







注意:拉到最后有视频版哦
项目地址:https://github.com/Rudrabha/Lip2Wav
论文地址:https://openaccess.thecvf.com/content_CVPR_2020/papers/Prajwal_Learning_Individual_Speaking_Styles_for_Accurate_Lip_to_Speech_Synthesis_CVPR_2020_paper.pdf
文字版
这次给大家分享一篇 CVPR2020 的做图片到语音映射的工作,单位是印度的海德巴哈研究院

我会从以下三个方面开始我的介绍

背景
首先是背景,这篇文章是开创了一个新的领域,就是直接从图像中恢复出语音,因为之前都是 TTS,他的背景就是说如果是在一个很嘈杂的环境中,我们会倾向于去读别人的唇语来理解他所说的话
动机
他的动机就是探索一下从图像中直接恢复出语音,而不是文字的方式

目标
然后他的研究目标就是假设网络会学习特定人的发音习惯,然后直接从图像中恢复语音

方法
然后讲一下他的研究方法,首先讲一下数据集,他在 YouTube 上爬取了五个人,有下象棋的、教化学的、讲课的等等,爬取了大量他们的视频,其中只有他们在发音。他这篇文章提出的是每一个人一个模型,所以他的数据集 id 数不多

然后讲一下他的网络结构,他借鉴的是 tacotron2,tacotron2 也是一个 encoder-decoder 的结构,他只把 encoder 进行了替换,因为 tacotron2 的 encoder 输入的是文字。
他这里把卷积都改成了 3D 卷积,因为他输入的是视频帧。
他这里做了一个实验,就是说明用 3D 卷积,比用 2D 卷积或者 2D+1D 的卷积效果要好,因为学习到了时间的信息(时序)
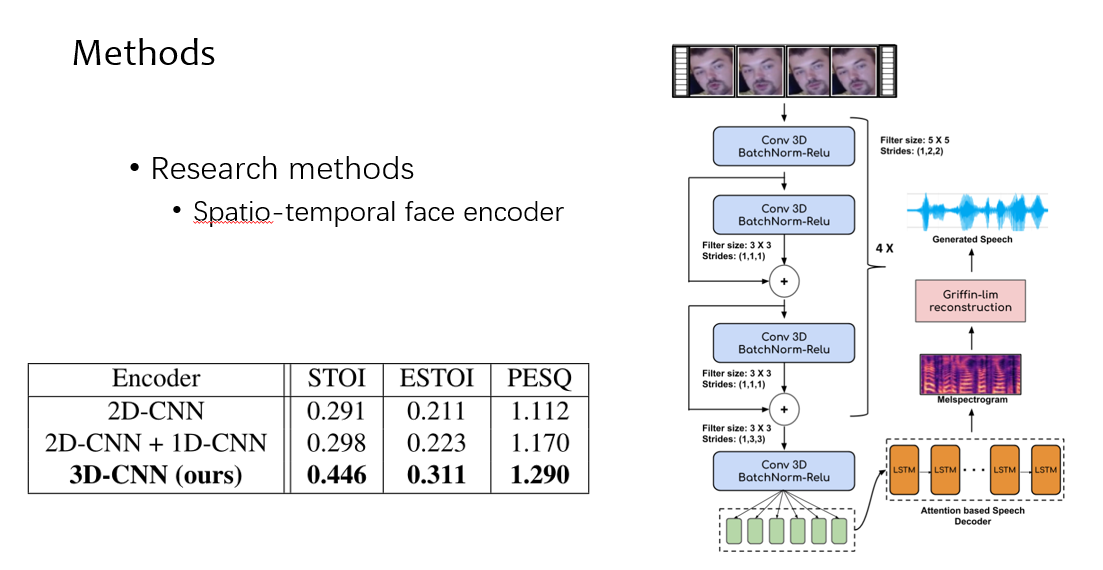
然后讲一下 decoder 的部分,他这里是直接把 tacotron 的 decoder 部分拿过来了,这里会有 attention 结构,然后有一个残差的结构,直接输出的就是这个 mel 频谱图。mel 频谱图就是一种语音的表示方法。在得到语音的 mel 频谱图后,需要通过一个声码器来恢复到我们听到的比如 mp3 的声音。文章这里运用的是 GL 算法,直接从数学角度做一个映射,当然这个部分应该可以有其他的改进
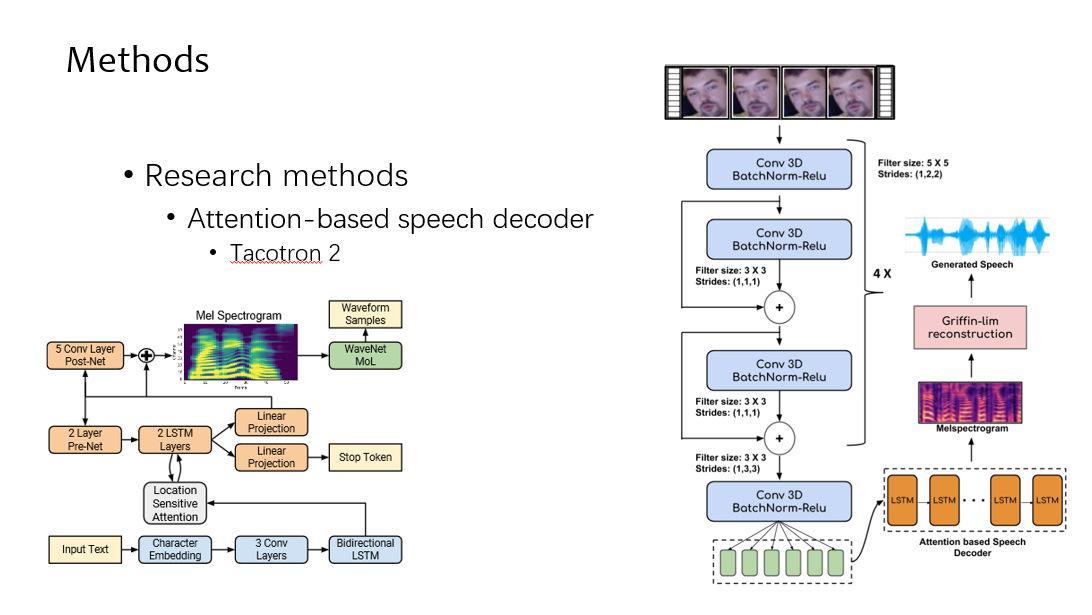
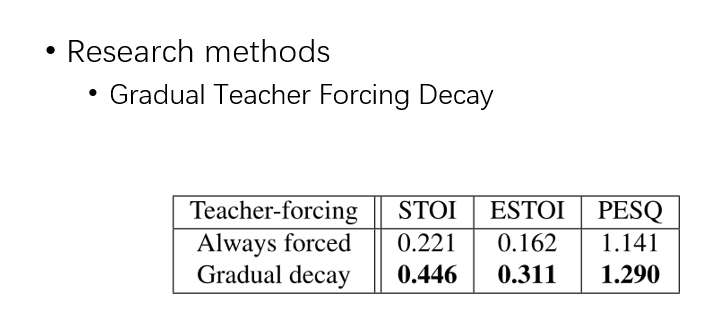
他还提出了一个小 trick,叫 teacher forcing,可以看到前面一个图,decoder 中有一个很长的 lstm。传统的 lstm 是上一层的输出作为下一层的输入,这个 decoder 中的很大,所以很难训练。这里的 teacher forcing 是什么意思呢,就是下一层的输入,是 gt,而不是上一层的输出。发现用这个策略之后呢,能够很快的收敛
这个实验说明,如果一直用 teacher forcing,后面泛化能力就会很差,所以需要梯度地减少。STOI,ESTOI,PESQ 是评判生成语音质量的标准。
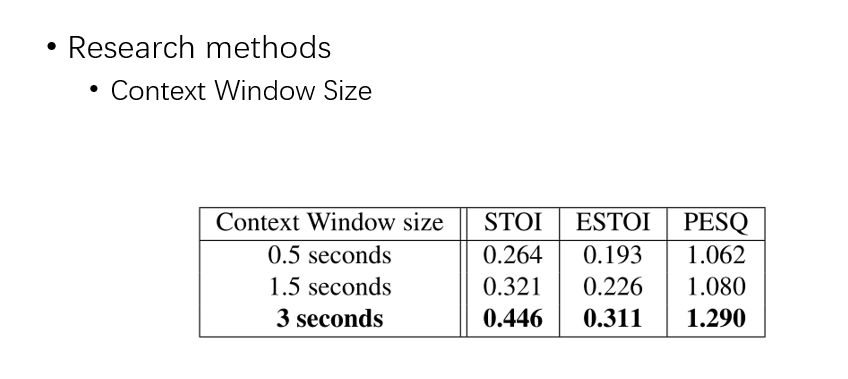
这里做了一个进去多少帧所对应的消融实验,窗口截 3s,也就是 90 帧,这个效果最好
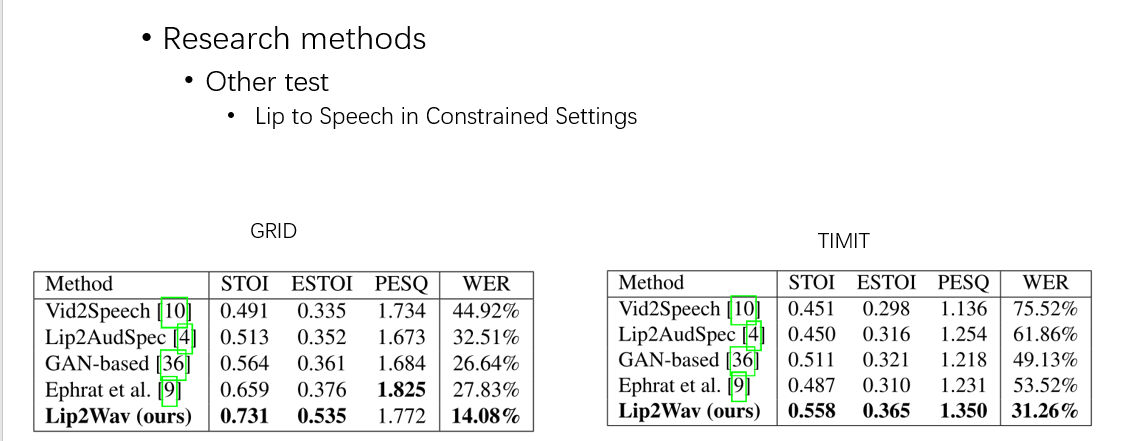
然后在 GRID 和 TIMIT 这两个集上进行了测试,可以发现本文的方法是最好的
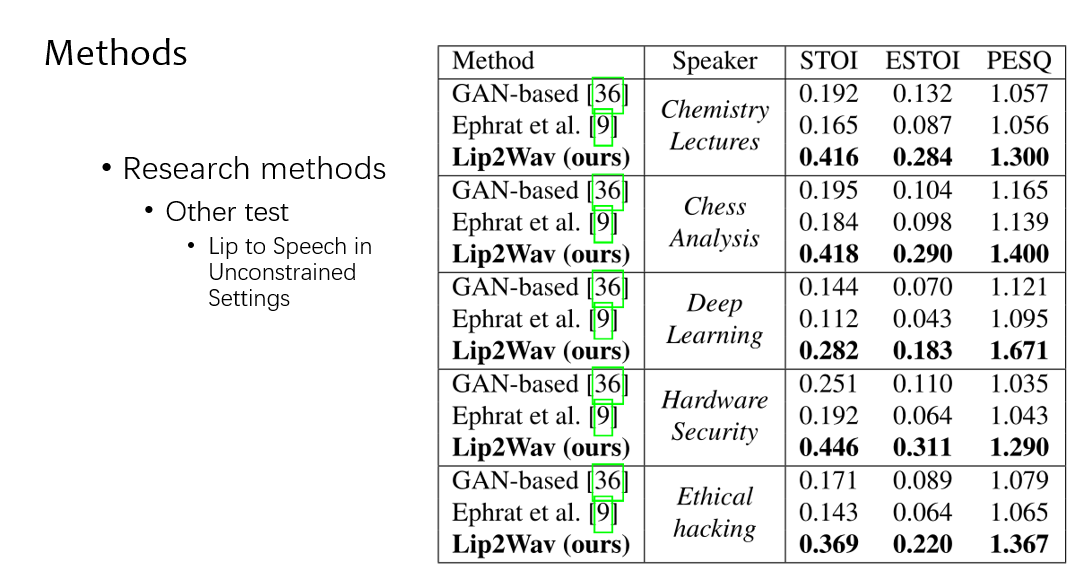
然后在他自己提的集上做的实验,他的是最优的
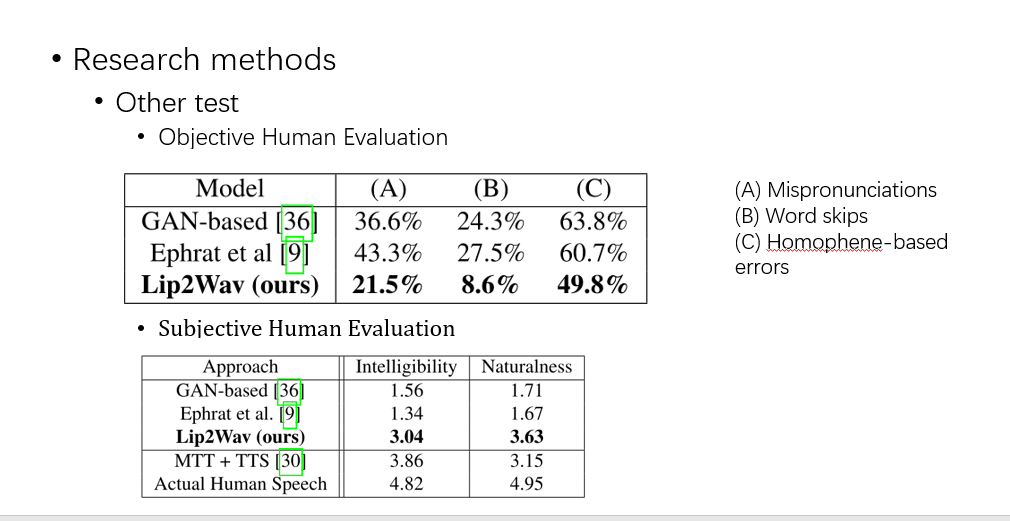
然后请了一些人来做打分,有一些客观和主观的打分
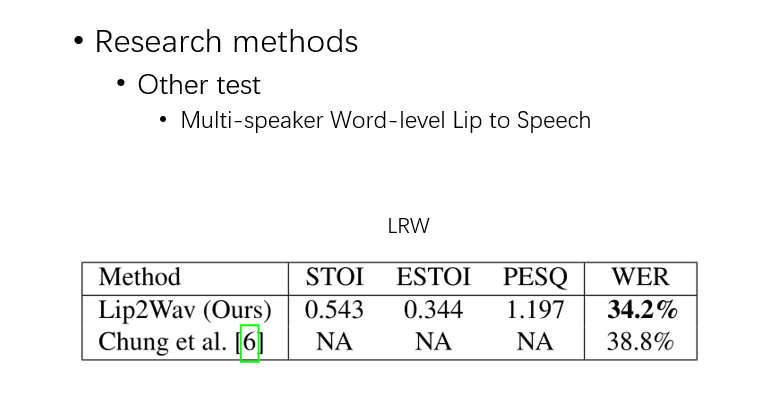
因为之前是做的一些单人的,在 LRW 上这个多人短句数据集上,效果也是最优
tacotron 中有个 attention 的结构,他把 attention 那个层可视化出来了,发现在嘴唇的部分,是有高亮的

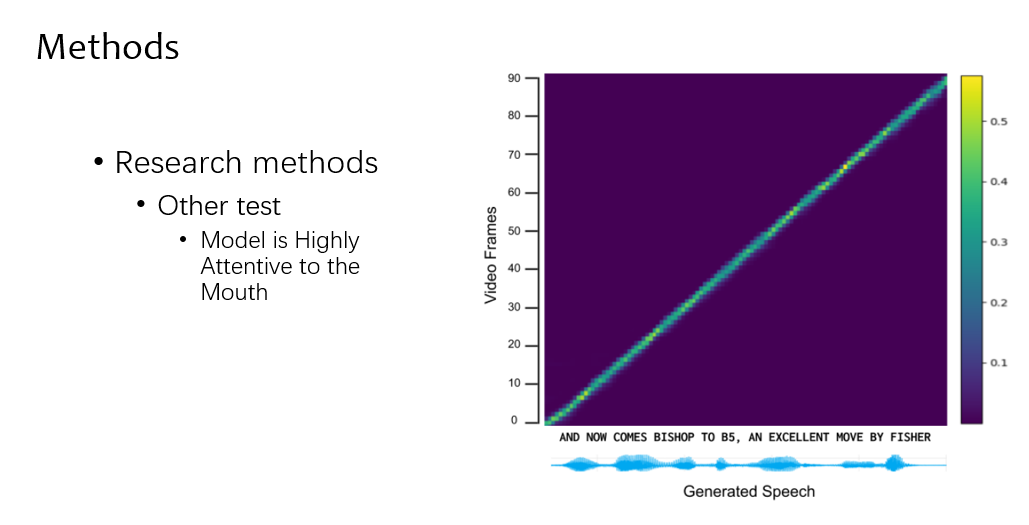
tacotron 还有个指标是 align,简单来说就是这个图越对角线越好,说明各个地方的发音是对的上的
结论
最后是研究结论,他是第一个做嘴唇的图片到语音的映射的,另外呢,他也是做了一个类似于 end2end 的结构

不足
最后的不足就是对于一些同音词的混淆

视频版
[CVPR20]Learning Individual Speaking Styles for Accurate Lip to Speech Synthesis
代码分析
[OpenBayes实现][CVPR20]Learning Individual Speaking Styles for Accurate Lip to Spe
















 640
640











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









