真实业务场景重现出来,进而分析系统容量是否满足业务要求
- 压测脚本里打印日志对性能有无想影响?
影响TPS,去掉
- API网关
实现API的集中化管理,包括签名验证,权限控制,日志,请求转发,限流,监控,接口调用统计等
- nginx负载均衡的几种方式
```bash
权重(默认)
指定轮询几率,weight和访问比率成正比,用于后端服务器性能不均的情况。
upstream loopweight{
server 127.0.0.1:8080 weight = 5;
server 127.0.0.2:7080 weight = 5;
server 127.0.0.3:6305 weight = 10;
}
轮询
每个请求按时间顺序逐一分配到不同的后端服务器,如果后端服务器down掉,能自动剔除。
upstream loop{
server 127.0.0.1:8080
server 127.0.0.1:7080
server 127.0.0.1:6305
}
ip_hash
每个请求按访问ip的hash结果分配,这样每个访客固定访问一个后端服务器,可以解决session的问题。
upstream iphash{
ip_hash;
server 127.0.0.1:8080;
server 127.0.0.2:7080;
server 127.0.0.3:6305;
}
这里的IP说的是客户端的出口IP,这样经过 des_server_ip = hash(ip)
相应的ip在没有down掉的情况下,肯定会hash到固定的ip上。
URL hash
按访问url的hash结果来分配请求,使每个url定向到同一个后端服务器,后端服务器为缓存时比较有效。
upstream urlhash{
server 127.0.0.1:8080;
server 127.0.0.2:7080;
server 127.0.0.3:6305;
hash $request_uri;
hash_method crc32;
}
15.正向代理和反向代理
正向代理
上述这样的代理模式称为正向代理,正向代理最大的特点是客户端非常明确要访问的服务器地址;服务器只清楚请求来自哪个代理服务器,而不清楚来自哪个具体的客户端;正向代理模式屏蔽或者隐藏了真实客户端信息。
客户端必须要进行一些特别的设置才能使用正向代理。
–
反向代理


16.Swap交换分区
Swap的相关参数swappiness,默认为60,意思是当剩余物理内存低于40%时,开始使用交换内存。 查看swappiness的配置
sysctl -a | grep vm.swappiness
17.压测目标的确定
一般情况下,产品不会直接给出目标TPS(QPS)是多少,但他们可以提供PV、UV; 如果知道PV, 那么TPS= 当天总PV/24/3600 如果知道UV,根据28原则可计算出TPS。 例如: 外卖平台美团高峰期集在午饭和晚饭的2个小时内,假如UV=1000万,那么1000万80% / 43600 =TPS
18 什么时候考虑用jmeter分布式压测
TPS大于1000时
19.linux内核参数
查看内核参数:
sysctl命令用于运行时配置内核参数
-a 查看所有系统参数
-w 临时修改系统参数
例如: sysctl -a|grep swappiness 查看swappiness的内核参数
–
修改内核参数
临时修改:
例如: sysctl -w vm.swappiness=40 临时修改swappiness的值为40
永久修改:
修改/proc/sys/目录中的文件。例如: echo 1 > /proc/sys/net/ipv4/tcp_tw_reuse
修改tcp_tw_reuse的值为1 echo 1 > /proc/sys/net/ipv4/tcp_tw_recycle
修改tcp_tw_recycle的值为1 echo 30 > /proc/sys/net/ipv4/tcp_fin_timeout
修改tcp_fin_timeout的值为30 或者
修改/etc/sysctl.conf文件里对应参数的值修改后执行sysctl
-p立即生效
- Keeplive和keep-Alive的区别(长连接)
Keeplive是TCP层的概念,侧重在保持客户端和服务端的连接,一方会不定期发送心跳包给另一方,当一方端掉的时候,没有断掉的定时发送几次心跳包,如果间隔发送几次,对方都返回的是RST,而不是ACK,那么就释放当前链接。设想一下,如果tcp层没有keepalive的机制,一旦一方断开连接却没有发送FIN给另外一方的话,那么另外一方会一直以为这个连接还是存活的,几天,几月。那么这对服务器资源的影响是很大的
–
keep-Alive是http层的概念,http连接是客户端连接上服务端,然后结束请求后,由客户端或者服务端进行http连接的关闭。下次再发送请求的时候,客户端再发起一个连接,传送数据,关闭连接。这么个流程反复。但是一旦客户端发送connection:keep-alive头给服务端,且服务端也接受这个keep-alive的话,两边对上暗号,这个连接就可以复用了,一个http处理完之后,另外一个http数据直接从这个连接走了。减少新建和断开TCP连接的消耗
–
HTTP协议的Keep-Alive意图在于短时间内连接复用,希望可以短时间内在同一个连接上进行多次请求/响应
–
TCP的KeepAlive机制意图在于保活、心跳,检测连接错误。当一个TCP连接两端长时间没有数据传输时(通常默认配置是2小时),发送keepalive探针,探测链接是否存活
–
在TCP层是没有“请求”一说的,请求是http的概念,http是建立在TCP之上(之后)的
- 三次握手里的全连接队列和半连接队列
–
握手过程:
第一次:client发送syn到server进行握手
第二次:server收到syn后回复syn+ack给client同时服务端将相关信息放在半连接队列中。
第三次:client收到syn+ack后回复server一个ack,表示收到了server的syn+ack,server收到client的ack后将根据不同的情况进行不同的处理(这与tcp_abort_on_overflow参数和accept
queue全连接队列是否已满有关)
–
在握手阶段存在两个队列:
全连接队列(accept queue)
半连接队列(syns queue)
–
解析:当第一次握手(client客户端的SYN到达server服务端时)TCP会在未完成连接队列中创建一个新项,这一项会一直保留在未完成连接队列中直到第三次握手(客户对服务器SYN的ACK)结束为止。如果三次握手全部正常完成,该项则会从未完成连接队列移到已完成连接队列的队尾。当进程调用accept()时,已完成连接队列中的队头项将返回给进程。
–
第三次握手时sever的具体处理方式
–
场景1:当全连接未满 当server收到client的ack后会先判断全连接队列accept
queue是否已满,如果队列未满则从半连接队列拿出相关信息存放入全连接队列中,之后服务端accept()处理此请求。
–
场景2:当全连接已满且tcp_abort_on_overflow = 0 server会扔掉client
发过来的ack。之后隔一段时间server会重发握手第二步的syn+ack包给client,如果客户端连接一直排队不上等待超时则会报超时异常,即Connection timieout。
–
场景3:全连接已满且tcp_abort_on_overflow = 1时
server会发送一个reset包给client,表示废除这个握手过程和这个连接(客户端会报connection reset by peer异常)
–
如何查看半连接队列是否溢出
我们通过 SYNs to LISTEN sockets dropped 来判断半连接队列是否溢出
[root@7dgroup ~]# netstat -s |grep -I listen 8866 SYNs to LISTEN sockets dropped 如上所知,半连接队列满了,SYN包被扔掉了。半连接队列相关参数
1) backlog
2) 内核参数tcp_max_syn_backlog
–
如何查看全连接队列是否溢出
通过 times the listen queue of a socket overflowed 来判断全连接队列是否溢出 [root@7dgroup2 ~]# netstat -s |grep overflow 154864
times the listen queue of a socket overflowed 如图所知,全连接队列溢出了。
–
全连接队列的相关参数
1) net.core.somaxconn:系统中每一个端口最大的监听队列的长度。
2)net.core.netdev_max_backlog:每个网络接口接收数据包的速率比内核处理这些包的速率快时,允许送到队列的数据包的最大数目。
3) open_file:文件句柄数


- 三次握手基础知识普及
[1] 搞清楚流程
–
[2] 为什么连接的时候是三次握手,断开连接的时候是四次握手呢
–
[3] Connection timeout和Connection reset出现的原因
–
[4] TIME_WAIT出现的原因及解决办法
–
[5] Linux服务器上端口数、TCP连接数的关系
一台linux服务器最多能开65535个端口(1024以下为保留端口),但可以有成千上万的TCP连接数,具体要看最大文件句柄(文件描述符)限制和TCP参数的优化程度。
具体可参考:https://www.jb51.net/article/169556.htm
我们在压测一台目标服务器,想看下负载的连接数,当我们压到一定数量的时候,控制台突然报"too many openfiles",这是因为linux系统创建一个TCP连接的时候,都会创建一个socket句柄,每个socket句柄就是一个文件句柄。操作系统对打开的文件句柄数量是有限制的。
–
[6] Backlog是什么
–
[7] TCP协议中常用标识
SYN 请求建立连接
ACK 确认是否收到(一般为1)
FIN 希望断开连接
RST 对方要求重新建立连接、复位
–
[8] 以下主动关闭端为客户端,被动关闭端为服务器。
LISTEN 侦听来自远方的TCP端口的连接请求(服务端)
SYN_SENT 请求已发送(客户端)
SYN_RECV 服务器已确认ACK,同时向客户端发送SYN后
ESTABLISHED 连接已建立
FIN_WAIT-1 客户端请求主动关闭
FIN_WAIT-2 主动关闭端收到ACK后,进入FIN_WAIT-2状态
CLOSE_WAIT 被动关闭端收到FIN后,并回复ACK后
LAST_ACK 被动关闭端给主动关闭端发送FIN()后
TIME_WAIT 主动关闭端收到FIN(连接释放报文)后,并发送ACK后
CLOSED 被动关闭端接收到ACK后,进入CLOSED,连接结束

- JVM
[1] JVM内存模型
年轻代
老年代
持久代(java8叫元空间)
–
[2] GC作用: 回收不可用的对象,移动可用对象
–
[3] JVM优化
-Xms=-Xmx
-server
–
[4] JVM性能问题定位
jmap
jstatck
jstat
24 . mysql
[1] 事务
事务必须满足的4个特性:原子性、一致性、隔离性、持久性
BEGIN 开始一个事务
ROLLBACK 事务回滚
COMMIT 事务确认
–
[2] DDL和DML操作
–
[3] 索引
普通索引(加速查找)
唯一索引(加速查找+索引列值唯一)
主键索引(加速查找+索引列不能重复)创建索引
删除索引
索引失效的N多种情况
–
[4] 存储引擎
innodb 支持事务
myisam 不支持事务
–
[5] explain优化sql
–
[6] mysql、redis、es比较
mysql:关系型数据库,数据存在硬盘,支持事务
redis:非关系型数据库,数据存储在内存、支持持久化
es:不是数据库,是全文检索中间件,适合存储更新频率比较低的数据,比如:商品编号
- redis
[1] redis特性
数据存储在内存中,所以速度快
单线程运行
支持持久化
key/value存储
支持主从复制和集群
–
[2] redis原理
–
[3] 基本数据类型
string
list
set
hash
[4] 持久化
redis持久化分为两种,RDB和AOF RDB
–
RDB是将redis某一时刻的数据持久化到磁盘中,是一种快照式的持久化方法
RDB缺点:redis故障时数据可能会丢失
–
AOF:将redis执行过的所有写指令记录下来,在下次redis重新启动时,只要把这些写指令从前到后再重复执行一遍,就可以实现数据恢复了
AOF优点:可以恢复不小心删除的数据;万一出现故障,最多丢失1秒的数据 AOF缺点:AOF文件比RDB大,恢复速度慢














 3644
3644











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









