






今天结束了这里的工作,晚上回来尽管身体有点疲惫,但是脑袋还是比较兴奋,帝都的响应级别终于下去了,虽然没结束,但作为有重大意义存在的帝都,这无疑释放了一个信号,然后很多高校已经把开学提上日程,大家的集体生活应该也快开始了,疫情赶紧结束吧,于是趁着节前,决定结束 t 检验的撰写,今晚效率还挺高,已经完成,节前发出去,以一篇文章结束我有史以来码字效率最高的一个月,供参考。祝大家五一节愉快。
关于t 检验,有的资料上特意强调主要用于样本含量较小(n<30)这一点,实际上 t 检验并非特意需要降低样本量,来自于我多年前本科时候的印象里,样本量小是不得以的选择,好像是啤酒酿造的时候的检验,样本量低,并非是特意控制到较低的数量,我查了一下网上的资料,并没有找到他起源的具体说法,但我已经没有读数时的生物统计课本了,因此只好做罢,各位有来源的可以告知。实际上 t 检验并没有限制样本的数量,资料上反而讲到,t分布是接近标准正态分布的钟型分布,当样本量大于 30 时,通常使用正态分布。也就是说只要是正态分布或近似正态分布,就可以使用 t 检验。
t检验是用 t 分布理论来推论差异发生的概率,他的检验有三种类型:
one-sample t-test,用来比较单个样本平均值和一个给定的平均值(理论值)的差异
例如,假设我们调查了一组男学生的身高,看看他们的平均值是否等于 170 cm。
independent samples t-test( unpaired two sample t-test),完全随机设计 (两组独立样本) 两样本均数比较的差异
例如,我要检查某有机肥是否有促进小麦品质的作用,我选了一组小麦施用该肥料,另一组施用常规化肥,最后我检查某指标之间,二者是否有差异。两组不同的小麦,他们之间是没有关系的,独立的
paired t-test,用于表两个相关的样本组之间的差异(与 0 比较)
例如,我要检验某杀虫剂是否有效果,我随机抽取一定样本,记录杀虫前后虫子的量。二者来自同一样本,是密切相关的。
下面的内容我们就用胡诌的例子和数据来演示相关的分析。
单样本 t 检验
例如,我们制定了一个标准,对于针对某虫害的杀虫剂,以一定的量喷洒 2 h 后,虫子的数量应减少 70%,下面我们来瞎编 16 个样本 2 h 后虫子数据降低量的数据:
pct_pesticide 0.6, 0.8, by= 0.02), 16, replace = TRUE)为保证后面 python 也用同样的数据,我把我运行的第一次结果作为实际的数据使用:
pct_pesticide 0.66, 0.80, 0.70, 0.72, 0.64, 0.80, 0.72, 0.66, 0.70, 0.76, 0.66, 0.60, 0.74, 0.72, 0.80, 0.72)为了满足条件,我们可以用 Q-Q 图看一下数据是否基本符合正态分布 (当然可以使用正态分布的随机数,但是那样有点太假了,我尽量把数据造的接近真实点,造数据,也要专业!):
library(car)qqPlot(pct_pesticide)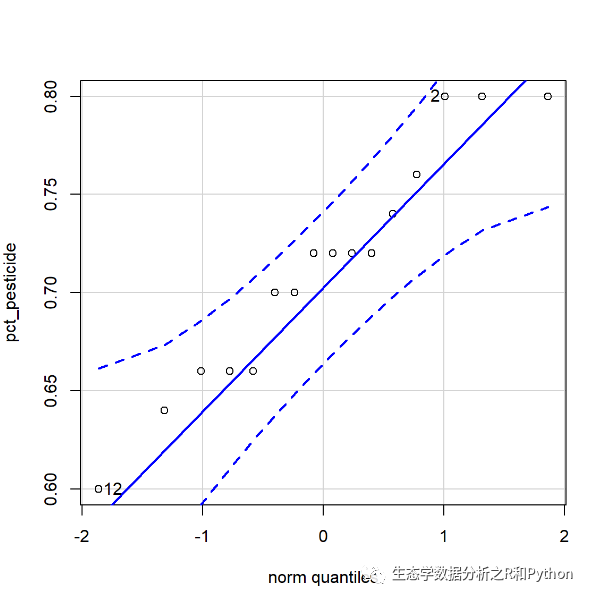
从图上看,尽管有点散乱,但还是满足我们接近正态分布的要求的。这里仅作为演示,后面的内容,为节省篇幅,不在针对造的数据验证了。
下面我们就是来进行检验了,那我们的 0 假设是二者相等,那么备择假设呢,我们可以选择这个药结果比较好,效果大于 0.7:
t.test(pct_pesticide, mu = 0.7, alternative = 'greater')## ## One Sample t-test## ## data: pct_pesticide## t = 0.84355, df = 15, p-value = 0.2061## alternative hypothesis: true mean is greater than 0.7## 95 percent confidence interval:## 0.6865227 Inf## sample estimates:## mean of x ## 0.7125上面的结果是 p 值比较大,我们接受零假设,说明该杀虫剂合格,但他仅仅是刚刚合格,没有接受备择假设。
那如果我们的备择假设是该药品不合格,低于 0.7,会有差别吗?
t.test(pct_pesticide, mu = 0.7, alternative = 'less')## ## One Sample t-test## ## data: pct_pesticide## t = 0.84355, df = 15, p-value = 0.7939## alternative hypothesis: true mean is less than 0.7## 95 percent confidence interval:## -Inf 0.7384773## sample estimates:## mean of x ## 0.7125其实看 p 值我们就明白了,备择假设没有影响我们的这个结果,那我们的备择假设如果选择 two.side,也就是默认选项呢?
t.test(pct_pesticide, mu = 0.7)## ## One Sample t-test## ## data: pct_pesticide## t = 0.84355, df = 15, p-value = 0.4122## alternative hypothesis: true mean is not equal to 0.7## 95 percent confidence interval:## 0.6809154 0.7440846## sample estimates:## mean of x ## 0.7125对于这个实验,没有影响结果,结论是接受 H0,但我们可以看一下另外的一组数据:
pct_high 0.8, 0.96, by= 0.02), 16, replace = TRUE)t.test(pct_high, mu = 0.7)t.test(pct_high, mu = 0.7, alternative = 'less')t.test(pct_high, mu = 0.7, alternative = 'greater')# two sides---------------------------------------------------------------## ## One Sample t-test## ## data: pct_high## t = 15.708, df = 15, p-value = 1.01e-10## alternative hypothesis: true mean is not equal to 0.7## 95 percent confidence interval:## 0.8782642 0.9342358## sample estimates:## mean of x ## 0.90625# less than---------------------------------------------------------------## ## One Sample t-test## ## data: pct_high## t = 15.708, df = 15, p-value = 1## alternative hypothesis: true mean is less than 0.7## 95 percent confidence interval:## -Inf 0.9292675## sample estimates:## mean of x ## 0.90625# greater than---------------------------------------------------------------## ## One Sample t-test## ## data: pct_high## t = 15.708, df = 15, p-value = 5.051e-11## alternative hypothesis: true mean is greater than 0.7## 95 percent confidence interval:## 0.8832325 Inf## sample estimates:## mean of x ## 0.90625可以看到如果是双尾的检验,那么对我们这个例子是不合适的,我们不知道杀虫剂是否合格,对于单尾的检验,备择假设是杀虫剂不合格,它的 p 值是 1,也就意味着我们 100% 不可能选择备择假设,杀虫率不能低于 70%,尽管看上去奇怪,但也能判断结果,最后一个备择假设则是看上去最正常的,说明杀虫剂效果高于我们制定的标准。所以,备择假设是不能随便假设的,以免增加工作量。
至于 python 的实现,那就费劲了,因为 scipy 内只有单样本双尾的检验,而且结果就给个 p 值、t值就结束了,这十分的不好,有点偷懒的嫌疑啊,毕竟不是统计学家搞得软件,细节方面目前就是这么不贴心,如果要得到结果,就只能手撸一长串的代码了,下面是不够贴心的代码:
from scipy import statspct_pesticide = [0.66, 0.80, 0.70, 0.72, 0.64, 0.80, 0.72, 0.66, 0.70, 0.76, 0.66, 0.60, 0.74, 0.72, 0.80, 0.72]stats.ttest_1samp(pct_pesticide , 0.7)## Ttest_1sampResult(statistic=0.8435490220263815, pvalue=0.4121721358547986)既然因为 LI-6800 是支持的 python,我又给自己挖了个坑,说不得只好费劲手撸代码了:
import pandas as pdfrom scipy import stats pct_pesticide = [0.66, 0.80, 0.70, 0.72, 0.64, 0.80, 0.72, 0.66, 0.70, 0.76, 0.66, 0.60, 0.74, 0.72, 0.80, 0.72]pct_pesticide = pd.Series(pct_pesticide)# mean of datapct_mean= pct_pesticide.mean()# scipy 里标准的均值的参数名为 pop_meanpop_mean = 0.7# 为了过程连贯,我们也在浪费点空间进行双尾检验t, p_2tail = stats.ttest_1samp(pct_pesticide , pop_mean)tp_2tail# 单尾检验的pp1 = p_2tail/2# less than 0.7p_lt = 1- p1# greater than 0.7p_gt = p1# 置信区间# 查t检验临界值表,自由度 11,t值 2.201tci = 2.201## sese = stats.sem(pct_pesticide)#confidence interval, upperconf_upper = pct_mean - tci * se conf_upperconf_lower = pct_mean + tci * seconf_lower## 0.8435490220263815## 0.4121721358547986## 0.6798848237842666## 0.7451151762157332不得不说,python 帮忙回顾了一下最基本的统计知识,真累。
独立样本 t 检验
独立样本的检验就不造数据了,还是 iris 吧,我们这次改为花萼宽度,看两个种之间有没有明显差别。
library(data.table)iris t.test(iris[Species== "setosa", Sepal.Width], iris[Species== "versicolor", Sepal.Width])## ## Welch Two Sample t-test## ## data: iris[Species == "setosa", Sepal.Width] and iris[Species == "versicolor", Sepal.Width]## t = 9.455, df = 94.698, p-value = 2.484e-15## alternative hypothesis: true difference in means is not equal to 0## 95 percent confidence interval:## 0.5198348 0.7961652## sample estimates:## mean of x mean of y ## 3.428 2.770p 值太小,也就是接受备择假设,这两个之间的差异不为 0。今天不小心看到了有个更贴心的 python 做 t 检验的模块,researchpy,但我决定不将上面的手撸代码删除了,好歹对理解 t 检验很有帮助。
import pandas as pdimport researchpy as rpiris = pd.read_csv("./data/iris.csv")setosa = iris.loc[iris['Species'] == "setosa", "Sepal.Width"]versicolor = iris.loc[iris['Species'] == "versicolor", "Sepal.Width"]rp.ttest(setosa, versicolor)## ( Variable N Mean SD SE 95% Conf. Interval## 0 Sepal.Width 50.0 3.428 0.379064 0.053608 3.320271 3.535729## 1 Sepal.Width 50.0 2.770 0.313798 0.044378 2.680820 2.859180## 2 combined 100.0 3.099 0.478739 0.047874 3.004008 3.193992, Independent t-test results## 0 Difference (Sepal.Width - Sepal.Width) = 0.6580## 1 Degrees of freedom = 98.0000## 2 t = 9.4550## 3 Two side test p value = 0.0000## 4 Difference < 0 p value = 1.0000## 5 Difference > 0 p value = 0.0000## 6 Cohen's d = 1.8910## 7 Hedge's g = 1.8765## 8 Glass's delta = 1.7359## 9 r = 0.6907)配对样本的 t 检验
配对样本和独立样本,最大的区别就是二者是否独立,配对当然是不独立,上个样本有现成的数据,这个我觉得这个配对的还是再造点看上去真实的数据吧,为了省事,我提高样本量,不检测是不是近似正态分布了:
假设我在测量高温短时间内对植物光合的影响,我想知道 35 摄氏度和 40 摄氏度对光合速率影响有没有显著差别,为避免其他效应的影响,我控制其他参数不变,植物处于饱和光照射下已经达到稳定状态,我在两个温度下连续测量了两个稳定的光合速率:
A35 10, 13, by= 0.1), 50, replace = TRUE)A40 7, 10, by= 0.1), 50, replace = TRUE)write.csv(data.frame(a35= A35, a40 = A40), "./data/photosyn.csv")还是用第一次的数据,到处后供 python 继续使用。
pair_data "data/photosyn.csv")t.test(pair_data$a35, pair_data$a40, paired = TRUE)## ## Paired t-test## ## data: pair_data$a35 and pair_data$a40## t = 18.268, df = 49, p-value < 2.2e-16## alternative hypothesis: true difference in means is not equal to 0## 95 percent confidence interval:## 2.696675 3.363325## sample estimates:## mean of the differences ## 3.03结论符合我故意让他们有差距的目的,然后是 python 版本:
import pandas as pdimport researchpy as rppair_data = pd.read_csv("./data/photosyn.csv")rp.ttest(pair_data["a35"], pair_data["a40"], paired = True)## ( Variable N Mean SD SE 95% Conf. Interval## 0 a35 50.0 11.544 0.880436 0.124512 11.293783 11.794217## 1 a40 50.0 8.514 0.861657 0.121857 8.269120 8.758880## 2 diff 50.0 3.030 1.172865 0.165868 2.696675 3.363325, Paired samples t-test results## 0 Difference (a35 - a40) = 3.0300## 1 Degrees of freedom = 49.0000## 2 t = 18.2675## 3 Two side test p value = 0.0000## 4 Difference < 0 p value = 1.0000## 5 Difference > 0 p value = 0.0000## 6 Cohen's d = 2.5834## 7 Hedge's g = 2.5636## 8 Glass's delta = 3.4415## 9 r = 0.9338)今天就是这些内容。
参考资料
Amrhein, Valentin, Sander Greenland, and Blake McShane. 2019. “Scientists Rise up Against Statistical Significance.” Nature. https://doi.org/10.1038/d41586-019-00857-9.
DeepAI. 2017. “What Is a Kernel Density Estimation?” https://deepai.org/machine-learning-glossary-and-terms/kernel-density-estimation.
Ed. 2017. “Transforming Data for Normality.” https://www.statisticssolutions.com/transforming-data-for-normality/.
Encyclopaedia Britannica, The Editors of. 2016. “Student’s T-Test.” https://www.britannica.com/science/Students-t-test.
Ford, Clay. 2017. “Understanding Q-Q Plots.” https://data.library.virginia.edu/understanding-q-q-plots/.
“Kernel Density Estimation(KDE).” 2017. https://blog.csdn.net/unixtch/article/details/78556499.
R Core Team. 2020. R: A Language and Environment for Statistical Computing. Vienna, Austria: R Foundation for Statistical Computing. https://www.R-project.org/.
Scipy. 2020. “Scipy Document.” https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.ttest_ind.html.
Trochim, William M. K. 2016. “Research Methods Knowledge Base.” https://conjointly.com/kb/statistical-student-t-test/.
Wasserstein, Ronald L., Allen L. Schirm, and Nicole A. Lazar. 2019. “Moving to a World Beyond ‘P < 0.05’.” The American Statistician. https://doi.org/10.1080/00031305.2019.1583913.















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









