






背景:
1.opencc项目可以把汉字在中国大陆、香港、台湾三种模式下互相转换,对于专用词汇和地区惯用字的转换做的相当不错,而且已经是 Linux 下非常通用的库。
2. OpenResty 可以做到许多事情,因为它内置了一个 LuaJIT,可以使用 Lua 这个脚本语言来自定义处理逻辑。
在linux(centos7)搭建 OpenResty+OpenCC
网上安装Openresty的方式很多,可自行搜索
因为opencc通过源码编译过于复杂,需要安装很多的编译环境(起码我没编译成功),因而https://hub.docker.com/r/rexskz/openresty-opencc-docker通过这个镜像中获取编译好的opencc函数库 ,如下图,只需要在镜像的/usr/lib64目录下获取以下这三个库文件即可:
也可以通过https://pan.baidu.com/s/1ROfvcR23XWpAfLKdGM4-_Q 可以通过在这个获取,提取码:gtzp
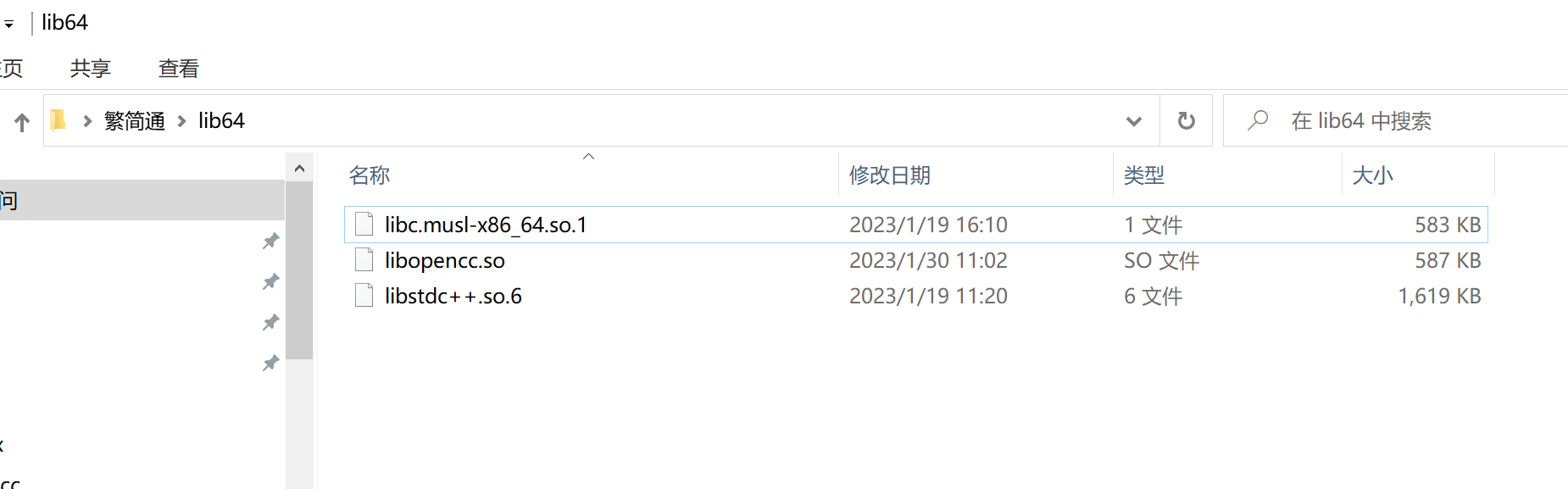
将上述三个文件放置服务器/usr/lib64文件夹下。
在上述镜像的/usr/share目录下获取opencc文件夹的词库信息:
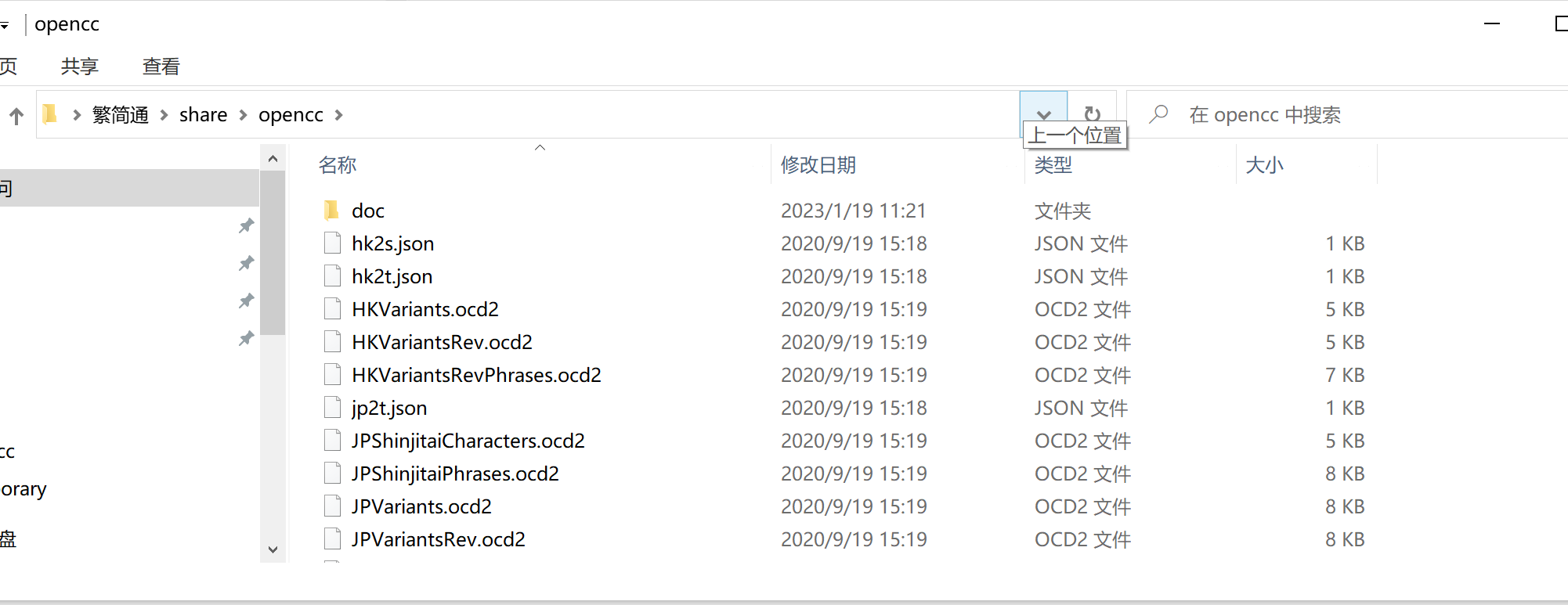
将获取的opencc词库目录放置到 服务器/usr/share目录下。
至此Opencc的基本环境信息就已经搭建完成,下面就是Openresty利用lua调用Opencc进行简体转换成繁体的。
nginx的nginx.conf文件
server {
listen 80;
server_name localhost;
#charset koi8-r;
#access_log logs/host.access.log main;
location / {
proxy_pass http://你需要代理到的网址/;
#文件根据实际路径配置 我是在nginx.conf同级下新建opencc文件夹下放置了opencc-filter.lua
body_filter_by_lua_file opencc/opencc-filter.lua;
header_filter_by_lua 'ngx.header["Content-Encoding"]=""';
}
#静态资源不需要简体和繁体的转换
location ~* \.(gif|jpg|png|js|css|ico|exe)$ {
proxy_pass http://你需要代理到的网址;
}
#error_page 404 /404.html;
# redirect server error pages to the static page /50x.html
#
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}opencc-filter.lua代码:
实现html文件的简体和繁体转换(我是放置在和nginx的conf)
local ffi = require('ffi')
--因为我代理的网页传输回来的数据格式是gzip压缩后的数据,如果没有压缩,则不需要这个
local zlib = require('zlib')
--定义的繁体转换函数
ffi.cdef[[
typedef void* opencc_t;
opencc_t opencc_open(const char *configFileName);
int opencc_close(opencc_t opencc);
char* opencc_convert_utf8(opencc_t opencc, const char *input, size_t length);
void opencc_convert_utf8_free(char *str);
]]
local cc = ffi.load('opencc')
local inst = cc.opencc_open('/usr/share/opencc/s2t.json')
--解压
local stream = zlib.inflate()
-- body_filter_by_lua_file:
-- 获取当前响应数据
local chunk, eof = ngx.arg[1], ngx.arg[2]
-- 定义全局变量,收集全部响应
if ngx.ctx.buffered == nil then
ngx.ctx.buffered = {}
end
-- 如果非最后一次响应,将当前响应赋值
if chunk ~= "" and not ngx.is_subrequest then
table.insert(ngx.ctx.buffered, chunk)
-- 将当前响应赋值为空,以修改后的内容作为最终响应
ngx.arg[1] = nil
end
-- 如果为最后一次响应,对所有响应数据进行处理
if eof then
-- 获取所有响应数据
local whole = table.concat(ngx.ctx.buffered)
ngx.ctx.buffered = nil
-- 进行你所需要进行的处理
-- 重新赋值响应数据,以修改后的内容作为最终响应 我是只转换Content-Type是text/html的页面
local startIndex, endIndex = string.find(string.lower(ngx.header["Content-Type"]),"text/html")
ngx.log(ngx.ERR,startIndex,endIndex)
if startIndex>0 and endIndex>0 then
ngx.log(ngx.ERR,"------------------------1111---------------")
local ok, t = pcall(stream,whole)
ngx.log(ngx.ERR,"------------------------ok---------------",ok)
if ok then
whole = t
end
local res = cc.opencc_convert_utf8(inst, whole, #whole)
whole = ffi.string(res)
cc.opencc_convert_utf8_free(res)
cc.opencc_close(inst)
end
ngx.arg[1] = whole
end注意:
1、如果要是要 local zlib = require('zlib')这个函数,需要引入zlib.so这个文件库放置到你安装的openrestry的lualib文件下,这个函数是用来做数据是gzip解压的。
2、local ok, t = pcall(stream,whole) 这个方法是用来判断是否解压成功,因为有些数据是gzip有些数据不是gzip的,ok是true表示解压成功
3、所有的相关文件https://pan.baidu.com/s/1ROfvcR23XWpAfLKdGM4-_Q 可以通过在这个获取,提取码:gtzp
参考网页:用 OpenResty+OpenCC 让网站支持正体中文 | 博客 | Powered by skywalker_z (rexskz.info)
有帮助的话,麻烦点个关注

















 1043
1043

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









