







作为每个数据科学家都非常熟悉和使用的最受欢迎和使用的工具之一,Pandas库在数据操作、分析和可视化方面非常出色
为了帮助你完成这项任务并对Python编码更加自信,我用Pandas上一些最常用的函数和方法创建了本教程。我真心希望这对你有用。
目录
- 导入库
- 导入/导出数据
- 显示数据
- 基本信息:快速查看数据
- 基本统计
- 调整数据
- 布尔索引:loc
- 布尔索引:iloc
- 基本处理数据
我们将研究“泰坦尼克号”的数据集,主要有两个原因:(1)很可能你已经对它很熟悉了;(2)它非常小,很简单
泰坦尼克号的数据集可以在这里下载:https://bit.ly/33tOJ2S
导入库
为了我们的目的,“Pandas”库是必须导入的
import pandas as pd导入/导出数据
“泰坦尼克号数据集”指定为“data”。
a) 使用read_csv将csv文件导入。你应该在文件中添加数据的分隔符。
data = pd.read_csv("file_name.csv", sep=';')b) 使用read_excel从excel文件读取数据。
data = pd.read_excel('file_name.xls')c) 将数据帧导出到csv文件,使用to_csv
data.to_csv("file_name.csv", sep=';', index=False)d) 使用“to_excel”将数据框导出到excel文件。
data.to_excel("file_name.xls´)显示数据
a) 正在打印前n行。如果没有给定,则默认显示5行。
data.head()
b) 打印最后“n”行。下面,显示最后7行。
data.tail(7)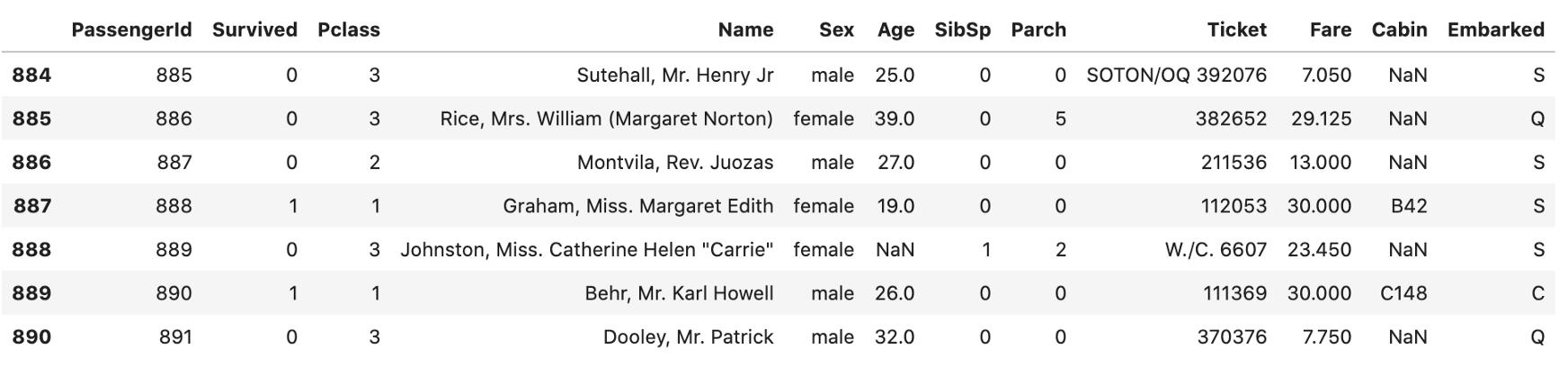
基本信息:快速查看数据
a) 显示数据集的维度:总行数、列数。
data.shape(891,12)
b) 显示变量类型。
data.dtypesPassengerId int64Survived int64Pclass int64Name objectSex objectAge float64SibSp int64Parch int64Ticket objectFare float64Cabin objectEmbarked objectdtype: objectc) 按升序值显示变量类型。
data.dtypes.sort_values(ascending=True)PassengerId int64Survived int64Pclass int64SibSp int64Parch int64Age float64Fare float64Name objectSex objectTicket objectCabin objectEmbarked objectdtype: objectd) 按类型对变量计数。
data.dtypes.value_counts()object 5int64 5float64 2dtype: int64e) 按升序值对每种类型计数。
data.dtypes.value_counts(ascending=True)float64 2int64 5object 5dtype: int64f) 以绝对值检查生存者与非生存者的数量。
data.Survived.value_counts()0 5491 342Name: Survived, dtype: int64g) 检查特征的比例,以百分比表示。
data.Survived.value_counts() / data.Survived.value_counts().sum()与以下相同:
data.Survived.value_counts(normalize=True)0 0.6161621 0.383838Name: Survived, dtype: float64h) 检查特征的比例,以百分比表示,四舍五入。
data.Survived.value_counts(normalize=True).round(decimals=4) * 1000 61.621 38.38Name: Survived, dtype: float64i) 评估数据集中是否存在缺失值。
data.isnull().values.any()Truej) 使用isnull()得到缺失值的数目。
data.isnull().sum()PassengerId 0Survived 0Pclass 0Name  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 13万+
13万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









