






总结:
np. argmin() 最小值索引
np.argmax() 最大值索引
np. argwhere(x>0.5) 指定条件索引
np.random.shuffle() 打乱顺序
np.sort() 排序
np. argsort() 排序索引
np. partition(x,5) 指定位置分割
np.argpartition(x,5) 分割索引
1.启动jupyter notebook
2.创建一个新的notebook,并导入numpy

3.创建一个随机数据x,并使用随机数种子
np.random.seed(100)
x = np.random.random(50)
x运行效果图如下:

4.np. argmin()求出最小值的位置,np. argmax()求出最大值的位置
#1.取出最小值
np.min(x)
#结果:0.004718856190972565
#2.得出最小值的位置
np.argmin(x)
#结果:4
#3.取出位置为4的值
x[4]
#结果:0.004718856190972565
#4.取出最大值的位置
np.argmax(x)
#结果:36运行效果图如下:

5.ind =np. argwhere(x>0.5)得到值大于0.5的所有索引的位置,可通过x[ind]取出对应的值
#1.取出指定条件的索引值
ind = np.argwhere(x>0.5)
ind
#2.取出索引值对应的值
x[ind]运行效果图如下:


6.排序和乱序
#1.创建一个随机数组x
x = np.arange(10)
x
#结果:array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
#2.将x顺序打乱,且x本身值改变
np.random.shuffle(x)
x
#结果:array([1, 6, 3, 5, 4, 0, 2, 7, 8, 9])
#3.将x重新排序,不改变x本身的值
np.sort(x)
#结果:array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
x
#结果:array([1, 6, 3, 5, 4, 0, 2, 7, 8, 9])
#4.直接使用x.sort()排序,改变x本身的值
x.sort()
x
#结果:array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
运行效果如下:

7.使用np. argsort(x),则会返回索引排序
#1.重新将x的顺序打乱
np.random.shuffle(x)
x
#结果:array([4, 2, 8, 7, 5, 1, 3, 6, 0, 9])
#2.返回排序后的索引值,并保存在变量ind中
ind = np.argsort(x)
ind
#结果:array([8, 5, 1, 6, 0, 4, 7, 3, 2, 9], dtype=int32)
#3.取出第一个索引对应的值
x[8]
#结果:0运行效果如下:

对索引进行切片操作:
#1.取出前三个索引值
ind[:3]
#结果:array([8, 5, 1], dtype=int32)
#2.取出前三个索引对应的值
x[ind[:3]]
#结果:array([0, 1, 2])
#3.取出排序后最后三位数
x[ind[-3:]]
#结果:array([7, 8, 9])运行效果图如下:

8.np. partition(x,5),将x分割成小于5和大于5在左右两侧。np. argpartition(x,5)返回小于5和大于5对应值的索引值
#1.重新输出x的值
x
#结果:array([4, 2, 8, 7, 5, 1, 3, 6, 0, 9])
#2.将<5的值放在左侧,>5的值放在右侧
np.partition(x, 5)
#结果:array([1, 4, 0, 3, 2, 5, 7, 6, 8, 9])
#3.将<5对应的索引放在左侧,>5对应的索引值放在右侧
np.argpartition(x,5)
#结果:array([5, 0, 8, 6, 1, 4, 3, 7, 2, 9], dtype=int32)
运行效果如下:

9.对二维数组进行排序
#1.创建一个二维数组X
X = np.random.randint(20,size=(4,5))
X
#2.默认对每一行进行排序
np.sort(X)
#3.对每一列进行排序
np.sort(X,axis=0)
运行效果图如下:

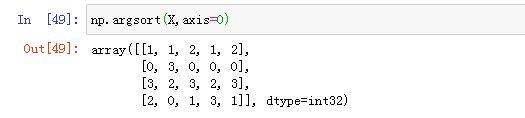
10.np.argsort(X,axis=0)对每一列索引排序,运行效果图如下:















 1197
1197











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









