 快速学会Python网络爬虫
快速学会Python网络爬虫




 本文分享了如何使用Python和BeautifulSoup快速搭建网络爬虫,抓取特定网站的文字信息,包括准备工作、代码实现及调试技巧。
本文分享了如何使用Python和BeautifulSoup快速搭建网络爬虫,抓取特定网站的文字信息,包括准备工作、代码实现及调试技巧。

一丶前话
大家好我是小默上一期分享了给电脑主机装副屏显示温度等等的 所以这一期的内容就是如何在最短的时间内教会你用python从网上爬到你想要的内容(本文只限于文字)。需要说明的是,我也只是个小白,不可避免的会犯一些错误,我只是分享一下我从这个方向走通了。如果有其他的问题,我就真的爱莫能助了。
二、准备工作
想要做好的自己的小虫虫,你需要准备以下准备:
Python的基本语法(如果有C的基础半天就能看懂)
Python的编译软件(我装的官方的那个,但是用的是sublime,打字舒服点)
一台能上网的电脑(要是你自己都上不了,还想让虫虫上?)
在开始打代码前,先装好beautifulsoup,lxml,requests这三个库

先升级一下固件,不然装完会有提示你更新版本
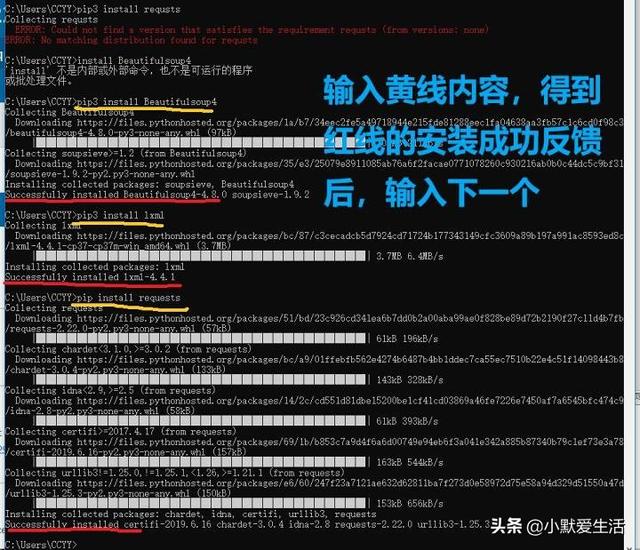
依次输入,重点看到successfully基本就没问题了
三、开始搞代码
我并不想从头开始教怎么写代码,我会在最后分享自己的代码。在这里我需要说的就是这个代码什么部分是什么(知道必须要有这个东西就行了),想要做自己的东西应该改哪个地方。整个代码我们从头开看,大概过一遍有什么。

第一部分

第二部分
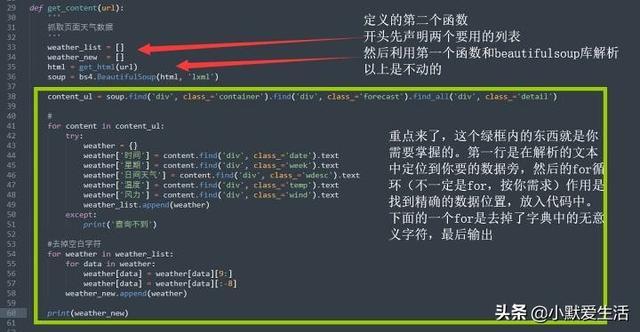
第三部分 重点

最后一点
四、观察网页
以上的代码你不一定看得懂,但是你应该有个框架在心中了,网页在代码中的表现形式就是一堆堆的英文字符等,我们所需要的数据就是通过特定的符号层层包裹在里面,我们需要做的就是一层一层定位到数据旁,再导入到代码中。下面我们将看到这个网页到底长怎么样。这里以我代码里面的网址为例,打开网页后,按F12,如果F12有额外复用功能的,需要一起按FN(很多笔记本就是这样)。我们需要做两步,第一步,找到代码位置;第二步,找到代码的嵌套标签。
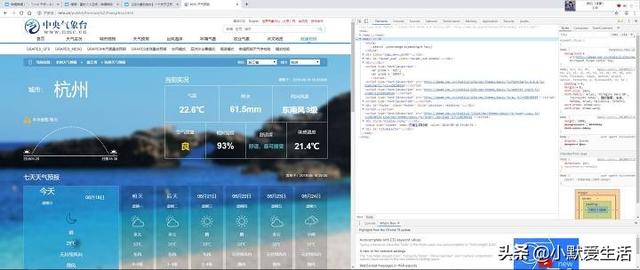
看到右边那些代码没,基本上就是一段代码对应了左边的一段内容,而我们第一步要做的就是找到你要数据所在的代码。这里讲一个懒人方法,把那个三角点一下全部展开,然后用鼠标扫一遍,直到扫到你要的那个代码在左边的画面中刚好对上,那么这就是你需要找的位置。
懒人方法
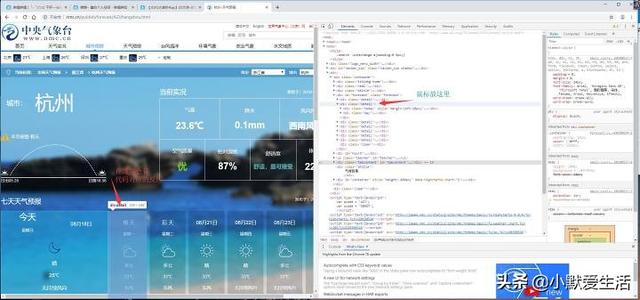
举个例子,我想要看明天的天气预报数据,那么你的代码应该定位在这个位置
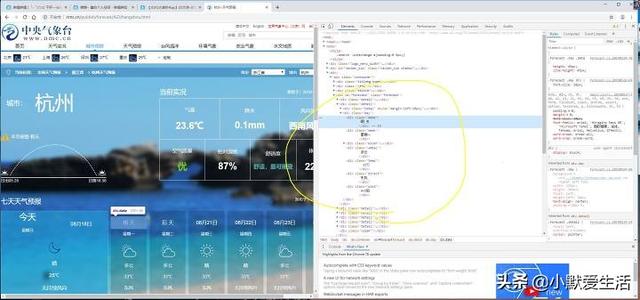
打开这个代码下面的所有折叠项目你就可以看到我们需要的数据了
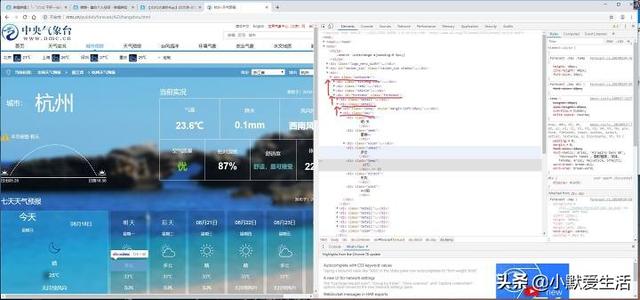
也写不下,看下面
第二步来了,注意划线部分,就是我们要找的标签,通常都是

定位代码
要想定位到这个地方。代码就是从外到里定位的。请模仿这个写法即可。当然不一定所有的都要写上,只要条件足够筛选出数据即可。细心的同学会发现,为什么前面是find,最后一个是find_all呢?这里需要说明的是,find的作用是找到第一个即可,find_all是符合条件的都筛进来。前面是定位,最后一个detail为什么要用find_all?仔细看代码中有7个,滑动看一下就知道,这7个detail对应的是未来7天的天气预报。所以我都整下来了。
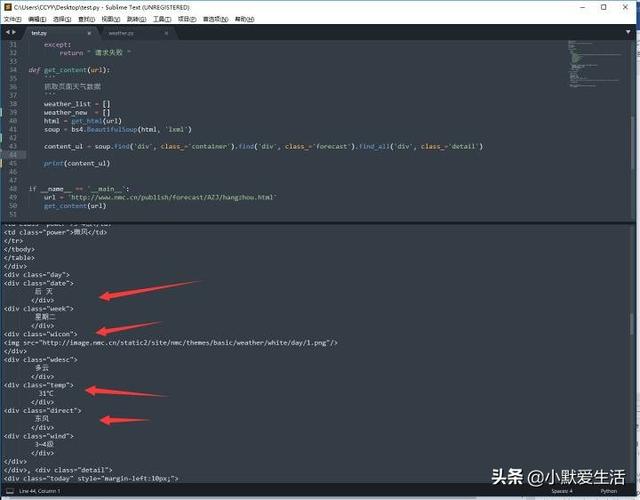
到这步就可以先printf出来康康了,可以看到我们要的数据基本都搞出来了。
定位下一步代码
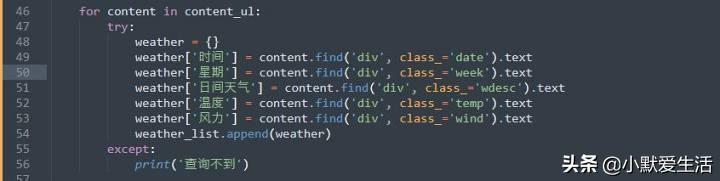
到这一步就可以往下走了,因为我这里是爬7天的天气数据,而且在代码里面会发现7天的数据是几乎类似的结构,所以在这里我就用了for in的结构,这个for x in y的结构有所不同的是,y是找到的那7个detail的代码,x是一个一个取出来,读取里面的数据后,再取下一个X,直到取完所有。(这里的try和expect是报错信息,可以查看我们上一步定位的数据有没有效,比如不小心混进去个其他的数据,但是也是有类似的标签。这个数据在这一步就进行不下去,就会返回一个except的情况告诉你:你给我安排的情况和我现在拿在手上的数据匹配不上!)

现在我们来看try里面的内容,第一行,创建空字典。

第二行及其后面的都是,找到div,class=”xxx”的结构,然后加个.text就可以把中间的内容赋值给字典对应的键
第二行及其后面的都是,找到div,class=”xxx”的结构,然后加个.text就可以把中间的内容赋值给字典对应的键值

比如这里就是把红圈内的“明天”赋值到代码了,需要注意的是,像这种情况,什么回车,空格也一起赋值进去了,这也是我最后为什么

回到正题,把要的数据筛一遍后,把这个字典添加到这个列表的尾端(循环7次不就有7个字典了吗)

爬出来的原始数据
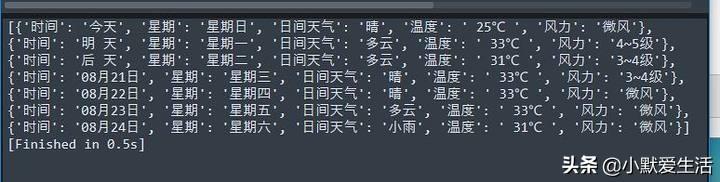
去掉了无意义字符
整段代码就这样了。是不是感觉有那么一点点触手可及了?至于后面那段去除空白字符的操作,这个和爬虫就没有关系了——就是基本的遍历,然后操作字符串就行了。
总结一下我们在干嘛。打开浏览器+F12,看到那堆代码没?爬虫的前半段会将它处理为类似于文本的信息,我们需要做的就是在这堆数据里面手动找到我们要的数据的位置,并告诉代码,然后在这堆有用信息中,我们用代码实现了从数据中挖取自己想要的数值。最后打印出来。至于这个数据要怎么用,那就是以后的事了
五、一些很重要的后话
Q:Z? WSM? 我用浏览器+F12看着数据好好的,为什么代码找不到?
A:正常,在解析网页的时候有时候会产生内容缺失。我现在遇到的有两种,一种可以通过改变解释器代码解决(你们也百度得到),另外一种就是这个数据没那么简单,需要更高级的技巧才搞得到。所以……你还是换个能爬的吧!@#¥%……
Q:我收藏了,我会了。所以你能帮帮我吗?这玩意儿还能干啥?
A: 还能……比如学生党可以查饭卡费,电费,课程安排等,其他~看你自己想象力了吧!@#¥%……&*
Q:我懂了。然后呢,你打算干嘛?
A:这个……只能说开了一个超级大坑,上到网络爬虫,下到单片机原理,我打算自己做个项目。做不做得出来就是另外一回事了,只是过程中有这么一个小小的成果,就拿出来分享一下。自勉吧。
疫情在家不如学习一下python 小默今天先教到这里喜欢小默的点个关注谢谢
#科技前线# #Python基础# #编程知识#

















- python 爬虫...&spm=1001.2101.3001.5002&articleId=110960362&d=1&t=3&u=0cacec121854459fa1a3f310470ee787)
 1211
1211

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









