







分群思维(一)基于RFM的用户分群
小P:小H,我有什么很好的方法可以对用户进行分群呢?这样我就可以针对不同用户开启特定的运营了
小H:简单的话可以尝试下RFM方法呢
小P:RFM方法是什么?
小H:RFM是通过最近一次消费(Recency)、消费频率(Frequency)、消费金额(Monetary)三个维度将用户进行区分,一般认为RFM较高的用户为高价值用户,RFM都很低的为低价值用户。而且对于一些特别的用户也能友好识别,例如RF较低,M却很高的用户有可能是潜在大客户,需要重点挽留等。
小P:那太好了,我这刚好有一些会员用户的消费数据,你帮我做一下分群吧~
小H:好(…)~
大多数情况,我们可以根据业务本身进行分群,例如异动分析中的维度下钻。但实际业务中也会存在一些需要通过数据对指定对象进行分群,这里我将介绍下最常见的用户分群方法-RFM。
RFM分箱
RFM最重要的一步就是对三个指标进行分箱操作,常见的方法有业务定义、二八原则、聚类等方法。例如业务上认为高于99元的就属于大客户,20%的头部用户贡献了80%的消费金额,聚类区分出了小额消费、中等消费和大额消费群体等。这里着重分享业务定义和聚类的方法。
import time
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from pyecharts.charts import Bar3D
from pyecharts import options as opts
import matplotlib.pyplot as plt
from IPython.display import display
import seaborn as sns
from sklearn.cluster import KMeans # 导入sklearn聚类模块
from sklearn.metrics import silhouette_score # 效果评估模块
以下数据如果有需要的同学可关注公众号HsuHeinrich,回复【分群思维01】自动获取~
# 读取数据
df = pd.read_excel('user_class.xlsx',sheet_name='2018')
df_user_grade = pd.read_excel('user_class.xlsx',sheet_name='会员等级')
df.head()
# 去除缺失值和异常值
df = df.dropna()
df = df[df['订单金额']>1] # 订单金额<=1业务认为异常
# 新增提交日期最大值,替代截止日期
df['max_year_date'] = df['提交日期'].max() # 增加一列最大日期值
# 计算日期差
df['date_interval'] = df['max_year_date']-df['提交日期']
df['date_interval'] = df['date_interval'].apply(lambda x: x.days) # 转换日期间隔为数字
# 按会员ID做汇总
rfm_gb = df.groupby(['会员ID'],as_index=False).agg({'date_interval': 'min', # 计算最近一次订单时间
'提交日期': 'count', # 计算订单频率
'订单金额': 'sum'}) # 计算订单总金额
# 重命名列名
rfm_gb.columns = ['会员ID', 'r', 'f', 'm']
# 匹配会员等级
rfm_merge = pd.merge(rfm_gb,df_user_grade,on='会员ID',how='inner')
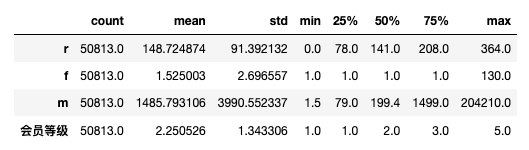
# 数据分布查看
rfm_merge.iloc[:,1:].describe().T
方案一:基于业务逻辑分箱
# 定义区间边界-业务逻辑
r_bins = [-1,78,208,365] # 默认为左开右闭区间(首边界应小于min),按照25%和75%划分为三类
f_bins = [0,2,5,130] # 业务划分
m_bins = [0,79,1499,204210] # 25%与75%位数
# 计算分箱得分
rfm_merge['r_score'] = pd.cut(rfm_merge['r'], r_bins, labels=[i for i in range(len(r_bins)-1,0,-1)]) # 计算R得分 3,2,1
rfm_merge['f_score'] = pd.cut(rfm_merge['f'], f_bins, labels=[i+1 for i in range(len(f_bins)-1)]) # 计算F得分 1,2,3
rfm_merge['m_score'] = pd.cut(rfm_merge['m'], m_bins, labels=[i+1 for i in range(len(m_bins)-1)]) # 计算M得分 1,2,3
rfm_merge.head()
方案二:聚类分箱
聚类最重要的是确定簇数,这里介绍两种方法:Elbow和轮廓系数
- Elbow法
# 法1:使用Elbow方法,得到最有的kmeans的簇 sse={} X = rfm_merge[['r']].copy() for k in range(2, 10): kmeans = KMeans(n_clusters=k, max_iter=1000).fit(X) X["clusters"] = kmeans.labels_ sse[k] = kmeans.inertia_ plt.figure() plt.plot(list(sse.keys()), list(sse.values())) plt.xlabel("Number of cluster") plt.show()
- 轮廓系数法
# 法2:通过轮廓系数得到最有的kmeans的簇 def best_k(X, k, **kwargs): score_list = list() # 用来存储每个K下模型的平局轮廓系数 silhouette_int = -1 # 初始化的平均轮廓系数阀值 for n_clusters in range(2, k+1): # 遍历从2到k+1个有限组 model_kmeans = KMeans(n_clusters=n_clusters, **kwargs) # 建立聚类模型对象 labels_tmp = model_kmeans.fit_predict(X) # 训练聚类模型 silhouette_tmp = silhouette_score(X, labels_tmp) # 得到每个K下的平均轮廓系数 if silhouette_tmp > silhouette_int: # 如果平均轮廓系数更高 best_k = n_clusters # 保存K将最好的K存储下来 silhouette_int = silhouette_tmp # 保存平均轮廓得分 best_kmeans = model_kmeans # 保存模型实例对象 cluster_labels_k = labels_tmp # 保存聚类标签 score_list.append([n_clusters, silhouette_tmp]) # 将每次K及其得分追加到列表 return best_k, best_kmeans, cluster_labels_k X = rfm_merge[['r']] best_k, best_kmeans, cluster_labels = best_k(X, 4, max_iter=1000) print(best_k)4
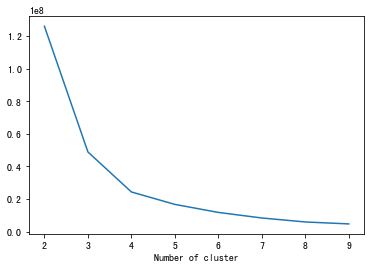
这里通过Elbow法对rfm进行定簇数,下图可以看到r、f、m的拐点均在簇数为4。
# Elbow确定rfm簇数
fig = plt.figure(figsize=(10,6))
for i, x in enumerate(['r', 'f', 'm']):
X=rfm_merge[[x]].copy()
for k in range(2, 10):
kmeans = KMeans(n_clusters=k, max_iter=1000).fit(X)
X["clusters"] = kmeans.labels_
sse[k] = kmeans.inertia_
point = int('22'+str(i+1))
plt.subplot(point)
plt.plot(list(sse.keys()), list(sse.values()))
plt.xlabel("%s cluster numbers" % x)
fig.tight_layout()
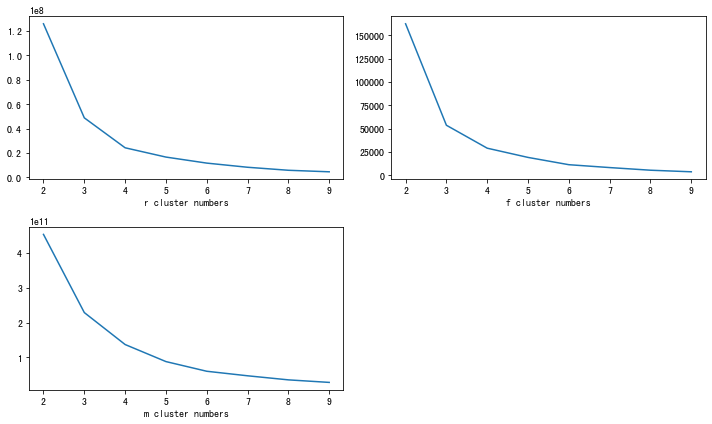
# rfm的簇可以定为k=4
for x in ['r', 'f', 'm']:
X=rfm_merge[[x]].copy()
model_kmeans=KMeans(n_clusters=4)
kmeans_result=model_kmeans.fit(X)
rfm_merge['%s_cluster_label' % x] = kmeans_result.labels_
def cluster_order(cluster_lable, target, df, ascending=True):
'''
对聚类标签重新赋值:使其标签具有比较意义,即较大的标签值较大
cluster_lable:聚类标签
target:目标值
df:数据集
ascending:默认为升序
'''
cluster_lable_mean=df.groupby(cluster_lable)[target].mean().sort_values(ascending=ascending).reset_index()
lable_map=dict(zip(cluster_lable_mean[cluster_lable],cluster_lable_mean.index))
df[cluster_lable]=df[cluster_lable].map(lable_map)
return df
# 对聚类标签赋予大小意义
# 主要目的是r聚类结果越大,对应的r值越小,即r分值越高
for target,cluster_lable in [('r', 'r_cluster_label'), ('f', 'f_cluster_label'), ('m', 'm_cluster_label')]:
if target=='r':
cluster_order(cluster_lable, target, rfm_merge, ascending=False)
else:
cluster_order(cluster_lable, target, rfm_merge)
print('%s结果:' % target,'\n','-'*80)
display(rfm_merge.groupby(cluster_lable)[target].describe())
r结果:
--------------------------------------------------------------------------------
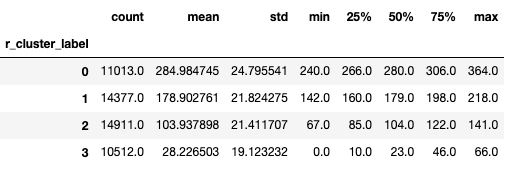
f结果:
--------------------------------------------------------------------------------
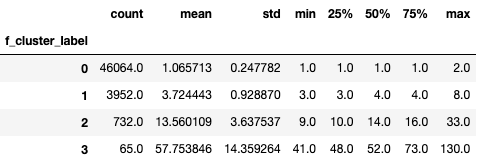
m结果:
--------------------------------------------------------------------------------
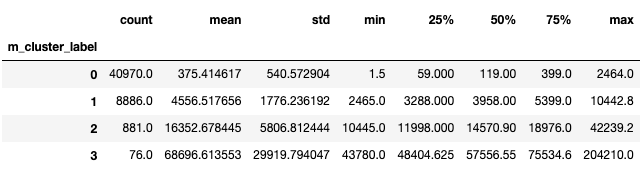
上面数据结果表明,当r聚类的结果为0时,该簇的最大r值为364,当r聚类的结果为3时,该簇的最大r值为66。表明r聚类的结果越大,消费时间越近,符合业务意义。同样的f聚类结果越大,消费频次越多;m聚类结果越大,消费金额越高。
RFM得分
分完箱后,就需要对各维度进行组合计算RFM的分数了。常见的组合方式有两种,一是加权得分,而是直接组合。
⚠️注意:为了方便,下面的分箱结果是基于业务逻辑下的分箱结果
方案一:加权得分
# 下述以业务分箱结果计算,聚类分箱结果可自行尝试
# 通过机器学习获得变量权重
clf = RandomForestClassifier(random_state=0)
clf = clf.fit(rfm_merge[['r','f','m']], rfm_merge['会员等级']) # 利用会员等级作为目标,提取rmf的权重
weights = clf.feature_importances_
print('feature importance:',weights)
# 加权得分
rfm_merge[['r_score', 'f_score', 'm_score']]=rfm_merge[['r_score', 'f_score', 'm_score']].astype(int)
rfm_merge['rfm_score'] = rfm_merge['r_score'] * weights[0] \
+ rfm_merge['f_score'] * weights[1] + rfm_merge['m_score'] * weights[2]
feature importance: [0.38219219 0.00878397 0.60902384]
方案二:组合得分
# 方法二:RFM组合
rfm_merge[['r_score', 'f_score', 'm_score']]=rfm_merge[['r_score', 'f_score', 'm_score']].astype(str)
rfm_merge['rfm_group'] = rfm_merge['r_score'].str.cat(rfm_merge['f_score']).str.cat(rfm_merge['m_score'])
rfm_merge.head()

结果展示
# 加权得分分布
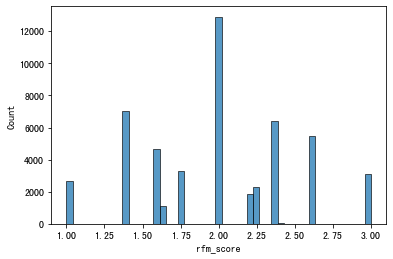
rfm_merge['rfm_score'].describe()
count 50813.000000
mean 1.989802
std 0.496024
min 1.000000
25% 1.609024
50% 1.991216
75% 2.373408
max 3.000000
Name: rfm_score, dtype: float64
# rfm加权得分的直方图
sns.histplot(rfm_merge['rfm_score'])
plt.show()
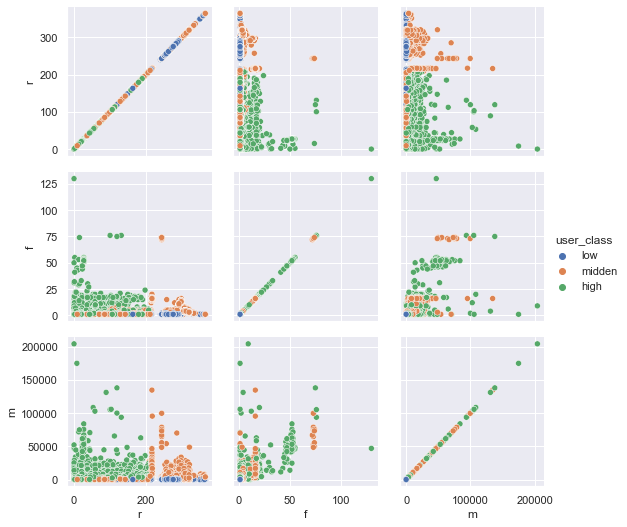
# 加权得分散点图
rfm_score_bins = [0,1.61,2.37,3] # 默认为左开右闭区间(首边界应小于min),按照25%和75%划分为三类
rfm_merge['user_class'] = pd.cut(rfm_merge['rfm_score'],
rfm_score_bins, labels=['low' ,'midden', 'high']) # 用户分类
sns.set(rc = {'figure.figsize':(15,8)})
g=sns.PairGrid(rfm_merge, hue="user_class", vars=["r", "f", "m"])
g=g.map(sns.scatterplot)
g = g.add_legend() # 手动添加图例
# 位置列重命名,首列重命名
def loc_col_rename(i, new_col, df):
'''
df.rename(columns={df.columns[0]: "new_col"}, inplace=True)
上述代码将所有与column[0]同名的列替换为'new_col',而不管它们的位置如何
如果存在同名列,尝试本函数
'''
df = df.copy()
s = df.columns.to_series()
s.iloc[i] = new_col
df.columns = s
return df
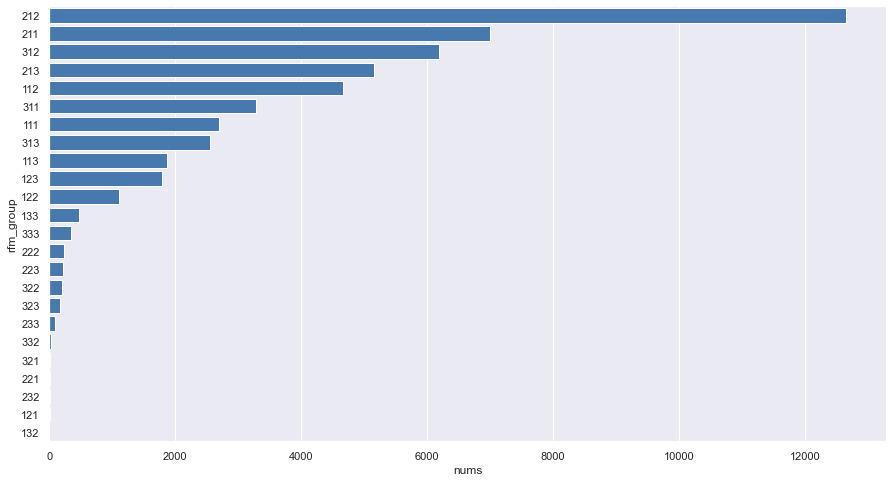
# rfm组合得分的条形图
rfm_group_df=rfm_merge.groupby('rfm_group').size().sort_values(ascending=False).reset_index()
rfm_group_df=loc_col_rename(1, 'nums', rfm_group_df)
sns.barplot(x="nums", y="rfm_group",
data=rfm_group_df, orient="h",
color=sns.xkcd_rgb['windows blue']
)
plt.show()
RFM应用
-
作为特征加入数据挖掘中:RFM很好的组合了用户的消费属性,常常将该得分作为一个基本特征加入模型进行训练,用以挖掘用户的其他价值
-
用于指导用户精细化运营:例如最常见的客户价值图,将rfm各分成两组最后得到8个组合。
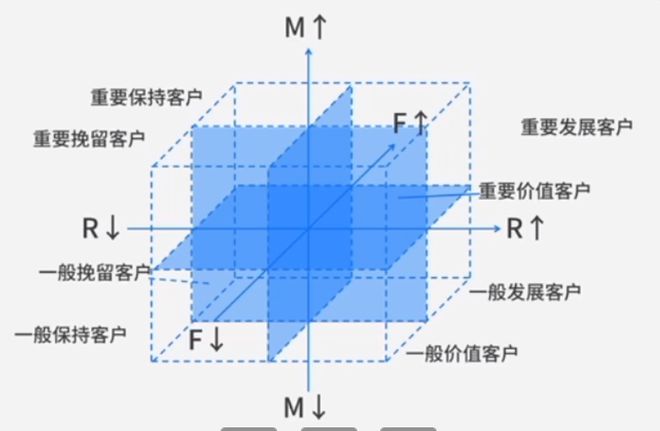
-
作为基本分群思想:RFM实质是通过用户的三个消费属性进行一定的分箱后组合,根据最终分数进行用户分群。因此我们只需要找到某个对象的三个(甚至是多个)主要特征就可以完成基于RFM的变形,例如RFA模型(以某个关键行为Action代替Money);通过最近一次评论时间+评论次数+评论字数+点赞数形成的评价分群法等等
结论
RFM是在三维上的一种特殊的分群方法,那二维、一维甚至多维是不是也有特定的方法呢。答案是肯定的,将会在接下来的几期逐步揭晓~
共勉~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









