







以某数据进行研究,先将数据集分为训练集和测试集,然后用不同的邻居数对训练集合测试集的新能进行评估:
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
import matplotlib.pyplot as plt
cancer=load_breast_cancer()
X_train,X_test,y_train,y_test=train_test_split(
cancer.data,cancer.target,stratify=cancer.target,random_state=66
)
plt.rcParams['font.sans-serif']=['SimHei']
training_accuracy=[]
test_accuracy=[]
neighbors_settings=range(1,11)
for n_neighbors in neighbors_settings:
clf=KNeighborsClassifier(n_neighbors=n_neighbors)
clf.fit(X_train,y_train)
training_accuracy.append(clf.score(X_train,y_train))
test_accuracy.append(clf.score(X_test,y_test))
plt.plot(neighbors_settings,training_accuracy,label='训练集精度')
plt.plot(neighbors_settings,test_accuracy,label='泛化精度')
plt.xlabel('邻居数')
plt.ylabel('精度')
plt.legend()
plt.show()
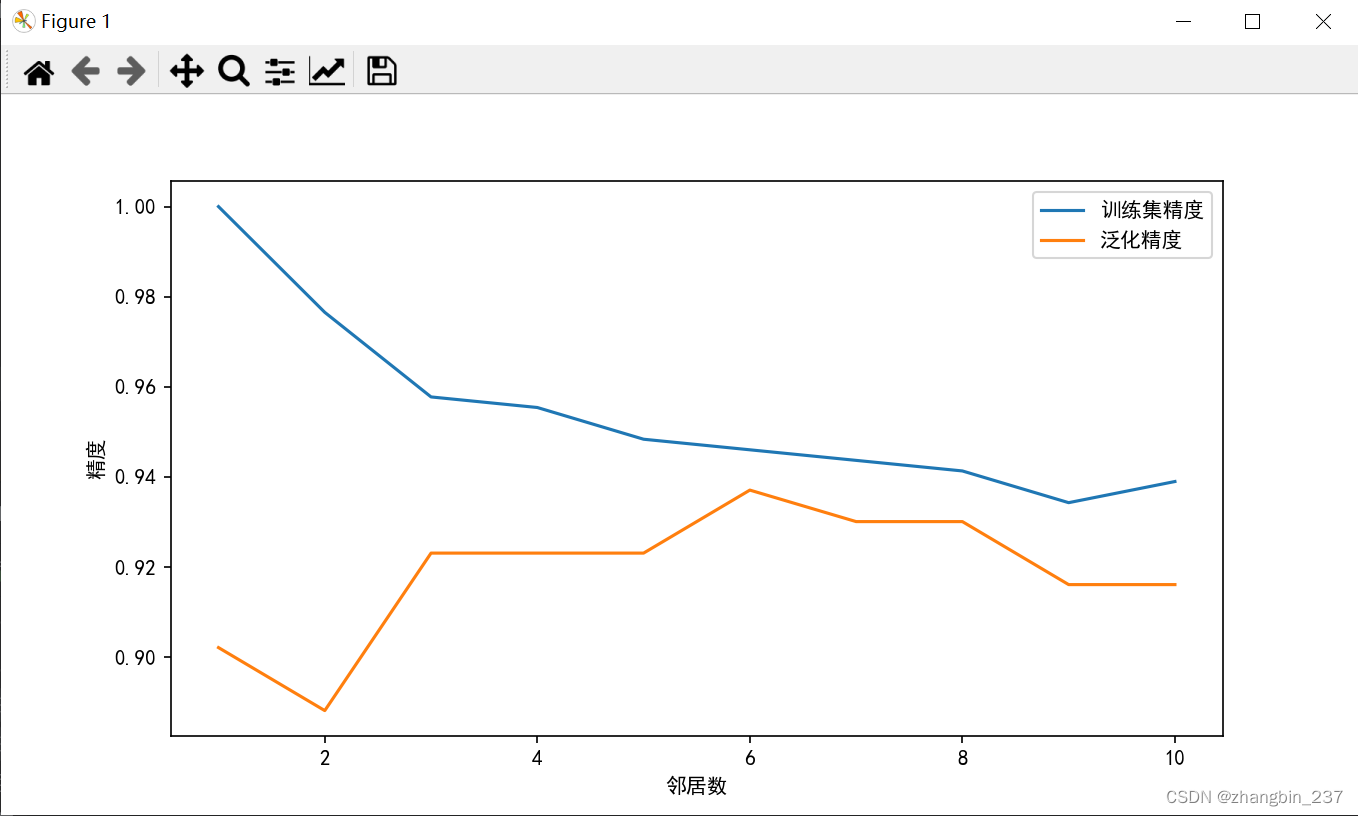
从结果上来看,进考虑单一近邻时,数据集上的预测结果非常完美,随着邻居个数的增多,模型变得简单,精度也随之下降。最佳性能在中间处,大概邻居为6个的时候。














 957
957











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









