






1.启动jupyter notebook
2.创建一个新的notebook
3.导入pandas
4.通过字典构建一个DataFrame对象
data = {
'name':['张三','李四','王五','赵六'],
'age':[18,19,17,20],
'height':[1.68,1.73,1.62,1.55]
}
df = pd.DataFrame(data,columns=['name','age','height'])
df
运行效果图如下:

5.获取列数据
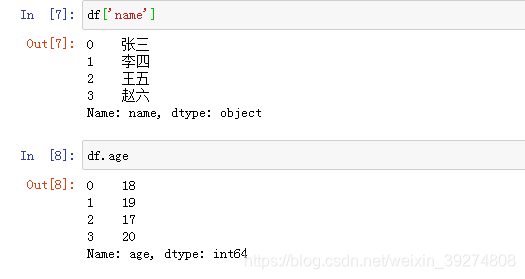
#1.获取姓名
df['name']
#2.获取年龄
df.age
运行效果图如下:
6.中括号传入一个列表,输出仍然DataFrame对象
#1.输出一列数据
df[['name']]
#2.输出多列数据
df[['name','age']]
运行效果图如下:

7.修改值,会报出警告
#1.将第一列赋值给names
names = df['name']
#2.修改第一列的第一个值
names[0] = '张三丰'
names
#3.输出df
df
运行效果图如下:

8.如果在引用后面加上. copy(),那么引用的改变,就不会改变原有df的值
#1.修改引用中的值
names = df.name.copy()
names[0] = '张无忌'
names
#2.重新输出df
df
运行效果图如下

9.df. colunms()获取列名,还可对获取的列名进行切片操作
#1.获取所有列名
df.columns
#2.获取指定列名
df.columns[1:3]
#3.获取列名对应的数值
df[df.columns[1:3]]
运行效果图如下:

10.添加列数据
#1.导入datetime模块
import datetime
#2.添加新的列year
df['year'] = datetime.datetime.now().year - df.age
#3.再次输出df
df
运行效果图如下:

11.删除列数据
#1.删除一列
df.drop('year',axis=1)
#2.删除多列
df.drop(['height','year'],axis=1)
运行效果图如下:

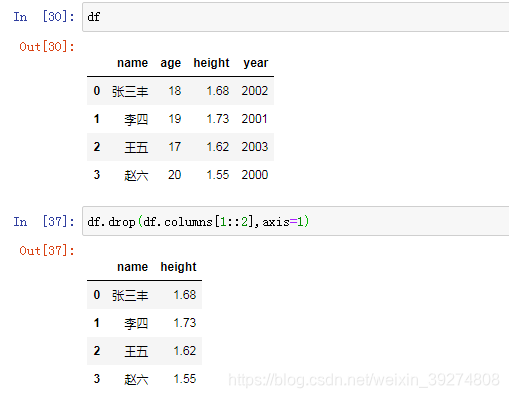
12.使用切片形式删除列
#1.重新输出df
df
#2.使用切片形式删除列
df.drop(df.columns[1::2],axis=1)
运行效果图如下:
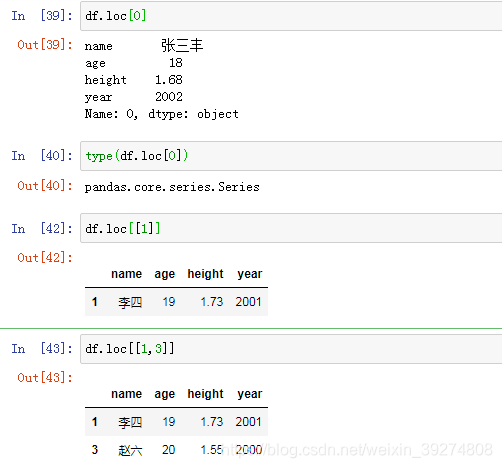
13.获取行数据
#1.输出第一行数据,返回一个Series对象
df.loc[0]
#2.输出第一行数据的类型
type(df.loc[0])
#3.传入一个列表,输出DataFrame对象
df.loc[[1]]
#4.输出多行数据
df.loc[[1,3]]
运行效果图如下:
14.index默认为整数类型,df. index获取所有索引值,可对index进行切片
#1.获取所有索引值
df.index
#2.获取最后两个索引值
df.index[-2:]
#3.获取最后两列索引对应的值
df.loc[df.index[-2:]]
运行效果图如下:
















 1554
1554











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









