







最近正要做一个人脸识别的门禁系统,所以打算抽出一些时间来做一个系列专题,讲解下我在系统中用到的一些技术来满足一下祖传的好为人师的愿望。
既然要识别人脸,那第一步当然要检测出人脸的位置。
刚好opencv提供了一些图像处理和识别的基本方法,提供了C++、python、java的接口,我个人比较喜欢用python来编程,所以接下来在本文中都会提供用python写的代码。
说一下编程的环境需求(Requirement):
-
系统:windows / linux / macos
-
解释器:python3
-
依赖库:numpy >= 1.0、opencv-python 3、opencv-contrib-python 3(接下来的代码都是基于python3和opencv3写的,其他版本可能会不支持,需要稍作修改)
python解释器可以在python官网( https://www.python.org/ )下载安装包直接安装,这里不做赘述,下面来安装必须的依赖库,在命令行中输入:
pip3 install numpy==1.14.5
pip3 install opencv-python==3.4.1.15
pip3 install opencv-contrib-python==3.4.2.17
为了保证不出现版本不兼容问题,我把所有的库都规定了版本
关于IDE有很多选择,比较出名的有Pycharm、Spyder、Eclipse+pydev、Eric,和科学计算有关的建议用Spyder:

它提供了一个类似于MATLAB的变量显示菜单,可以清楚地看到创建的每一个变量的类型、数值、大小等,对于调试非常方便:
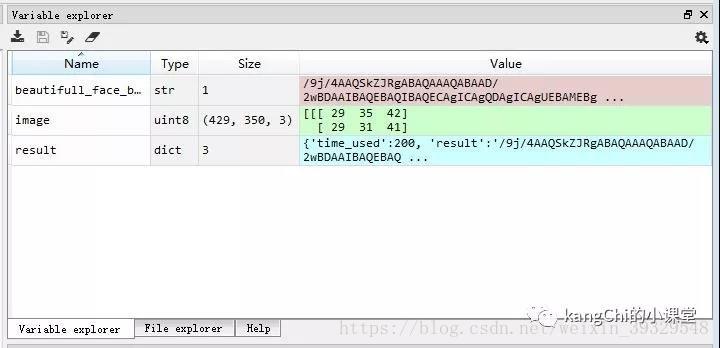
可以看到每个图片变量的矩阵原始值。
好了,基本的编程和运行环境已经搭建完了,下面开始设计代码,基本的思路是使用 Paul Viola 和 Michael Jones 的论文《Rapid Object Detection using a Boosted Cascade of Simple Features》中的算法,opencv很好的实现了这个算法,并把它封装在了级联分类器中,所以接下来写代码的步骤就变成了:加载级联分类器人脸模型 -> 打开摄像头 -> 获取图片 -> 图片灰度化 -> 人脸检测 -> 画出矩形框 -> 图像显示 。
这里用的是Haar特征来描述人脸,它反映了图像的灰度变化情况。
下面开始撰写代码:
1. 引入opencv模块
import cv2 2. 加载级联分类器模型:
faceCascade = cv2.CascadeClassifier("haarcascade_frontalface_default.xml")在opencv的‘\sources\data\haarcascades’目录下可以找到这个官方训练好的普适性模型,效果还过得去,如果想要更加的准确或者识别其他物体,可以自己用正负样本去训练(记得把模型放在和代码相同的目录下)
3. 打开摄像头
cap = cv2.VideoCapture(0) 4. 获取图片
ret, image = cap.read()5. 图像灰度化(降低运算强度)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) 6. 人脸检测
faces = faceCascade.detectMultiScale(gray, scaleFactor=1.2, minNeighbors=5, minSize=(30, 30),) detectMultiScale函数的第一个参数是灰度图像。
第二个参数是scaleFactor,不同人距离镜头不一样,有的脸比较大,有的小,scaleFactor用来对此进行补偿。
分类器使用滑动窗口来检测物体, minSize是每个窗口的大小,minNeighbors会定义其周围有多少物体。
detectMultiScale返回了一个numpy array:faces,检测出几个人脸列表的长度即为多少,faces中每一行中的元素分别表示检出的人脸在图中的(坐标x、坐标y、宽度、高度)
7. 在原先的彩图上画出包围框(绿色框,边框宽度为2)
for (x, y, width, height) in faces:
cv2.rectangle(image, (x, y), (x + width, y + height), (0, 255, 0), 2) 8. 显示图片
cv2.imshow("Face",image)
cv2.waitKey(0)
看,它很完美的检测出了我的脸在图片中的位置:

再来个大合照:
需要把从摄像头获取数据改为从图片读取数据:
image = cv2.imread(image_path) 
Look, 并没有出现种族歧视的现象。
当然有时候也会出现一些误识别和漏识别的情况:

这个时候如果期望达到更好的识别效果,可能需要去自己训练模型(https://coding-robin.de/2013/07/22/train-your-own-opencv-haar-classifier.html)或者做一些图片的预处理使图片更容易识别、调节detectMultiScal函数中的各个参数来达到期望的效果。
Warning:由于级联分类器使用的是机器学习算法,所以不能期望它达到100%的正确率,但是大多数情况下是可以达到一个不错的效果。
当然,这个级联分类器并不是只可以检测人脸,加载不同的模型,就可以检测不同的物体, 比如说喵脸:

今天就先到这里,下次再详细讲解对检测到的人脸进行人脸识别,并在图上贴上姓名标签,也就是对人脸进行分类。















 3644
3644











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









