






开篇引入:在线性回归模型(一)中的讨论中,我们探讨了线性回归模型的基本假设还有相关的推导方法。但是,在线性回归模型中,是不是每一个变量都对我们的模型有用呢?还是我们需要一个更加优秀的模型呢?下面我们来探讨线性回归的模型选择吧!
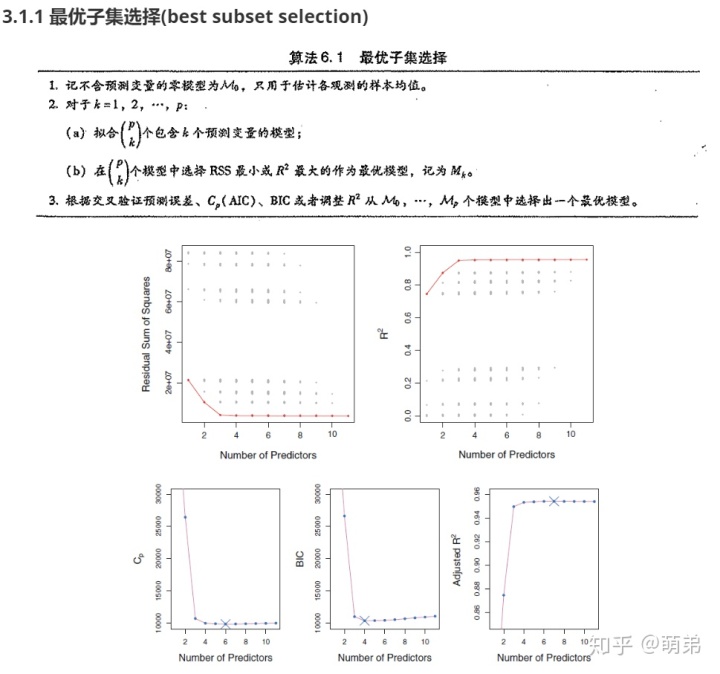
1 子集选择(subset selection)
当我们初步建立的模型中,如果p个预测变量里面存在一些不相关的预测变量,那么我们应该从中间选择一个比较好的预测变量的子集去重新拟合模型,使我们模型的预测能力 和解释能力 都能得到提高。


3.1.4 向前逐渐(Forward-Stagewise )回归

2压缩估计(Shrinkage Methods)
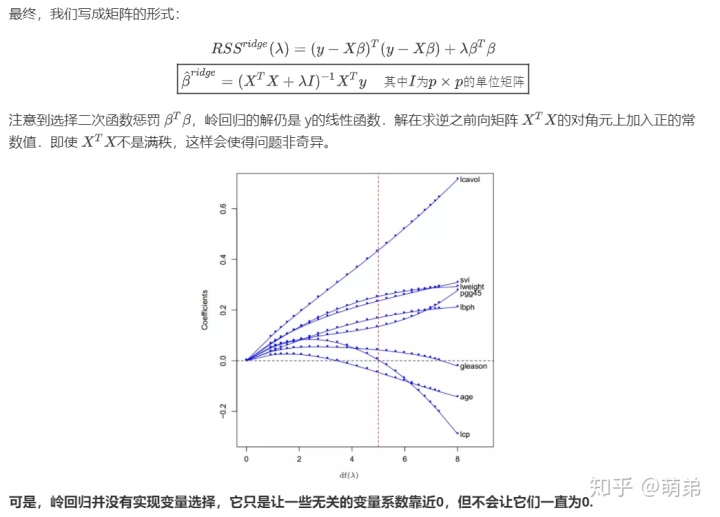
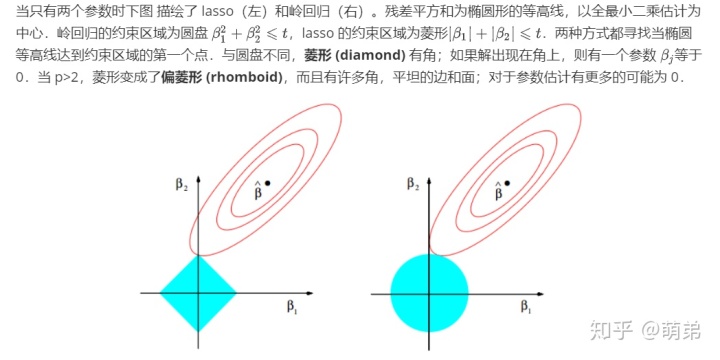
通过保留一部分预测变量而丢弃剩余的变量,子集选择 (subset selection) 可得到一个可解释的、预测误差可能比全模型低的模型.然而,因为这是一个离散的过程(变量不是保留就是丢弃),所以经常表现为高方差,因此不会降低全模型的预测误差.而压缩估计 (shrinkage methods) 更加连续,因此不会受 高易变性 (high variability) 太大的影响.


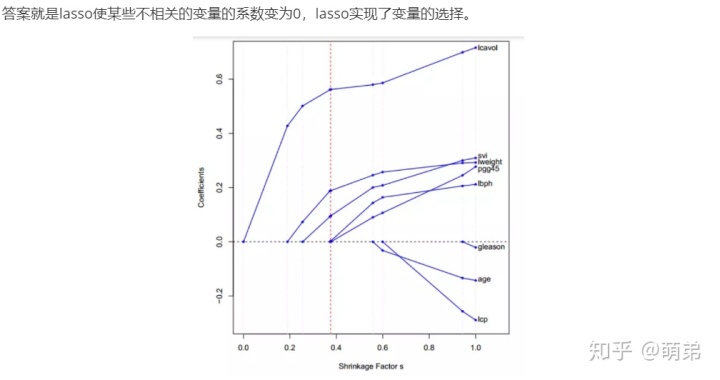
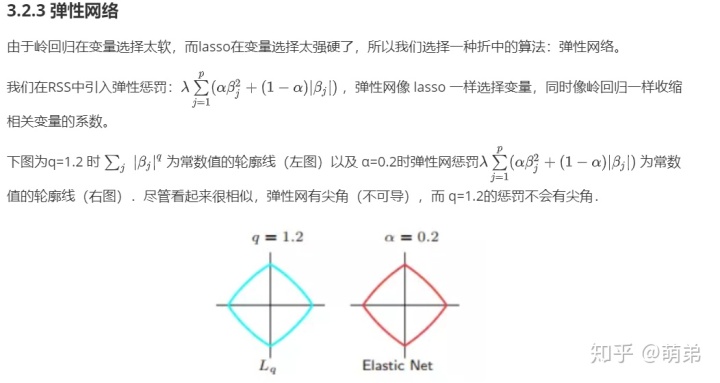

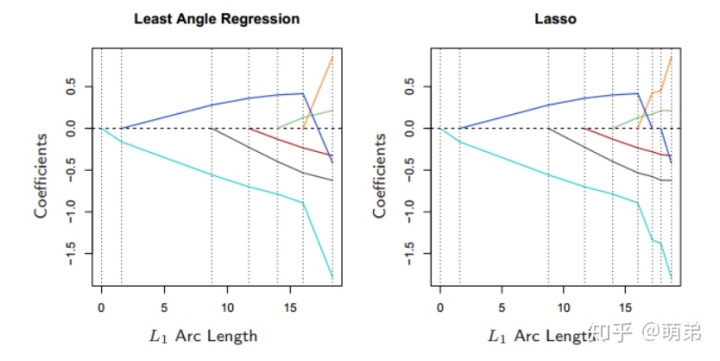
LARS可以作为Lasso的快速求解版本:如果一个非零的系数达到0,则从变量的活跃集中删除该变量并且重新计算当前的联合最小二乘方向.
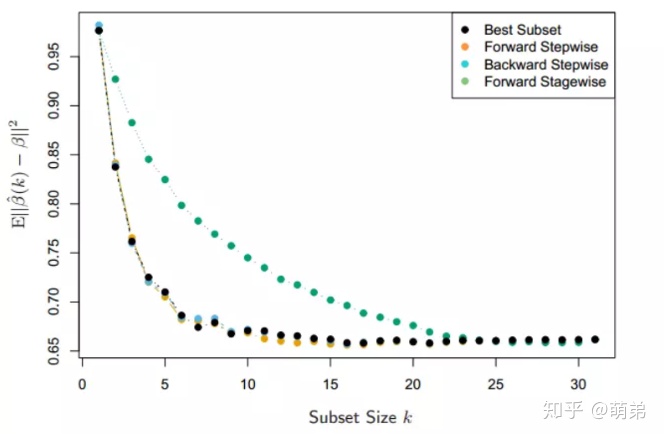
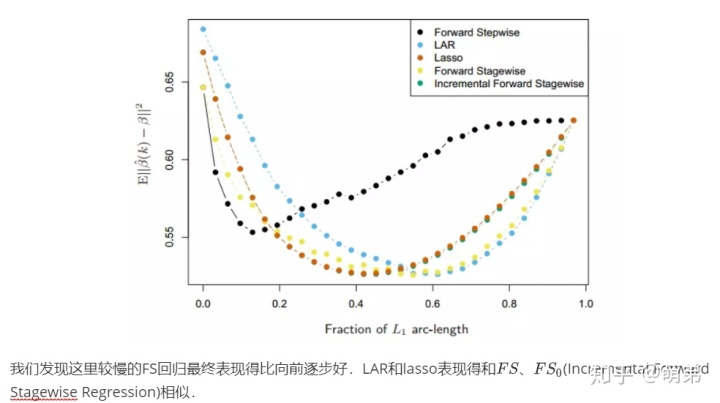
我们来对比下之前学过的子集选择方法跟我们的压缩估计在结果上有什么区别:
3降维方法(Dimension Reduction Methods)
3.3.1 主成分回归(PCL)
在前面两节我们讨论的都是在原数据上对某些变量集合的子集进行筛选的,主成分分析是一种将原变量做线性组合输出一系列不相关的其他变量,进而使用最小二乘估计。
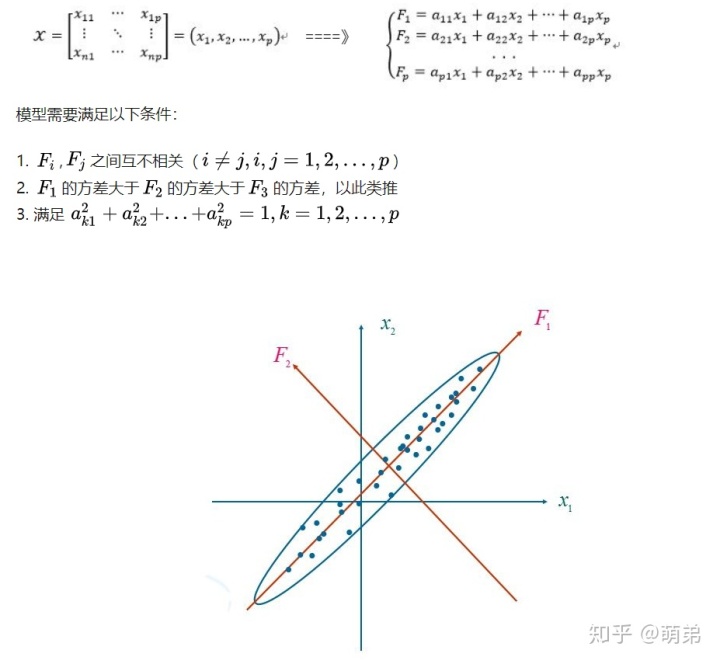

3.3.2 偏最小二乘回归(PLS)
由于主成分回归在降维的过程中只用到了自变量的某些信息,没有体现自变量与因变量上的某些关系,因此偏最小二乘回归就是为了解决这个问题。

偏最小二乘法不仅将响应矩阵进行分解提取主因子,也将浓度矩阵进行分解提取主因子。此外,在建立校正模型时,不是简单的将两个矩阵作主成分分解,而是在将X分解得分矩阵时引入有关Y的得分矩阵的信息,在将Y分解得分矩阵时引入有关X的得分矩阵的信息,这样可以保证X,Y的得分矩阵之间具有良好的线性关系。
今天的线性回归模型(二)分享分享到这里啦,接下来的章节中,我们还会给大家介绍如何评价线性回归模型好坏的残差分析。大家下期再见!!















 3023
3023











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









