







本文章主要对基于深度学习的推荐模型进行总结,传统推荐算法例如矩阵分解MF,逻辑回归LR、FM、LS-PLM等不再赘述,但这些模型毕竟是推荐算法的鼻祖,其推荐原理值得研究。在随着神经网络的出现和应用,深度学习的处理复杂特征的优势和将特征工程模型化能力显著等这些优势逐渐让之前的推荐模型黯然失色,所以本部分的笔记将会主要以深度学习模型展开,如果涉及到传统推荐模型也会进行少量的阐述;
2016年是一个深度学习模型走进推荐领域的一个时间开始点,随着FNN、WIDE&Deep、Deep Crossing等一大批优秀的推荐模型架构被提出,推荐模型相对于其它领域的模型而言,模型的主要研究出发点应该是特征,由于在推荐场景中,往往没有固定单一确定的特征类别,例如有的时候推荐特征是商品这种单一独立离散的特征,有的是行为序列这种随着时间变化的离散序列等,而且各个特征领域权重度不一样,像推荐往往实时性数据,比如最近的用户交互特征等 往往显得更具有效益,但与此同时也是不能忽略用户离线的历史数据,所以推荐领域,它的特征是具有非常的不统一特性,所以往往人们更愿意称呼并构建推荐系统,因为数据对象的庞大也将推荐分成了若干环节,比如召回和排序等;其实在做推荐的时候一定要有个清晰的概念,模型是为了针对特征而建立的,因为在其它领域不论是视频还是语音都是以信号的形式出现,其特征比较统一基本都是因果非线性信号,可以进行傅里叶变化等方式展开作为模型输入,或者时域信号的序列信号输入,相比这下,推荐显得复杂多了。
一、Deep Crossing 模型
该模型解决的问题:
(1)输入特征过于稀疏;
(2)特征自动交叉组合;
(3)在输出层完成优化目标。
该模型的网络结构图如下:

该模型结构分别由四个结构层:Embedding、Stacking层、Multiple Residual Unit层和Scoring层。这里可以依次阐述一下各个层的作用:
1、Embedding层:作用是为了将稀疏的特征转化为稠密的Embedding向量,值得注意的是如果某一个特征为数值特征则不需要进行转化直接可以输入(例如年龄这种数值特征);
2、Stacking层:对Embedding层的输入向量进行拼接,形成包含所有特征的特征向量(这里估计会会有人想到这是没有对特征交叉进行考量的,因为只是输入原特征向量,而不像MF那样计算出交叉特征的,该问题在下一个层进行解决);
3、Multiple Residual Unit层:这一层的结构主要是多层感知机(所谓感知机是指的输入最初输入数据),使用了多层的残差网络,通多多层的残差网络对特征向量的各个维度(和传统交叉特征做法不一样的地方)进行充分的交叉组合,让模型能够抓到更多的非线性特征和组合特征的信息,使之能力更加强大;
4、Scoring层:为了优化目标而存在,若是二分类问题,使用逻辑回归模型,若是多分类问题使用softmax模型即可。
以上是对该模型的结构阐述,该模型对于当今更为复杂的模型看来也就是一般般的复杂,相对于传统的FM和FFM二阶特征交叉来看,该模型是通过调整网络深度来实现特征交叉的,且不是人工特征,而是交给了模型处理的,算是一大进步把,这一点的思想值得记忆。
二、Neural CF 模型
其实就是神经网络与协同过滤结合,协同过滤相对于传统的模型要注意,协同过滤更像是一个过滤器,所有的参数都不是预先训练好的,都是随着训练计算而输出,这一点和信号中的滤波器很像,建议不太懂得可以单独去了解一下协同过滤的算法知识。
推荐论文 《Neural Collaborative Filtering》

论文原图如上,协同过滤是模型化了对相关商品一种隐式的关联,它所推荐的对象是针对俩个方面一个是itemCF,另一个维度是userCF,目前碰到的场景以后者居多,协同过滤因为其特殊性,其模型训练并不存在训练数据这一概念,即对全量的数据直接进行模型学习训练,其最终输出值也即是真实输出预测值,上图的NCF由俩部分组成,一部分来源矩阵分解MF,另一部分来源于神经网络,以此形成MF和深度学习上的互补。
个人对协同过滤模型的思想可以理解为因为你和你的朋友们都喜欢做同一类事比如看电影等,突然有一天发现你的朋友们还喜欢玩一款游戏,但是你没有玩这个游戏,那么模型就会认为你也喜欢这个游戏;简单总结成一句古话:物以类聚,人以群分。
论文推荐《Neural Collaborative Filtering》
三、Wide & Deep
该模型分为wide和deep俩个部分,这俩个部分是分别负责不同的预测效果,wide简单来说就是通过机器学习算法让模型拥于‘记忆’,一般地,协同过滤、逻辑回归等简单模型有较强地‘记忆能力’,由于模型简单因此往往特征能直接影响到推荐结果,比如职业特征是学生一定不抽烟,那么wide将会使得该模型实现的就是这样直接简单得特征预测,当然特征也包括交叉特征,即该部分得特征输入为 [x, φ(x)],x表示原特征(x = [x1, x2, …, xd]),φ(x)表示交叉特征,交叉特征计算如下:
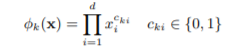
其中,cki这个参数是之前就定义好得,具体可以通过数据挖掘等方式(比如GBDT+LR)实现对交叉特征的参数确定,以此进一步确定哪些特征参与交叉输入。
另一个部分就是Deep部分,该部分主要是为了推荐系统的泛化能力,利用前向神经网络层构成,泛化能力可以理解为模型传递特征的相关性,以及挖掘稀疏甚至从未出现过的特征与最终标签的相关性,所以神经网络可以理解为深层的挖掘模型潜在的‘特征’。
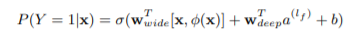
上图是俩部分输出的向量拼接在一起 输入到最后输出层,如果是二分类问题,最后激活函数使用sigmod。

其中,左部分为wide 部分,右图为Deep部分,中间图是整体模型图。
论文推荐《Wide & Deep Learning for Recommender Systems》
四、FM与深度学习结合
基于FM特征工程的深度学习推荐模型,主要是利用FM进行充分的特征交叉,形成比较全面的特征,输入到模型特征这是FNN的模型特点;DeepFM则是相当于利用FM替代Wide&Deep模型中的WIDE部分,形成了FM和Deep模型结合,该模型在Wide&Deep模型在wide部分不具备特征特征组合能力基础上提出来的,更好的形成对交叉特征的输入利用;
特征工程这条思路在这里也算是其能力极限了,模型进一步提升的空间很小,这也是这类模型的极限。
五、引入注意力机制在推荐模型中
5.1 DIN 引入注意力机制的深度学习网络

该注意力的思想反映在模型中也是比较直观的。利用候选商品和历史行为商品之间的相关性计算出一个权重,这个权重就代表注意力的强弱,注意力形式化表达式如下:
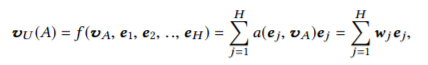
vu是用户的Embedding向量,a(·)是前向网络的激活函数,ej是用户u第j个行为向量。值得注意的是a(·)是通过注意力激活单元来生成注意力得分,激活单元的输入是俩个Embedding向量,经过元素减操作后,与原Embedding向量一同连接后形成全连接输入,最后通过单神经元输出层生成注意力得分。
5.2 DIEN 序列模型与推荐模型的结合
DIEN是阿里继DIN之后于2019年推出的另一个深度学习推荐模型,该模型引入了行为序列特征,并且通过行为序列特征模拟了用户的兴趣进化过程,
序列特征信息的重要性:
- 加强了最近行为对下次行为预测的影响;
- 序列模型能够学习到购买趋势的信息。
(1) DIEN模型网络结构图

相对于DIN,该模型增加了兴趣进化网络,兴趣进化层网络分为三层,从下往上依次:
(1) 行为序列层:将用户行为每个行为特征id转化为Emmbedding行为序列;
(2) 兴趣抽取层: 模拟用户兴趣迁移过程,从而提取用户兴趣;
(3) 兴趣进化层: 在兴趣抽取层基础上加入注意力机制,模拟与当前目标广告相关的兴趣进化过程。
六、强化学习在推荐系统上的应用
强化学习应用在推荐系统中,主要进行推荐模型的线上实时学习和更新,优点在于能够让模型对数据的实时性利用能力大大增强,但同样线上部分比较复杂,工程实现难度较大,对于推荐工程师们是一个比较大的挑战。
强化学习的研究起源于机器人研究领域,针对智能体在不断变化的环境中决策和学习过程进行建模。在智能体的学习过程中,会完成收集外部反馈,改变自身状态,再根据自身状态对下一步的行动进行决策,在行动之后持续不断的收集反馈的循环,简称 “ 行动-反馈-状态更新 ”的循环。
七、结合树和协同过滤的ESMM
未完待续…















 851
851











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









