










1.提出背景
在DQN网络中,使用神经网络取代了Q-table。
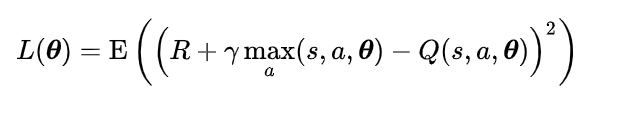
但是由于无法表示随机策略,无法表示连续动作,产生不连续的变化会影响算法的收敛等问题,策略梯度算法被提出。
2.主要内容
R.Sutton 在2000年提出的Policy Gradient 方法,是RL中,学习连续的行为控制策略的经典方法。其最为核心公式如下:
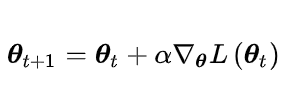
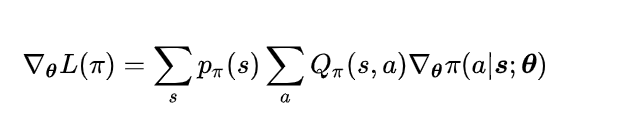
根据策略梯度定理,目标函数对策略参数的梯度值正比于策略函数梯度的加权和,权重为按照该策略执行时状态的概率分布,因此按照该策略执行时,各状态出现的次数正比于此概率值。替换掉策略梯度计算公式中对s的求和,目标函数的梯度可以写成对概率p(s)的数学期望。为了降低计算难度,提升效果。用蒙特卡洛算法近似计算该期望值。接下来用相同的方式替换掉对a的求和。

以及梯度下降的迭代公式:
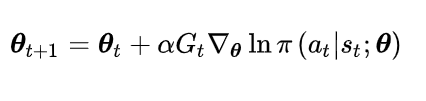
注:提出来自于Richard S Sutton, David A Mcallester, Satinder P Singh, Yishay Mansour. Policy Gradient methods for reinforcement learning with function approximation. neural information processing systems, 2000.
3.核心代码实现
策略梯度中作为核心代码为计算梯度部分。下面分别给出该部分的tensorflow和pytorch版本。
def create_softmax_network(self):
W1 = self.weight_variable([self.state_dim, 20])
b1 = self.bias_variable([20])
W2 = self.weight_variable([20, self.action_dim])
b2 = self.bias_variable([self.action_dim])
self.state_input = tf.placeholder("float", [None, self.state_dim])
self.tf_acts = tf.placeholder(tf.int32, [None, ], name="actions_num")
self.tf_vt = tf.placeholder(tf.float32, [None, ], name="actions_value")
h_layer = tf.nn.relu(tf.matmul(self.state_input, W1) + b1)
self.softmax_input = tf.matmul(h_layer, W2) + b2
self.all_act_prob = tf.nn.softmax(self.softmax_input, name='act_prob')
self.neg_log_prob = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=self.softmax_input,labels=self.tf_acts)
self.loss = tf.reduce_mean(self.neg_log_prob * self.tf_vt)
self.train_op = tf.train.AdamOptimizer(LEARNING_RATE).minimize(self.loss)
def learn(self):
self.time_step += 1
discounted_ep_rs = np.zeros_like(self.ep_rs)
running_add = 0
for t in reversed(range(0, len(self.ep_rs))):
running_add = running_add * GAMMA + self.ep_rs[t]
discounted_ep_rs[t] = running_add
discounted_ep_rs -= np.mean(discounted_ep_rs)
discounted_ep_rs /= np.std(discounted_ep_rs)
discounted_ep_rs = torch.FloatTensor(discounted_ep_rs).to(device)
softmax_input = self.network.forward(torch.FloatTensor(self.ep_obs).to(device))
neg_log_prob = F.cross_entropy(input=softmax_input, target=torch.LongTensor(self.ep_as).to(device), reduction='none')
loss = torch.mean(neg_log_prob * discounted_ep_rs)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()















 479
479











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









