





- 斯特鲁普效应简介
斯特鲁普效应(Stroop effect)在心理学中指优势反应对非优势反应的干扰。例如当测试者被要求回答有颜色意义的字体的颜色时,回答字本身的意义为优势反应,而回答字体颜色为非优势反应,若字体颜色与自意不同,被测者往往会反应速度下降,出错率上升。

- 进行斯特鲁普实验
分比对颜色和意义一样的组,颜色和意义不一样的组进行识别时间测试,其中这两组文字为自变量,测试时间为因变量
一、描述统计分析
#导入包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from scipy import stats
#导入实验测试数据集
read_File = pd.read_csv('C:/Users/zhao/Desktop/斯特鲁普数据集.csv',engine='python')
read_File.head()
字段理解:
Congruent:颜色和字义相同
Incongruent:颜色和字义不相同
# 查看基本描述统计信息
read_File.describe()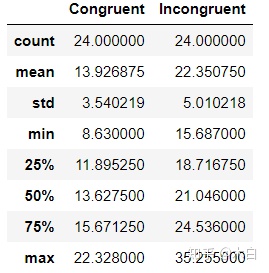
每列共24个数据
#分别求出 ‘Congruent’和‘Incongruent’两组数据的均值和标准差,赋值各自变量
con_mean = read_File['Congruent'].mean()
con_std = read_File['Congruent'].std()
inc_mean = read_File['Incongruent'].mean()
inc_std = read_File['Incongruent'].std()
print('第一组反映平均时间是',con_mean,'标准差:',con_std)
print('第二组反映平均时间是',inc_mean,'标准差:',inc_std)
#使用柱状图进行数据比较
fig = plt.figure(figsize=(20,10)) #创建画板
ax = fig.add_subplot(1,1,1)#plt.subplot(1,1,1) #创建画纸
read_File.plot(kind='bar',ax = ax)
plt.show()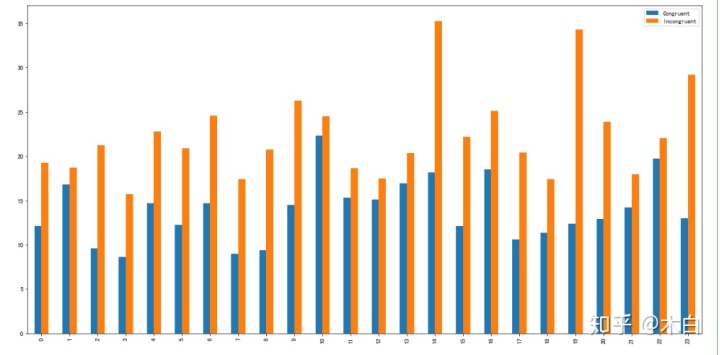
print('在字体颜色和内容一致的情况下,所需时间为{},标准差为{},
n在字体颜色和内容不一致的情况下,所需时间{},标准差为{}'.format(con_mean,con_std,inc_mean,inc_std))
print('在同一时间内,不一致要比一致花费更长时间')
新建差值 列二、推论统计分析
1、明确问题是什么?
(1)零假设和备择假设
H0 : U1 - U2 = 0 两组均值相等,没有显著性差异
H1: U1 < U2 两组均值不想等
(2)检验类型
这里选择是相关配对检验,因为该使用的是两组数据的相关样本,所以选择相关配对检验的是每对观测值之差的均值是否等于目标值,在只关注差值集的情况下,样本集处理后,只有一组差值集
read_File['差值'] = read_File['Congruent'] - read_File['Incongruent']
read_File.head()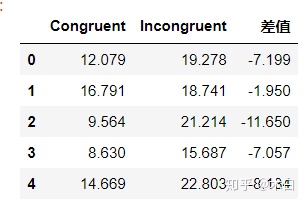
(3)抽样分布类型
由于样本量 大小为 n = 24, n < 30 ,为小样本,现在要看下这个小样本是否能够满足t抽样分布,通过seaborn 包的核密度估计来查看
sns.distplot(read_File['差值'])
plt.title('差值数据集分布')
plt.show()
(4)检验方向
检验方向分 左尾,右尾和双尾,这个分析中,由于备择假设是 U1 < U2,即颜色和内容不一致的情况下,人测试的时间会变长因此本次检验方向为左尾t检验,显著水平 5%
- 小结本次检验为 相关配对单尾t检验,检验方向为左尾
2、证据是什么?
在零假设成立的前提下,样本平均值的概率p是多少?
'''利用python中的统计模块包 scipy自动计算
ttest_rel : 相关配对检验
返回的第一个变量 t 是t假设检验的t值,
返回的第二个变量two_Tail 是双尾的概率值p
方入的参数是想要对比的列数据'''
t , two_Tail = stats.ttest_rel(read_File['Congruent'],read_File['Incongruent'])
print('t值:',t , '双尾概率p值:',two_Tail)
#由于scipy求出的概率p值是双尾,所以根据单尾原则,需要将双尾p 除以 2
one_Tail = two_Tail / 2
print(print('t值:',t , '概率p值:',one_Tail))
3、判断标准是什么?
#判断显著性水平 alpha = 0.05
alpha = 0.054、作出结论
# 左尾判断标准: t < 0 and p < one_Tail
# 右尾判断标准: t < 0 and p < one_Tail
if(t < 0 and one_Tail< alpha):
print('拒绝零假设,有统计显著')
print('也就是接受备择假设:特鲁普效应存在')
else:
print('接受备择假设,没有统计显著,也就是特鲁普效应不存在')
假设检验报告:
相关匹配检验 t(24) = -8.0886,p = 1.7743595748624577e-08( α=0.5%)左尾检验,拒绝零假设,有统计显著也就是接受备择假设:特鲁普效应存在
5、置信区间
'''样本置信区间
置信上限 a = 样本平均值 + t_ci * 标准误差
置信下限 b = 样本平均值 + t_ci * 标准误差'''
t_ci = -8.0886
# 差值数据集平均值
sample_mean = read_File['差值'].mean()
#使用scipy计算标准误差
se = stats.sem(read_File['差值'])
# 置信上限
a = sample_mean + t_ci * se
#置信下限
b = sample_mean - t_ci * se
print('两个平均值差值的置信区间,95置信水平 CI=[%f,%f]' % (a,b))
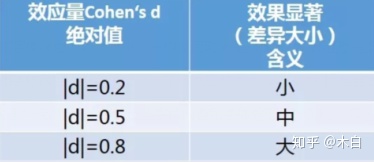
6、效应量
'''效应量差异指标Cohensd’'''
#差值数据集对应的总体平均值0
pop_mean = 0
#差值数据集的标准差
sample_std = read_File['差值'].std()
d=(sample_mean - pop_mean) / sample_std
d
三、统计分析报告
描述统计分析:
在字体颜色和内容一致的情况下,所需时间为13.926875000000003,标准差为3.5402194271529703,
在字体颜色和内容不一致的情况下,所需时间22.35075,标准差为5.010217727196399
在同一时间内,不一致要比一致花费更长时间
推论统计分析:
1)假设检验
相关配对检验t(24)= -8.0886,p=1.7743595748624577e-08(α=0.5%)左尾检验
拒绝零假设,特鲁普实验现象存在
2)置信区间
两个平均值差值的置信区间,95置信水平 CI=[-16.847739,-0.000011]
3)效应量
d=-1.651















 1072
1072











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









