






背景音乐:借我 - 谢春花
今天学习学得头大,放松之余,水一篇文章好了——
用python爬虫豆瓣电影TOP100的简易信息
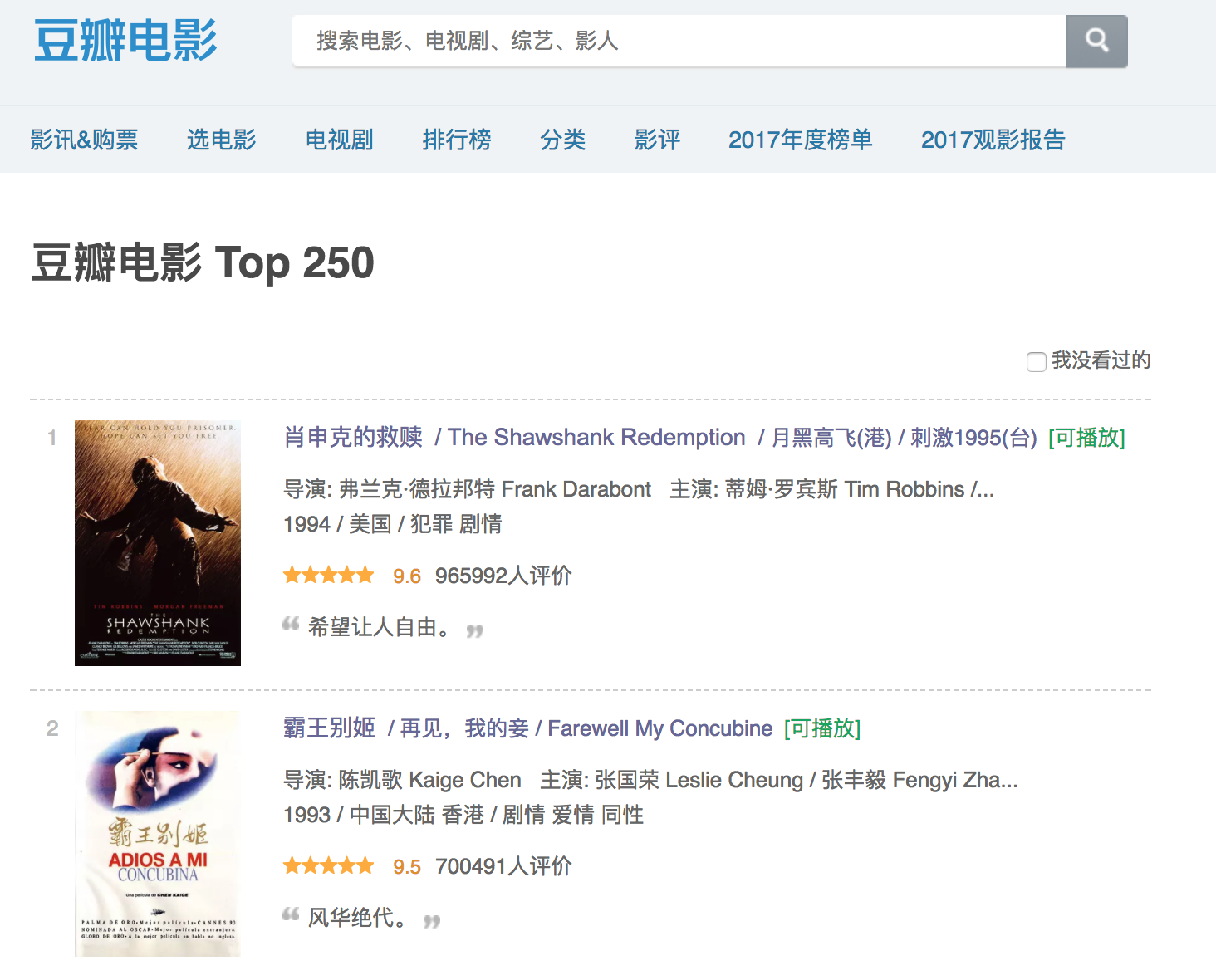
要收集的信息包括:每部电影的标题、导演、上映年份、评分以及引用。
环境:python 2.7
系统:macOS 10.13.1
模块:BeautifulSoup、requests、pandas
过程很简单,分析一下网页结构,然后用BeautifulSoup分分钟写好呀:
from BeautifulSoup import BeautifulSoup
import requests
import pandas as pd
movies = []
N = 1
for i in range(4): # 每页25部电影,共需搜索4页
page = requests.get('https://movie.douban.com/top250?start={}&filter='.format(i))
soup = BeautifulSoup(page.text) # 用BeautifulSoup对html源码进行处理
info_list = soup.findAll('ol')[0].findAll('li') # 观察可知电影信息在第1个<ol>标签的各个<li>标签里
for info in info_list:
movie = {
'ranking':str(N),
'title':info.find('span', attrs={'class':'title'}).text, # title在class为"title"的<span>标签里
'rating_num':info.find('span', attrs={'class':'rating_num'}).text, # 如上
'quote':info.find('span', attrs={'class':'inq'}).text, # 如上
'director':str(info.find('p')).split('导演: ')[1].split(' ')[0], # 导演信息在字符串中,需要特殊提取
'year':str(info.find('p')).split('<br />')[-1].strip().split('&')[0] # 同上
}
movies.append(movie)
N += 1
df = pd.DataFrame(movies)[['ranking', 'title', 'rating_num', 'year', 'director', 'quote']] # 指定DataFrame的列的顺序
df.to_csv('douban_movie.csv', encoding='utf-8', index=False)
最后输出到douban_movie.csv里,打开后是这样的~
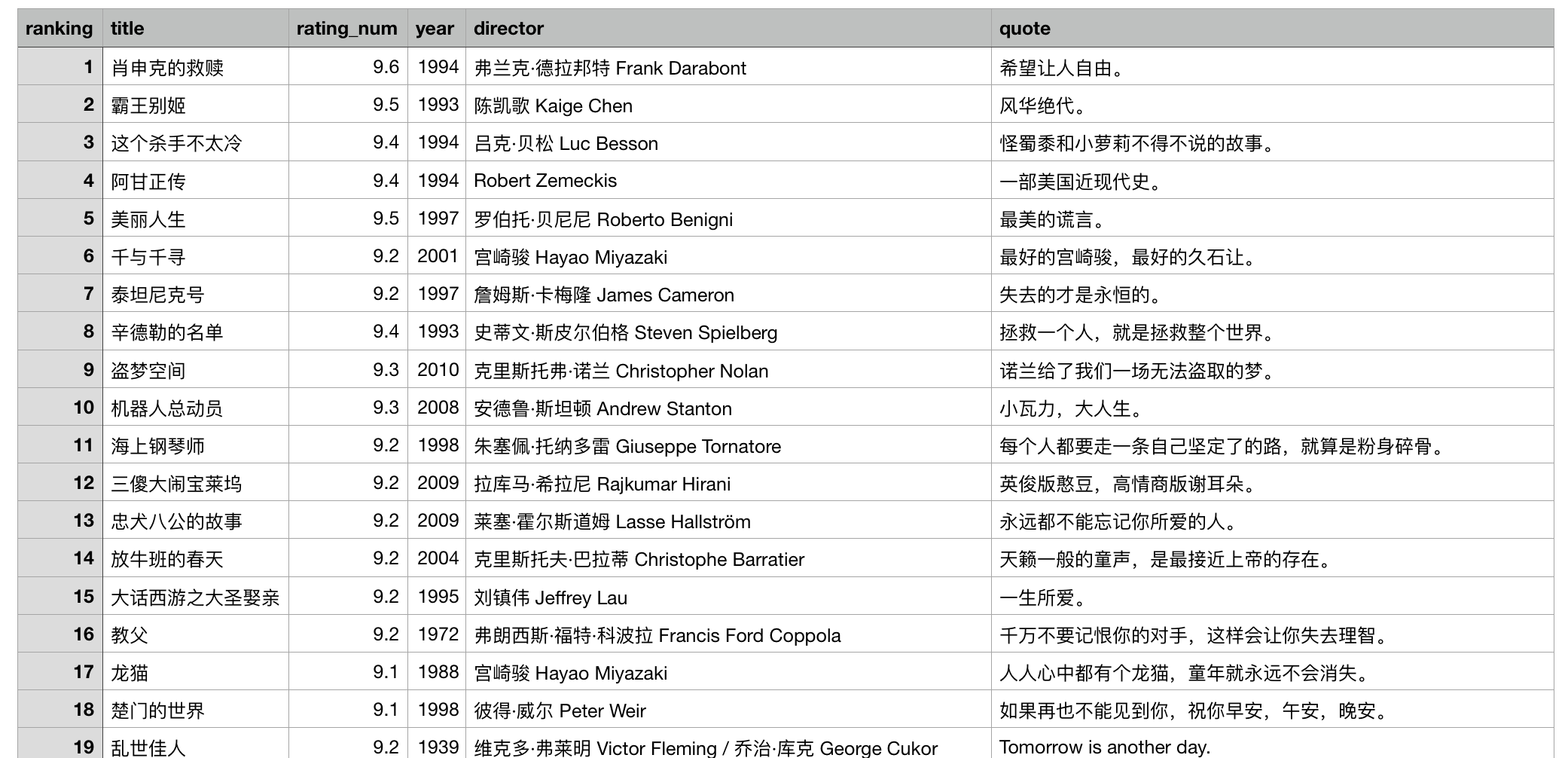
今天先做个代码的储备,以后如果要收集影评做一些情感分析的话,就方便一些了。
如果想收集电影更多的信息,比如说影评之类的,那么就要在创建movie字典之前,从info里提取电影页的url并用request获得html源码,再提取一下就好啦。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









