







深度学习之Tensorflow
1.深度学习介绍
学习目标:
- 知道深度学习与机器学习的区别
- 了解深度学习的应用以及框架
1.1 深度学习与机器学习区别

(1) 特征提取方面
- 机器学习的特征工程步骤是要靠手动完成的,而且需要大量领域专业知识
- 深度学习通常由多个层组成,它们通常将更简单的模型组合在一起,通过将数据从一层传递到另一层来构建更复杂的模型。通过大量数据的训练自动得到模型,不需要人工设计特征提取环节。
深度学习算法试图从数据中学习高级功能,这是深度学习的一个非常独特的部分。因此,减少了为每个
问题开发新特征提取器的任务。适合用在难提取特征的图像、语音、自然语言领域
(2) 数据量的大小

1.需要大量的训练数据集
2.训练神经网路需要大量的算力
需要对GPU服务器进行计算
全面管理的分布式训练与预测服务--比如谷歌TensorFlow云机器学习平台,为大家提供云CPU,GPU平台
(3)算法代表
- 机器学习:朴素贝叶斯,决策树,随机森林…
- 深度学习:神经网络
(4)应用场景
- 图像识别
物体识别
场景识别
车型识别
人脸检测跟踪
人脸关键点定位
人脸身份认证 - 自然语言处理技术
机器翻译
文本识别
聊天对话 - 语音技术
语音识别
2. Tensorflow 框架
2.1 Tensorflow框架介绍
学习目标:
说明Tensorlow的数据流图结构
应用Tensorflow操作图
说明会话在Tensorflow程序中的作用
应用Tensorflow实现张量的创建,形状类型修改操作
应用Variable实现变量op的创建
应用Tensorboard图结构以及张量值的表示
应用tf.train.sever实现tensorflow的模型保存以及加载
应用tf.app.flags实现明令行参数添加和使用
应用tensorflow实现线性回归
2.2 Tensorflow数据流图
- Tensorflow是一个采用数据流图(data flow graph),用于计算的开源软件库.节点(Operation)在图中表示数学操作,图中的线(edges)则表示相互联系的多维数据数组,即张量(tensor).

2.3 Tensorflow解构分析
Tensorflow程序通常被组织成一个**构建图阶段和一个执行图阶段,**在构建图阶段,op的执行步骤,被描和述成一个图,在执行图阶段,使用会话执行图中的op.
- 图与会话:
图:这是ensorFlow将计算表示为指令之间的依赖关系的一种表示方法.
会话:TensorFlow一个或多个(本地或远程)设备运行数据流图的机制. - 张量:TensorFlow中的基本数据对象
- 形状:#0维:() 1维:(10,) 2维:(1,2) 3维:(1,2,3)
- 变化:
- 类型:tf.cast
- 形状:
- tf.reshape:会创建新的张量,不修改原来张量的形状,注意元素数量匹配
- tf.set_shape:修改张量本身的形状,固定形状不能修改,也不能跨阶数修改.
#张量demo
import tensorflow as tf
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' #关闭警告
con1, con2= tf.constant([[1, 2], [3, 4]]), tf.constant([[5, 6], [7, 8]])
sum_ = tf.add(con1, con2, name="add_1")
plt = tf.placeholder(tf.float32, [None, 4])
print(plt)
plt.set_shape([5, 4]) #set_shape静态修改形状,不能跨阶数改变形状
print(plt)
plt_reshap = tf.reshape(plt, [4, 5]) #创建新的张量,但不修改原来的张量形状,张量元素个数必须匹配
print(plt_reshap, plt)
输出结果:
/home/yuyang/anaconda3/envs/tensor1-6/bin/python3.5 "/media/yuyang/Yinux/heima/Deep learning/demo.py"
Tensor("Placeholder:0", shape=(?, 4), dtype=float32)
Tensor("Placeholder:0", shape=(5, 4), dtype=float32)
Tensor("Reshape:0", shape=(4, 5), dtype=float32) Tensor("Placeholder:0", shape=(5, 4), dtype=float32)
Process finished with exit code 0
- 节点(OP):提供图当中的运算操作
- tf下的API我们都可以称为一个OP,也称之为指令.
- OP有一个名字:在TensorFlow中全局唯一
- Tensor(“Const0”, shape=(), dtpye=float32)
- Tensor(“Const0_1:0”, shape=(), dtpye=float32)
- 通过name参数,修改指令名称,便于查看图当中OP内容.
- 图与Tensorborad:
- 一.将程序数据序列话-events文件(生成一个文件格式events.out.tfevents.{timestamp}.{hostname})
- 启动TensorBorad`````tensorard --logdir=“events路径”`
- 会话:
- 运行程序
- 需要close关闭会话,释放资源
- 会话运行的是默认的这张图,所以要运行的OP必须是这张图当中的
- 通过graph残暑去修改运行图,修改了图就要运行对应图中的OP
- run参数:
- fetches:运行多个使用列表,运行对象不能是一些非op,tensor对象,比如int,double
- feed_dict:在运行时实时提供数据,分批给数据.一般不确定数据形状时,可以结合placeholder去使用,用在训练的是后,实时提供要训练的批次数据.

代码演示:
import tensorflow as tf
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' #关闭警告
#创建一张图
g = tf.Graph()
with g.as_default():
con_g = tf.constant(4.0)
#print(con_g.graph)
#实现加法,创建一个带有张量的op
con1, con2 = tf.constant(11.0), tf.constant(12.0)
sum_ = tf.add(con1, con2, name="add_1")
#这个数据,在图当中
#None代表行不固定,此时plt中没有内容
plt = tf.placeholder(tf.float32, shape=[None, 2])
# #在指定GPU上运行
# with tf.device("GPU:0"):
# sum_ = tf.add(con1, con2, name="add_1") #运行的程序在GPU上炮
#图:打印出来就是一个内存分配的地址
#print(tf.get_default_graph())
#print(g)
#with tf.Session(graph=g) as sess: #汇话运行的是默认的图,所以要运行的OP必须是本图当中的
#通过graph参数去修改运行图,修改了图就要运行图中的OP
with tf.Session(config=tf.ConfigProto(allow_soft_placement= True,
log_device_placement=True)) as sess:
#在会话当中序列化图到events文件
file_writer = tf.summary.FileWriter("./temp/summary/", graph=sess.graph)
print(sess.run([con1, con2, sum_]))
# 看后台tensorard --logdir="/media/yuyang/Yinux/heima/Deep learning/temp/summary"
#feed_dict在运行时实时提供数据,分批给数据.一般不确定数据形状时,可以结合placeholder去使用
#本例中,填给plt提供3行2列的数据.
print(sess.run(plt, feed_dict={plt: [[1, 2], [3, 4], [5, 6]]}))
#print(con1.graph)
输出结果:
/home/yuyang/anaconda3/envs/tensor1-6/bin/python3.5 "/media/yuyang/Yinux/heima/Deep learning/basic_knowledge1.py"
Device mapping:
/job:localhost/replica:0/task:0/device:GPU:0 -> device: 0, name: GeForce GTX 1080 Ti, pci bus id: 0000:01:00.0, compute capability: 6.1
add_1: (Add): /job:localhost/replica:0/task:0/device:GPU:0
Const: (Const): /job:localhost/replica:0/task:0/device:GPU:0
Const_1: (Const): /job:localhost/replica:0/task:0/device:GPU:0
Placeholder: (Placeholder): /job:localhost/replica:0/task:0/device:GPU:0
[11.0, 12.0, 23.0]
[[1. 2.]
[3. 4.]
[5. 6.]]
Process finished with exit code 0
在交互式界面中使用TensoFlow,
In [1]: import tensorflow as tf
In [2]: tf.InteractiveSession()
Out[2]: <tensorflow.python.client.session.InteractiveSession at 0x7f43703487f0>
In [3]: tf.zeros([3,4],dtype=tf.float32).eval()
Out[3]:
array([[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]], dtype=float32)
In [4]: tf.cast(tf.zeros([3,4],dtype=tf.float32),tf.int32).eval()
Out[4]:
array([[0, 0, 0, 0],
[0, 0, 0, 0],
[0, 0, 0, 0]], dtype=int32)
- 变量OP:
- tensorflow变量表示程序处理的共享持久状态的最佳方法。
- 变量通过tf.Variable OP类以及tf.get_variable()类进行操作。
- 变量的特点:
- 存储持久化;可修改值; 可指定被训练.
- 命名空间与共享变量:
- tf.variable_scope去创建,会在op的名字前继续加上空间的名字
- tf.get_variable:如果一个命名空间中存在名字一样的,那么会报冲突错误,怎么解决?
- with tf.variable_scope(“my_scope1”) as scope : scope.resue_variables()
- with tf.variable_scope(“my_scope1”, reuse=tf.AUTO_REUSE):
- var2 = tf.get_variable(initializer=tf.random_normal([2, 3], mean=0.0, stddev=1.0) name=“var2”)
- Tensorflow:维护一个所有OP名字的列表,不是以取的名字(自定义python变量)去区分.
代码演示:
import tensorflow as tf
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # 关闭警告
# 特殊的创建张量OP,变量OP
# 必须手动初始化,否则print(var)会出错,与tf.constant不同
var = tf.Variable(tf.random_normal([2, 3], mean=0.0, stddev=1.0), name="var")
# tf.global_variables_initializer() 显示初始化,也可以写在后面
new_var = var.assign([[1, 2, 3], [4, 5, 6]]) # 通过assign修改原来的变量OP
# print(new_var)
#在var变量对应位置上加上新的值
new_var_1 = var.assign_add([[1, 2, 3], [4, 5, 6]])
# 命名空间与共享变量(全局变量) name全局唯一
with tf.variable_scope("my_scope"):
con1, con2 = tf.constant(11.0, name="con1"), tf.constant(12.0, name="con2")
sum_1 = tf.add(con1, con2, name="add_2")
# var = tf.Variable(name="var", initial_value=[4], dtype=tf.float32)
# var_double = tf.Variable(name="var", initial_value=[4], dtype=tf.float32)
with tf.variable_scope("my_scope1", reuse=tf.AUTO_REUSE):
var = tf.Variable(tf.random_normal([2, 3], mean=0.0, stddev=1.0),
name="var1")
var_double = tf.Variable(tf.random_normal([2, 3], mean=0.0, stddev=1.0),
name="var1")
# 使用get_variable 如果一个命名空间存在名字一样的,那么会报冲突,采用reuse方法解决,注意initializer
var2 = tf.get_variable(initializer=tf.random_normal([2, 3], mean=0.0, stddev=1.0),
name="var2")
var2_double = tf.get_variable(initializer=tf.random_normal([2, 3], mean=0.0, stddev=1.0),
name="var2")
with tf.Session() as sess:
sess.run(tf.global_variables_initializer()) # 显式初始化
# 看后台tensorboard --logdir="./temp/summary"
file_writer = tf.summary.FileWriter("./temp/summary", graph=sess.graph)
print(sess.run(var))
print(sess.run(new_var))
print(sess.run(new_var_1))
print(var)
print(var_double)
print(var2)
print(var2_double)
输出结果:
/home/yuyang/anaconda3/envs/tensor1-6/bin/python3.5 "/media/yuyang/Yinux/heima/Deep learning/demo.py"
[[ 0.10190357 0.729149 -0.4308761 ]
[-0.9505443 -1.6613313 -0.40749055]]
[[1. 2. 3.]
[4. 5. 6.]]
[[ 2. 4. 6.]
[ 8. 10. 12.]]
<tf.Variable 'my_scope1/var1:0' shape=(2, 3) dtype=float32_ref>
<tf.Variable 'my_scope1/var1_1:0' shape=(2, 3) dtype=float32_ref>
<tf.Variable 'my_scope1/var2:0' shape=(2, 3) dtype=float32_ref>
<tf.Variable 'my_scope1/var2:0' shape=(2, 3) dtype=float32_ref>
Process finished with exit code 0
张量图:

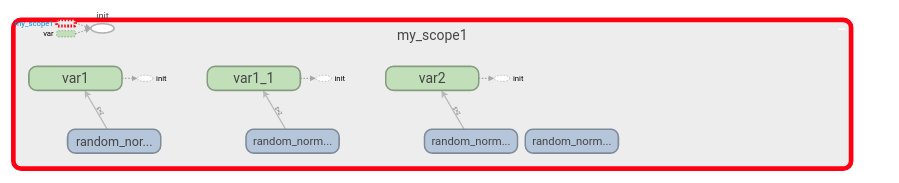
2.4 Tensorflow API简介
2.4.1 基础API
- tf.app
这个模块想当于为TensorFlow进行的脚本提供了一个main函数入口,可以定义脚本运行的flags. - tf.image
Tensorflow的图像处理操作,主要是一些颜色变换,变形和图像的编码和解码. - tf.gfile
这个模块提供了一组文件操作函数 - tf.summary
用来生成Tensorboard可用的统计日志,目前summary提供了4种类型:audio,image,histogram,sacla - tf.python_io
用来读写TFRecords文件 - tf.train
这个模块提供了一系列训练器,与tf.nn组合起来,实现一些网络的优化算法. - tf.nn
这个模块提供了一些构建神经网络的底层函数.TensorFlow构建网络的核心模块.其中包含了添加各种层的函数,比如卷基层,池化层等.
2.4.2 高级API
- tf.keras
Keras本来是一个独立的深度学习库,tensorflow将其学习过来,增加这部分模块,便于快速建立模型. - tf.layers
- 高级API,以更高级的概念层来定义一个模型,类似tf.keras
- tf.contrib
- tf.contrib.layers提供能够将计算图中的网络层,正则化,摘要操作,是构建计算图的高级操作.
- tf.estimator
- 一个estimator想当于Model + Training + Evaluate的合体,在模块中,已经实现了几种简单的分类器和回归器,包括:Baseline,Learning 和DNN.这里的DNN网路只是全连接网络,没有提供卷积.
2.5 案例-线性回归
学习目标:
- 以逻辑回归为例,熟悉整个开发流程:
2.5.1 步骤分析
特征值:x ; 目标值:y_true ;
预测值:y_predict = x1w1 + x2w2 +x3w3 +…+xnwn +b
-
步骤分析:
1.准备数据的特征值和目标值inputs
2.根据特征值建立线性回归模型(确定参数个数形状)inference
模型的参数必须使用op创建
3.根据模型得出预测结果,建立损失loss
4.梯度下降优化器优化损失 sgd_op -
1.准备数据 x, y_true
-
2.根据数据建立模型
- w:随机初始化一个权重
- b:随机初始化一个偏置
- y_predict = x*w + b
-
3.利用y_predict 和 y_true求出均方误差损失
-
4.利用梯度下降去减小模型损失,从而优化模型参数
学习率指定:0-1之间的值
2.5.2 API
API:
- 1.运算
矩阵运算 : tf.matmul(x,w); 平方:tf.square(error); 均值:tf.reduce_mean(error) - 2.梯度下降优化
tf.train.GradientDescentOptimizer(learnung_rate)
梯度下降优化; 学习率(0-1); return 梯度下降op
2.5.3 学习率、步长及梯度爆炸
学习率不应设置过大,否则导致梯度爆炸(极端情况下损失值为nan)
要想训练较好的效果:学习率越大,步长(训练的次数)要设置小一些;
学习率小,步长要设置大一些。
一般选学习率:0.01, 0.001, 0.0001模型越大,学习率要尽量小些
- 如何解决梯度爆炸;
- 重新设计网络;
- 调整学习率;
- 使用梯度截断(在训练过程中检查和限制梯度大小);
- 使用激活函数
- 模型的优化参数必须选择tf.Variable定义,并且可以用trainable参数指定是否被训练
2.5.4 其他功能
-
(1)增加命名空间:使代码结构更加清晰,Tensorboard图更加清楚
-
(2)变量Tensorboard显示; 在ensorboard中观察模型的参数、损失值等变量值的变化
- 1)收集变量
- tf.summary.scalar(name=".tensor)收集对于损失函数和准确率等单值变量,name为变量的名字,tensor为值
- tf.summary.histogram(name=".tensor) 收集高纬度的变量参数
- tf.summray.image(name=",tensor) 收集输入的图片,张量能显示图片
- 2)合并变量写入事件文件
- merged = tf.summary.merge_all()
- 运行合并:summary = sess.run(merged) 每次迭代都须运行
- 添加:FileWriter.summary(summary,i) i表示第几次的值
- 1)收集变量
-
(3)模型保存与加载;
- tf.train.Saver(var_list=None,max_to_keep=5)
- 保存:指定路径,指定会话,默认保存Variable中的OP,可以指定保存哪些
- 保存文件格式:checkpoint文件
- 加载:本地文件模型当中的一些变量名字与要进行加载训练的代码中的变量名字必须一致,代码训练
- 以本地文件模型的参数值继续训练
-
var_list:指定将要保存和还原的变量。它可以作为一个dict或一个列表传递
-
max_to_keep:只是要保留的最近检查点文件的最大数量。创建新文件时,会删除较旧的文件,如果无0,则保留所有检查点文件、默认为5(即保留最新的检查点文件)
-
例如:saver.save(sess, “./temp/model/myregression”)
saver.restore(sess, “./temp/model/myregression”)
-
- tf.train.Saver(var_list=None,max_to_keep=5)
-
(4)命令行参数设置
定义模型训练的步数- tf.app.flags.DEFINE_integer(“train_step”, 0, “训练模型的步数”)
- tf.app.flags.DEFINE_string(“model_dir”, " ", “.模型保存的路径”)
FlAGS = tf.app.flags.FLAGS
训练的步长:FLAGS.train_step
保存的路径:FLAGS.model_dir
2.5.5 代码实现
import tensorflow as tf
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # 关闭警告
# 定义模型训练的步数
tf.app.flags.DEFINE_integer("train_step", 0, "训练模型的步数")
tf.app.flags.DEFINE_string("model_dir", " ", ".模型保存的路径")
FlAGS = tf.app.flags.FLAGS
class MyLinearRegression(object):
'''
实现线性回归训练
'''
def __init__(self):
self.learning_rate = 0.01
def inputs(self):
'''
获取需要训练的数据
:return:
'''
# 构造数据x:[100, 100行1列,即100个样本,1个特征 y_true = x*0.7 + 0.8
x_data = tf.random_normal([100, 1], mean=0.0, stddev=1.0, name='x_data')
# [100, 1] * [1, 1] = [100, 1]
y_true = tf.matmul(x_data, [[0.7]]) + 0.8
return x_data, y_true
def inference(self, feature):
'''
根据数据特征值,建立线性回归模型
:param feature:
:return:
'''
# 定义一个命名空间
with tf.variable_scope("linear_model"):
# w, b
# x[100, 1] * w[1, 1] +b = y_predict
# 随机初始化权重和偏置
# 权重和偏置必须使用tf.Variable去定义,因为只有Variable才能被梯度下降所训练
# self.weight = tf.Variable(tf.random_normal(shape=[1, 1], mean=0.0, stddev=1.0),
# name="weight",trainable=False) #trainable默认为True,如果为Flase则停止训练参数
self.weight = tf.Variable(tf.random_normal(shape=[1, 1],
mean=0.0,
stddev=1.0), name="weight") # shapp[1, 1]代表2维
self.bias = tf.Variable(tf.random_normal(shape=[1],
mean=0.0,
stddev=1.0), name="bias")
# 建立预测模型
y_predict = tf.matmul(feature, self.weight) + self.bias
return y_predict
def loss(self, y_true, y_predict):
'''
根据预测值和真实值求出均方误差损失
:param y_true:
:param y_predict:
:return:
'''
# 定义一个命名空间
# sum(y_true - y_predict)^2) mean()
with tf.variable_scope("losses"):
# 求出损失
# 对列表中的数据求和之后求平均值
loss = tf.reduce_mean(tf.square(y_true - y_predict))
return loss
def sgd_op(self, loss):
'''
利用梯度下降优化器去优化损失(优化模型参数)
:param loss:
:return:
'''
# 定义一个命名空间
with tf.variable_scope("train_op"):
train_op = tf.train.GradientDescentOptimizer(self.learning_rate).minimize(loss)
return train_op
def merge_summary(self, loss, ):
# 定义收集张量的函数
# 收集对于损失函数和准确率等单值变量
tf.summary.scalar("losses", loss)
# 收集高纬度的张量值
tf.summary.histogram("w", self.weight)
tf.summary.histogram("b", self.bias)
# 合并变量(OP)
merged = tf.summary.merge_all()
return merged
def train(self):
'''
用于训练的函数
:return:
'''
# 获取默认的图
g = tf.get_default_graph()
# 在默认的图当中去操作
with g.as_default():
# 进行训练
# 1.获取数据
x_data, y_true = self.inputs()
# 2.利用模型得出预测结果
y_predict = self.inference(x_data)
# 3.计算损失
loss = self.loss(y_true, y_predict)
# 4.优化损失
train_op = self.sgd_op(loss)
# 5.收集要观察张量值
merged = self.merge_summary(loss)
# 6.定义一个保存文件的SaveOP
saver = tf.train.Saver()
# 开启会话去训练
with tf.Session() as sess:
# 初始化变量
sess.run(tf.global_variables_initializer())
# 创建events文件
file_writer = tf.summary.FileWriter("./temp/summary/", graph=sess.graph)
# 打印模型没有训练初始化的参数
print("模型没有初始化的参数权重:%f, 偏置为:%f" % (
self.weight.eval(), self.bias.eval()
))
# 加载模型,从模型当中找出与当前训练的模型代码当中(名字一样的OP操作),覆盖原来的值
ckpt = tf.train.latest_checkpoint("./temp/model/")
# 判断模型是否存在
if ckpt:
saver.restore(sess, ckpt)
# 打印模型没有训练的初始化参数
print("第一次加载模型保存的模型参数权重:%f, 偏置为:%f" % (
self.weight.eval(),
self.bias.eval()))
print("以模型中的参数继续去训练:")
# 运行
#for i in range(FlAGS.train_step):
for i in range(300):
_, summary = sess.run([train_op, merged]) # 返回是个列表
# 把收集的张量的值写入到events文件当中
file_writer.add_summary(summary, i)
print("第 %d 步,总损失变化:%f,模型优化参数权重:%f, 偏置为:%f" % (
i,
loss.eval(),
self.weight.eval(),
self.bias.eval()
))
# # 每隔100步保存一遍模型
# if i % 100 == 0:
# # 要指定路径+名字
# saver.save(sess, FlAGS.model_dir)
if __name__ == "__main__":
lr = MyLinearRegression()
lr.train()
输出结果:
模型没有初始化的参数权重:1.250911, 偏置为:-0.280832
第一次加载模型保存的模型参数权重:0.763315, 偏置为:0.002632
以模型中的参数继续去训练:
第 0 步,总损失变化:0.607149,模型优化参数权重:0.762953, 偏置为:0.018502
第 1 步,总损失变化:0.578595,模型优化参数权重:0.759503, 偏置为:0.034284
.........
第 298 步,总损失变化:0.000004,模型优化参数权重:0.700046, 偏置为:0.798109
第 299 步,总损失变化:0.000003,模型优化参数权重:0.700050, 偏置为:0.798147
Process finished with exit code 0
命令行参数使用:
通过tf.app.run()启动main(argv)参数:
1.将 for i in range(500):
改为 for i in range(FlAGS.train_step):
2.# 每隔100步保存一遍模型
if i % 50 == 0:
# 要指定路径+名字
saver.save(sess, FlAGS.model_dir)
3.在终端输入:
python demo.py --train_step=500 --model_dir="./temp/model/"
输出结果同上.
3.Tensorflow文件读取流程
3.1 文件读取流程

- (1)第一阶段将生成文件名来读取它们,并将它们排入文件名队列。
- (2)第二阶段对于文件名的队列,进行队列实例,并且对内容进行编码。
- (3)第三阶段从新入新的队列,这将是新的样本队列
注:这些造作需要启动运行这些队列操作的线程,以便我们训练循环可以将队列中的内容入队出队操作。
3.1.1第一阶段
我们称之为构造文件队列,将需要读取的文件装入到一个固定的队列当中
- tf.train.string_input_produce(string_tensor, shuffle=True)
- string_tensor:含有文件名+路径的1阶张量
- num_epochs:过几遍数据,默认无限过数据
- return 文件队列
3.1.2 第二阶段
这里需要从队列当中读取文件的内容,并且进行解码操作。关于读取内容会有一定的规则。
3.1.2.1读取文件内容
Tensorflow默认只读取一个样本,具体到文本文件读取一行、二进制文件读取到指字节数(最好一个样本)图片文件默认读取一张图片
- tf.TextLineReader:
阅读文本文件逗号分隔值(CSV)格式,默认按行读取
return 读取器实例 - tf.WholeFileReader:用于读取图片文件
tf.TFRecordReader:
读取TFRecordReader文件 - tf.FixedLengthRecordReader:二进制文件
要读取每个记录是固定数量字节的二进制文件
record_bytes:整形,指定每次读取(一个样本)的字节数
return:读取器实例
注:读取方法:read(file_queue):从队列中指定数量内容返回一个tensor元组(key文件名字,value默认的内容(一个样本))
默认只读取一个样本,需要进行批处理/使用tf.train.batch或tf.train.shuffle_batch进行多样本获取,便于训练时候
指定每批次多样本的训练。
3.1.2.2内容解码
对于读取不同的文件类型,内容需要解码操作,解码成统一的tensor格式
- tf.decode_csv:解码文本文件内容
- tf.decode_raw:解二进制文件内容
与tf.FixLengthRecordReader搭配使用,二进制读取为uint8格式 - tf.image,decode_jpeg(contents)
将JPEG编码的图像解码为unit8张量
return:unit8张量,3—D形状(height,width,channels) - tf.image,decode_png(contents)
将PNG编码的图像解码为unit8张量
return:张量类型2,3—D形状(height,width,channels)
注:解码阶段,默认所有内容都解码为tf.unit8格式,如果需要后续的类型,继续处理
3.1.3 第三阶段
在解码之后我们可以直接获取一个样本的内容了,但如果想要获取多个样本,这个时候需要结合管道的末尾进行批处理。
- tf.train.batch(tensors,batch_size,num_threads=1,capacity=32,name=None)
读取指定大小(个数)的张量- tensors:可以是包含张量的列表,批处理的内容放到列表当中
- batch_size:从队列中读取的批处理大小
- num_threads:进入队列的线程数
- capacity;整数,队列中元素的最大数量
- tf.train.shuffle_batch
3.1.4 线程操作
以上创建这些队列操作称之为tf.train.QueueRunner.每个QueueRunner都负责一个阶段,并拥有需要在线程中运行的排队操作列表.一旦图形被构建,tf.train.start_queue_runners寒暑就会要求图中的每个QueueRunner启动它的运行排队操作的线程.(这些操作需要在会话中开启)
- tf.train.start_queue_runners(sess=None, coord=None)
- 收集所有图中的队列线程,并启动线程
- sess:所在会话中
- coord:线程协调器
- return:返回所有线程
- tf.train.Coordinator()
线程协调员,实现一个简单的机制来协调一组线程的中止- request_stop():请求停止
- should_stop():询问是否结束
- join(threads=None,stop_grace_period_secs=120):回收线程
- return:线程协调员实例
3.2 CIFAR10 二进制数据读取

分析: 构造文件队列;读取二进制数据并进行解码;处理图片数据形状及数据类型,批处理返回;开启会话线程运行
3.3 TFrecords文件
应用:将CIFAR10类图片数据的TFRecords存储和读取
什么是TFRecords文件:
TFRecords是一种二进制文件,能更好的利用内存,更方便复制和移动,并且不需要单独的标签文件.
TFRecords文件包含了tf.train.Example协议内存块(protocol buffer),包含了字段(Features)
可以获取数据,将数据填入到Example协议内存块(propotol buffer), 将协议内存块序列化为一个字符串,并且通过
- tf.python_io.TFRecordWriter 写入到TFRecords文件.
- 文件格式:tfrecords
- TFRecords
3.3.2 Examples协议

3.3.1 写入文件分析:

3.3.2 读取文件分析

3.4 案例 - 读取CIFAR狗的TFRecords文件
代码:
import tensorflow as tf
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' #关闭警告
def picread(file_list):
'''
读取狗图片数据到张量
:param file_list: 路径 + 文件名的列表
:return:
'''
#构造文件队列
file_queue = tf.train.string_input_producer(file_list)
#创建一个读取实例,利用图片读取器去读取文件队列中的内容
reader = tf.WholeFileReader()
#默认一次一张图片
_, value = reader.read(file_queue) #返回key和value
print(value)
#对图像进行解码
#string-->unit8
#()-->(?,?,?)
image = tf.image.decode_jpeg(value)
print(image)
#图片的形状固定、大小处理
#把图片大小固定统一大小(算法训练要求样本的特征值数量一样)
image_resize = tf.image.resize_images(image, [200, 200])
print(image_resize)
#设置图片形状
image_resize.set_shape([200, 200, 3])
#进行批处理
#3D-->4D
image_batch = tf.train.batch([image_resize], batch_size=10, num_threads=2, capacity=10)
print(image_batch)
return image_batch
class CifarRead(object):
'''
读取CIFAR10类别的二进制文件
'''
def __init__(self):
#每个样本的图片属性
self.height = 32
self.width = 32
self.channel = 3
#bytes
self.label_bytes = 1 #1
self.image_bytes = self.height * self.width * self.channel #3072
self.all_bytes = self.label_bytes + self.image_bytes #3073
def bytes_read(self, file_list):
'''
读取二进制解码张量
:return:
'''
#1.构造文件队列
file_queue = tf.train.string_input_producer(file_list)
#2.使用tf.FixLengthRecordReader(bytes)读取
#默认必须指定读取一个样本
reader = tf.FixedLengthRecordReader(self.all_bytes)
_, value = reader.read(file_queue)
#3.解码操作
#(?,) (3073,) = lable(1,) + feature(3072)
label_image = tf.decode_raw(value, tf.uint8)
print(label_image)
#为了训练方便,一般会把特征值目标值分开处理
#使用tf.slice进行切片
label = tf.cast(tf.slice(label_image, [0], [self.label_bytes]), tf.int32)
image = tf.slice(label_image, [self.label_bytes], [self.image_bytes])
print(label, image)
#处理类型和图片的形状
#图片形状[32, 32, 3] reshape,不能用set_shape,不能设置已经固定的形状,并且跨阶数
#reshape(3072,)------[channel, height, width]
#transpose [channel, height, width]------>[height, width, channel]
depth_major = tf.reshape(image, [self.channel, self.height, self.width])
print(depth_major)
image_reshape = tf.transpose(depth_major, [1, 2, 0])
print(image_reshape)
#4.批处理
image_batch, label_batch = tf.train.batch([image_reshape, label], batch_size=10, num_threads=4, capacity=10)
return image_batch, label_batch
def write_to_tfrecords(self, image_batch, label_batch):
'''
将数据写入TFRecords文件
:param image_batch:
:param label_batch:
:return:
'''
#构造TFRecords存储器
writer = tf.python_io.TFRecordWriter("./temp/cifar.tfrecords")
#循环将每个样本构造成一个example, 然后序列化写入
for i in range(10):
#取出相应的第i个样本的特征值和目标值
#写入的是具体的张量的值,不是OP的名字
#[10, 32, 32, 3]
#[32, 32, 3]值
image = image_batch[i].eval().tostring()
#[10, 1]
#彐整型类型
label = label_batch[i].eval()[0]
#每个样本的example
example = tf.train.Example(features=tf.train.Features(feature={
"image": tf.train.Feature(bytes_list=tf.train.BytesList(value=[image])),
"label": tf.train.Feature(int64_list=tf.train.Int64List(value=[label]))
}))
#写入第i个样本的example
writer.write(example.SerializeToString())
writer.close()
return None
def read_tfrecords(self):
#1.构造文件队列
file_queue = tf.train.string_input_producer(["./temp/cifar.tfrecords"])
#2.tf.TFRecordReader 读取TFRecords数据并
# 解析example协议
reader = tf.TFRecordReader()
#默认只读取一个样本
_, value = reader.read(file_queue)
#进行解析example协议
feature = tf.parse_single_example(value, features={
"image":tf.FixedLenFeature([], tf.string),
"label":tf.FixedLenFeature([], tf.int64)
})
#3.解码操作 二进制的格式必须解码
image = tf.decode_raw(feature['image'], tf.uint8)
label = tf.cast(feature['label'], tf.int32)
#形状类型
#[32, 32, 3]----->bytes---->tf.uint8
image_reshape = tf.reshape(image, [self.height, self.width, self.channel])
#4.批处理
image_batch, label_batch = tf.train.batch([image_reshape, label], batch_size=10, num_threads=4, capacity=10)
return image_batch, label_batch
if __name__ =="__main__":
#创建文件名的 名字列表
filename = os.listdir("./data/cifar-10/")
#print(filename)
# 构造路径+文件名的列表
file_list = [os.path.join("./data/cifar-10/", file)
for file in filename if file[-2] =="_"]
#print(file_list)
cr = CifarRead()
#二进制读取
#image_batch, label_batch = cr.bytes_read(file_list)
#读取TFRecords的结果
image_batch, label_batch = cr.read_tfrecords()
with tf.Session() as sess:
#创建线程回收的协调员
coord = tf.train.Coordinator()
#需要手动开启子线程去批处理读取到队列操作
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
print(sess.run([image_batch, label_batch]))
#写入文件
#cr.write_to_tfrecords(image_batch, label_batch)
#回收线程
coord.request_stop()
coord.join(threads)
# if __name__ =="__main__":
# #创建文件名的 名字列表
# filename = os.listdir("./data/cat_vs_dog_test/")
# #print(filename)
# # 构造路径+文件名的列表
# file_list = [os.path.join("./data/cat_vs_dog_test/", file) for file in filename]
# #print(file_list)
# image_batch = picread(file_list)
#
# with tf.Session() as sess:
#
# #创建线程回收的协调员
# coord = tf.train.Coordinator()
#
# #需要手动开启子线程去批处理读取到队列操作
# threads = tf.train.start_queue_runners(sess=sess, coord=coord)
#
# print(sess.run(image_batch))
#
# #回收线程
# coord.request_stop()
# coord.join(threads)
输出结果:/home/yuyang/anaconda3/envs/tensor1-6/bin/python3.5 “/media/yuyang/Yinux/heima/Deep learning/Tansorflow 文件读写.py”
[array([[[[ 74, 50, 61],
[ 72, 51, 64],
[ 79, 55, 61],
…,
[111, 179, 186],
[ 89, 198, 204],
[ 82, 173, 176]]]], dtype=uint8), array([222, 113, 252, 205, 154, 154, 137, 34, 76, 142], dtype=int32)]
Process finished with exit code 0
`` `
3.5 总结
图片的张量表示:
灰度图,彩色图
高,宽(单通道,三通道)
3D[height, width, channel]
4D[batch,height, width, channel]
读取步骤
构造图片文件队列
读取图片数据并进行解码tf.WholeFileReader() read
处理图片数据形状,批处理返回tf.image.resize_images, set_shape
形状必须固定之后才能进行,tf.train.batch
打印内容,运行:需要开启子线程运行,子线程去把数据读取到队列,主线程取出数据去训练
数据类型:运算的时候:需要float32类型 读取出来解码的类型:unit8格式
二进制数据结构的读取(指定bytes:一个样本的)
构造二进制文件队列
读取二进制数据并进行文件解码:tf.FixedLengthRecordReader(self.all_bytes);tf.decode_raw(value, tf.uint8)
分割目标和特征值:tf.slice
形状类型改变:tf.cast
reshape(3072,)------[channel, height, width] (3072,)--->(1024R,1024G,1024B)
transpose [channel, height, width]------>[height, width, channel]
批处理:
TFrecords文件特点
1.它能更好的利用内存,更方便复制和移动,并且不需要单独的标签.
2.方便存储更多的图片信息,特征值,目标值,通道等等,不需要更多去处理读取出来的结果
3.存储
tf.python_io.TFRecordWriter("./temp/cifar.tfrecords")
循环数据构造Example协议内存块(protocol buffer)序列化之后写入到文件
构造example:tf.train.Int64List(value=[Value]);
tf.train.BytesList(value=[Bytes]);
tf.train.FloatList(value=[Value]);
4.读取
在读取出内容之后,需要增加一个解析example协议的步骤
feature = tf.parse_single_example(value, features={
"image":tf.FixedLenFeature([], tf.string),
"label":tf.FixedLenFeature([], tf.int64)
})`















 2843
2843











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









