









简单介绍
slice 并不是数组或数组指针。它通过内部指针和相关属性引用数组片段,以实现变长方案。
- 切片:切片是数组的一个引用,因此切片是引用类型。但自身是结构体,值拷贝传递。
- 切片的长度可以改变,因此,切片是一个可变的数组。
- 切片遍历方式和数组一样,可以用len()求长度。表示当前元素数量,读写操作不能超过该限制。
- cap可以求出slice最大扩张容量,不能超出数组限制,否则会扩容。0 <= len(slice) <= len(array),其中array是slice引用的数组。
- 切片的定义:var 变量名 []类型,比如 var str []string var arr []int。
- 如果 slice == nil,那么 len、cap 结果都等于 0。
创建切片的各种方式
package main
import "fmt"
func main() {
//1.声明切片
var s1 []int
if s1 == nil {
fmt.Println("是空")
} else {
fmt.Println("不是空")
}
// 2.:=
s2 := []int{}
// 3.make()
var s3 []int = make([]int, 0)
fmt.Println(s1, s2, s3)
// 4.初始化赋值
var s4 []int = make([]int, 0, 0)
fmt.Println(s4)
s5 := []int{1, 2, 3}
fmt.Println(s5)
// 5.从数组切片
arr := [5]int{1, 2, 3, 4, 5}
var s6 []int
// 前包后不包
s6 = arr[1:4]
fmt.Println(s6)
}
输出结果:
空
[] [] []
[]
[1 2 3]
[2 3 4]
切片初始化
全局:
var arr = [...]int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
var slice0 []int = arr[start:end]
var slice1 []int = arr[:end]
var slice2 []int = arr[start:]
var slice3 []int = arr[:]
var slice4 = arr[:len(arr)-1] //去掉切片的最后一个元素
局部:
arr2 := [...]int{9, 8, 7, 6, 5, 4, 3, 2, 1, 0}
slice5 := arr[start:end]
slice6 := arr[:end]
slice7 := arr[start:]
slice8 := arr[:]
slice9 := arr[:len(arr)-1] //去掉切片的最后一个元素
- 中括号里的:len是取到第几个数,不是取多少个数更不是按照索引(从0开始)来算取多少个数!
- :冒号左边儿的数字要大于等于右边儿
- 冒号左边儿省略的话,左边儿数字就是0
- 冒号右边儿省略,右边儿数字就是被截取切片/数组的长度
- 冒号右边儿数字的最大值为被截取切片的容量或者被截取数组的长度
sl := make([]int, 1, 4)
sa := sl[2:] //panic: runtime error: slice bounds out of range [2:1]
//上面冒号右边儿的数字就是sl的长度了,即为1,2不小于等于1,报错!
sl := make([]int, 1, 4)
sl[0] = 1
sl = append(sl, 2)
sl = append(sl, 3)
fmt.Printf("sl:len=%d;cap=%d;val=%v\n", sl, sl, sl)//sl:len=[1 2 3];cap=[1 2 3];val=[1 2 3]
sa := sl[2:4]
fmt.Printf("sa:len=%d;cap=%d;val=%v\n", sa, sa, sa)//sa:len=[3 0];cap=[3 0];val=[3 0]

/*
* @Description:
* @version:
* @Author: Steven
* @Date: 2022-10-10 23:44:53
*/
package main
import (
"fmt"
)
var arr = [...]int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
var slice0 []int = arr[2:8]
var slice1 []int = arr[0:6] //可以简写为 var slice []int = arr[:end]
var slice2 []int = arr[5:10] //可以简写为 var slice[]int = arr[start:]
var slice3 []int = arr[0:len(arr)] //var slice []int = arr[:]
var slice4 = arr[:len(arr)-1] //去掉切片的最后一个元素
func main() {
fmt.Printf("全局变量:arr %v\n", arr)
fmt.Printf("全局变量:slice0 %v\n", slice0)
fmt.Printf("全局变量:slice1 %v\n", slice1)
fmt.Printf("全局变量:slice2 %v\n", slice2)
fmt.Printf("全局变量:slice3 %v\n", slice3)
fmt.Printf("全局变量:slice4 %v\n", slice4)
fmt.Printf("-----------------------------------\n")
arr2 := [...]int{9, 8, 7, 6, 5, 4, 3, 2, 1, 0}
slice5 := arr2[2:8]
slice6 := arr2[0:6] //
slice7 := arr2[5:10] //
slice8 := arr2[0:len(arr2)] //slice := arr[:]
slice9 := arr2[:len(arr2)-1] //去掉切片的最后一个元素
fmt.Printf("局部变量: arr2 %v\n", arr2)
fmt.Printf("局部变量: slice5 %v\n", slice5)
fmt.Printf("局部变量: slice6 %v\n", slice6)
fmt.Printf("局部变量: slice7 %v\n", slice7)
fmt.Printf("局部变量: slice8 %v\n", slice8)
fmt.Printf("局部变量: slice9 %v\n", slice9)
}
D:\GOMOD\hello>go run hello.go
全局变量:arr [0 1 2 3 4 5 6 7 8 9]
全局变量:slice0 [2 3 4 5 6 7]
全局变量:slice1 [0 1 2 3 4 5]
全局变量:slice2 [5 6 7 8 9]
全局变量:slice3 [0 1 2 3 4 5 6 7 8 9]
全局变量:slice4 [0 1 2 3 4 5 6 7 8]
-----------------------------------
局部变量: arr2 [9 8 7 6 5 4 3 2 1 0]
局部变量: slice5 [7 6 5 4 3 2]
局部变量: slice6 [9 8 7 6 5 4]
局部变量: slice7 [4 3 2 1 0]
局部变量: slice8 [9 8 7 6 5 4 3 2 1 0]
局部变量: slice9 [9 8 7 6 5 4 3 2 1]
通过make来创建切片
var slice []type = make([]type, len)//第二个参数不能省略,第三个可以!
slice := make([]type, len)// 省略cap len=cap
slice := make([]type, len, cap)
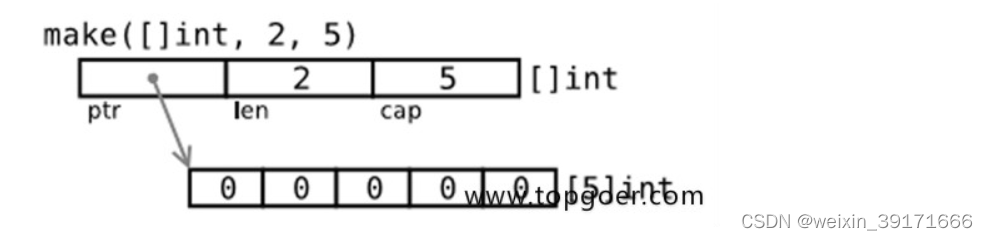
直接创建 slice 对象,自动分配底层数组。
package main
import "fmt"
func main() {
s1 := []int{0, 1, 2, 3, 8: 100} // 通过初始化表达式构造,可使用索引号。
fmt.Println(s1, len(s1), cap(s1))
s2 := make([]int, 6, 8) // 使用 make 创建,指定 len 和 cap 值。
fmt.Println(s2, len(s2), cap(s2))
s3 := make([]int, 6) // 省略 cap,相当于 cap = len。
fmt.Println(s3, len(s3), cap(s3))
}
[0 1 2 3 0 0 0 0 100] 9 9
[0 0 0 0 0 0] 6 8
[0 0 0 0 0 0] 6 6
切片的数据结构
切片底层是一个结构体,三个元素,一个指向数组的指针,一个切片长度,一个切片容量,指针指向的是引用的数组块第一个元素(并非数组的第一个元素,slice1 :=arr[1:2],这时是数组的第二个元素)
Slice 的数据结构定义如下:
type slice struct {
array unsafe.Pointer
len int
cap int
}
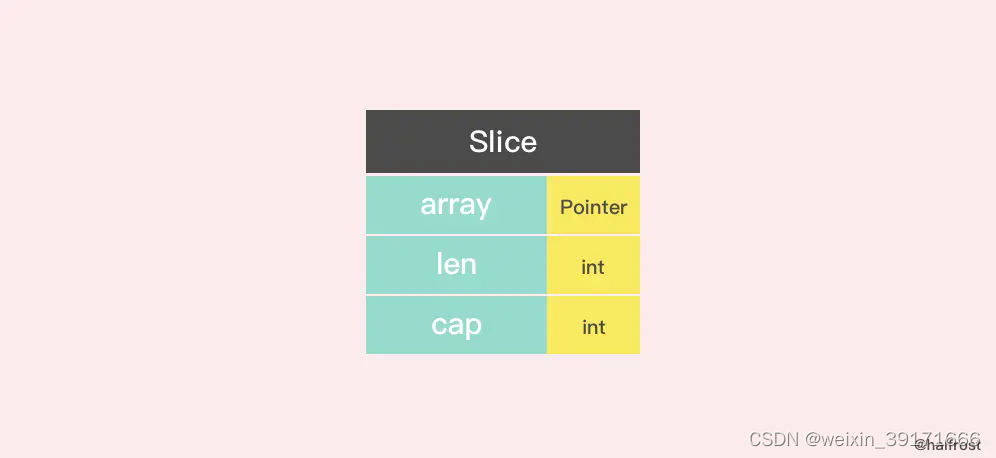
切片的结构体由3部分构成,Pointer 是指向一个数组的指针,len 代表当前切片的长度,cap 是当前切片的容量。cap 总是大于等于 len 的。
nil 和空切片
var slice []int //nil 只是声明 没赋值
silce := make( []int , 0 ) //空切片 声明并且赋值
slice := []int{ }//空切片 声明并且赋值
package main
import (
"fmt"
)
func main() {
var slice1 []int
slice2 := []int{}
slice3 := make([]int, 0)
if slice1 == nil {
fmt.Println("slice1=nil")
} else {
fmt.Println("slice1!=nil")
}
fmt.Println("---------")
if slice2 == nil {
fmt.Println("slice2=nil")
} else {
fmt.Println("slice2!=nil")
if len(slice2) == 0 {
fmt.Println("slice2 空")
} else {
fmt.Println("slice2 非 空")
}
}
fmt.Println("---------")
if slice3 == nil {
fmt.Println("slice3=nil")
} else {
fmt.Println("slice3!=nil")
if len(slice3) == 0 {
fmt.Println("slice3 空")
} else {
fmt.Println("slice3 非 空")
}
}
fmt.Println(slice1, slice2, slice3)
}
slice1=nil
---------
slice2!=nil
slice2 空
---------
slice3!=nil
slice3 空
[] [] []
**nil 切片被用在很多标准库和内置函数中,描述一个不存在的切片的时候,就需要用到 nil 切片。**比如函数在发生异常的时候,返回的切片就是 nil 切片。nil 切片的指针指向 nil。
空切片一般会用来表示一个空的集合。比如数据库查询,一条结果也没有查到,那么就可以返回一个空切片。
空切片和 nil 切片的区别在于,空切片指向的地址不是nil,指向的是一个内存地址,但是它没有分配任何内存空间,即底层元素包含0个元素。
最后需要说明的一点是。不管是使用 nil 切片还是空切片,对其调用内置函数 append,len 和 cap 的效果都是一样的。
切片删除
切片的底层是数组,因此删除意味着后面的元素需要逐个向前移位。每次删除的复杂度为 O(N),因此切片不合适大量随机删除的场景,这种场景下适合使用链表
删除指定位置的元素
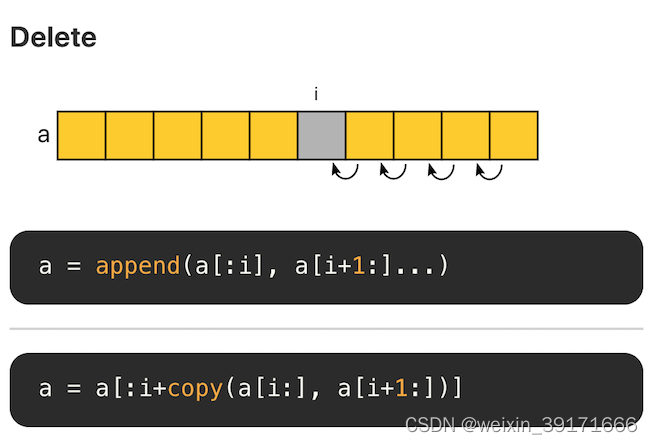
通过append实现
package main
import "fmt"
func main() {
sl := make([]int, 10)
for i := 0; i < 10; i++ {
sl[i] = i
}
fmt.Printf("sl=%#v;len=%d;cap=%d;\n", sl, len(sl), cap(sl))
num := 5 //删除下标为5,即第6个元素
//sl[:num]=[0, 1, 2, 3, 4]
//sl[num+1:]=[ 6, 7, 8, 9]
sl = append(sl[:num], sl[num+1:]...)
fmt.Printf("sl=%#v;len=%d;cap=%d;\n", sl, len(sl), cap(sl))
}
通过copy
package main
import "fmt"
func main() {
sl := make([]int, 10)
for i := 0; i < 10; i++ {
sl[i] = i
}
fmt.Printf("sl=%#v;len=%d;cap=%d;\n", sl, len(sl), cap(sl))//sl=[]int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9};len=10;cap=10;
num := 5 //删除下标为5,即第6个元素
//sl[num:]=[5, 6, 7, 8, 9]
//sl[num+1:]=[6, 7, 8, 9]
//copy(sl[num:], sl[num+1:])
//将sl[num:]的值[5, 6, 7, 8, 9]的前四个元素分别替换为[6, 7, 8, 9],所以copy函数返回值为4
//之后sl[num:]的值就变为了[6, 7, 8, 9, 9]
//s1底层引用的数组,后5个元素就变成了[6, 7, 8, 9, 9]
//所以此时sl=[{0, 1, 2, 3, 4, 6, 7, 8, 9, 9]
//此时我们要删除的第6个元素,值为5,已经不在s1当中了
//但是此时s1最后面的两个元素都为9,我们需要将最后一个剔除
//也就是s1[:9],也就是s1[:num+4],4是copy函数返回结果
sl = sl[:num+copy(sl[num:], sl[num+1:])]
fmt.Printf("sl=%#v;len=%d;cap=%d;\n", sl, len(sl), cap(sl))//sl=[]int{0, 1, 2, 3, 4, 6, 7, 8, 9};len=9;cap=10;
}
删除具体的元素!
移位法
思路:就是将所有不是待删除的元素,往前/后移动
- 定义一个变量初始值等于0,发现不是待删除的元素,就将该元素放到该变量对应代表索引位置上
- 放完一个元素,该变量的值就加以
package main
import "fmt"
func main() {
// sl := make([]int, 10)
// for i := 0; i < 10; i++ {
// sl[i] = i
// }
sl := []int{1, 5, 3, 4, 5, 6, 7, 5, 9, 5}
fmt.Printf("sl=%#v;len=%d;cap=%d;\n", sl, len(sl), cap(sl)) //sl=[]int{1, 5, 3, 4, 5, 6, 7, 5, 9, 5};len=10;cap=10;
sl = deleteElem4(sl, 5)
fmt.Printf("sl=%#v;len=%d;cap=%d;\n", sl, len(sl), cap(sl)) //sl=[]int{1, 3, 4, 6, 7, 9};len=6;cap=10;
}
func deleteElem4(sl []int, elem int) []int {
j := 0
for _, v := range sl {
if v != elem {
sl[j] = v
j++
}
}
return sl[:j]
}
切片插入元素
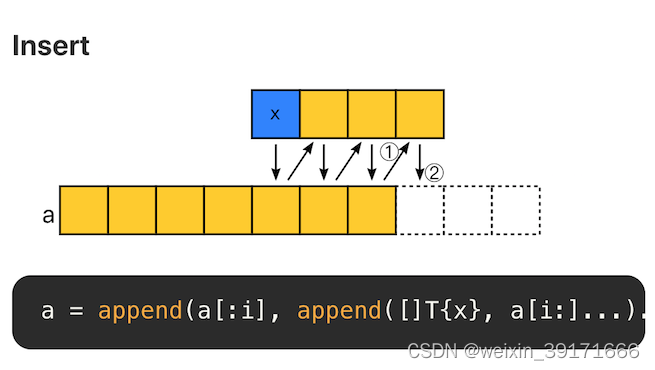
insert 和 append 类似。即在某个位置添加一个元素后,将该位置后面的元素再 append 回去。复杂度为 O(N)。因此,不适合大量随机插入的场景。
Filter(过滤掉特定元素)
很明显还是使用的位移法!
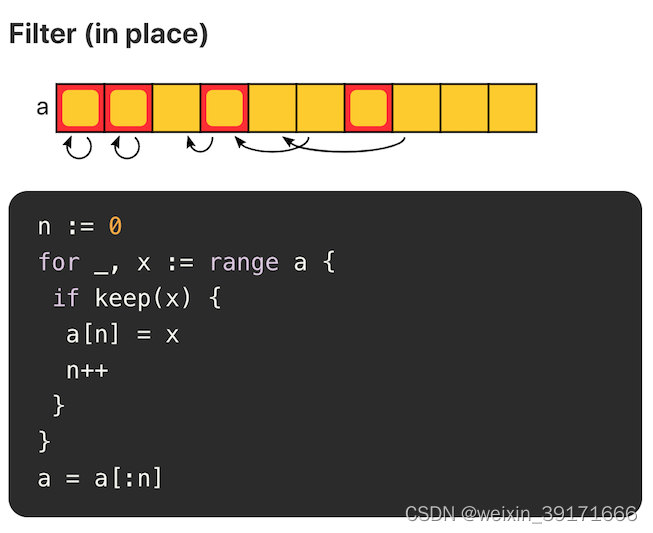
当原切片不会再被使用时,就地 filter 方式是比较推荐的,可以节省内存空间。
Push(尾部/头部插入元素)
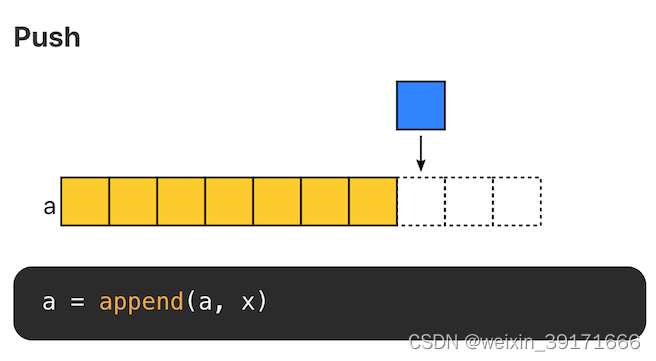
在末尾追加元素,不考虑内存拷贝的情况,复杂度为 O(1)。
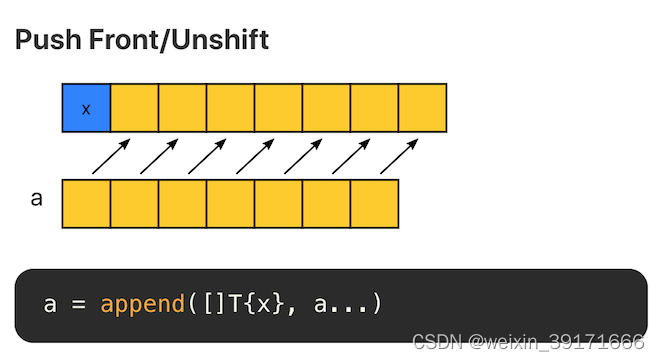
在头部追加元素,时间和空间复杂度均为 O(N),不推荐。
Pop(头尾删除元素)
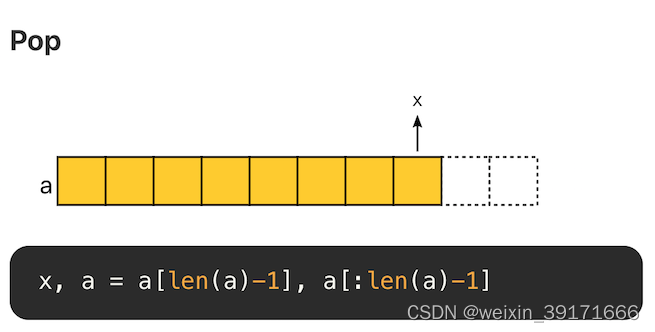
尾部删除元素,复杂度 O(1)
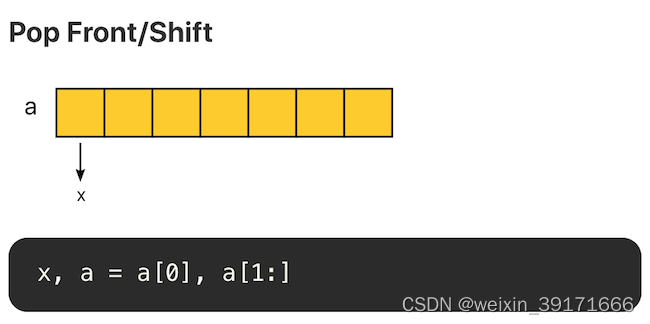
头部删除元素,如果使用切片方式,复杂度为 O(1)。但是需要注意的是,底层数组没有发生改变,第 0 个位置的内存仍旧没有释放。如果有大量这样的操作,头部的内存会一直被占用。
*扩容策略
具体的策略
源码位置:D:\program\GO\src\runtime\slice.go
扩容函数:growslice
确定大致容量
摘取扩容实现的一段代码:
下面的是旧版本的:
golang1.18版本之前
newcap := old.cap//旧切片容量
doublecap := newcap + newcap//旧切片容量的2倍
if cap > doublecap {//cap为能容纳下新切片的最小容量,即新切片的长度等于这个cap
newcap = cap//所需最小容量都大约旧容量的2倍,则直接将新切片的容量扩容到最小容量,
} else {//如果所需的最小容量,小于旧切片的容量二倍
if old.cap < 1024 {//如果旧切片容量小于1024
newcap = doublecap//则直接将新切片的容量扩大为旧切片容量的二倍
} else {//如果旧切片的容量大于1024了
// 检查0 < newcap检测溢出
// 和防止无限循环。
for 0 < newcap && newcap < cap {//旧切片容量大于0,并且小于所需的最小容量
newcap += newcap / 4//扩容增加旧切片容量的4分之一,但是这个时候,也不一定够,如果不够,就得再次扩容了!
}
// 设置newcap为所请求的上限
// newcap计算溢出。
if newcap <= 0 {
newcap = cap
}
}
}
所以根据上面一段代码总结出,旧版本的情况:
- 如果期望容量大于当前容量的两倍就会使用期望容量;
- 如果当前切片的长度小于 1024 就会将容量翻倍;
- 如果当前切片的长度大于 1024 就会每次增加 25% 的容量,直到新容量大于期望容量;
下面是新版本的!
golang1.18版本之后的,包括1.18版本
本机就是这个版本的,版本号是:go1.19.1
与旧版本的区别就是else里的不同
newcap := old.cap
doublecap := newcap + newcap
if cap > doublecap {
newcap = cap
} else {
const threshold = 256
if old.cap < threshold {//这里变成了256,旧版本是1024
newcap = doublecap
} else {
// Check 0 < newcap to detect overflow
// and prevent an infinite loop.
for 0 < newcap && newcap < cap {
// Transition from growing 2x for small slices
// to growing 1.25x for large slices. This formula
// gives a smooth-ish transition between the two.
newcap += (newcap + 3*threshold) / 4//扩容增量等于:(旧切片容量+3*256)/4
//旧版本是
// newcap += newcap / 4
}
// Set newcap to the requested cap when
// the newcap calculation overflowed.
if newcap <= 0 {
newcap = cap
}
}
}
所以根据上面一段代码总结出,新版本的情况:
- 如果期望容量大于当前容量的两倍就会使用期望容量;
- 如果当前切片的长度小于 256 就会将容量翻倍;
- 如果当前切片的长度大于 256 就会每次增加 (旧切片容量+3*256)/4 的容量,直到新容量大于期望容量;
上述代码片段仅会确定切片的大致容量,下面还需要根据切片中的元素大小对齐内存,当数组中元素所占的字节大小为 1、8 或者 2 的倍数时,运行时会使用如下所示的代码对齐内存:
根据内存对齐得出最终的扩容之后的容量:
var overflow bool
var lenmem, newlenmem, capmem uintptr
//指定et.size的公共值。
// 对于1,我们不需要任何除法/乘法。
// 对于goarch.PtrSize,编译器会将除法/乘法优化为一个常数的移位。
// /对于2的幂,使用变量shift。
switch {//et.size是切片元素占用字节大小
case et.size == 1:
lenmem = uintptr(old.len)
newlenmem = uintptr(cap)
capmem = roundupsize(uintptr(newcap))//runtime.roundupsize 函数会将待申请的内存向上取整
overflow = uintptr(newcap) > maxAlloc
newcap = int(capmem)
case et.size == goarch.PtrSize://goarch.PtrSize=8
lenmem = uintptr(old.len) * goarch.PtrSize
newlenmem = uintptr(cap) * goarch.PtrSize
capmem = roundupsize(uintptr(newcap) * goarch.PtrSize)
overflow = uintptr(newcap) > maxAlloc/goarch.PtrSize
newcap = int(capmem / goarch.PtrSize)
case isPowerOfTwo(et.size):
var shift uintptr
if goarch.PtrSize == 8 {
// Mask shift for better code generation.
shift = uintptr(sys.Ctz64(uint64(et.size))) & 63
} else {
shift = uintptr(sys.Ctz32(uint32(et.size))) & 31
}
lenmem = uintptr(old.len) << shift
newlenmem = uintptr(cap) << shift
capmem = roundupsize(uintptr(newcap) << shift)
overflow = uintptr(newcap) > (maxAlloc >> shift)
newcap = int(capmem >> shift)
default:
lenmem = uintptr(old.len) * et.size
newlenmem = uintptr(cap) * et.size
capmem, overflow = math.MulUintptr(et.size, uintptr(newcap))
capmem = roundupsize(capmem)
newcap = int(capmem / et.size)
}
func isPowerOfTwo(x uintptr) bool {
return x&(x-1) == 0
}
runtime.roundupsize 函数会将待申请的内存向上取整,取整时会使用 runtime.class_to_size 数组,使用该数组中的整数可以提高内存的分配效率并减少碎片
// Returns size of the memory block that mallocgc will allocate if you ask for the size.
func roundupsize(size uintptr) uintptr {
if size < _MaxSmallSize {//_MaxSmallSize=32768
if size <= smallSizeMax-8 {//smallSizeMax=1024
//取整时会使用 runtime.class_to_size 数组,使用该数组中的整数可以提高内存的分配效率并减少碎片
return uintptr(class_to_size[size_to_class8[divRoundUp(size, smallSizeDiv)]])//smallSizeDiv=8
} else {
return uintptr(class_to_size[size_to_class128[divRoundUp(size-smallSizeMax, largeSizeDiv)]])
}
}
if size+_PageSize < size {
return size
}
return alignUp(size, _PageSize)
}
// divRoundUp returns ceil(n / a).
func divRoundUp(n, a uintptr) uintptr {
// a is generally a power of two. This will get inlined and
// the compiler will optimize the division.
return (n + a - 1) / a
}
// alignUp rounds n up to a multiple of a. a must be a power of 2.
func alignUp(n, a uintptr) uintptr {
return (n + a - 1) &^ (a - 1)
}
const (
_MaxSmallSize = 32768
smallSizeDiv = 8
smallSizeMax = 1024
largeSizeDiv = 128
_NumSizeClasses = 68
_PageShift = 13
_PageSize = 1 << _PageShift
)
var class_to_size = [_NumSizeClasses]uint16{0, 8, 16, 24, 32, 48, 64, 80, 96, 112, 128, 144, 160, 176, 192, 208, 224, 240, 256, 288, 320, 352, 384, 416, 448, 480, 512, 576, 640, 704, 768, 896, 1024, 1152, 1280, 1408, 1536, 1792, 2048, 2304, 2688, 3072, 3200, 3456, 4096, 4864, 5376, 6144, 6528, 6784, 6912, 8192, 9472, 9728, 10240, 10880, 12288, 13568, 14336, 16384, 18432, 19072, 20480, 21760, 24576, 27264, 28672, 32768}
var size_to_class8 = [smallSizeMax/smallSizeDiv + 1]uint8{0, 1, 2, 3, 4, 5, 5, 6, 6, 7, 7, 8, 8, 9, 9, 10, 10, 11, 11, 12, 12, 13, 13, 14, 14, 15, 15, 16, 16, 17, 17, 18, 18, 19, 19, 19, 19, 20, 20, 20, 20, 21, 21, 21, 21, 22, 22, 22, 22, 23, 23, 23, 23, 24, 24, 24, 24, 25, 25, 25, 25, 26, 26, 26, 26, 27, 27, 27, 27, 27, 27, 27, 27, 28, 28, 28, 28, 28, 28, 28, 28, 29, 29, 29, 29, 29, 29, 29, 29, 30, 30, 30, 30, 30, 30, 30, 30, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32}
举几个例子
例子1
package main
import "fmt"
func main() {
var arr []int64
fmt.Printf("arr=%+v;len=%d;cap=%d;\n", arr, len(arr), cap(arr))//arr=[];len=0;cap=0;
arr = append(arr, 1, 2, 3, 4, 5)
fmt.Printf("arr=%+v;len=%d;cap=%d;\n", arr, len(arr), cap(arr))//arr=[1 2 3 4 5];len=5;cap=6;
}
上面代码,我们用append往容量为0的切片里追加了5个元素,但是追加之后的切片的容量竟然是6,具体怎么计算的呢!
咱们由上面计算扩容之后的容量计算步骤,逐一往下分析!
- 首先确定出大致容量
由于本机的growslice方法是新版本的,即与1024无关,跟256有关!所以确定大致容量的规则是下面的规则
所以根据上面一段代码总结出,新版本的情况:
如果期望容量大于当前容量的两倍就会使用期望容量;
如果当前切片的长度小于 256 就会将容量翻倍;
如果当前切片的长度大于 256 就会每次增加 (旧切片容量+3*256)/4 的容量,直到新容量大于期望容量;
开始计算:
var arr []int64
arr = append(arr, 1, 2, 3, 4, 5)
//旧切片的容量为0,新切片所需最小容量为5
//得出,期望容量大小大于旧切片容量的两倍
//所以确定出大致容量为5
- 根据内存对齐策略,来计算出最终的容量
旧切片元素类型为int64,占用字节大小为8,所以进入et.size == goarch.PtrSize分支
case et.size == goarch.PtrSize://goarch.PtrSize=8
--注释掉的无关的代码--
capmem = roundupsize(uintptr(newcap) * goarch.PtrSize)
//=capmem = roundupsize(5 * 8)
--注释掉的无关的代码--
newcap = int(capmem / goarch.PtrSize)//最终的容量
执行roundupsize(40):
func roundupsize(size uintptr) uintptr {//此时size=40
if size < _MaxSmallSize {//_MaxSmallSize=32768
if size <= smallSizeMax-8 {//smallSizeMax=1024;40<=1024-8,为true
return uintptr(class_to_size[size_to_class8[divRoundUp(size, smallSizeDiv)]])//smallSizeDiv=8
} else {
return uintptr(class_to_size[size_to_class128[divRoundUp(size-smallSizeMax, largeSizeDiv)]])
}
}
if size+_PageSize < size {
return size
}
return alignUp(size, _PageSize)
}
执行:
uintptr(class_to_size[size_to_class8[divRoundUp(size, smallSizeDiv)]])
//=uintptr(class_to_size[size_to_class8[divRoundUp(40, 8)]])
执行:
// divRoundUp returns ceil(n / a).
func divRoundUp(n, a uintptr) uintptr {//n=40,a=8
// a is generally a power of two. This will get inlined and
// the compiler will optimize the division.
return (n + a - 1) / a
}
//返回结果为5!
size_to_class8[5]的结果为什么呢!
var size_to_class8 = [smallSizeMax/smallSizeDiv + 1]uint8{0, 1, 2, 3, 4, 5, 5, 6, 6, 7, 7, 8, 8, 9, 9, 10, 10, 11, 11, 12, 12, 13, 13, 14, 14, 15, 15, 16, 16, 17, 17, 18, 18, 19, 19, 19, 19, 20, 20, 20, 20, 21, 21, 21, 21, 22, 22, 22, 22, 23, 23, 23, 23, 24, 24, 24, 24, 25, 25, 25, 25, 26, 26, 26, 26, 27, 27, 27, 27, 27, 27, 27, 27, 28, 28, 28, 28, 28, 28, 28, 28, 29, 29, 29, 29, 29, 29, 29, 29, 30, 30, 30, 30, 30, 30, 30, 30, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32}
size_to_class8[5]=5//为5
接下来就是获取class_to_size下标为5的元素:
var class_to_size = [_NumSizeClasses]uint16{0, 8, 16, 24, 32, 48, 64, 80, 96, 112, 128, 144, 160, 176, 192, 208, 224, 240, 256, 288, 320, 352, 384, 416, 448, 480, 512, 576, 640, 704, 768, 896, 1024, 1152, 1280, 1408, 1536, 1792, 2048, 2304, 2688, 3072, 3200, 3456, 4096, 4864, 5376, 6144, 6528, 6784, 6912, 8192, 9472, 9728, 10240, 10880, 12288, 13568, 14336, 16384, 18432, 19072, 20480, 21760, 24576, 27264, 28672, 32768}
class_to_size[5]=48//为48
最终roundupsize函数返回结果为48!
也就是capmem=48
case et.size == goarch.PtrSize://goarch.PtrSize=8
--注释掉的无关的代码--
capmem = roundupsize(uintptr(newcap) * goarch.PtrSize)//此时capmem=48
//=capmem = roundupsize(5 * 8)
--注释掉的无关的代码--
newcap = int(capmem / goarch.PtrSize)
//newcap = int(48 / 8)
//newcap = 6
最终得出扩容之后切片的容量为6!
例子2
package main
import "fmt"
func main() {
var arr []int64
fmt.Printf("arr=%+v;len=%d;cap=%d;\n", arr, len(arr), cap(arr)) //arr=[];len=0;cap=0;
arr = append(arr, 1, 2, 3, 4, 5)
fmt.Printf("arr=%+v;len=%d;cap=%d;\n", arr, len(arr), cap(arr)) //arr=[1 2 3 4 5];len=5;cap=6;
arr = append(arr, 1, 2, 3, 4, 5)
fmt.Printf("arr=%+v;len=%d;cap=%d;\n", arr, len(arr), cap(arr))/
//旧切片容量为6,期望容量为10,期望容量小于旧切片容量的2倍
//得出新切片大致容两为12
}
分析内存对齐!
//还是进入这个分支
case et.size == goarch.PtrSize:
分析:
capmem = roundupsize(uintptr(newcap) * goarch.PtrSize)
//capmem = roundupsize(12 * 8)
func roundupsize(size uintptr) uintptr {//size=96
if size < _MaxSmallSize {
if size <= smallSizeMax-8 {//96<=1024-8
return uintptr(class_to_size[size_to_class8[divRoundUp(size, smallSizeDiv)]])
} else {
return uintptr(class_to_size[size_to_class128[divRoundUp(size-smallSizeMax, largeSizeDiv)]])
}
}
if size+_PageSize < size {
return size
}
return alignUp(size, _PageSize)
}
继续分析:
divRoundUp(size, smallSizeDiv)
//divRoundUp(96, 8)
func divRoundUp(n, a uintptr) uintptr {
// a is generally a power of two. This will get inlined and
// the compiler will optimize the division.
return (n + a - 1) / a
}
//返回结果为12
var size_to_class8 = [smallSizeMax/smallSizeDiv + 1]uint8{0, 1, 2, 3, 4, 5, 5, 6, 6, 7, 7, 8, 8, 9, 9, 10, 10, 11, 11, 12, 12, 13, 13, 14, 14, 15, 15, 16, 16, 17, 17, 18, 18, 19, 19, 19, 19, 20, 20, 20, 20, 21, 21, 21, 21, 22, 22, 22, 22, 23, 23, 23, 23, 24, 24, 24, 24, 25, 25, 25, 25, 26, 26, 26, 26, 27, 27, 27, 27, 27, 27, 27, 27, 28, 28, 28, 28, 28, 28, 28, 28, 29, 29, 29, 29, 29, 29, 29, 29, 30, 30, 30, 30, 30, 30, 30, 30, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32}
size_to_class8[12]=8
var class_to_size = [_NumSizeClasses]uint16{0, 8, 16, 24, 32, 48, 64, 80, 96, 112, 128, 144, 160, 176, 192, 208, 224, 240, 256, 288, 320, 352, 384, 416, 448, 480, 512, 576, 640, 704, 768, 896, 1024, 1152, 1280, 1408, 1536, 1792, 2048, 2304, 2688, 3072, 3200, 3456, 4096, 4864, 5376, 6144, 6528, 6784, 6912, 8192, 9472, 9728, 10240, 10880, 12288, 13568, 14336, 16384, 18432, 19072, 20480, 21760, 24576, 27264, 28672, 32768}
class_to_size[8]=96
最后回到
case et.size == goarch.PtrSize:
里
capmem = roundupsize(uintptr(newcap) * goarch.PtrSize)//capmem=96
newcap = int(capmem / goarch.PtrSize)//96/8=12
最终新切片的容量也确实为12!
arr=[];len=0;cap=0;
arr=[1 2 3 4 5];len=5;cap=6;
arr=[1 2 3 4 5 1 2 3 4 5];len=10;cap=12;
演示扩容,出现数组拷贝
- 切片直接使用下标操作是不会扩容的,如果下标越界会直接报错,使用append才会自动扩容。见下面代码一
- 超出范围并不单只指切片的长度已经超出容量,使用的下标超出范围(长度)也是越界的!见下面代码二
//代码一
package main
func main() {
var slice1 []int
slice1 = make([]int, 2)//长度跟容量都是2
slice1[0] = 1
slice1[1] = 1
slice1[2] = 1//这里就超出了
}
输出结果:
panic: runtime error: index out of range [2] with length 2
goroutine 1 [running]:
main.main()
D:/GoWork/src/timedemo/test.go:8 +0x1b
exit status 2
//代码二
package main
func main() {
var slice1 []int
slice1 = make([]int, 2)
slice1[0] = 1
slice1[2] = 1
}
输出结果:一样报错的
panic: runtime error: index out of range [2] with length 2
goroutine 1 [running]:
main.main()
D:/GoWork/src/timedemo/test.go:7 +0x1b
exit status 2
代码三:
aa := make([]int, 0, 2)//长度为0
aa[0] = 1
//aa = append(aa, 1)//这个时候只能使用append来添加元素
fmt.Println(aa)
//一样越界了
panic: runtime error: index out of range [0] with length 0
goroutine 1 [running]:
main.main()
D:/GOMOD/rpcdemo/main.go:11 +0x31
exit status 2
将要扩容的切片指向的原数组内容拷贝到创建的新数组
func main() {
slice := []int{10, 20, 30, 40}
newSlice := append(slice, 50)
fmt.Printf("Before slice = %v, Pointer = %p, len = %d, cap = %d\n", slice, &slice, len(slice), cap(slice))
fmt.Printf("Before newSlice = %v, Pointer = %p, len = %d, cap = %d\n", newSlice, &newSlice, len(newSlice), cap(newSlice))
newSlice[1] += 10
fmt.Printf("After slice = %v, Pointer = %p, len = %d, cap = %d\n", slice, &slice, len(slice), cap(slice))
fmt.Printf("After newSlice = %v, Pointer = %p, len = %d, cap = %d\n", newSlice, &newSlice, len(newSlice), cap(newSlice))
}
输出结果:
Before slice = [10 20 30 40], Pointer = 0xc4200b0140, len = 4, cap = 4
Before newSlice = [10 20 30 40 50], Pointer = 0xc4200b0180, len = 5, cap = 8
After slice = [10 20 30 40], Pointer = 0xc4200b0140, len = 4, cap = 4
After newSlice = [10 30 30 40 50], Pointer = 0xc4200b0180, len = 5, cap = 8
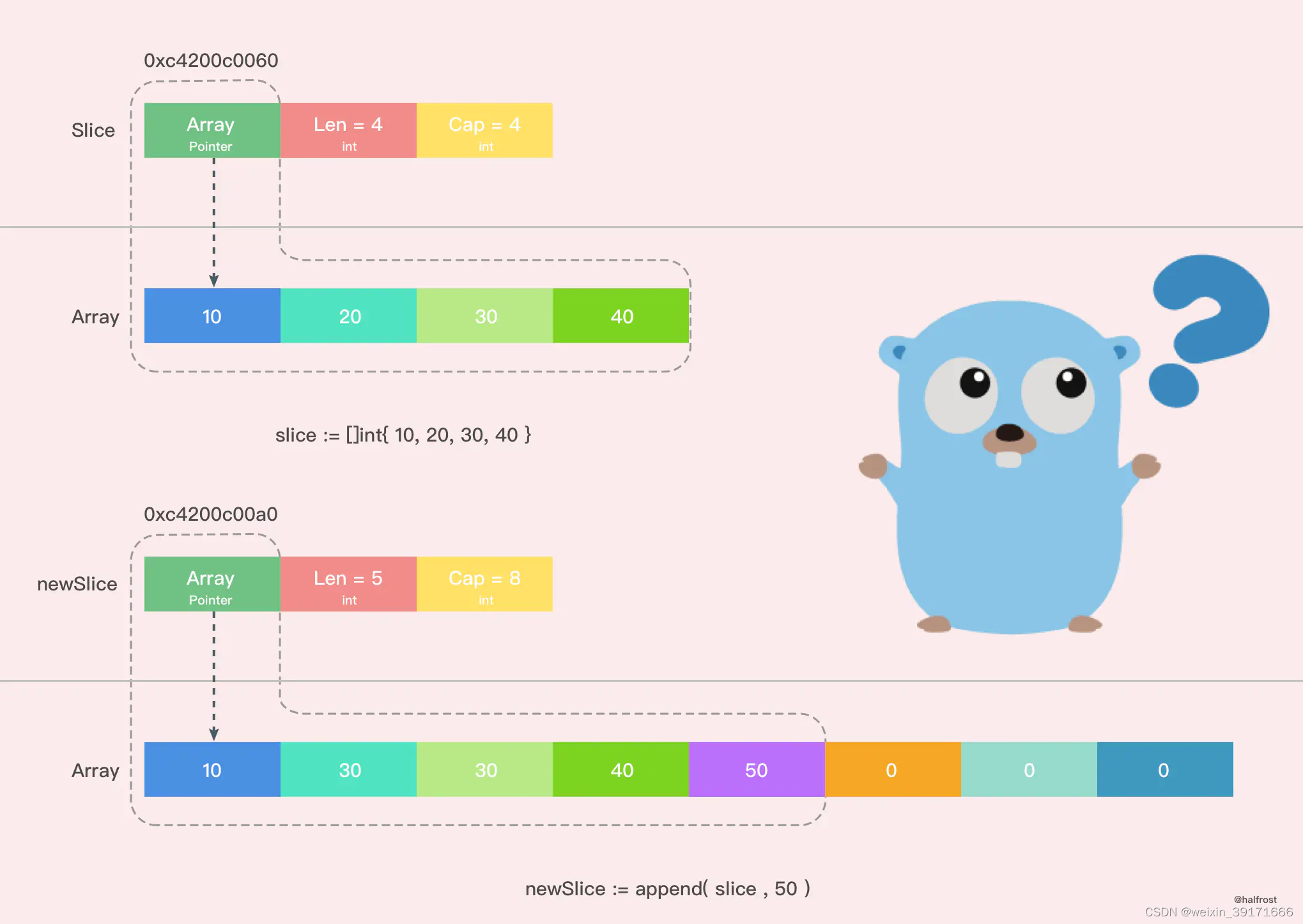
从图上我们可以很容易的看出,新的切片和之前的切片已经不同了,因为新的切片更改了一个值,并没有影响到原来的数组,新切片指向的数组是一个全新的数组。并且 cap 容量也发生了变化。这之间究竟发生了什么呢?
注意:扩容扩大的容量都是针对原来的容量而言的,而不是针对原来数组的长度而言的。
元素为map类型的切片
切片跟切片的元素map都要初始化
下面的代码演示了切片中的元素为map类型时的操作:
func main() {
var mapSlice = make([]map[string]string, 3) //利用make 切片初始化了
for index, value := range mapSlice {
fmt.Printf("index:%d value:%v\n", index, value)
}
fmt.Println("after init")
// 对切片中的map元素进行初始化
mapSlice[0] = make(map[string]string, 10) //还得对切片元素map类型的进行初始化,因为map也是引用类型,必须初始化
mapSlice[0]["name"] = "王五"
mapSlice[0]["password"] = "123456"
mapSlice[0]["address"] = "红旗大街"
for index, value := range mapSlice {
fmt.Printf("index:%d value:%v\n", index, value)
}
}
如何打印slice变量的地址?
s := []int{1, 2}
fmt.Printf("%p\n", &s)
如何打印slice底层数组的地址?有2种方法
s = make([]int, 2, 3)
fmt.Printf("%p %p\n", s, &s[0])
切片注意事项
切片是引用类型,必须初始化才能使用,单是使用append追加的话,就不用使用make来初始化了,因为append会自动扩容
- 切片直接使用下标操作是不会扩容的,如果下标越界会直接报错,使用append才会自动扩容。
- 超出范围并不单只指切片的长度已经超出容量,使用的下标超出范围也是越界的!
//正确使用
var slice1 []int = make([]int, 2, 10)
slice1[1] = 1
fmt.Println(slice1)
var slice1 []int//此时长度和容量都是0
slice1 = append(slice1, 1)//append会自动扩容,所以这里哪怕没有初始化,直接使用appengd追加也是没问题的
fmt.Printf("len=%d,cap=%d,值=%v", len(slice1), cap(slice1), slice1)//len=1,cap=1,值=[1]
}
//错误使用
var slice1 []int//slice[0]操作,直接越界,报错
slice1[0] = 1//panic: runtime error: index out of range [0] with length 0
fmt.Println(slice1)
var slice1 []int = make([]int, 2, 10) //[0,0]
slice1[2] = 1 //直接使用下标2,也是超出了
fmt.Println(slice1)
var slice1 []int = make([]int, 0, 10) //长度为0
slice1[0] = 1 //直接使用下标操作,不管下标为多少都会报错
fmt.Println(slice1)
append操作谨慎使用
总结:append扩容操作为了防止影响到原来数组和原来的切片,在append之前务必保证原来切片已经达到最大容量,即原来切片的len=cap
再谈谈扩容之后的数组一定是新的么?这个不一定,分两种情况。
情况一:
func main() {
array := [4]int{10, 20, 30, 40}
slice := array[0:2]
newSlice := append(slice, 50)
fmt.Printf("Before slice = %v, Pointer = %p, len = %d, cap = %d\n", slice, &slice, len(slice), cap(slice))
fmt.Printf("Before newSlice = %v, Pointer = %p, len = %d, cap = %d\n", newSlice, &newSlice, len(newSlice), cap(newSlice))
newSlice[1] += 10
fmt.Printf("After slice = %v, Pointer = %p, len = %d, cap = %d\n", slice, &slice, len(slice), cap(slice))
fmt.Printf("After newSlice = %v, Pointer = %p, len = %d, cap = %d\n", newSlice, &newSlice, len(newSlice), cap(newSlice))
fmt.Printf("After array = %v\n", array)
}
打印输出:
Before slice = [10 20], Pointer = 0xc4200c0040, len = 2, cap = 4
Before newSlice = [10 20 50], Pointer = 0xc4200c0060, len = 3, cap = 4
After slice = [10 30], Pointer = 0xc4200c0040, len = 2, cap = 4
After newSlice = [10 30 50], Pointer = 0xc4200c0060, len = 3, cap = 4
After array = [10 30 50 40]
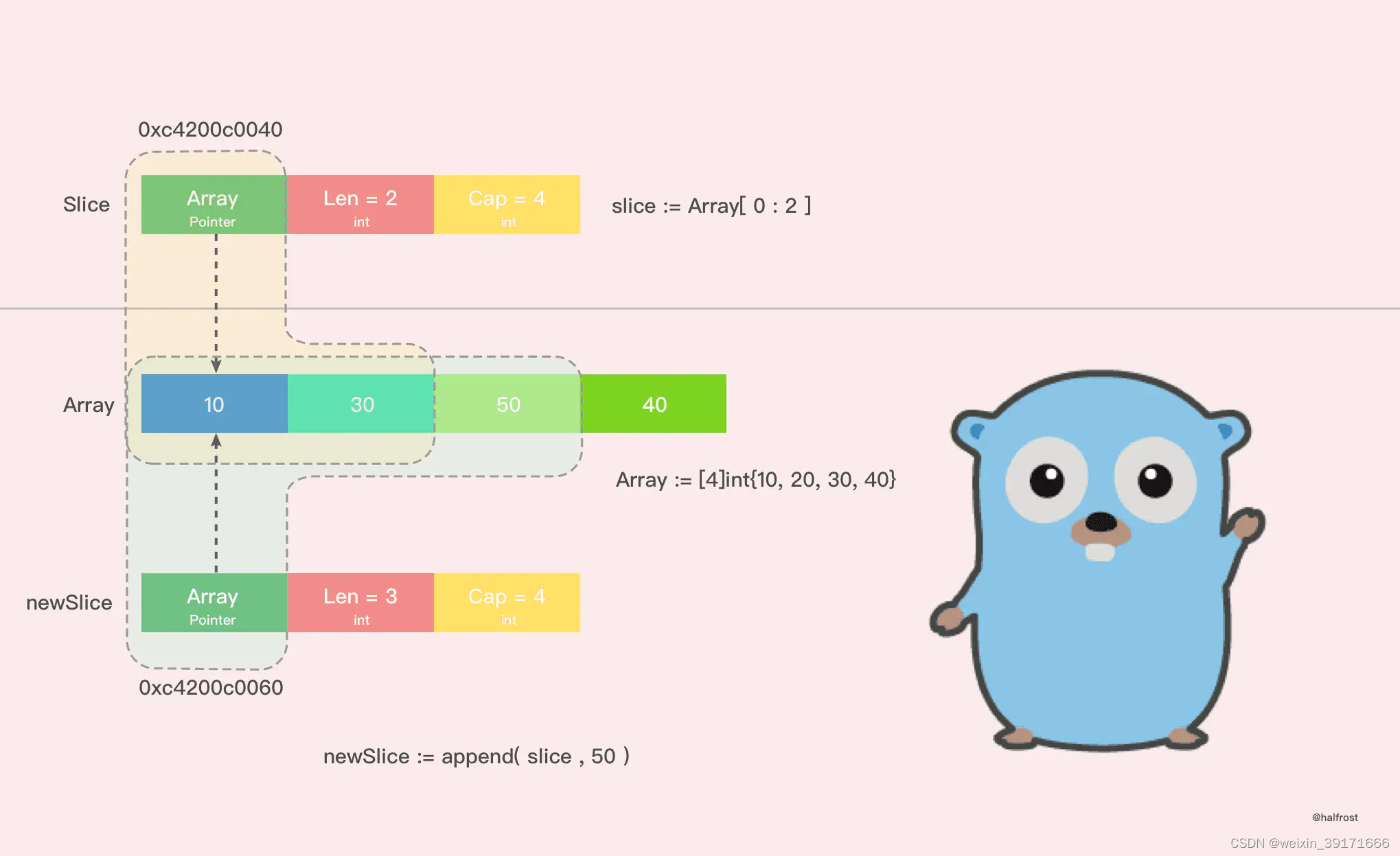
通过打印的结果,我们可以看到,在这种情况下,扩容以后并没有新建一个新的数组,扩容前后的数组都是同一个,这也就导致了新的切片修改了一个值,也影响到了老的切片了。并且 append() 操作也改变了原来数组里面的值。一个 append() 操作影响了这么多地方,如果原数组上有多个切片,那么这些切片都会被影响!无意间就产生了莫名的 bug!
这种情况,执行 append() 操作时,没有超出容量,也就不会重新分配内存空间,切片底层引用的还是原数组,所以还是会在原数组上直接操作,
情况二:
情况二其实就是在扩容策略里面举的例子,在那个例子中之所以生成了新的切片,是因为原来切片的容量已经达到了最大值,再想扩容, Go 默认会先开一片内存区域,把原来切片引用数组的值拷贝过来,然后再执行 append() 操作。这种情况丝毫不影响原数组。
所以建议尽量避免情况一,尽量使用情况二,避免 bug 产生。
正确使用:利用扩容创建新数组的方式(防止影响原数组或原切片)
向切片追加内容时,保证切片已经达到最大容量,即cap=len,这个是时候就会涉及扩容,扩容会创建新数组,自然不会影响到旧数组
package main
import "fmt"
func main() {
array := [4]int{10, 20, 30, 40}
slice := array[0:2:2]//只修改了这里,引用了一个定义的数组,并且声明了切片这时的容量为cap(2)=len(2)
newSlice := append(slice, 50)
fmt.Printf("Before slice = %v, Pointer = %p, len = %d, cap = %d\n", slice, &slice, len(slice), cap(slice))
fmt.Printf("Before newSlice = %v, Pointer = %p, len = %d, cap = %d\n", newSlice, &newSlice, len(newSlice), cap(newSlice))
newSlice[1] += 10
fmt.Printf("After slice = %v, Pointer = %p, len = %d, cap = %d\n", slice, &slice, len(slice), cap(slice))
fmt.Printf("After newSlice = %v, Pointer = %p, len = %d, cap = %d\n", newSlice, &newSlice, len(newSlice), cap(newSlice))
fmt.Printf("After array = %v\n", array)
}
运行结果:
Before slice = [10 20], Pointer = 0xc000008078, len = 2, cap = 2
Before newSlice = [10 20 50], Pointer = 0xc000008090, len = 3, cap = 4
After slice = [10 20], Pointer = 0xc000008078, len = 2, cap = 2
After newSlice = [10 30 50], Pointer = 0xc000008090, len = 3, cap = 4
After array = [10 20 30 40]
或者:
package main
import "fmt"
func main() {
//array := [4]int{10, 20, 30, 40}//不引用一个定义的数组
slice := []int{10, 20}//直接切片初始化的时候,定义切片内容,这个切片也引用了一个数组,只不过是不可见的,这定义的切片容量cap也是等于len的,都是2
//或者使用make
//slice := make([]int, 2, 2)
//slice[0] = 10
//slice[1] = 20
newSlice := append(slice, 50)
fmt.Printf("Before slice = %v, Pointer = %p, len = %d, cap = %d\n", slice, &slice, len(slice), cap(slice))
fmt.Printf("Before newSlice = %v, Pointer = %p, len = %d, cap = %d\n", newSlice, &newSlice, len(newSlice), cap(newSlice))
newSlice[1] += 10
fmt.Printf("After slice = %v, Pointer = %p, len = %d, cap = %d\n", slice, &slice, len(slice), cap(slice))
fmt.Printf("After newSlice = %v, Pointer = %p, len = %d, cap = %d\n", newSlice, &newSlice, len(newSlice), cap(newSlice))
//fmt.Printf("After array = %v\n", array)
}
运行结果:
Before slice = [10 20], Pointer = 0xc000008078, len = 2, cap = 2
Before newSlice = [10 20 50], Pointer = 0xc000008090, len = 3, cap = 4
After slice = [10 20], Pointer = 0xc000008078, len = 2, cap = 2
After newSlice = [10 30 50], Pointer = 0xc000008090, len = 3, cap = 4
当切片底层数组数据不再使用了,就应该释放掉!
极客兔兔博客
下面两个函数都是返回源切片的最后两个元素!
func lastNumsBySlice(origin []int) []int {
return origin[len(origin)-2:]
//返回的是源切片,这个时候虽然只返回了源切片的后两个元素,但是源切片引用的底层数组一样不会被释放。
//当底层数组太大时,就会一直站着内存,很耗性能
}
func lastNumsByCopy(origin []int) []int {
result := make([]int, 2)//定义一个新的切片
copy(result, origin[len(origin)-2:])//将后两个元素拷贝到新切片里
return result//返回一个新的切片,这时源切片底不再被引用,所占用的内存就会被垃圾回收掉
}















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









