







 本文深入探讨了梯度下降优化算法的各种变体及其在深度学习中的应用,包括批量、随机及小批量梯度下降。重点介绍了动量法、Adagrad、Adadelta、RMSprop和Adam等优化算法,对比了它们在不同场景下的表现,以及如何选择合适的优化算法。
本文深入探讨了梯度下降优化算法的各种变体及其在深度学习中的应用,包括批量、随机及小批量梯度下降。重点介绍了动量法、Adagrad、Adadelta、RMSprop和Adam等优化算法,对比了它们在不同场景下的表现,以及如何选择合适的优化算法。
寄语
今天开始学习读paper,希望自己能脚踏实地,勤奋努力不偷懒。正所谓“不积跬步,无以至千里;不积小流,无以成江海。”
吴恩达大大独门绝技 – “6分钟读论文”
学习论文,首先要构建一个知识架构,即大体分为哪几部分。然后再关注Abstract、Introduction、Conclusion,接着看非数学的部分,最后再去看相关的数学公式。
首先,带着这4个问题去读:
- 作者试图解决什么问题?(what did authors try to accomplish?)
- 这篇论文的关键元素是什么?(what are key elements of the paper?)
- 论文中有什内容可以“为你所用”?(what can you use yourself?)
- 有哪些参考文献你想继续研究?(what reference do you want to clear down?)
读时,可采用“渐进式”读论文大法:
- 先读标题/摘要/主要图表(title/abstracts/figures)
- 再读引言/结论/更多图表/跳过相关研究部分(intro/conclusions/morefigures/skim the rest/skip related work)
- 概览整篇文章(whole paper skim)
- 通读整篇论文(read the whole paper)
简单总结一下,先构建知识网络,再构建每一部分的具体细节。
斯坦福的N堂课|吴恩达“手把手”教你读AI论文和规划人生
强烈推荐:Github 2.4k星,深度学习paper阅读路线图
摘要
梯度下降优化算法虽然越来越受欢迎,但通常被用作黑盒优化器,因此很难对其优缺点进行实际解释。 本文旨在为读者提供关于不同算法的直观认识,以帮助读者使用这些算法。 在这篇概述中,我们将研究梯度下降的不同变体,总结这些算法面临的挑战,介绍最常见的优化算法,回顾并行和分布式架构,以及调研其他优化梯度下降的策略。
1 引言
梯度下降是执行优化的最流行的算法之一,也是迄今为止优化神经网络的最常用的方法。同时,每个最先进的深度学习库都包含各种梯度下降优化算法的实现(例如lasagne,caffe和kera)。然而,这些算法通常用作黑盒优化器。因此,很难得到对其优缺点的实际解释。
本文旨在为读者提供关于优化梯度下降的不同算法的直观认识,以帮助读着使用它们。在第2节中,我们首先要看看梯度下降的不同变体。然后,我们将在第3节中简要总结训练过程中面临的挑战。随后,在第4节中,我们将介绍最常见的优化算法,展示他们如何解决这些挑战以及如何进行参数的更新。然后,在第5节中,我们将简要介绍在并行和分布式环境中优化梯度下降的算法和框架。最后,我们将在第6节中考虑其他有助于优化梯度下降的策略。
梯度下降法是最小化目标函数的一种方法。通过往目标函数梯度 ∇ θ J ( θ ) \nabla _ { \theta } J ( \theta ) ∇θJ(θ)的反方向更新参数 θ ∈ R d \theta \in R ^ { d } θ∈Rd。 学习率 η η η决定了达到(局部)最小值所采取的步长。 即,我们沿着目标函数的斜面下降的方向,直到到达谷底。
2 梯度下降的变体
梯度下降有三种变体,区别在于计算目标函数梯度使用到多少数据。 根据数据量的多少,我们在参数更新的精度和执行更新所需的时间之间进行权衡。
2.1批量梯度下降 Batch gradient descent
Vanilla梯度下降,又称批量梯度下降,在整个训练数据集上计算损失函数关于参数的梯度:
θ
=
θ
−
η
⋅
∇
θ
J
(
θ
)
θ=θ−η⋅∇ _θJ(θ)
θ=θ−η⋅∇θJ(θ)
由于每更新一次参数都需要计算整个数据集的梯度,因此批量梯度下降可能非常慢,并且无法处理超出内存容量限制的数据集。 批量梯度下降也不允许我们在线更新模型,即在运行中不能增加新的样本。
在代码中,批处理梯度下降看起来像这样:
for i in range(nb_epochs):
params_grad = evaluate_gradient(loss_function, data, params)
params = params - learning_rate * params_grad
对于给定的迭代次数epoch,首先,我们利用整个数据集计算损失函数关于参数向量params的梯度向量params_grad。 注意,最新的深度学习库中提供了自动求导的功能,可以有效地计算关于参数梯度。如果自己求导,那么梯度检查是个好主意。
然后,我们在梯度方向上更新我们的参数,学习速率决定了我们更新参数的步长有多大。 批量梯度下降保证收敛到凸函数平面的全局最小值或者非凸函数平面的局部最小值。
2.2 随机梯度下降 Stochastic gradient descent
相反,随机梯度下降法对每个训练样本
(
x
(
i
)
,
y
(
i
)
)
(x^{(i)},y^{(i)})
(x(i),y(i))求梯度并更新参数:
θ
=
θ
−
η
⋅
∇
θ
J
(
θ
;
x
(
i
)
;
y
(
i
)
)
θ=θ−η⋅∇_θJ(θ;x^{(i)};y^{(i)})
θ=θ−η⋅∇θJ(θ;x(i);y(i))
批量梯度下降为大型数据集执行冗余计算,因为它会在每次参数更新之前重新计算很多相似样本的梯度。 SGD通过单个样本进行更新参数来消除此冗余。因此,它通常更快,也可用于在线学习。 但SGD频繁更新参数,就会导致损失函数的方差比较大,如下图剧烈的震荡:
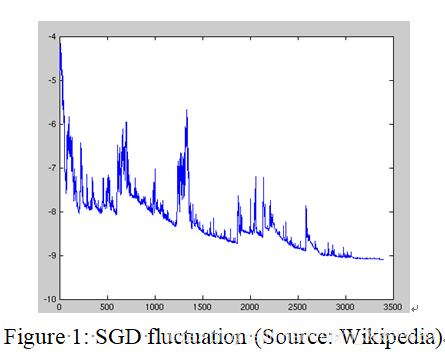
与批梯度下降法的收敛会使得损失函数陷入局部最小相比,一方面SGD的波动使其能够跳到新的并且可能更好的局部最小值。另一方面,这使得最终收敛到特定最小值的过程变得复杂,因为SGD将一直持续波动。然而,已经证明当我们慢慢降低学习速率时,SGD显示出与批量梯度下降相同的收敛行为,几乎肯定会分别收敛到非凸和凸优化的局部或全局最小值。与批梯度下降的代码相比,SGD的代码片段仅仅是在对训练样本的遍历和利用每一条样本计算梯度的过程中增加一层循环。注意,如6.1节中的解释,在每一次循环中,我们打乱训练样本。
for i in range(nb_epochs):
np.random.shuffle(data)
for example in data:
params_grad = evaluate_gradient(loss_function, example, params)
params = params - learning_rate * params_grad
2.3 小批量梯度下降 2.3 Mini-batch gradient descent
小批量梯度下降法最终结合了上述两种方法的优点,对n个训练样本求梯度并进行参数更新: θ = θ − η ⋅ ∇ θ J ( θ ; x ( i ; i + n ) ; y ( i ; i + n ) ) θ=θ−η⋅∇_θJ(θ;x^{(i;i+n)};y^{(i;i+n)}) θ=θ−η⋅∇θJ(θ;x(i;i+n);y(i;i+n))
- 减少了参数更新的方差,这可以带来更稳定的收敛;
- 够充分利用深度学习框架的矩阵优化算法,非常高效。 常见的小批量大小在50到256之间,但可以根据不同的应用而调整。
当训练神经网络时,小批量梯度下降通常是最典型的算法,当使用小批量梯度下降法时,也将其称为SGD。 注意:在下文的改进的SGD中,为了简单,我们省略了参数。
设置batch_size的默认值为50,小批量梯度下降的伪代码如下所示:
for i in range (nb_epochs):
np.random.shuffle (data)
for batch in get_batches (data , batch_size =50):
params_grad = evaluate_gradient ( loss_function , batch , params )
params = params - learning_rate * params_grad
3 挑战
虽然Vanilla小批量梯度下降法并不能保证较好的收敛性,但给我们留下了如下的一些挑战:
- 选择合适的学习率可能很困难。学习率太小会导致痛苦的缓慢收敛,而学习率太大会阻碍收敛并导致损失函数在最小值附近波动甚至偏离最小值。
- 学习率时间表尝试通过例如退火来调整训练期间的学习率。即例如按照预设的时间表来降低学习率或者当梯度小于某个阈值以后改变学习率。但是,这些时间表和阈值必须事先预设的,因此无法自适应数据集的特征。
- 此外,对所有的参数更新使用同样的学习率。如果数据是稀疏的,同时,特征的频率差异很大时,我们也许不想以同样的学习率更新所有的参数,对于出现次数较少的特征,我们对其执行更大的学习率。
- 最小化神经网络常见的高度非凸误差函数时,另一个关键挑战是避免陷入其无数次优的局部最小值。Dauphin等人认为困难实际上不是来自局部最小值,而是来自鞍点,即一维度上是递增的,而在另一个维度上是递减的。这些鞍点通常被具有相同误差的点包围,这使得SGD难以逃脱,因为梯度在所有维度上接近于零。
4 梯度下降优化算法
下面,我们将概述深度学习社区广泛使用的一些算法,以应对上述挑战。 我们不会讨论在实际中不适合高维数据集的算法,例如, 二阶方法,牛顿法。
4.1 动量法
SGD在沟壑中遇到了麻烦,即在一个维度上表面弯曲得比在另一个维度上更陡峭的区域,这些区域在局部最小值附近是常见的。 在这些情况下,SGD在山沟的斜坡上振荡,而只是沿着底部朝向局部最佳缓慢移动,如图2a所示。
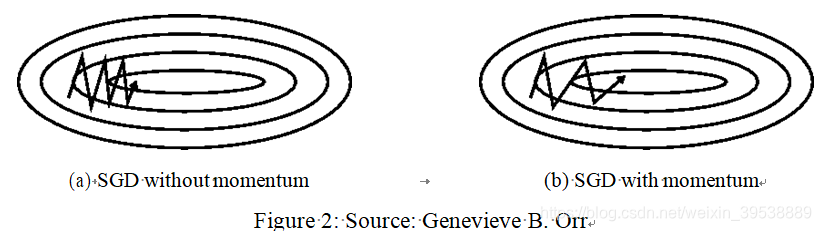
动量法是一种有助于SGD在相关方向上加速并抑制振荡的方法。如图2b所示。 它通过将过去时间步的更新向量的分量γ添加到当前更新的向量来实现
v
t
=
γ
v
t
−
1
+
η
∇
θ
J
(
θ
)
v_t=γv_{t−1}+η∇_θJ(θ)
vt=γvt−1+η∇θJ(θ)
θ
=
θ
−
v
t
θ=θ−vt
θ=θ−vt
动量项γ通常设定为0.9或类似值。
从本质上说,动量法,就像我们将球推下山。 当球向下滚动时,球会积聚动量,在途中变得越来越快(直到达到其最终速度,如果有空气阻力,即γ<1)。 我们的参数更新也会发生同样的情况:对于其梯度指向相同方向的维度,动量项增加,并减少梯度改变方向的维度的更新。 结果,我们获得更快的收敛和减少振荡。
4.2 Nesterov加速梯度下降
然而,一个盲目跟随斜坡滚下山坡的球,是不令人满意的。 我们希望有一个更聪明的球,它知道在山坡再次上升之前减速。
Nesterov加速梯度下降(NAG)是一种给我们的动量项这样的预知能力的方法。 我们知道我们,将使用动量项
γ
v
t
−
1
γv_{t-1}
γvt−1来移动参数θ。 计算
θ
−
γ
v
t
−
1
\theta - γv_{t-1}
θ−γvt−1下一个位置的近似值(完全更新时缺少梯度),这也就是告诉我们参数大致将变为多少。 现在可以通过计算关于参数未来的近似位置的梯度来有效地向前看。
v
t
=
γ
v
t
−
1
+
η
∇
θ
J
(
θ
−
γ
v
t
−
1
)
v_t=γv_{t−1}+η∇_θJ(θ−γv _{t−1})
vt=γvt−1+η∇θJ(θ−γvt−1)
θ
=
θ
−
v
t
θ=θ−v_t
θ=θ−vt
同样,我们将动量项
γ
γ
γ设置为大约0.9。 动量法首先计算当前梯度(图3中的小蓝色矢量)然后在更新的累积梯度(大蓝色矢量)的方向上进行大跳跃时,NAG首先在前一累积梯度的方向上进行大跳跃( 棕色矢量),测量梯度,然后进行校正(绿色矢量)。 这种预期的更新阻止我们过快地进行并提高响应速度,这一点在很多RNN任务中对于的性能提升有着重要的意义。
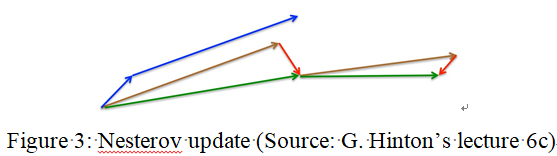
现在我们能够根据误差函数的斜率调整我们的更新并依次加速SGD,我们还希望根据每个独立参数的重要性,调整执行每个参数的更新的大小。
4.3 Adagrad
这个老朋友前面在李宏毅老师的GD章节也出现过。
Adagrad 是一种基于梯度的优化算法:它使学习率适应参数,对于不频繁出现的特征,我们对其采用更大的学习率,对于频繁出现的特征,采用较小的学习率。因此,它非常适合处理稀疏数据。Dean等人发现Adagrad大大提高了SGD的稳健性,并用它来训练Google的大型神经网络,其中包括 - 在Youtube视频中学习猫的识别。此外,Pennington等人使用Adagrad训练GloVe词向量,因为低频词比高频词需要更大的学习率。
之前,我们一次对所有参数
θ
θ
θ设置相同的学习率
η
η
η。由于Adagrad在每个时间点
t
t
t对每个参数
θ
i
θ_i
θi使用不同的学习速率,我们首先介绍Adagrad的每一个参数更新,然后我们进行矢量化。为简洁起见,我们将
g
t
,
i
g_{t,i}
gt,i设置为在
t
t
t时刻参数
θ
i
θ_i
θi的目标函数的梯度:
g
t
,
i
=
∇
θ
J
(
θ
i
)
g_{t,i}=∇_θJ(θ_i)
gt,i=∇θJ(θi)
θ
t
+
1
,
i
=
θ
t
,
i
−
η
⋅
g
t
,
i
θ_{t+1,i}=θ_{t,i}−η⋅g_{t,i}
θt+1,i=θt,i−η⋅gt,i
对于Adagrad来说,对于
θ
i
\theta_i
θi在某个时间点进行更新,它还会基于过去梯度的历史来计算:
θ
t
+
1
,
i
=
θ
t
,
i
−
η
G
t
,
i
i
+
ϵ
⋅
g
t
,
i
\theta _ { t + 1,i } = θ_{t,i}- \frac { \eta} { \sqrt { G_{t,ii}+ \epsilon } }⋅g _ { t , i }
θt+1,i=θt,i−Gt,ii+ϵη⋅gt,i
G
t
∈
R
d
x
d
G_ { t } \in R ^ { d x d }
Gt∈Rdxd是一个对角矩阵,其中每个对角线元素
i
i
i是梯度的平方和,非对角线元素为0。
ϵ
ϵ
ϵ是平滑项,避免分母为0(通常是在1e-8的数量级)。
由于的对角线上包含了关于所有参数的历史梯度的平方和,现在,我们可以通过和之间的元素向量乘法向量化上述的操作:
θ
t
+
1
=
θ
t
−
η
G
t
+
ϵ
⊙
g
t
\theta _ { t + 1} = θ_{t}- \frac { \eta} { \sqrt { G_{t}+ \epsilon } }⊙g _ {t}
θt+1=θt−Gt+ϵη⊙gt
Adagrad的主要好处之一是它不需要手动调整学习率。 在大多数的应用场景中,使用默认值0.01。
主要弱点是它在分母中累加梯度的平方:由于每个附加项都是正数,因此累积总和在训练期间不断增大。 这反过来导致学习率缩小并最终变得无限小,此时Adagrad不再能够获得额外的信息。 以下算法旨在解决此缺陷。
4.4 Adadelta
Adadelta 是Adagrad的延伸,旨在处理Adagrad学习速率单调递减的问题。 Adadelta不是累积所有过去的梯度平方,而是将累积历史梯度的窗口大小限制为一个固定值 w w w。
Adadelta不是低效地存储先前的梯度平方,而是将梯度之和递归地定义为所有过去的梯度平方的均值。 然后,在时间点
t
t
t的运行平均值
E
[
g
2
]
t
E [g^2]_t
E[g2]t仅取决于先前的平值和当前梯度(分量类似于动量项:
E
[
g
2
]
t
=
γ
E
[
g
2
]
t
−
1
+
(
1
−
γ
)
g
t
2
E [g^2]_t = \gamma E [g^2]_{t-1} + (1- \gamma)g^2_t
E[g2]t=γE[g2]t−1+(1−γ)gt2
我们依旧将动量项设置为大约为0.9。 最原始的SGD的参数变化量为:
Δ
θ
t
=
−
η
⋅
g
t
,
i
\Delta \theta _ { t } = - \eta ⋅ g_{t,i}
Δθt=−η⋅gt,i
θ
t
+
1
=
θ
t
+
Δ
θ
t
\theta _ { t+1} =\theta _ { t} + Δ \theta _ { t}
θt+1=θt+Δθt
Adagrad的参数变量为:
Δ
θ
t
=
−
η
G
t
+
ϵ
⊙
g
t
\Delta \theta _ { t } =- \frac { \eta} { \sqrt { G_{t}+ \epsilon } }⊙g _ {t}
Δθt=−Gt+ϵη⊙gt
现在,我们简单将对角矩阵替换成历史梯度的均值,Adadelta的参数参数变量为:
Δ
θ
t
=
−
η
E
[
g
2
]
t
+
ϵ
g
t
\Delta \theta _ { t } =- \frac { \eta} { \sqrt { E [g^2]_t+ \epsilon } } g _ {t}
Δθt=−E[g2]t+ϵηgt
由于分母仅仅是梯度的均方根(root mean squared,RMS)误差,我们可以简写为:
Δ
θ
t
=
−
η
R
M
S
[
g
]
t
g
t
\Delta \theta _ { t } =- \frac { \eta} { RMS [g]_t} g _ {t}
Δθt=−RMS[g]tηgt
作者指出上述更新公式中的每个部分(与SGD,动量法或者Adagrad)并不一致,即更新规则中必须与参数具有相同的假设单位。为了实现这个要求,作者首次定义了另一个指数衰减均值,这次不是梯度平方,而是参数的平方的更新:
E
[
Δ
θ
2
]
t
=
γ
E
[
Δ
θ
2
]
t
−
1
+
(
1
−
γ
)
Δ
θ
2
E [\Delta \theta^2]_t = \gamma E [\Delta \theta^2]_{t-1} + (1- \gamma)\Delta \theta^2
E[Δθ2]t=γE[Δθ2]t−1+(1−γ)Δθ2
因此,参数更新的均方根误差为:
R
M
S
[
Δ
θ
]
t
=
E
[
Δ
θ
2
]
t
+
ϵ
RMS [\Delta \theta]_t = \sqrt{ E [\Delta \theta^2]_{t} + \epsilon}
RMS[Δθ]t=E[Δθ2]t+ϵ
由于是未知的,我们利用参数的均方根误差来近似更新。利用替换先前的更新规则中的学习率,最终得到Adadelta的更新规则:
Δ
θ
t
=
−
R
M
S
[
Δ
θ
]
t
−
1
R
M
S
[
g
]
t
g
t
\Delta \theta_t = - \frac { R M S [\Delta \theta ] _ { t - 1 } } { R M S [ g ] _ { t } }g_t
Δθt=−RMS[g]tRMS[Δθ]t−1gt
θ
t
+
1
=
θ
t
+
Δ
θ
t
\theta _ { t+1} =\theta _ { t} + Δ \theta _ { t}
θt+1=θt+Δθt
使用Adadelta算法,我们甚至都无需设置默认的学习率,因为更新规则中已经移除了学习率。
4.5 RMSprop
RMSprop是一个未被发表的自适应学习率的算法,该算法由Geoff Hinton在其Coursera课堂的课程6e中提出。
RMSprop和Adadelta在相同的时间里被独立的提出,都起源于对Adagrad的极速递减的学习率问题的求解。实际上,RMSprop是先前我们得到的Adadelta的第一个更新向量的特例:
E
[
g
2
]
t
=
0.9
E
[
g
2
]
t
−
1
+
0.1
g
t
2
E [g^2]_t = 0.9 E [g^2]_{t-1} + 0.1g^2_t
E[g2]t=0.9E[g2]t−1+0.1gt2
θ
t
+
1
=
θ
t
−
η
E
[
g
2
]
t
+
ϵ
g
t
\theta _ { t+1 } =\theta _ { t}- \frac { \eta} { \sqrt { E [g^2]_t+ \epsilon } } g _ {t}
θt+1=θt−E[g2]t+ϵηgt
同样,RMSprop将学习率分解成一个平方梯度的指数衰减的平均。Hinton建议将
γ
\gamma
γ设置为0.9,对于学习率
η
\eta
η,固定为0.001。
4.6 Adam
Adam本质上是综合了动量法和Adadelta的优点。
4.7 算法的可视化
下面两张图给出了上述优化算法的优化行为的直观理解。(还可以看看这里关于Karpathy对相同的图片的描述以及另一个简明关于算法讨论的概述)。
在图4a中,我们看到不同算法在损失曲面的等高线上走的不同路线。所有的算法都是从同一个点出发并选择不同路径到达最优点。注意:Adagrad,Adadelta和RMSprop能够立即转移到正确的移动方向上并以类似的速度收敛,而动量法和NAG会导致偏离,想像一下球从山上滚下的画面。然而,NAG能够在偏离之后快速修正其路线,因为NAG通过对最优点的预见增强其响应能力。
图4b中展示了不同算法在鞍点出的行为,鞍点即为一个点在一个维度上的斜率为正,而在其他维度上的斜率为负,正如我们前面提及的,鞍点对SGD的训练造成很大困难。这里注意,SGD,动量法和NAG在鞍点处很难打破对称性,尽管后面两个算法最终设法逃离了鞍点。而Adagrad,RMSprop和Adadelta能够快速想着梯度为负的方向移动,其中Adadelta走在最前面。
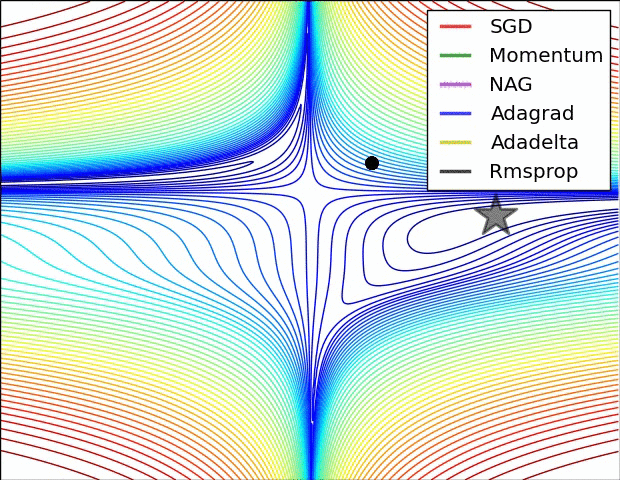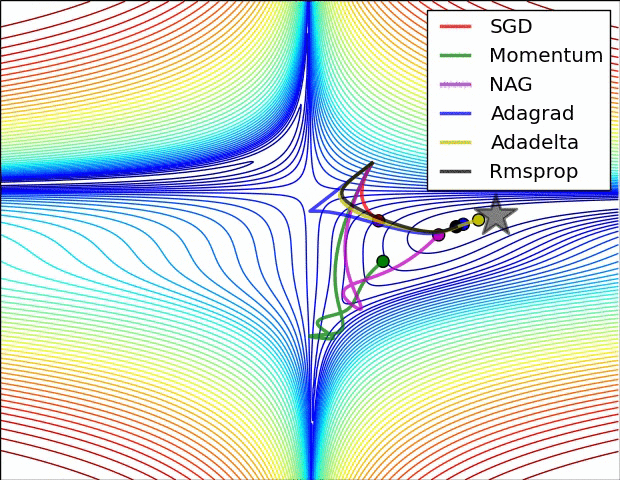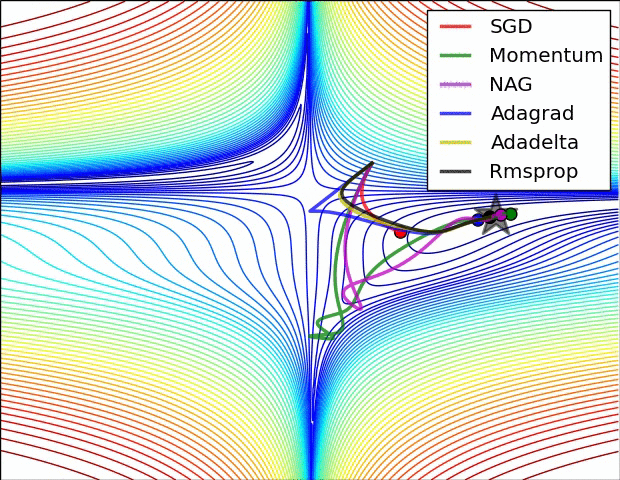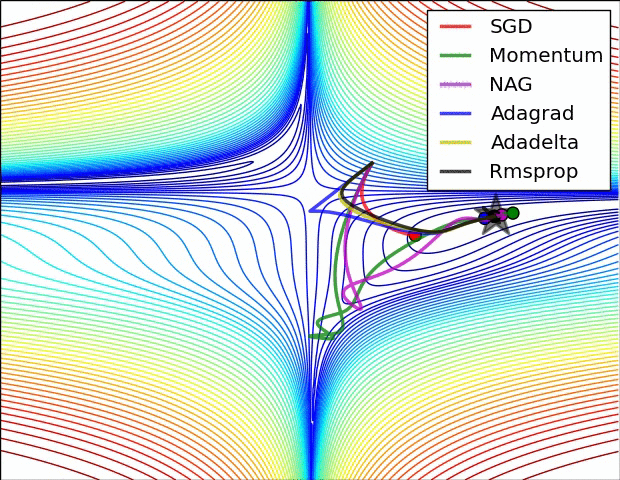
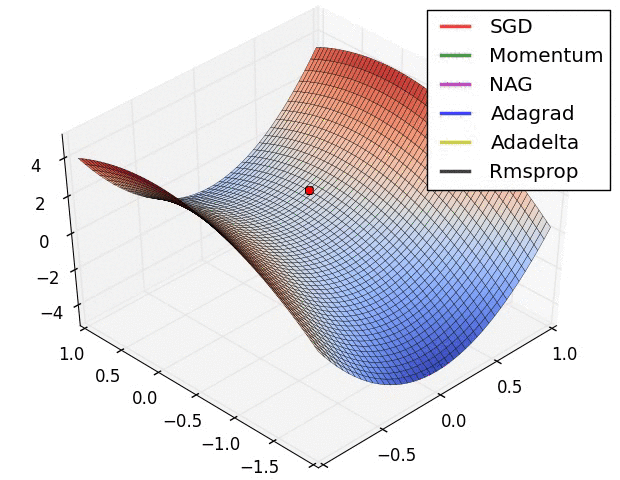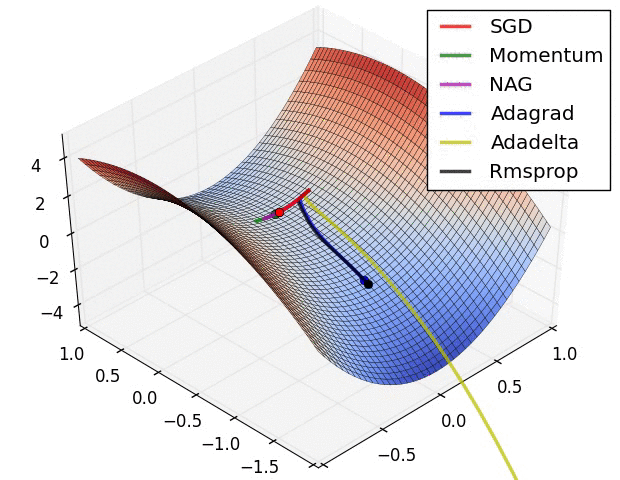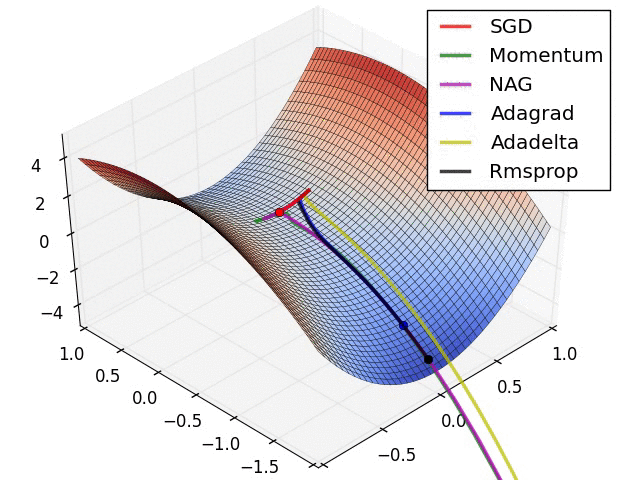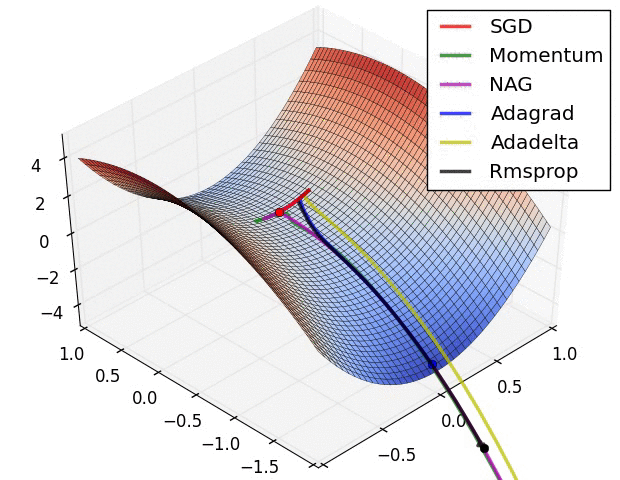
正如我们所看到的,自适应学习速率的方法,即 Adagrad、 Adadelta、 RMSprop 和Adam,最适合这些场景下最合适,并在这些场景下得到最好的收敛性。
4.8 选择使用哪种优化算法?
那么,我们应该选择使用哪种优化算法呢?如果输入数据是稀疏的,选择任一自适应学习率算法可能会得到最好的结果。选用这类算法的另一个好处是无需调整学习率,选用默认值就可能达到最好的结果。
总的来说,RMSprop是Adagrad的扩展形式,用于处理在Adagrad中急速递减的学习率。RMSprop与Adadelta相同,所不同的是Adadelta在更新规则中使用参数的均方根进行更新。最后,Adam是将偏差校正和动量加入到RMSprop中。在这样的情况下,RMSprop、Adadelta和Adam是很相似的算法并且在相似的环境中性能都不错。Kingma等人指出在优化后期由于梯度变得越来越稀疏,偏差校正能够帮助Adam微弱地胜过RMSprop。综合看来,Adam可能是最佳的选择。
有趣的是,最近许多论文中采用不带动量的SGD和一种简单的学习率的退火策略。已表明,通常SGD能够找到最小值点,但是比其他优化的SGD花费更多的时间,与其他算法相比,SGD更加依赖鲁棒的初始化和退火策略,同时,SGD可能会陷入鞍点,而不是局部极小值点。因此,如果你关心的是快速收敛和训练一个深层的或者复杂的神经网络,你应该选择一个自适应学习率的方法。
5 总结
在这篇paper中,我们初步了解了梯度下降的三种变体,其中小批量梯度下降是最受欢迎的。 然后,我们研究了最常用于优化SGD的算法:Momentum, Nesterov accelerated gradient, Adagrad, Adadelta, RMSprop, Adam, 以及优化异步SGD的不同算法。 最后,我们考虑了其他改善SGD的策略,例如shuffling(打乱顺序)、curriculum learning, batch normalization, and early stopping(早停)。
小结
之前学习项目代码的时候随机梯度下降和小批量梯度下降都见到过,读过这篇paper对他们有了更深刻的认识。正如文章中提到的,在深度学习库中,这些经过优化的梯度下降法仅仅是封装好的一个函数,我们只需要拿一个适合的来用就行了。综合看来,AdamOptimizer可能依旧是我的最佳选择。
参考:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









