





开局一段代码
talk is cheap,show me the code,先来看一段创建Kafka producer的代码
1public class KafkaProducerDemo {
2
3 public static void main(String[] args) {
4
5 KafkaProducer producer = createProducer(); 6 7 //指定topic,key,value 8 ProducerRecord record = new ProducerRecord<>("test1","newkey1","newvalue1"); 910 //异步发送11 producer.send(record);12 producer.close();1314 System.out.println("发送完成");1516 }1718 public static KafkaProducer createProducer() {19 Properties props = new Properties();2021 //bootstrap.servers 必须设置22 props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.239.131:9092");2324 // key.serializer 必须设置25 props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());2627 // value.serializer 必须设置28 props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());2930 //client.id31 props.put(ProducerConfig.CLIENT_ID_CONFIG, "client-0");3233 //retries34 props.put(ProducerConfig.RETRIES_CONFIG, 3);3536 //acks37 props.put(ProducerConfig.ACKS_CONFIG, "all");3839 //max.in.flight.requests.per.connection40 props.put(ProducerConfig.MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION, 1);4142 //linger.ms43 props.put(ProducerConfig.LINGER_MS_CONFIG, 100);4445 //batch.size46 props.put(ProducerConfig.BATCH_SIZE_CONFIG, 10240);4748 //buffer.memory49 props.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 10240);5051 return new KafkaProducer<>(props);52 }53}生产者的API使用还是比较简单,创建一个ProducerRecord对象(这个对象包含目标主题和要发送的内容,当然还可以指定键以及分区),然后调用send方法就把消息发送出去了。在发送ProducerRecord对象时,生产者要先把键和值对象序列化成字节数组,这样才能在网络上进行传输。
在深入源码之前,我先给出一张源码分析图给大家(其实应该在结尾的时候给出来),这样看着图再看源码跟容易些
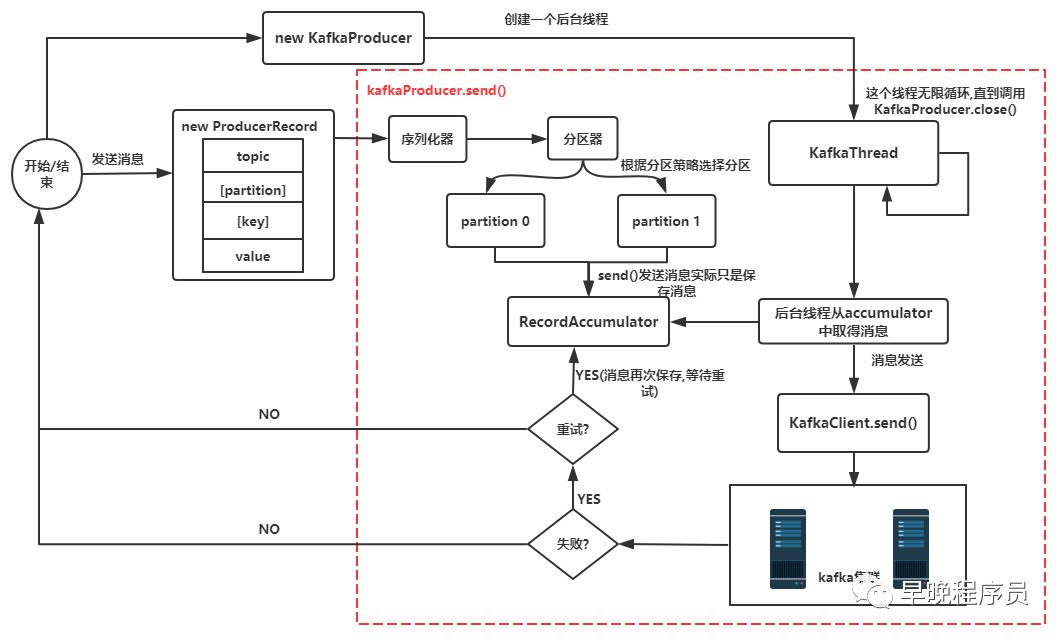
简要说明:
new KafkaProducer()后创建一个后台线程KafkaThread(实际运行线程是Sender,KafkaThread是对Sender的封装)扫描RecordAccumulator中是否有消息调用
KafkaProducer.send()发送消息,实际是将消息保存到RecordAccumulator中的一个batchs属性中,它的核心数据结构是ConcurrentMap>,这条消息会被记录到同一个记录批次(相同主题相同分区算同一个批次)里面,这个批次的所有消息会被发送到相同的主题和分区上后台的独立线程扫描到
RecordAccumulator中有消息后,会将消息发送到kafka集群中(不是一有消息就发送,而是要看消息是否ready)如果发送成功(消息成功写入kafka),就返回一个
RecordMetaData对象,它包换了主题和分区信息,以及记录在分区里的偏移量。如果写入失败,就会返回一个错误,生产者在收到错误之后会尝试重新发送消息(如果允许重试的话,此时会将消息在保存到RecordAccumulator中),几次之后如果还是失败就返回错误消息
源码分析
后台线程的创建
1KafkaClient client = new NetworkClient(...);
2this.sender = new Sender(.,client,...);
3String ioThreadName = "kafka-producer-network-thread" + " | " + clientId;
4this.ioThread = new KafkaThread(ioThreadName, this.sender, true);
5this.ioThread.start();
上面的代码就是构造KafkaProducer时核心逻辑,它会构造一个KafkaClient负责和broker通信,同时构造一个Sender并启动一个异步线程,这个线程会被命名为:kafka-producer-network-thread|${clientId},如果你在创建producer的时候指定client.id的值为myclient,那么线程名称就是kafka-producer-network-thread|myclient
发送消息(缓存消息)
1KafkaProducer producer = createProducer();2//指定topic,key,value3ProducerRecord record = new ProducerRecord<>("test1","newkey1","newvalue1");45//异步发送,可以设置回调函数6producer.send(record);7//同步发送8//producer.send(record).get();发送消息有同步发送以及异步发送两种方式,我们一般不使用同步发送,毕竟太过于耗时,使用异步发送的时候可以指定回调函数,当消息发送完成的时候(成功或者失败)会通过回调通知生产者。
发送消息实际上是将消息缓存起来,核心代码如下:
1RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp,
2 serializedKey,serializedValue, headers, interceptCallback, remainingWaitMs);RecordAccumulator的核心数据结构是ConcurrentMap>,会将相同主题相同Partition的数据放到一个Deque(双向队列)中,这也是我们之前提到的同一个记录批次里面的消息会发送到同一个主题和分区的意思。append()方法的核心源码如下:
1//从batchs(ConcurrentMap>)中
2//根据主题分区获取对应的队列,如果没有则new ArrayDeque<>返回
3Deque dq = getOrCreateDeque(tp); 4 5//计算同一个记录批次占用空间大小,batchSize根据batch.size参数决定 6int size = Math.max(this.batchSize, AbstractRecords.estimateSizeInBytesUpperBound( 7 maxUsableMagic, compression, key, value, headers)); 8 9//为同一个topic,partition分配buffer,如果同一个记录批次的内存不足,10//那么会阻塞maxTimeToBlock(max.block.ms参数)这么长时间11ByteBuffer buffer = free.allocate(size, maxTimeToBlock);12synchronized (dq) {13 //创建MemoryRecordBuilder,通过buffer初始化appendStream(DataOutputStream)属性14 MemoryRecordsBuilder recordsBuilder = recordsBuilder(buffer, maxUsableMagic);15 ProducerBatch batch = new ProducerBatch(tp, recordsBuilder, time.milliseconds());1617 //将key,value写入到MemoryRecordsBuilder中的appendStream(DataOutputStream)中18 batch.tryAppend(timestamp, key, value, headers, callback, time.milliseconds());1920 //将需要发送的消息放入到队列中21 dq.addLast(batch);22}发送消息到Kafka
上面已经将消息存储RecordAccumulator中去了,现在看看怎么发送消息。上面我们提到了创建KafkaProducer的时候会启动一个异步线程去从RecordAccumulator中取得消息然后发送到Kafka,发送消息的核心代码是Sender.java,它实现了Runnable接口并在后台一直运行处理发送请求并将消息发送到合适的节点,直到KafkaProducer被关闭
1/** 2* The background thread that handles the sending of produce requests to the Kafka cluster. This thread makes metadata 3* requests to renew its view of the cluster and then sends produce requests to the appropriate nodes. 4*/
5public class Sender implements Runnable {
6
7 public void run() {
8
9 // 一直运行直到kafkaProducer.close()方法被调用
10 while (running) {
11 run(time.milliseconds());
12 }
13
14 //从日志上看是开始处理KafkaProducer被关闭后的逻辑
15 log.debug("Beginning shutdown of Kafka producer I/O thread, sending remaining records.");
16
17 //当非强制关闭的时候,可能还仍然有请求并且accumulator中还仍然存在数据,此时我们需要将请求处理完成
18 while (!forceClose && (this.accumulator.hasUndrained() || this.client.inFlightRequestCount() > 0)) {
19 run(time.milliseconds());
20 }
21 if (forceClose) {
22 //如果是强制关闭,且还有未发送完毕的消息,则取消发送并抛出一个异常new KafkaException("Producer is closed forcefully.")
23 this.accumulator.abortIncompleteBatches();
24 }
25 ...
26 }
27}
KafkaProducer的关闭方法有2个,close()以及close(long timeout,TimeUnit timUnit),其中timeout参数的意思是等待生产者完成任何待处理请求的最长时间,第一种方式的timeout为Long.MAX_VALUE毫秒,如果采用第二种方式关闭,当timeout=0的时候则表示强制关闭,直接关闭Sender(设置running=false)。
run(long)方法中我们先跳过对transactionManager的处理,查看发送消息的主要流程如下:
1//将记录批次转移到每个节点的生产请求列表中
2long pollTimeout = sendProducerData(now);
3
4//轮询进行消息发送
5client.poll(pollTimeout, now);
首先查看sendProducerData()方法,它的核心逻辑在sendProduceRequest()方法(处于Sender.java)中
1for (ProducerBatch batch : batches) {
2 TopicPartition tp = batch.topicPartition;
3
4 //将ProducerBatch中MemoryRecordsBuilder转换为MemoryRecords(发送的数据就在这里面)
5 MemoryRecords records = batch.records();
6 produceRecordsByPartition.put(tp, records);
7}
8
9ProduceRequest.Builder requestBuilder = ProduceRequest.Builder.forMagic(minUsedMagic, acks, timeout,
10 produceRecordsByPartition, transactionalId);
11
12//消息发送完成时的回调
13RequestCompletionHandler callback = new RequestCompletionHandler() {
14 public void onComplete(ClientResponse response) {
15 //处理响应消息
16 handleProduceResponse(response, recordsByPartition, time.milliseconds());
17 }
18};
19
20//根据参数构造ClientRequest,此时需要发送的消息在requestBuilder中
21ClientRequest clientRequest = client.newClientRequest(nodeId, requestBuilder, now, acks != 0,
22 requestTimeoutMs, callback);
23
24//将clientRequest转换成Send对象(Send.java,包含了需要发送数据的buffer),
25//给KafkaChannel设置该对象,记住这里还没有发送数据
26client.send(clientRequest, now);上面的client.send()方法最终会定位到NetworkClient.doSend()方法,所有的请求(无论是producer发送消息的请求还是获取metadata的请求)都是通过该方法设置对应的Send对象。所支持的请求在ApiKeys.java中都有定义,这里面可以看到每个请求的request以及response对应的数据结构。
上面只是设置了发送消息所需要准备的内容,现在进入到发送消息的主流程,发送消息的核心代码在Selector.java的pollSelectionKeys()方法中,代码如下:
1/* if channel is ready write to any sockets that have space in their buffer and for which we have data */
2if (channel.ready() && key.isWritable()) {
3 //底层实际调用的是java8 GatheringByteChannel的write方法
4 channel.write();
5}
就这样,我们的消息就发送到了broker中了,发送流程分析完毕,这个是完美的情况,但是总会有发送失败的时候(消息过大或者没有可用的leader),那么发送失败后重发又是在哪里完成的呢?还记得上面的回调函数吗?没错,就是在回调函数这里设置的,先来看下回调函数源码
1private void handleProduceResponse(ClientResponse response, Map batches, long now) {
2 RequestHeader requestHeader = response.requestHeader();
3
4 if (response.wasDisconnected()) {
5 //如果是网络断开则构造Errors.NETWORK_EXCEPTION的响应
6 for (ProducerBatch batch : batches.values())
7 completeBatch(batch, new ProduceResponse.PartitionResponse(Errors.NETWORK_EXCEPTION), correlationId, now, 0L);
8
9 } else if (response.versionMismatch() != null) {
10
11 //如果是版本不匹配,则构造Errors.UNSUPPORTED_VERSION的响应
12 for (ProducerBatch batch : batches.values())
13 completeBatch(batch, new ProduceResponse.PartitionResponse(Errors.UNSUPPORTED_VERSION), correlationId, now, 0L);
14
15 } else {
16
17 if (response.hasResponse()) {
18 //如果存在response就返回正常的response
19 ...
20 }
21 } else {
22
23 //如果acks=0,那么则构造Errors.NONE的响应,因为这种情况只需要发送不需要响应结果
24 for (ProducerBatch batch : batches.values()) {
25 completeBatch(batch, new ProduceResponse.PartitionResponse(Errors.NONE), correlationId, now, 0L);
26 }
27 }
28 }
29}而在completeBatch方法中我们主要关注失败的逻辑处理,核心源码如下:
1private void completeBatch(ProducerBatch batch, ProduceResponse.PartitionResponse response, long correlationId, 2 long now, long throttleUntilTimeMs) {
3 Errors error = response.error;
4
5 //如果发送的消息太大,需要重新进行分割发送
6 if (error == Errors.MESSAGE_TOO_LARGE && batch.recordCount > 1 &&
7 (batch.magic() >= RecordBatch.MAGIC_VALUE_V2 || batch.isCompressed())) {
8
9 this.accumulator.splitAndReenqueue(batch);
10 this.accumulator.deallocate(batch);
11 this.sensors.recordBatchSplit();
12
13 } else if (error != Errors.NONE) {
14
15 //发生了错误,如果此时可以retry(retry次数未达到限制以及产生异常是RetriableException)
16 if (canRetry(batch, response)) {
17 if (transactionManager == null) {
18 //把需要重试的消息放入队列中,等待重试,实际就是调用deque.addFirst(batch)
19 reenqueueBatch(batch, now);
20 }
21 }
22}Producer发送消息的流程已经分析完毕,现在回过头去看流程图会更加清晰。
更多关于Kafka协议的涉及可以参考这个链接
分区算法
1List partitions = cluster.partitionsForTopic(topic); 2int numPartitions = partitions.size(); 3if (keyBytes == null) { 4 //如果key为null,则使用Round Robin算法 5 int nextValue = nextValue(topic); 6 List availablePartitions = cluster.availablePartitionsForTopic(topic); 7 if (availablePartitions.size() > 0) { 8 int part = Utils.toPositive(nextValue) % availablePartitions.size(); 9 return availablePartitions.get(part).partition();10 } else {11 // no partitions are available, give a non-available partition12 return Utils.toPositive(nextValue) % numPartitions;13 }14} else {15 // 根据key进行散列16 return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;17}Kafka中对于分区的算法有两种情况
如果键值为null,并且使用了默认的分区器,那么记录键随机地发送到主题内各个可用的分区上。分区器使用轮询(Round Robin)算法键消息均衡地分布到各个分区上。
如果键不为空,并且使用了默认的分区器,那么Kafka会对键进行散列(使用Kafka自己的散列算法,即使升级Java版本,散列值也不会发生变化),然后根据散列值把消息映射到特定的分区上。同一个键总是被映射到同一个分区上(如果分区数量发生了变化则不能保证),映射的时候会使用主题所有的分区,而不仅仅是可用分区,所以如果写入数据分区是不可用的,那么就会发生错误,当然这种情况很少发生。
如果你想要实现自定义分区,那么只需要实现Partitioner接口即可。
生产者的配置参数
分析了KafkaProducer的源码之后,我们会发现很多参数是贯穿在整个消息发送流程,下面列出了一些KafkaProducer中用到的配置参数。
acks
acks参数指定了必须要有多少个分区副本收到该消息,producer才会认为消息写入是成功的。有以下三个选项
acks=0,生产者不需要等待服务器的响应,也就是说如果其中出现了问题,导致服务器没有收到消息,生产者就无从得知,消息也就丢失了,当时由于不需要等待响应,所以可以以网络能够支持的最大速度发送消息,从而达到很高的吞吐量。
acks=1, 只需要集群的leader收到消息,生产者就会收到一个来自服务器的成功响应。如果消息无法到达leader,生产者会收到一个错误响应,此时producer会重发消息。不过如果一个没有收到消息的节点称为leader,消息还是会丢失。
acks=all,当所有参与复制的节点全部收到消息的时候,生产者才会收到一个来自服务器的成功响应,最安全不过延迟比较高。
buffer.memory
设置生产者内存缓冲区的大小,如果应用程序发送消息的速度超过生产者发送到服务器的速度,那么就会导致生产者空间不足,此时send()方法要么被阻塞,要么抛出异常。取决于如何设置max.block.ms,表示在抛出异常之前可以阻塞一段时间。
retries
发送消息到服务器收到的错误可能是可以临时的错误(比如找不到leader),这种情况下根据该参数决定生产者重发消息的次数。注意:此时要根据重试次数以及是否是RetriableException来决定是否重试。
batch.size
当有多个消息需要被发送到同一个分区的时候,生产者会把他们放到同一个批次里面(Deque),该参数指定了一个批次可以使用的内存大小,按照字节数计算,当批次被填满,批次里的所有消息会被发送出去。不过生产者并不一定会等到批次被填满才发送,半满甚至只包含一个消息的批次也有可能被发送。
linger.ms
指定了生产者在发送批次之前等待更多消息加入批次的时间。KafkaProducer会在批次填满或linger.ms达到上限时把批次发送出去。把linger.ms设置成比0大的数,让生产者在发送批次之前等待一会儿,使更多的消息加入到这个批次,虽然这样会增加延迟,当时也会提升吞吐量。
max.block.ms
指定了在调用send()方法或者partitionsFor()方法获取元数据时生产者的阻塞时间。当生产者的发送缓冲区已满,或者没有可用的元数据时,这些方法就会阻塞。在阻塞时间达到max.block.ms时,就会抛出new TimeoutException("Failed to allocate memory within the configured max blocking time " + maxTimeToBlockMs + " ms.");
client.id
任意字符串,用来标识消息来源,我们的后台线程就会根据它来起名儿,线程名称是kafka-producer-network-thread|{client.id}
max.in.flight.requests.per.connection
该参数指定了生产者在收到服务器响应之前可以发送多少个消息。它的值越高,就会占用越多的内存,不过也会提升吞吐量。把它设为1可以保证消息是按照发送的顺序写入服务器的,即便发生了重试。
timeout.ms、request.timeout.ms和metadata.fetch.timeout.ms
request.timeout.ms指定了生产者在发送数据时等待服务器返回响应的时间,metadata.fetch.timeout.ms指定了生产者在获取元数据(比如目标分区的leader)时等待服务器返回响应的时间。如果等待响应超时,那么生产者要么重试发送数据,要么返回一个错误。timeout.ms指定了broker等待同步副本返回消息确认的时间,与asks的配置相匹配——如果在指定时间内没有收到同步副本的确认,那么broker就会返回一个错误。
max.request.size
该参数用于控制生产者发送的请求大小。broker对可接收的消息最大值也有自己的限制(message.max.bytes),所以两边的配置最好可以匹配,避免生产者发送的消息被broker拒绝。
receive.buffer.bytes和send.buffer.bytes
这两个参数分别制定了TCP socket接收和发送数据包的缓冲区大小(和broker通信还是通过socket)。如果他们被设置为-1,就使用操作系统的默认值。如果生产者或消费者与broker处于不同的数据中心,那么可以适当增大这些值,因为跨数据中心的网络一般都有比较高的延迟和比较低的带宽。















 709
709











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









