









文章目录
前言
重读《Deep Reinforcemnet Learning Hands-on》, 常读常新, 极其深入浅出的一本深度强化学习教程。 本文的唯一贡献是对其进行了翻译和提炼, 加一点自己的理解组织成一篇中文笔记。
第三章 深度学习:Pytorch的使用
在之前的章节中,我们对强化学习有了初步的了解。 但是最新的技术中,强化学习往往与深度学习相结合, 以解决更复杂更具挑战的难题。
这一章就是详细介绍了, 如何通过pytorch 实现 深度学习的方法。 本章的目的并不是详细到如同用户手册般地介绍pytorch的框架,更多地是为了让你们熟悉 这个 框架及常用的API, 为节约时间, 已假设读者拥有基本的深度学习知识。
Pytorch库基础
Tensor 张量
张量 是 深度学习库的最基本组成部分。 其本质就是一个多维的数组。一个单独的数(标量)就是一个0维 (zero-dimension)的张量, 一个向量 就是 一维 张量, 矩阵 则是 二维张量。三维以上的张量则统一称为高维张量。
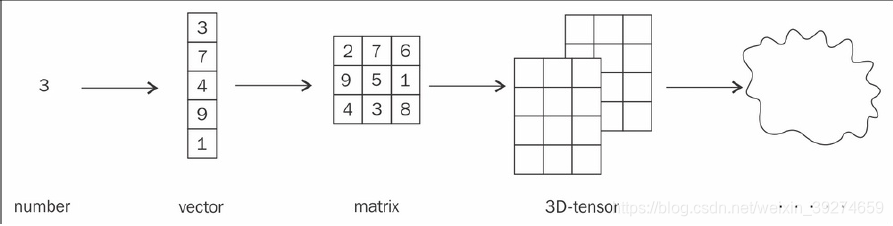
根据数据类型的不同, pytorch中的张量也分为不同的类。 最常用的是 : FloatTensor, ByteTensor 和 LongTensor, 分别代表32位浮点数, 8位整数和64位整数。
有三种方式创建 tensor:
- 直接调用 对应类型张量的构造器
>>> import torch
>>> a = torch.FloatTensor(3, 2)
>>> a
tensor([[ 4.1521e+09, 4.5796e-41],
[ 1.9949e-20, 3.0774e-41],
[ 4.4842e-44, 0.0000e+00]])
上例中, 我们调用了 torch.FloatTensor()得到了一个未初始化的张量。 其接受的参数数量不限, 参数代表每一维的维度。 如上例中, 共有两个参数3和2, 那么就生成了 3*2 的张量。 Pytorch为其分配了内存, 但并未初始化其值。 为了清零该张量(从上例中可以看到, 其值是随机生成的莫名其妙数据), 可以使用zero_()方法:
>>> a.zero_()
tensor([[ 0., 0.],
[ 0., 0.],
[ 0., 0.]])
在pytorch中, 后面加了下划线 “_” 的方法,代表 替换操作 (Inplace)。即, 该方法直接在本张量上操作,返回值即是被操作后的张量。 如上例中, a.zero_()即是对张量a本身进行操作。
- 另一种创建方式 是 转换 python中的 可迭代对象, 如 list, tuple, numpy数组等, 将其作为张量的内容来创建张量。
>>> torch.FloatTensor([[1,2,3],[3,2,1]])
tensor([[ 1., 2., 3.],
[ 3., 2., 1.]])
>>> import numpy as np
>>> n = np.zeros(shape=(3, 2))
>>> n
array([[ 0., 0.],
[ 0., 0.],
[ 0., 0.]])
>>> b = torch.tensor(n)
>>> b
tensor([[ 0., 0.],
[ 0., 0.],
[ 0., 0.]], dtype=torch.float64)
上例中, 分别可以将 python 列表, 和 numpy 数组, 转化为 新创建的张量的 内容。 第二个例子中, 发现有numpy 数组转化的tensor b, 自动继承了numpy的数据类型, 即torch.float64, 一般而言, 64位的高精度浮点数是不必要的且严重浪费内存, 我们可以这样改变:
>>> n = np.zeros(shape=(3, 2), dtype=np.float32)
>>> torch.tensor(n)
tensor([[ 0., 0.],
[ 0., 0.],
[ 0., 0.]])
即, 指定numpy的数据类型, 这样转换后的torch.tensor也会继承该类型。 另一种是在转换时直接指定tensor的数据类型:
>>> n = np.zeros(shape=(3,2))
>>> torch.tensor(n, dtype=torch.float32)
tensor([[ 0., 0.],
[ 0., 0.],
[ 0., 0.]])
- 直接使用已有API来创建张量。
>>> a = torch.zeros(3,2)
>>> a
tensor([[0., 0.],
[0., 0.],
[0., 0.]])
标量张量
目前pytorch已经支持标量张量, 而无需再像以前一样,创建一个维度为1的一维张量。
>>> a = torch.tensor([1,2,3])
>>> a
tensor([ 1, 2, 3])
>>> s = a.sum()
>>> s
tensor(6)
>>> s.item()
6
>>> torch.tensor(1)
tensor(1)
s就是一维张量, 通过item()方法,可以直接获取其数值。
张量的操作
绝大部分时候, Numpy库的操作,一般在Pytorch中也有对应类似的API。比如 torch.stack(), torch.transpose(), and torch.cat().。更一般的API接口们可以到pytorch的官方文档中查询。
张量 与 梯度
作为深度学习的库, 张量需要有一个极为重要的性质: 自动计算梯度值。 当然你也可以选择,自己手动计算梯度值, 来完成神经网络的训练。 这样有助于理论的理解, 但无疑, 每次重复这样的步骤是极为枯燥的。 因此,我们希望能自动计算梯度。
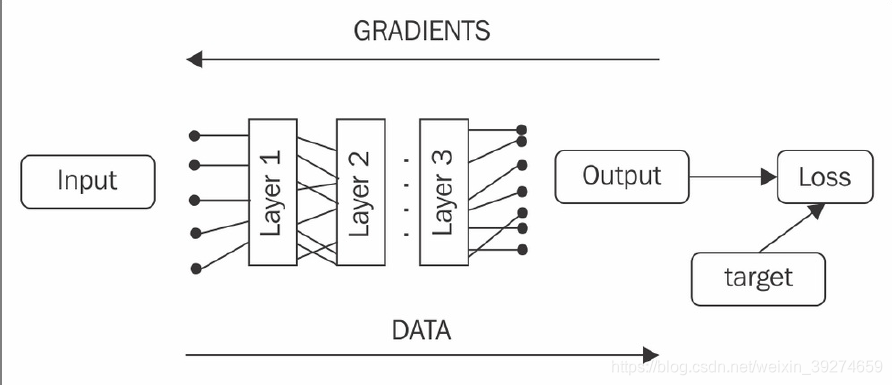
当今所有流形的深度学习框架, 都拥有自动计算梯度的机制——虽然具体实践上会有所区别,但是都贯彻一点: 你指定你的网络中输入到输出的具体顺序, 框架会自动帮你计算梯度,后向传播。
- 静态图框架: Tensorflow1.0, Theano等框架。 在开始运算前, 你必须完整定义你的计算图(即输入到输出的具体结构)。 在开始运算前, 框架会对其进行计算优化。 静态图的优点是 运行效率更高速度更快, 缺点则是难以进行调试, 且无法在计算图生成后动态修改。
- 动态图框架: pytorch。 不需要预先定制好整个计算图。 框架会记录你当前的计算顺序, 储存对应的梯度值, 来服务于神经网络的计算。 调试 和 搭建网络的灵活性上, 动态图远远优于静态图。 这一方法也被称为 notebook gradient。
Pytorch 的 张量, 内置了 梯度计算和跟踪机制, 因此, 你只需要把数据转换为张量, 然后使用pytorch提供的API进行操作即可。 每个张量都含有以下几个与梯度相关的属性:
- grad:自动计算的梯度——是和张量本身维度一样的张量。
- is_leaf: 如果张量由用户创建, 则为True; 有转化函数得到,则为False。
- requires_grad: 张量是否需要计算梯度, 是则为True。默认值为False,即无需计算。
为了让pytorch 的 gradient-leaf机制 更为清晰, 我们举一个例子:
>>> v1 = torch.tensor([1.0, 1.0], requires_grad=True)
>>> v2 = torch.tensor([2.0, 2.0])
>>> v_sum = v1 + v2
>>> v_res = (v_sum*2).sum()
>>> v_res
tensor(12.)
>>> v1.is_leaf, v2.is_leaf
(True, True)
>>> v_sum.is_leaf, v_res.is_leaf
(False, False)
>>> v1.requires_grad
True
>>> v2.requires_grad
False
>>> v_sum.requires_grad
True
>>> v_res.requires_grad
True
>>> v1.grad
>>>
>>> v_res.backward()
>>> v1.grad
tensor([ 2., 2.])
>>> v2.grad
>>>
这个例子中,我们可以知道:
- 因为v1 的 requires_grad属性为真,因此由其计算得到的v_sum, v_res的该属性默认为真。
- 对最后的结果v_res使用backward()方法, pytorch会自动求出整个计算图中, requires_grad属性为真的张量的梯度。可以看到, 在使用backward()前, v1.grad返回为空。使用后, v1返回了相对于v_res的正确梯度。
- v2由于requires_grad为False, 因此没有算出其grad。
- 注意, 这里只能对v_res,即最后的结果使用backward()。 因为该方法只能对最后的标量结果使用, v_sum是张量, 无法使用backward(),去求出v1对于v_sum的梯度。
requires_grad属性, 可以有效地把计算资源用于计算我们关心的变量——如神经网络中,需要加以优化的权重矩阵, 而对于那些无关的变量等,我们可以将属性设为False,不必浪费资源去计算其梯度。
Pytorch 的神经网络包:torch.nn
神经网络多年的积累后, 已有了许多通用的网络结构。 pytorch中提供了快速实现这些结构的API,使得你不需要自己手动从底层开始搭建。 这些API归在torch.nn包中。
这些网络API由类实现, 由于实现了__callable__ 内置方法, 可以像调用函数一样使用。 以 实现 普通全连接网络的线性层Linear为例:
>>> import torch.nn as nn
>>> l = nn.Linear(2, 5) # 参数为 输入维度 和 输出维度
>>> v = torch.FloatTensor([1, 2])
>>> l(v)
tensor([ 0.1975, 0.1639, 1.1130, -0.2376, -0.7873])
这里,我们创建了一个随机初始化的前馈线性层 ,来处理我们的张量v。torch.nn中所有类都继承自基类nn.Module, 你也可以自定义自己的网络结构层。 nn.Module 主要提供了以下这些基本方法:
- parameters(): 返回了一个迭代器, 里面包括所有需要求梯度的网络变量(比如网络的权重) 。 注:迭代器实现了__next__方法, 对迭代器a可以使用next(a),获取a中的值。
- zero_grad():顾名思义, 将所有变量的梯度清零,一般用于初始化。
- to(device):使用GPU加速
- state_dict():返回网络中的所有变量值
- load_state_dict():以现有的字典数据,初始化网络参数。
以下是这些方法的示例:
>>>l1 = nn.Linear(2,3)
>>>l2 = nn.Linear(2,3)
>>>a = l1.state_dict()
>>>a
Out[73]:
OrderedDict([('weight',
tensor([[-0.3434, 0.6596],
[ 0.4947, 0.6010],
[-0.1376, 0.5829]])),
('bias', tensor([-0.2760, 0.4102, 0.4186]))])
>>>b = l2.state_dict()
>>>b
Out[75]:
OrderedDict([('weight',
tensor([[ 0.2113, 0.0015],
[-0.4391, 0.2420],
[-0.2873, 0.0567]])),
('bias', tensor([0.6091, 0.2362, 0.2396]))])
>>>l2.load_state_dict(a)
Out[76]: <All keys matched successfully>
>>>l2.state_dict()
Out[77]:
OrderedDict([('weight',
tensor([[-0.3434, 0.6596],
[ 0.4947, 0.6010],
[-0.1376, 0.5829]])),
('bias', tensor([-0.2760, 0.4102, 0.4186]))])
接着,再介绍能将多个网络层 串联在一起 构成一个神经网络的类:nn.Sequential, 同样,也用例子来诠释他的用法:
>>> s = nn.Sequential(
... nn.Linear(2, 5),
... nn.ReLU(),
... nn.Linear(5, 20),
... nn.ReLU(),
... nn.Linear(20, 10),
... nn.Dropout(p=0.3),
... nn.Softmax(dim=1))
>>> s
Sequential (
(0): Linear (2 -> 5)
(1): ReLU ()
(2): Linear (5 -> 20)
(3): ReLU ()
(4): Linear (20 -> 10)
(5): Dropout (p = 0.3)
(6): Softmax ()
)
>>> s(torch.FloatTensor([[1,2]]))
tensor([[ 0.1410, 0.1380, 0.0591, 0.1091, 0.1395, 0.0635,
0.0607,
0.1033, 0.1397, 0.0460]])
nn.Linear, nn.ReLu, nn.Dropout, nn.Softmax,都是同名的知名网络层/激活函数的相应类。Sequential接受这些类作为参数, 并拼接成一个完整的神经网络。
以上就是简单地对 torch.nn包预定义的API进行简单应用的讲述啦!
自定义网络层
在上一节中,我们介绍了nn的Module类——所有预定义的知名网络层都继承自它。 同时,你也可以通过创建其子类, 定义自己的网络层,并完美地融入pytorch框架之中。你可以构建一个 一层的小网络层, 也可以构建一个1000多层的ResNet。接下来,还是用代码示例来说明:
import torch
import torch.nn as nn
class OurModule(nn.Module):
def __init__(self, num_inputs, num_classes, dropout_prob=0.3):
super(OurModule, self).__init__()
self.pipe = nn.Sequential(
nn.Linear(num_inputs, 5),
nn.ReLU(),
nn.Linear(5, 20),
nn.ReLU(),
nn.Linear(20, num_classes),
nn.Dropout(p=dropout_prob),
nn.Softmax(dim=1)
)
def forward(self, x):
return self.pipe(x)
if __name__ == "__main__":
net = OurModule(num_inputs=2, num_classes=3)
print(net)
v = torch.FloatTensor([[2, 3]])
out = net(v)
print(out)
这一段代码中, 我们先在初始化__init__函数中,调用了父类的初始化函数,借着利用Sequential类, 创建了一个简单的网络。 然后我们重写了 forward()函数——这个是自定义函数中必不可少的, 其接受输入数据, 返回输出结果。 在实例使用中, 首先创建自定义类的一个实例net, 注意:Module类实现了__str__方法,因此可以直接print(net)来打印网络。 需要注意的是,虽然我们定义的是forward()函数,但我们使用的时候, 是直接使用net(v)来对v做变换。 这是因为Module类实现了__callable__方法,直接使用net(v)就是调用了forward()。因此,不要使用net.forward(v), 直接使用net(v)即可。
损失函数与优化器
损失函数
pytorch中,预定义了许多著名的损失函数:
- nn.MSELoss
- nn.BCELoss: Binary cross-entropy loss. 二元交叉熵。
- nn.CrossEntropyLoss: 用于多分类问题的交叉熵。
优化器
pytorch中,预定义了常用的优化器:
- torch.optim.SGD:随机梯度下降优化器
- torch.optim.Adam: Adam优化器
- torch.optim.RMSprop: RMSprop优化器
创建优化器的时候, 你可以自定义参数来控制具体的优化,如:
torch.optim.Adagrad(params, lr=0.01, lr_decay=0, weight_decay=0)
第一个参数为 需要梯度优化的参数。 第二个参数lr就是学习率的缩写。 第三个参数代表学习率的衰减,默认为0, 第四个代表权重衰减。
以下是实例中对优化器的使用:
for batch_samples, batch_labels in iterate_batches(data, batch_size=32):
batch_samples_t = torch.tensor(batch_samples))
batch_labels_t = torch.tensor(batch_labels))
out_t = net(batch_samples_t)
loss_t = loss_function(out_t, batch_labels_t)
loss_t.backward()
optimizer.step()
optimizer.zero_grad()
这段代码的流程是:
在循环中,每次取出一部分的样本(mini-batch), 用于网络优化训练。 首先,前两行代码,将原始数据samples和labels转为torch的张量。 然后用定义的net网络对其进行处理, 得到输出out。 将out和标签输入loss函数,可以得到损失值。 对损失值使用backward()方法,pytorch会自动对网络处理中所有需要计算梯度的变量,求取其梯度。 接着调用优化器optimizer的step()方法, 优化器会根据求好的梯度,对网络进行优化。最后一步优化器调用zero_grad(),清零本次的梯度。
我们已经了解了pytorch库 搭建一个神经网络及训练的 核心要素。 但在以一个实际的例子融汇之前, 我们再了解一个重要的工具:监视器。
通过Tensorboard监控网络训练
只要你训练过神经网络,你就知道这是一件不确定性极大的事情。 哪怕时至今日, 即使你有很强的直觉, 也无法第一次就跑通完美的网络。 因此,你希望可以监控训练的过程,来找出问题所在。 训练中,人们一般会监测这些指标:
- 损失值
- 在验证集和测试集上的表现
- 梯度 和 权重 的相关数据统计
- 学习率, 以及其他超参数
Tensorboard 就是 满足这一需求的经典工具。
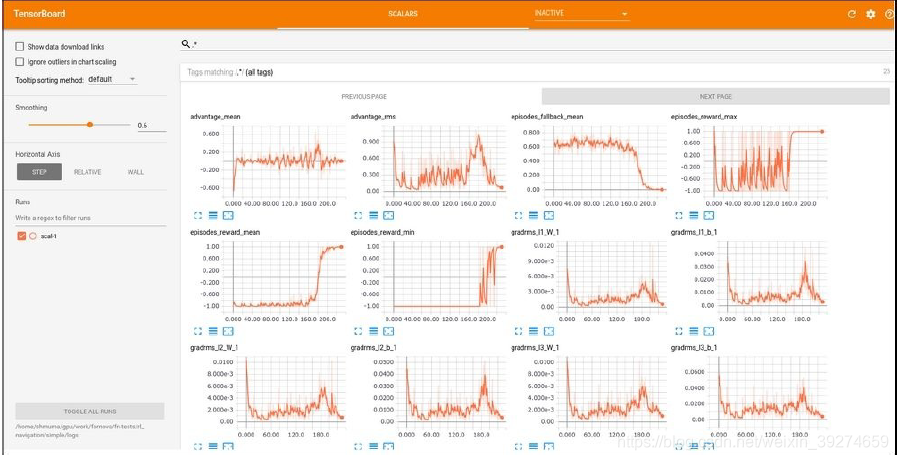
他可以监控到训练中的各种数据。 Tensorboard是使用流程如下:
- 进行训练, 并存储数据到本地字典
- 打开tensorboard的网络服务
- 打开浏览器, 输入正确的端口号, 观看监控结果
当你是使用非本地计算机时,这一功能尤其完美——你可以通过网页访问云端服务器的训练情况。
照例,我们用实例来说明:
在使用前, 请务必使用
pip install tensorboard-pytorch下载相关的组件。下载该包会自动下载tensorboard。 接下来, 找到下载到的tensorboard.exe的路径, 将其添加到windows的环境变量中(这里不会的百度)。
运行如下代码 02_tensorboard.py
import math
from tensorboardX import SummaryWriter
if __name__ == "__main__":
writer = SummaryWriter()
funcs = {"sin": math.sin, "cos": math.cos, "tan": math.tan}
for angle in range(-360, 360):
angle_rad = angle * math.pi / 180
for name, fun in funcs.items():
val = fun(angle_rad)
writer.add_scalar(name, val, angle)
writer.close()
这段代码并不涉及神经网络, 只是展示了如何使用tensorboard。 即, 用SummaryWriter()创建了一个实例, 接着使用add_scalar方法, 写入参数, 用于后续的可视化展示。
运行完上述代码后, 路径中应该出现了一个名为run的文件夹, 里面的子文件夹是以运行时间命名的, 子文件夹内就是刚刚运行后保存的数据文件, 用于tensorboard的可视化。 注意, 每次运行这段py代码,都会生成一个以运行时间命名的子文件夹。我的路径结构如下(代码大家可以直接clone上面给出的全书源代码的github库,我就是这么做的):
确保已经生成上述文件后,就可以进行可视化的操作了!
首先,复制自己要可视化的文件夹的路径(注意, 是文件夹的路径,而不是文件的路径),比如, 我的路径是 C:\Deep-Reinforcement-Learning-Hands-On\Chapter03\runs。
接下来, 打开命令行, 输入以下代码
tensorboard --logdir C:\Deep-Reinforcement-Learning-Hands-On\Chapter03\runs
出现如下结果(如果出现说 tensorboard不是命令之类的报错,那时因为你没有把tensorboard的路径配置到环境路径中):
忽略中间的无聊警告,看到最后一句,就是tensorboard已经在本地的6006号端口上运行了。 这时候, 我们打开浏览器 (我用的是chrome,也推荐大家使用,谷歌自家的), 在地址栏输入http://localhost:6006/,可以看到如下的网页:

完美地可视化了我们刚刚写入的数据!















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











