










本博文基于《Character-Level Language Modeling with Deeper Self-Attention》这篇文章进行讲解,该文章发表在2019年的AAAI会议上,作者来自Google AI。在本文中,作者展示了具有固定上下文的深层(64层)transformer模型(Vaswani et al.2017)在很大程度上优于RNN变体,在两个流行基准上实现了SOTA水平:text8上每个字符1.13位,enwik8上为1.06位。为了在这个深度上获得好的结果,作者证明在中间网络层和中间序列位置增加辅助损失(auxiliary losses)是很重要的。该模型也有人称之为Vanilla Transformer[1]。
一、任务背景
自然语言文本的字符级建模具有挑战性,原因有几个。首先,模型必须“从头开始”学习大量词汇。其次,自然文本在数百或数千个时间步的长距离上表现出依赖性。第三,字符序列比单词序列长,因此需要更多的计算步骤。
近年来,强字符级语言模型通常遵循一个通用模板(Mikolov et al. 2010; 2011; Sundermeyer, Schlüter, 和Ney 2012)。递归神经网络(RNN)使用相对较短的序列长度(例如200个tokens)对小批量文本序列进行训练。为了捕获比批序列长度更长的上下文,将按顺序提供训练批,并将前一批的隐藏状态传递给当前批。这一过程被称为“时间截断反向传播”(truncated backpropagation through time, TBTT),因为梯度计算只进行一个批次(Werbos 1990)。出现了一系列无偏和改进TBTT的方法(Tallec和Ollivier, 2017;Ke et al. 2017)。
虽然这项技术取得了很好的效果,但它增加了训练过程的复杂性,最近的研究表明,以这种方式训练的模型实际上并没有“强有力地”利用长期(long-term)下文。例如,Khandelwal等人(2018年)发现,基于单词的LSTM语言模型仅有效地使用了大约200个上下文标记(即使提供了更多),并且词序仅在大约最后50个token内有效。
在本文中,作者证明了非递归模型可以在字符级语言建模方面取得很好的效果。具体而言,使用transformer自注意层网络(Vaswani et al.2017)和因果(backward-looking)注意来处理固定长度的输入并预测即将出现的字符。该模型在训练语料库中随机位置的小批量序列上进行训练,没有从一批传递到下一批的信息。
作者的主要发现是transformer体系结构非常适合于长序列上的语言建模,并且可以在该领域取代RNN。推测transformer在这里的成功是因为它能够在任意距离上“快速”传播信息;相比之下,RNN需要学习逐步向前传递相关信息。
作者还发现,对基本transformer架构的一些修改在该领域是有益的。作者添加了三个辅助损失,要求模型预测即将出现的字符(i)在中间序列位置,(ii)来自中间隐藏表示,以及(iii)在未来的多个步骤中的目标位置。这些损失加速了收敛,并使训练更深层次的网络成为可能。
二、主要内容
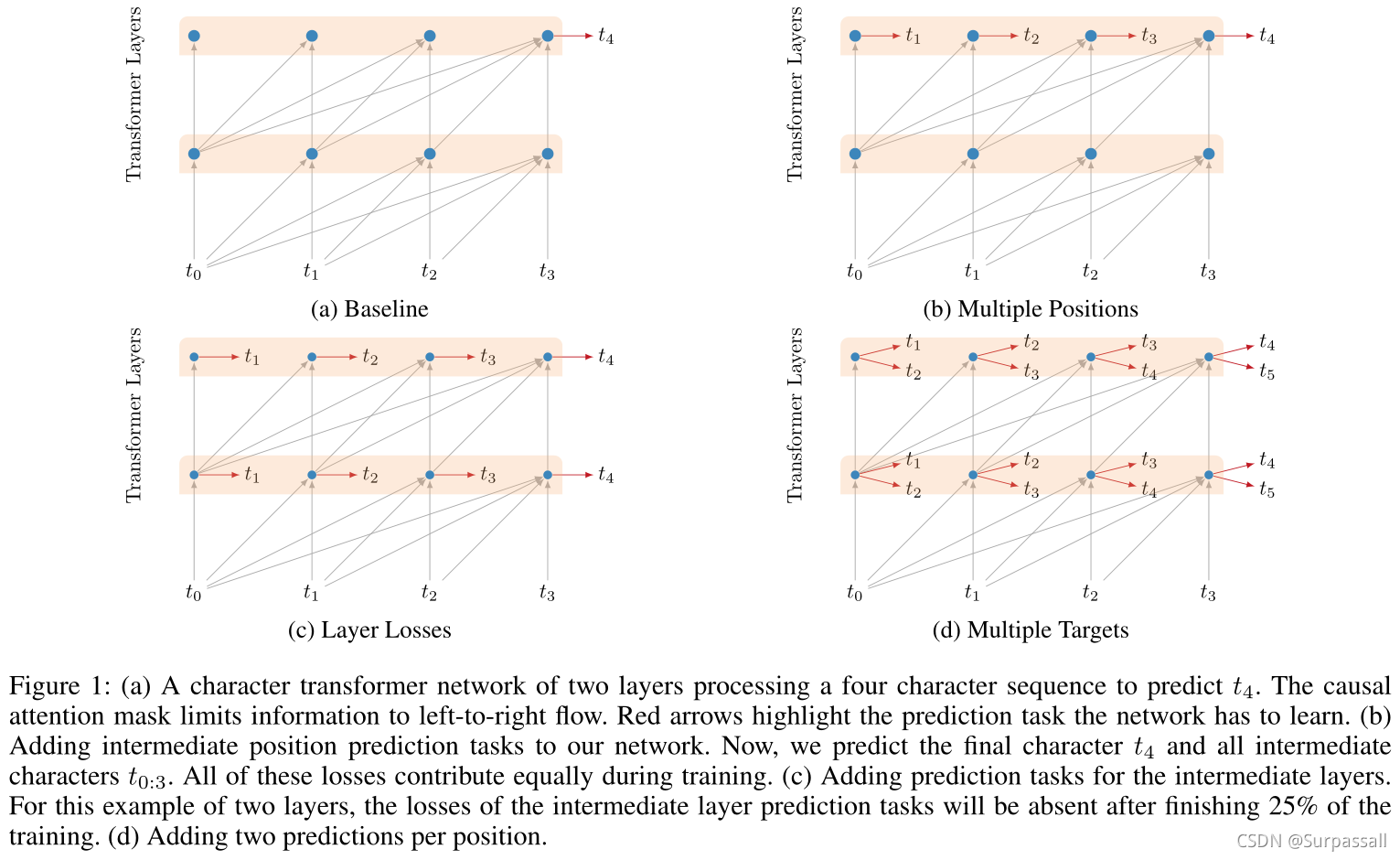
1 字符transformer模型(Character Transformer Model)
语言模型通过如下方式分解联合概率,在tokens序列上分配概率分布,其中L为序列长度:

作者提出的字符级transformer架构有64个transformer层。继Vaswani等人(2017年)之后,作者所说的“transformer层”是指包含多头自注意力子层和两个全连接子层的前馈网络的块。
为了确保模型的预测仅以过去的角色为条件,用causal attention来掩盖注意力层,因此每个位置只能关注到左边的信息。这与用于序列到序列问题的原始transformer架构的解码器组件中的“masked attention”相同(Vaswani等人,2017)。
图1a显示了初始模型,其中causal attention限制了从左到右的信息流。每个字符预测仅以较早出现的字符为条件。
1.1 Auxiliary Losses
据作者所言,本文提出的网络比之前工作中讨论的任何transformer网络都要深。在最初的实验中,训练一个深度超过十层的网络很有挑战性,收敛速度慢,准确性差。通过添加辅助损失,能够将网络深化到更好的效果,从而显著加快了训练的收敛速度。
作者添加了几种类型的辅助损失,对应于中间位置(intermediate positions)、中间层(intermediate layers)和非相邻目标(non-adjacent targets)。假设这些损失不仅加快了收敛速度,而且还充当了一个额外的正则化器。在训练过程中,辅助损失通过加权的方式加入到网络的总损失中。每种类型的辅助损失都有自己的衰减时间表。在evaluation和inference期间,仅使用对最终层的最终位置的预测。
该方法的一个结果是,许多网络参数仅在训练期间使用,具体而言,输出分类层中的参数与中间层的预测和非相邻目标的预测相关。因此,在列出模型中的参数数量时,区分“训练参数”和“推理参数”。
1.1.1 Multiple Positions
首先,为最后一层中的每个位置添加预测任务,将预测从每个位置扩展到 ∣ L ∣ |L| ∣L∣(序列长度)。注意,在基于RNN的方法中,预测所有序列位置是标准做法。然而,在作者的例子中,由于没有信息在batch之间传递,这迫使模型预测给定的较小上下文,有时只有一个或两个字符。这些二级训练任务是否有助于在全语境下进行预测这一主要任务,尚不清楚。然而,作者发现增加这种辅助损失可以加快训练速度,并给出更好的结果(见下面的消融实验)。图1b说明了预测所有序列位置的任务。作者在训练过程中增加这些损失,而不会使他们的权重下降。
1.1.2 Intermediate Layer Losses
除了最终的预测层之外,我们还添加了从每个中间transformer层的输出进行的预测。与最后一层一样,作者为序列中的所有中间位置添加预测(见图1c)。随着训练的进行,较低层对损失的贡献越来越小。
如果一共有
n
n
n层,则第
l
l
l层中间层在完成
l
/
2
n
l/2n
l/2n的训练后停止贡献任何loss。在完成一半的训练后,此计划将消除所有中间loss。
1.1.3 Multiple Targets
在序列中的每个位置,模型对未来的字符进行两次(或更多)预测。对于每个新目标,作者引入一个单独的分类器。在将额外目标的loss添加到相应层的loss之前, 将其以0.5的权重加权。
1.2 Positional Embeddings
在Vaswani et al.(2017)所述的基本transformer网络中,正弦定时信号被添加到第一层transformer block之前的输入序列中。然而,由于本文的网络更深(64层),作者假设在通过这些层的传播过程中,时间信息可能会丢失。为了解决这个问题,作者在每个transformer层之前的输入序列中添加可学习的位置嵌入。具体地说,该模型为每个层中的每个上下文位置学习一个唯一的512维嵌入向量,给出总共的L×N×512个附加参数。作者能够在任务中安全地使用位置嵌入,因为不需要将模型泛化到比训练期间看到的更长的上下文中。
2 实验设置(Experimental Setup)
2.1 数据集
对于评估,作者主要关注text8(Mahoney 2009)。此数据集由英文维基百科文章组成,删除了多余内容(表格、外语版本链接、引文、脚注、标记、标点符号)。其余文本将被处理为使用27个唯一字符(小写字母a到z)和空格组成的最小字符词汇表。数字被其拼写的等价物替换,因此“20”变成“two zero”。不在[a-zA-Z]范围内的字符序列将转换为单个空格。最后,文本是小写的。语料库的大小为100万个字符。继Mikolov等人(2012年)和Zhang等人(2016年)之后,作者将数据分为90M个字符用于训练,5M个字符用于验证,5M个字符用于测试。
为了与其他最新方法进行比较,作者还评估了enwik8(Mahoney 2009)上的模型,enwik8是1亿字节未处理的维基百科文本,包括标记和非拉丁字符。数据集中有205个唯一的字节。继Chung等人(2015年)之后,与text8一样,我们将数据分为90M、5M和5M,分别用于训练、验证和测试。
2.2 训练
与大多数基于transformer的模型相比(Vaswani et al.2017;Salimans et al.2018),作者提出的模型非常深入,有64个transformer层,每层使用两个注意头。每个transformer层的隐藏维度为512,过滤器大小为2048。输入长度为512的模型序列。序列中的每个项表示一个字节(或等价为text8中的一个字符),该字节被它的embedding(大小为512的向量)替换。作者为字节embedding添加了一个单独的学习位置embedding,用于512个token位置中,如上面的Positional Embeddings部分所述。在整个网络的每一层都做同样的添加。位置embedding不会跨层共享。每个位置有两个预测,每层学习预测1024个字符。因为主要感兴趣的是预测紧随其后的字符(一步的距离),所以将两步距离的预测字符的loss减半。预测层是全部256个输出(唯一字节数)上的逻辑回归层。为了证明模型的泛化性,总是对所有256个标签进行训练和预测,即使是在涵盖较小词汇表的数据集上。尽管如此,作者发现在实践中,该模型从未预测过训练数据集中观察到的字节值之外的字节值。
该模型有大约2.35亿个参数,大于text8训练语料库中的字符数。为了正则化模型,作者在注意层和ReLU层中应用了概率为0.55的dropout。使用动量为0.99的动量优化器。训练期间,学习率固定为0.003。作者训练了400万个step的模型,每个step处理一批16个随机选择的序列。连续降低中间层损耗,如上面中间层损耗部分所述。从第一层开始,每
62.5
K
(
=
4
M
×
1
2
∗
64
)
62.5K (=4M×\frac{1}{2∗64})
62.5K(=4M×2∗641)步骤中,降低下一层引入的损耗。根据该计划,训练完成一半后,只出现最后一层损失。
2.3 Evaluation
在推断时,使用模型在最后一层的最终位置的预测来计算给定512个字符上下文中的字符概率。与RNN模型一样,预测之间没有状态传递,因此对于预测的每个字符,必须从头开始处理上下文。由于没有重用前面步骤中的计算,模型需要昂贵的计算资源进行评估和推理。作者通过评估整个验证集上的每字符位(bpc)来衡量训练检查点的性能(大约每10000步一次),并保存性能最佳的参数。最佳模型是在大约250万个步骤的训练后实现的,在单个Google Cloud TPU v2上需要175个小时。
三、结果和讨论
如表1和表3所示,作者提出的无论是大模型(T64)还是小模型(T12)都优于以前的模型。将网络深度从12层增加到64层可显著改善结果,辅助loss使训练能够更好地利用网络深度。表3之所以用bpb(bits per character),是因为以往的作者有些是用这种标准,为了方便比较,也换算成bpb。


Ablation Experiments
作者做了消融实验,发现对模型提升最大的组件是multiple positions和intermediate layers losses。

Comparison with Word-Level Models
表5显示了两类语言模型之间的性能差距。这种比较的研究实验可以作为研究弥补差距的可能途径的起点。

定性分析(Qualitative Analysis)

为了探究最佳模型(T64)的优缺点,作者向前运行该模型,从图2中512个字符的种子序列开始,该序列取自text8测试集。图3显示了该种子文本真实延续期间模型预测的每个字符指标。在每个位置,作者测量 i)模型在所有256个输出类中的预测熵(以比特为单位),ii)其丢失目标标签的负对数概率,即该位置的“每个字符的比特数”,以及 iii)目标在按可能性排序的输出类列表中的排名。毫不奇怪,该模型在预测单词的第一个字符时最不确定,并且随着后续字符的出现,该模型变得越来越自信和正确。
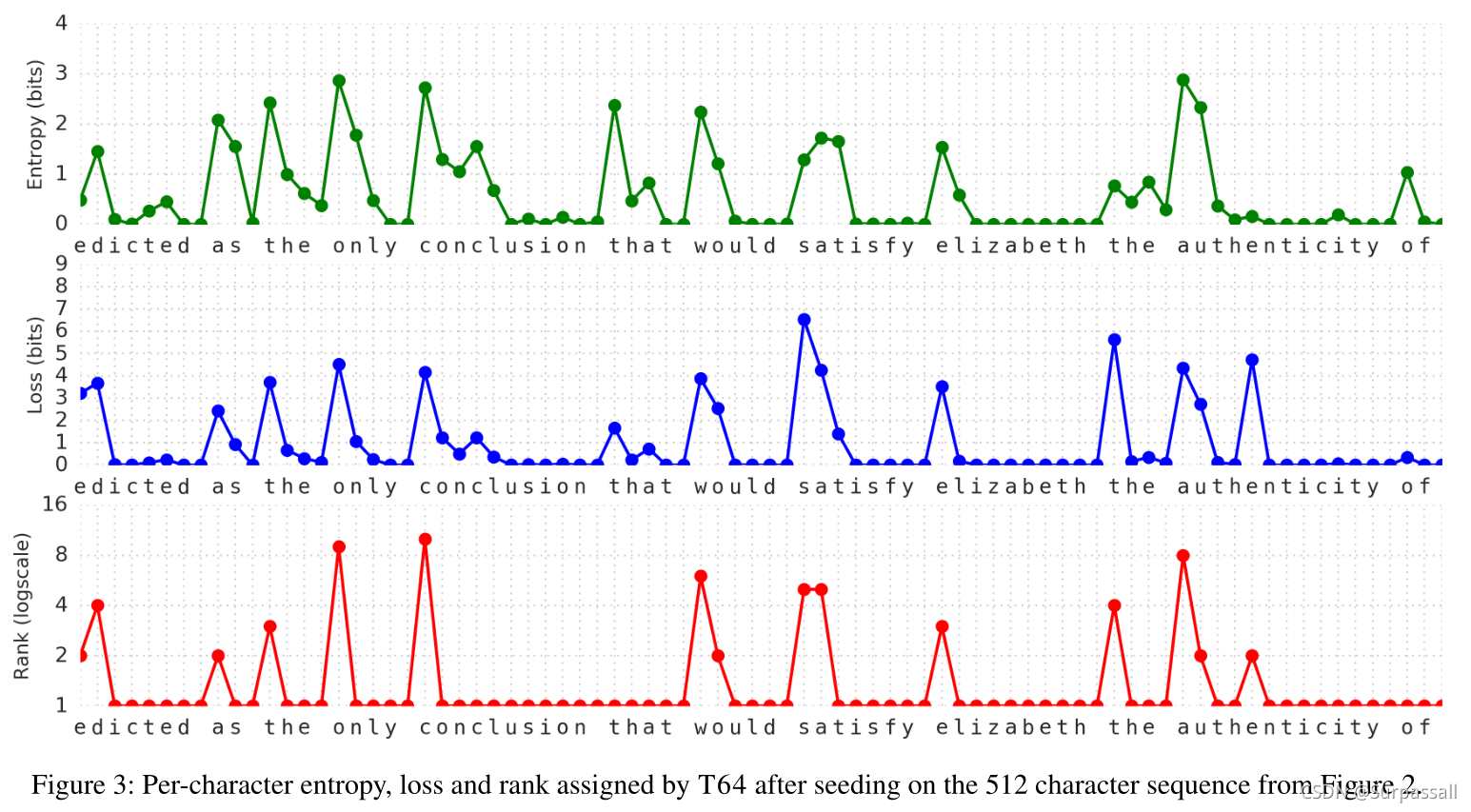
为了调查模型在多大程度上更喜欢真实的英语单词而不是不存在的单词,作者计算了模型分配给种子之后所有连续体的可能性。当连续性达到一个空格字符时,或者当连续性的总概率低于0.001时,将切断连续性。图2按概率顺序显示了一整套单词补全,其中,为了可读性,重复来自种子的初始pr。请注意,这些都是真实的或可信的(经验证的)英语单词,即使是短而糟糕的连续体(如prz)也比长而真实的单词补全(如predictable)具有更低的累积概率。
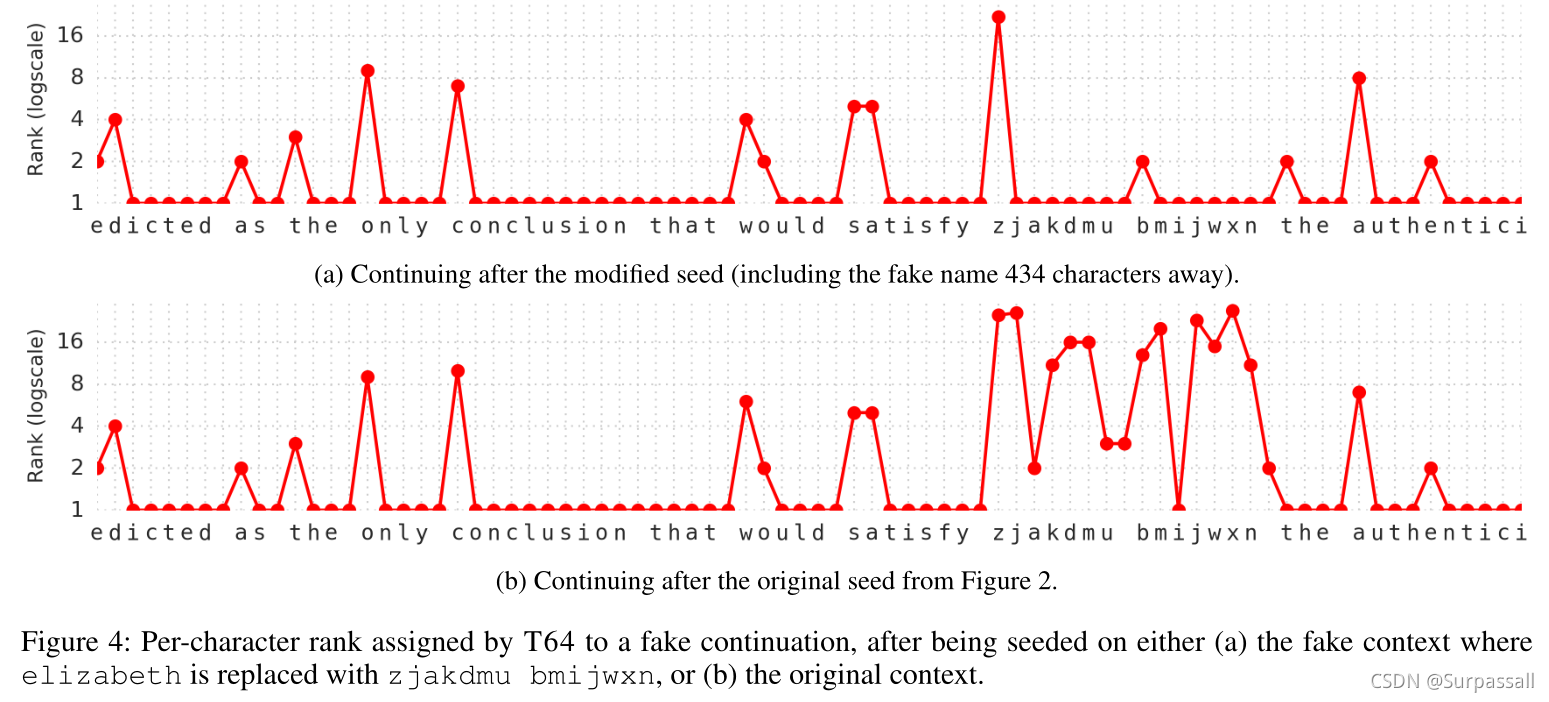
作者希望transformer的自注意力能够使模型很容易复制在长距离上下文中观察到的序列(最多512个字符的上下文大小)。为了测试这个期望,作者引入了一个假名zjakdmu bmijwxn,从而破坏了上面的种子和延续。具体来说,将第一次出现在种子中的elizabeth改为zjakdmu bmijwxn,第二次出现在种子中的是she。类似地,在后续中,将elizabeth更改为zjakdmu bmijwxn。两次出现的假名称之间的距离为434个字符。
图4a证实了模型可以成功地复制这么长的距离。虽然zjakdmu中的初始z是出乎意料的,但该模型立即选择从上下文中复制该单词的其余部分,而不是预测在训练期间学习到的任何真实z单词。类似地,虽然该模型不确定是否会出现假姓氏bmijwxn(将初始b设为2级),但在观察到b后,它会立即发现对应关系,正确预测假姓氏的其余部分。
为了进行比较,图4b显示了如果使用elizabeth的原始种子,该模型将如何对模型的伪延续中的目标进行排序。这证实,根据通过训练获得的知识,假名字是不可预测的,并且确实是从前面的上下文中复制的。
Generation
为了使用自己提出的语言模型生成样本,作者在一个较大且处理较少的数据集enwik9(Mahoney 2009)上进行训练。将enwik9分为900M、50M和50M,用于训练、验证和测试。使用验证数据集来调整dropout,发现dropout=0.1的性能最好。在测试数据集上,T64达到0.85 bpb。表6显示了种子文本之后使用1.0的采样温度生成的不同样本。

四、相关工作(Related Work)
字符级建模在情感分析(Radford、Józefowicz和Sutskever 2017)、问答(Kenter、Jones和Hewlett 2018)和分类(Zhang、Zhao和LeCun 2015)等许多领域都表现出了良好的前景,由于其简单性和易于适应其他语言的能力,它是一个令人兴奋的领域。自Bengio等人(2003)证明了基于神经网络的语言建模的有效性以来,人们对其进行了大量的研究。到目前为止,该领域最流行的架构是RNN和变体,首先在Mikolov等人(2010)中进行了研究。
通过LSTM(Hochreiter和Schmidhuber,1997年)、GRU(Cho等人,2014年)、Recurrent Highway Networks (Zilly等人,2016年)、Unitary RNN(Arjovsky、Shah和Bengio,2015年)等体系结构缓解梯度消失问题(Hochreiter等人,2001年),该领域取得了很大进展。这是一个transformer没有的问题,因为注意力机制允许short path到所有输入。正则化激活函数的方法,如Batch Normalization(Ioffe和Szegedy 2015;Merity、Keskar和Socher 2017)和layer Normalization(Lei-Ba、Kiros和Hinton 2016)也证明了语言建模任务的改进。与这项工作一样,通过Recurrent Dropout(Zaremba、Sutskever和Vinyals 2014;Gal和Ghahramani 2015)和Zoneout(Krueger et al.2016;Rocki 2016)等技术,在发现正则化序列架构的方法方面取得了进展。
一个相关的架构是Neural Cache Model(Grave、Joulin和Usunier 2016),其中RNN可以在每一步处理其之前的所有隐藏状态。(Daniluk等人,2017年)使用了另一个类似的模型,其中使用了类似于transformer的关键值关注机制。这两种方法都显示了单词级语言建模的改进。Memory Networks(Weston、Chopra和Bordes 2014)在设计上与transformer模型相似,因为它还具有处理表示输入文档的固定内存的注意层,并且已证明在语言建模方面是有效的(Sukhbatar et al.2015)。ByteNet(Kalchbrenner et al.2016)在字节级语言建模方面显示了有希望的结果,该方法是相关的,但使用了扩展的卷积层,而不是注意力。Gated Convolutional Networks(Dauphin et al.2016)是一种早期的非重复性模型,在单词级语言建模方面表现出优异的性能。
由于训练RNN的计算限制,语言模型通常不是很深,这也限制了参数的数量。transformer架构允许使用大量参数构建非常深层(64层)的模型。最近的CNN文本分类模型(Conneau等人,2016)在29层被认为是NLP社区的比较深的层。Sparsely-Gated Mixture-of-Experts Layer(Shazeer et al.2017)允许语言建模实验通过每个时间步仅访问一小部分参数来大幅增加参数数量,显示出每个字的位数减少。在Józefowicz等人(2016年)中,通过混合字符级和单词级模型、使用专门的软件和使用大量计算资源进行训练,实现了参数数量的增加。IndRNN(Li et al.2018)使用简化的RNN体系结构,允许使用21层进行更深的堆叠,实现近SOTA字符级语言建模。Fast-Slow Recurrent Neural Networks (Mujika、Meier和Steger 2017)也通过增加每个处理字符的循环步骤数实现了SOTA左右的效果。
五、结论
字符语言建模一直由递归网络方法主导。在本文中,作者展示了一个由12个堆叠变压器层组成的网络在这项任务中实现了SOTA的结果。通过将网络深化到64层,有效利用容量和深度,进一步提高了质量。在中间层和位置使用辅助loss对于达到这一性能至关重要,这些loss使作者能够训练更深的transformer网络。最后,作者分析了网络的行为,发现它能够利用依赖关系的结构和内容的长距离(超过400个字符的距离)。
参考文献
[1] 【读论文】Character-Level Language Modeling with Deeper Self-Attention(Vanilla Transformer)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









