







注:拉到最后有视频版哦~
论文地址:https://bhaasha.iiit.ac.in/lipsync
这次给大家讲一篇做 lip generation 的文章,发表在 MM 的 2020 上

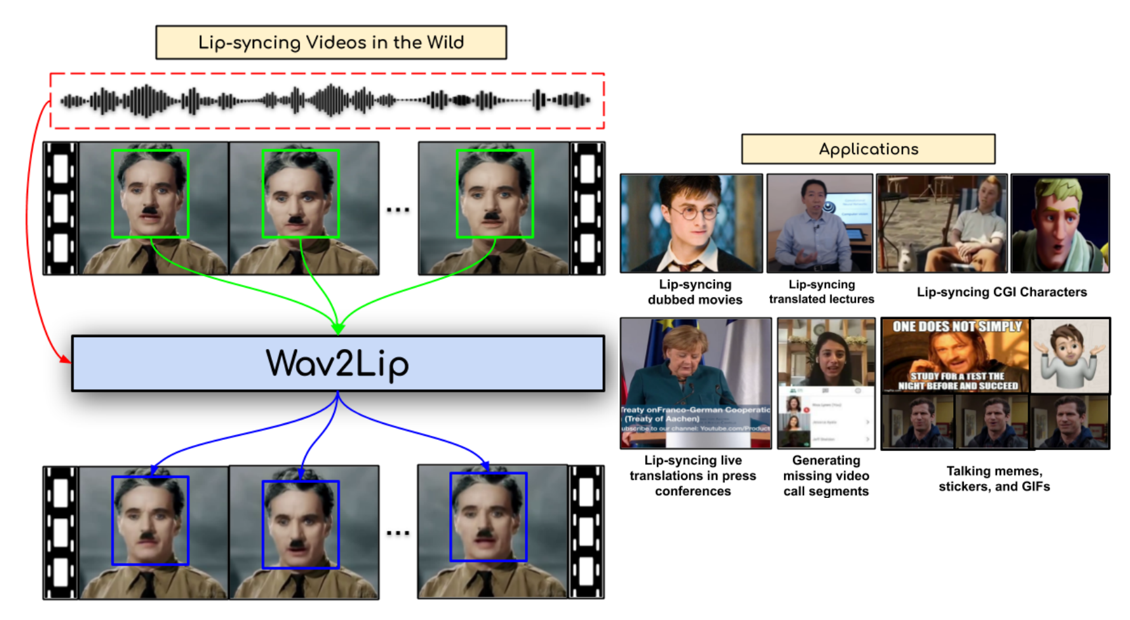
效果如图所示,大致意思就是根据语音生成对应的唇语图片,应用在配音上
大致从这五个方面来介绍这篇论文

背景
背景就是视听消费的兴起增长了快速创建视频的需求

动机
动机是现在的方法在没见过的场景下缺乏鲁棒性和泛化性

目标
研究目标是在不需要特定说话者信息的情况下生成真实的同步图片

方法
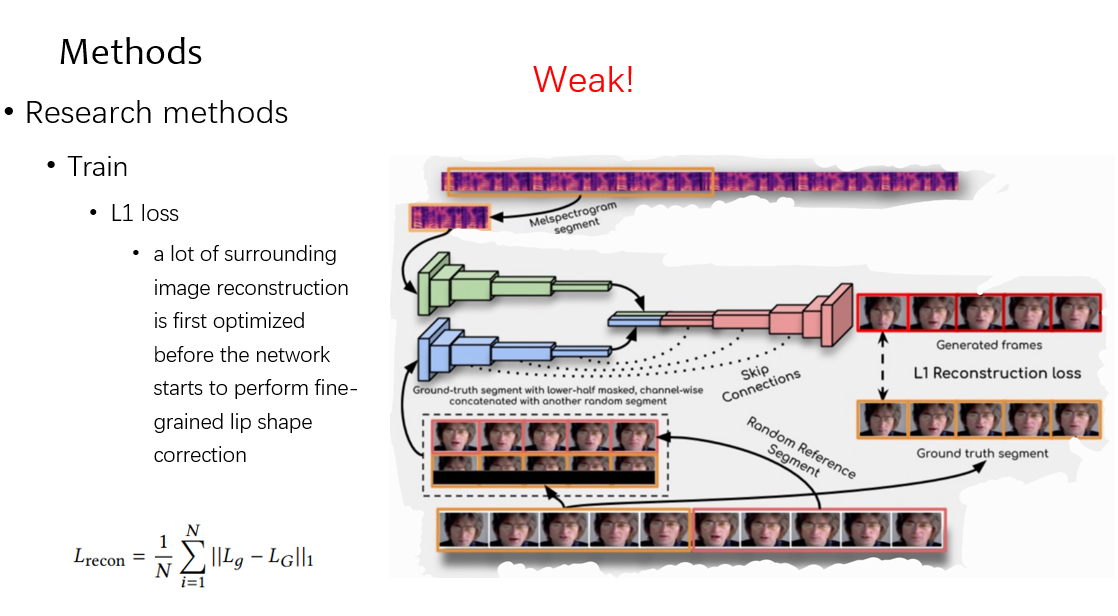
对于方法,先看下 overview,比较复杂,我们拆开来讲
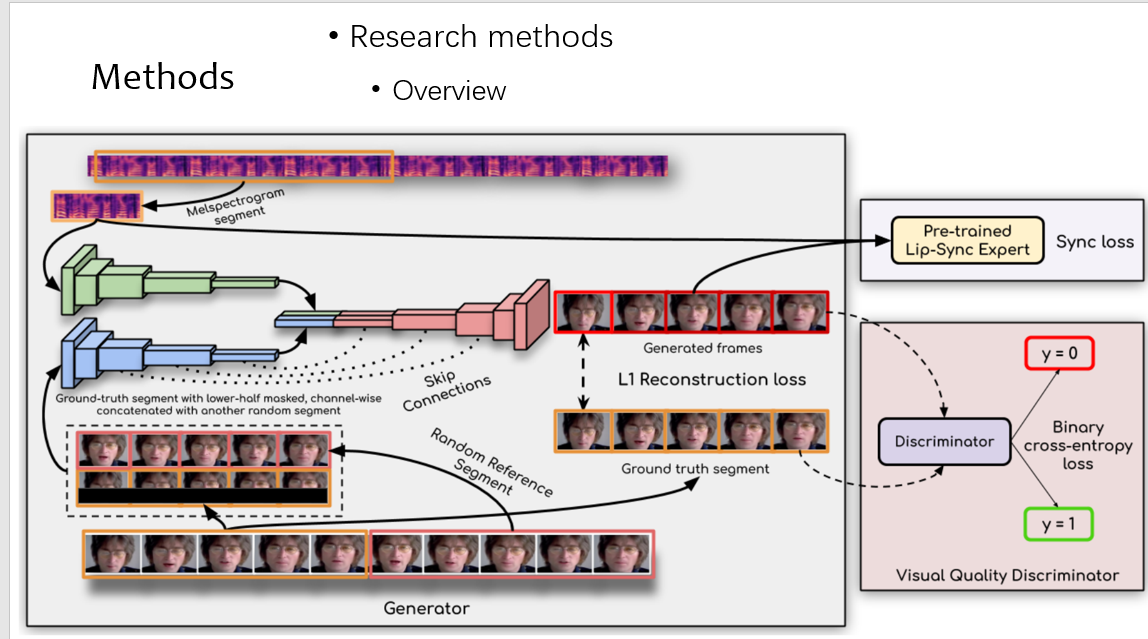
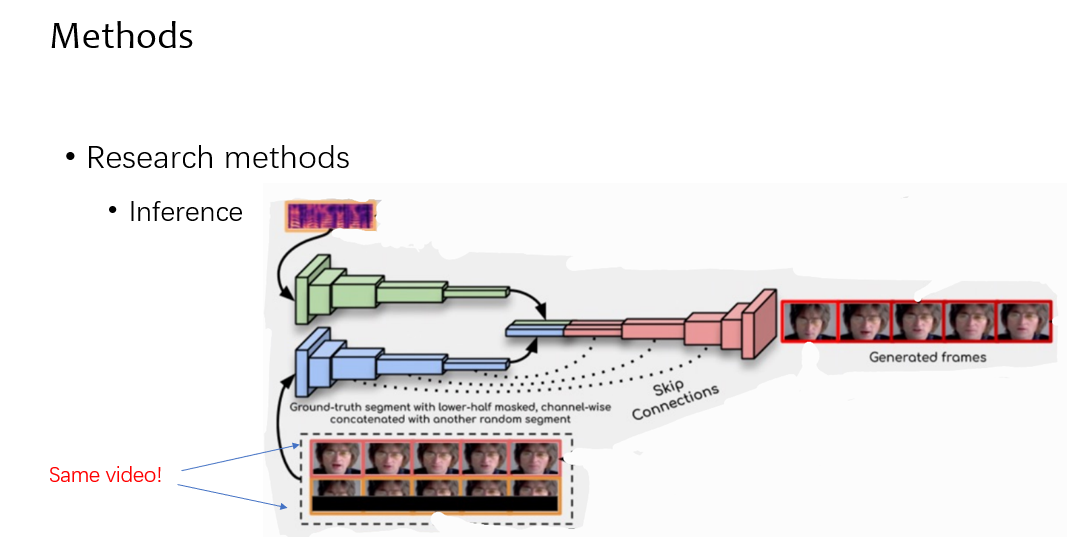
先来看推理,推理的时候,对应的 mel 频谱和 video 进入网络,其中 video 分为两个部分,上面红框代表着这个人的带时序的说话信息,也就是 reference,下面黄色的框为截掉唇部的视频帧,在推理的时候,这两个 video 是一样的
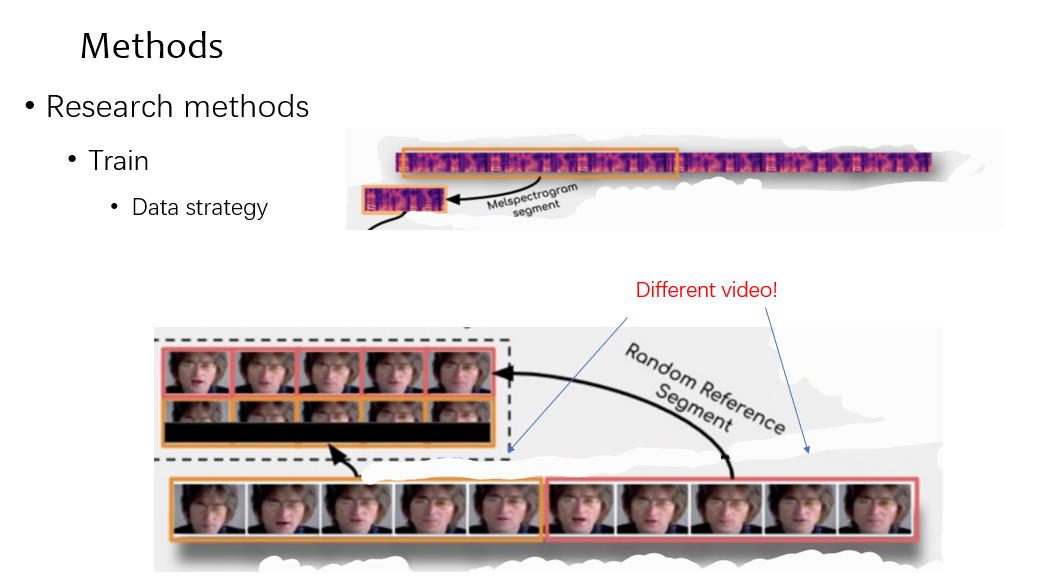
在训练的时候,先来看数据时怎么准备的,可以看到和测试不同的是,reference video 是随机选取的,为了保证泛化性
然后来看优化方案,先来看 L1 loss,因为嘴唇只占图片中的一小部分,于是网络先学习到了嘴唇周围的区域,这种约束是很弱的
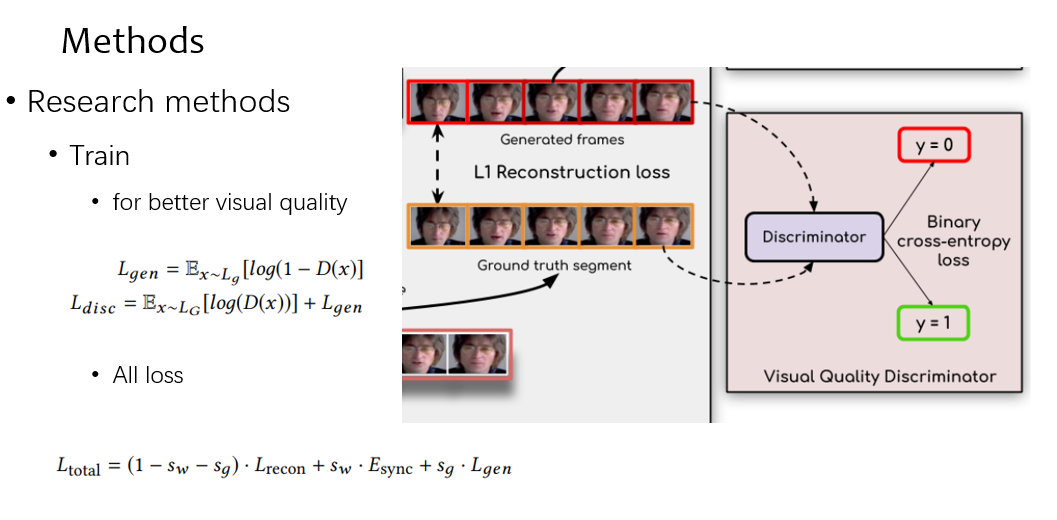
第二个是 loss 是同步的 loss,这个地方很特别,可以看到如果在训练时候不 fix 住,判别器会倾向于学习视觉的伪影,而不是同步信息,而且他只用了 single frame,如表的第一行

故为了同步的 loss,我们用 syncnet pretrain 了一个模型,算 video 和 mel 的距离,定量效果上看到是最佳

最后的 loss 就是上述两个 loss 加上一个 video 的判别 loss
实验
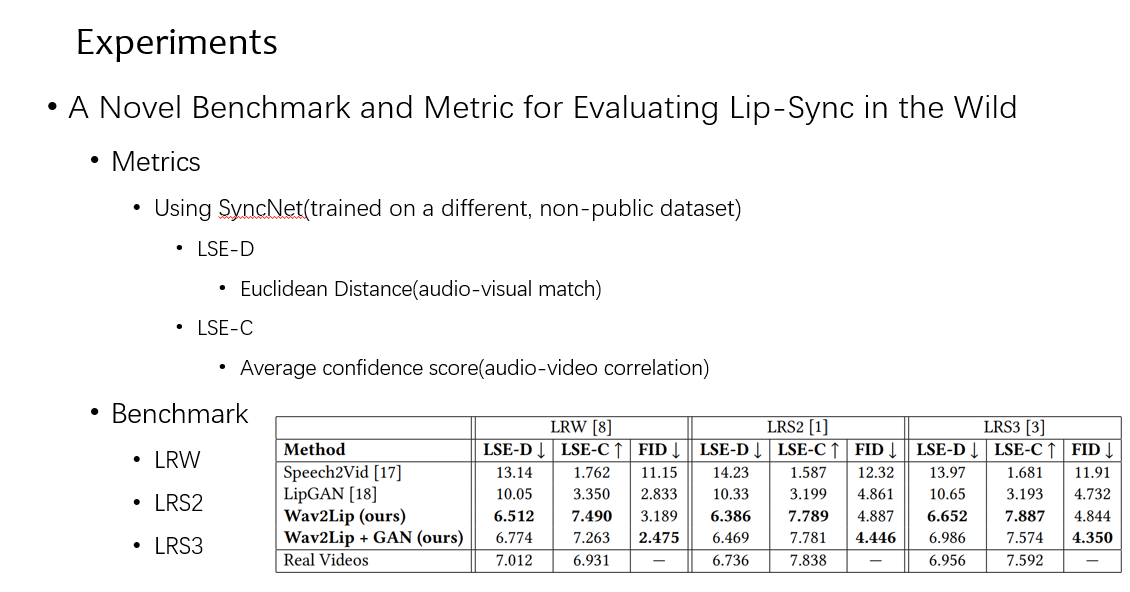
首先提出一个问题,现在的评价方案为了不失一般性,都是在 video 中选一张 frame 和生成的结果做评价,这不一致,也不能完好评价生成的质量,因为随机选的 frame 和应该生成的结果可能存在姿态等的差异

同时也因为随机切一帧出来,当前的时序没有被考虑进去,这样也导致 SSIM 和 PSNR 这些经典指标结果不准确

他提出了一个新的指标,在数据集上 pretrain 了一个同步模型,用来评价,还有两个指标,一个是 mel 和 video 在特征空间的距离,第二个是相关性。可以看到在多个数据集上,效果都很不错
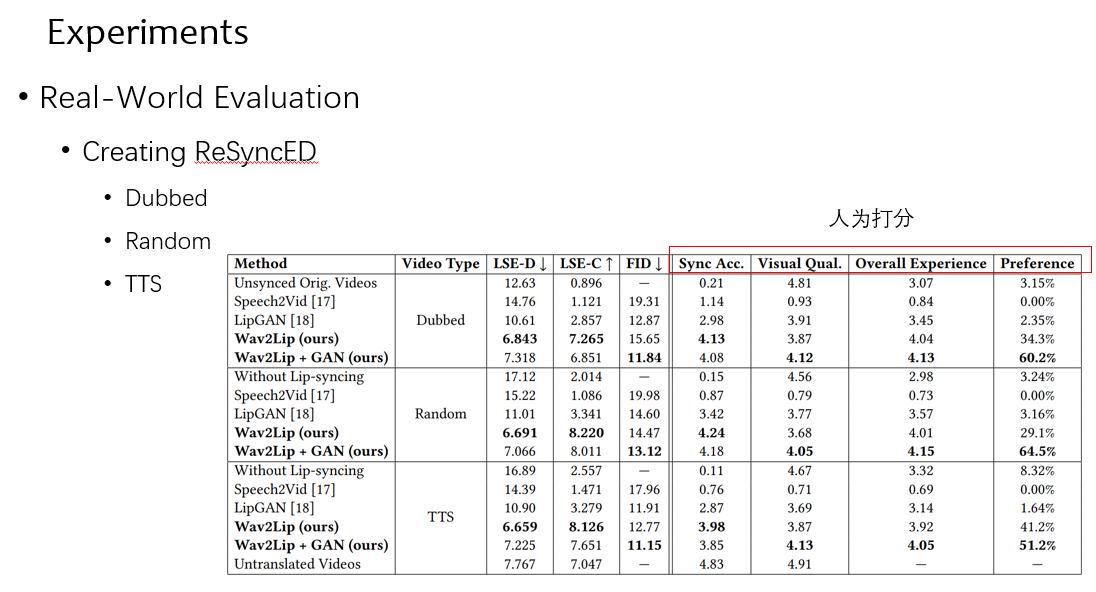
为配音,随机对和 TTS 这三个任务做 MOS,就是人为打分,可以看到效果都是不错的
结论
结论就是提出了一个生成精确的,且视听同步的视频的方法

不足
现在是一帧一帧生成的,可能不够好
同步模型是 pretrain 的,可能要想想怎么结合到进网络,且 force 他不要学伪影
视觉质量和同步质量存在 trade-off

[MM2020]A Lip Sync Expert Is All You Need for Speech to Lip Generation In The Wi

))















 8374
8374











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









