







句向量SDK【支持中文】
使用场景主要是中文,少量英文的情况。
-
模型通过千万级 (2200w+) 的中文句对数据集进行训练
-
模型支持中英双语的同质文本相似度计算,异质文本检索等功能
-
模型是文本嵌入模型,可以将自然语言转换成稠密的向量
-
句向量
SDK功能:
- 句向量提取
- 相似度(余弦)计算
句向量应用:
- 语义搜索,通过句向量相似性,检索语料库中与query最匹配的文本
- 文本聚类,文本转为定长向量,通过聚类模型可无监督聚集相似文本
- 文本分类,表示成句向量,直接用简单分类器即训练文本分类器
模型比对:
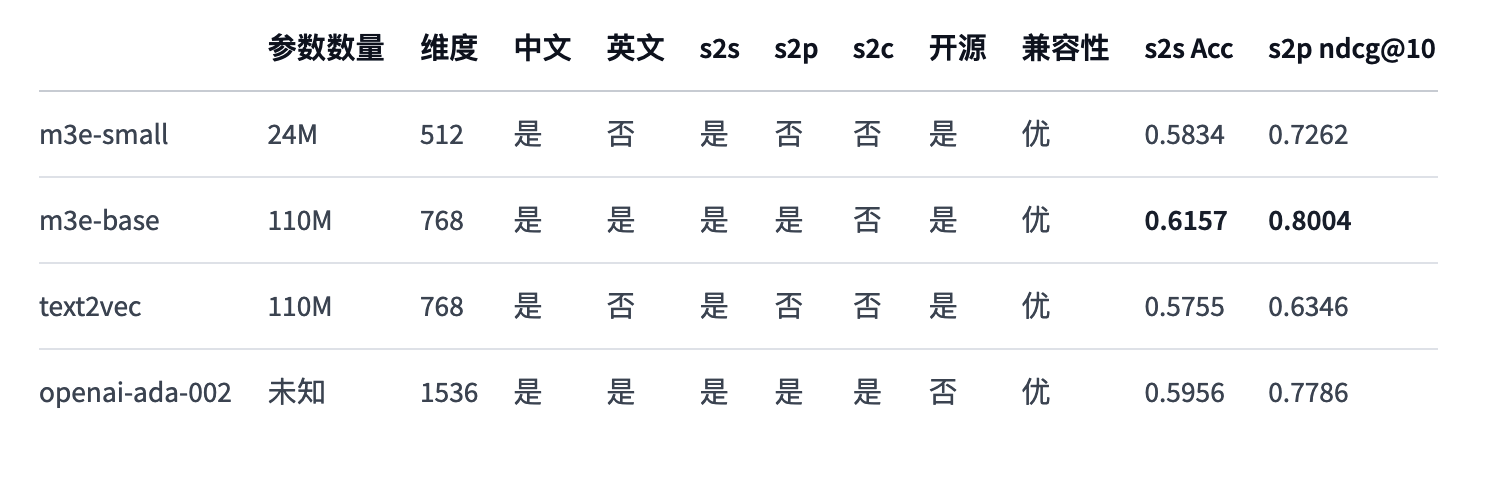
- 说明:
- s2s, 即 sentence to sentence ,代表了同质文本之间的嵌入能力,适用任务:文本相似度,重复问题检测,文本分类等
- s2p, 即 sentence to passage ,代表了异质文本之间的嵌入能力,适用任务:文本检索,GPT 记忆模块等
运行例子 - SentenceEncoderExample
运行成功后,命令行应该看到下面的信息:
...
# 测试语句:
[INFO ] - input Sentence1: 今天天气不错
[INFO ] - input Sentence2: 今天风和日丽
# 向量维度:
[INFO ] - Vector dimensions: 768
# 中文 - 生成向量:
[INFO ] - Sentence1 embeddings: [0.38705915, 0.47916633, ..., -0.38182813, -0.3867086]
[INFO ] - Sentence2 embeddings: [0.504677, 0.52846897, ..., -0.36328274, -0.62557095]
#计算中文相似度:
[INFO ] - Chinese Similarity: 0.9068957















 3033
3033











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









