






Using pyinstaller to package scrapy project into exetutable file
目标:将scrapy项目打包成二进制
方法:调用第三方库 pyinstaller
基本原理:pyinstaller在打包python文件成二进制文件时,将收集执行python文件所需要的库以及解释器,然后将其封装起来成一个整体。在这种方式下,打包好的文件则可以直接在其他电脑上运行,不要其安装相关库以及python。
pyinstaller打包缺点:
- 在windows平台上打包的文件只能在windows上运行;在linius平台上打包的文件只能在linius平台运行;
- 由于pyisntaller在python文件时,是根据文件中的import语句来手机相关库,如果存在动态导入,例如在函数中进行导入或者使用importlib进行导入,pyinstaller都将无法导入;
- 如果相关库需要一些数据文件,由于数据文件的导入不是使用import语句,将使得相关数据文件无法被打包,这时候需要告诉pyinstaller数据文件的位置;
案例:使用官网quotes案例
pyinstaller打包scapy的有三个关键点:
- 目录,即文件的结构
- 爬虫的入口
- 打包的方式
先来看看目录
==目录==
1,未打包之前的目录
2,打包之后的目录
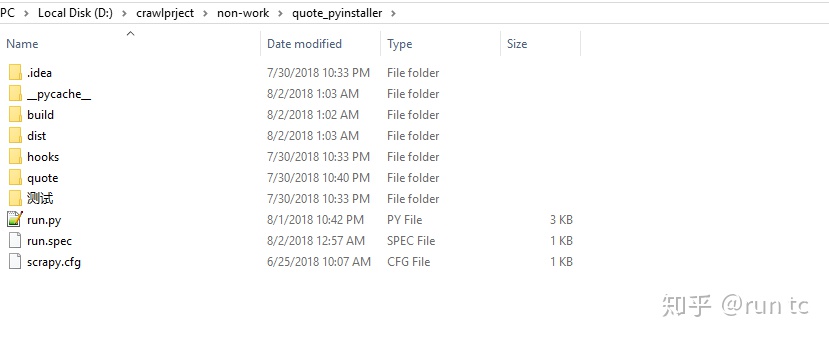
可以看出,这里多个两个文件夹:【dist】【build】
【dist】文件主要运行程序所需要的部件以及可执行程序,【build】文件夹主要存放日志以及一些工作文件。
注意:run.py放在工程目录下面,一方面可以让scrapy添加寻址路径;另外一方面不会存在工作目录下相对导入的问题;
==爬虫入口==
run文件内容
#coding = utf-8
from scrapy.crawler import CrawlerProcess
from scrapy.utils.project import get_project_settings
# -*- coding: utf-8 -*-
import scrapy
from quote.items import QuoteItem
from scrapy.http.response.html import HtmlResponse as HtmlResponse
from scrapy.http.request import Request
#解决方案--官网
class QuotesSpider(scrapy.Spider):
name = 'quotes'
allowed_domains = ['quotes.toscrape.com'] #过滤器
start_urls = ['http://quotes.toscrape.com/']
def parse(self, response):
assert isinstance(response,HtmlResponse)
urls = response.xpath("//div[@class='col-md-4 tags-box']//a/@href").extract()
tags = response.xpath("//div[@class='col-md-4 tags-box']//a/text()").extract()
abs_urls = [response.url[:-1] + i for i in urls]
print("abs_urls",abs_urls)
for i,j,p in zip(abs_urls,tags,range(len(tags))):
yield Request(url= i,meta={"base_tag":j},priority=p,callback=self.parse_tag)
def parse_tag(self,response):
item = QuoteItem()
assert isinstance(response,HtmlResponse)
bases = response.xpath("//div[@class='col-md-8']/div[@class='quote']")
for base in bases:
item["text"] = base.xpath("./span/text()").extract_first() #quote
item["author"] = base.xpath("./span/text()").extract()[1] #author
item["tags"] = base.xpath(".//div[@class ='tags']/a/text()").extract()
item["base_tag"] = response.request.meta["base_tag"]
item["priority"] = str(response.request.priority)
yield item
next_page_text = response.xpath("//ul[@class='pager']/li/a/text()").extract_first() #next page
print("next_page_text",next_page_text)
if 'Next' in next_page_text:
url = response.xpath("//ul[@class='pager']/li/a/@href").extract_first()
next_page = 'http://quotes.toscrape.com' + url
base_tag = url.split("/")[2] if url.split("/")[2] else ""
print("next_page",next_page)
yield Request(url= next_page,priority=response.request.priority,callback=self.parse_tag,meta={"base_tag":base_tag})
#创建一个进程
process = CrawlerProcess(get_project_settings())
# 'followall' is the name of one of the spiders of the project.
process.crawl(QuotesSpider) #避开命令行
process.start()
重点:
1,程序的入口,没有采用常规的cmdline形式,而是因为scrapy commands文件夹的下面命令在导入是实在函数中进行,pyinstaller无法找到,除非你告诉它位置,否则报错无法找到命令。以下是采用cmdline.execute的核心机制,从中可以看出命令的加载机制。
def execute(argv=None, settings=None):
#核心函数
#导入设置;取出命令;运行命令
if argv is None:
argv = sys.argv #sys.argv[]是用来获取命令行参数;列表
# --- backwards compatibility for scrapy.conf.settings singleton ---
if settings is None and 'scrapy.conf' in sys.modules:
from scrapy import conf
if hasattr(conf, 'settings'):
settings = conf.settings #获取设置
# ------------------------------------------------------------------
if settings is None:
settings = get_project_settings()
# set EDITOR from environment if available
try:
editor = os.environ['EDITOR']
except KeyError: pass
else:
settings['EDITOR'] = editor
check_deprecated_settings(settings) #编辑器
# --- backwards compatibility for scrapy.conf.settings singleton ---
import warnings
from scrapy.exceptions import ScrapyDeprecationWarning
with warnings.catch_warnings():
warnings.simplefilter("ignore", ScrapyDeprecationWarning)
from scrapy import conf
conf.settings = settings
# ------------------------------------------------------------------
inproject = inside_project() #true or false
#==================cmds的获取方式==================
cmds = _get_commands_dict(settings, inproject)
#================================================
cmdname = _pop_command_name(argv) #取出命令的名称
parser = optparse.OptionParser(formatter=optparse.TitledHelpFormatter(),
conflict_handler='resolve')
if not cmdname:
_print_commands(settings, inproject)
sys.exit(0)
elif cmdname not in cmds:
_print_unknown_command(settings, cmdname, inproject)
sys.exit(2)
cmd = cmds[cmdname]#取出命令
parser.usage = "scrapy %s %s" % (cmdname, cmd.syntax())
parser.description = cmd.long_desc()
settings.setdict(cmd.default_settings, priority='command')
cmd.settings = settings
cmd.add_options(parser) #加解析器
#解析命令行参数
opts, args = parser.parse_args(args=argv[1:]) #arg:未知参数;opts,命名参数
_run_print_help(parser, cmd.process_options, args, opts) #处理opts
cmd.crawler_process = CrawlerProcess(settings)#核心,简历crawl流程
_run_print_help(parser, _run_command, cmd, args, opts) #运行命令
sys.exit(cmd.exitcode)#运行结束,返回状态码def _get_commands_dict(settings, inproject):
cmds = _get_commands_from_module('scrapy.commands', inproject)
cmds.update(_get_commands_from_entry_points(inproject))#更新命令
cmds_module = settings['COMMANDS_MODULE'] #定制的命令;自行定义命令的模块
if cmds_module:
cmds.update(_get_commands_from_module(cmds_module, inproject))
return cmd明显,_get_commands_from_module('scrapy.commands', inproject)是指从模块中加载文件。由于调用的函数较多,这里就不一一阐述其工作机制。
2,process.crawl(QuotesSpider),直接写爬虫的类,不要写名字
道理和上面的一样,spider所在的模块也是在在函数中导入
==pyinstaller的打包方法==
一般的打包,只需要直接运行 pyinstaller xx.py 即可,如果有需要,则添加一些参数,具体请查看官网。
而scrapy存在大量的隐形导入(这里也包括部分数据文件),pyinstaller 无法知道这些文件需要被导入,因此,打包之后的程序无法运行。
解决方案--
1,缺啥补啥。在运行打包之后的程序时,提示无法找到某个文件,则在run.py 直接导入。具体可以看 《用Pyinstaller打包Scrapy项目问题解决!!! - CSDN博客》
2,构建hook文件,系统性的导入文件。这里分为两步,第一步,构建scrapy-hook.py文件;第二步,构建run.spec文件。
scrapy-hook.py
#coding=utf-8
#调用hook,批量导入数据与模块
from PyInstaller.utils.hooks import collect_submodules, collect_data_files
# This collects all dynamically imported scrapy modules and data files.
hiddenimports = (collect_submodules('scrapy') +
collect_submodules('scrapy.pipelines') +
collect_submodules('scrapy.extensions') +
collect_submodules('scrapy.utils')+collect_submodules('scrapy.spiders')
)
#加载数据
datas = collect_data_files('scrapy')hiddenimports告诉pyinstaller有哪些隐形导入;datas告诉有哪些数据需要添加。
collect_submodules, collect_data_files这两个函数为我们提供统一导入模块与数据的接口,适合系统性的解决打包问题,这也是hooK文件由来--专门为解决某一个库的打包问题。
run.spec
# -*- mode: python -*-
block_cipher = None
a = Analysis(['run.py'],
pathex=['D:quote_pyinstaller'],
binaries=[],
datas=[(".scrapy.cfg",".")],
hiddenimports=["quote.items","quote.middlewares",'quote.pipelines','quote.settings','quote.spiders'],
hookspath=[".hooks"],
runtime_hooks=[],
excludes=[],
win_no_prefer_redirects=False,
win_private_assemblies=False,
cipher=block_cipher)
pyz = PYZ(a.pure, a.zipped_data,
cipher=block_cipher)
exe = EXE(pyz,
a.scripts,
exclude_binaries=True,
name='run',
debug=False,
strip=False,
upx=True,
console=True )
coll = COLLECT(exe,
a.binaries,
a.zipfiles,
a.datas,
strip=False,
upx=True,
name='run')
这个文件有两个要点:hiddenimports 与 hookspath
- hiddenimports告诉pyinstaller有哪些文件需要被导入;
- hookspath告诉pyinstaller hook文件的位置
==================================================
生成可执行文件时,使用命令 pyinstaller run.spec
后记:scrapy的打包这个问题,困扰了我好几天。一开始以为一个简单的pyinstaller run.py就可以搞定一切,结果打包的程序不断被报错;在阅读pyinstaller官网以及scrapy源码之后,才找到避开一些坑的路子。由此,要搞定一些问题,还得多花时间,系统性思考。















 853
853











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









