





深度学习是当今最火的研究方向之一。它以其卓越的学习能力,实现了AI的关键功能。

一般来说,深度学习一次肯定是不够的,那到底学习多少次合适呢?
翻了翻各位大牛的研究成果,有训练10个迭代的,有30个,甚至也有1万个以上的。
这就让小白迷茫了,到底训练多少次合适?训练的检验标准是什么?
有一些大牛上来直接就说训练多少次,也不解释为什么,就说是凭经验,这种我们学不来。还有一些专家给出了一些理由,我们来总结一下。
01 当loss值收敛时结束迭代
深度学习的一个关键原理就是比较学习结果和样本标签之间的差距。理论上差距越小,表明学习的效果越好。这个差距就是loss值。
Loss值不可能变为0,只能无限逼近0。所以通过脚趾都能想到,当loss值无法变小的时候,这称为收敛,就是学习结束之时。比如像下图这样的:
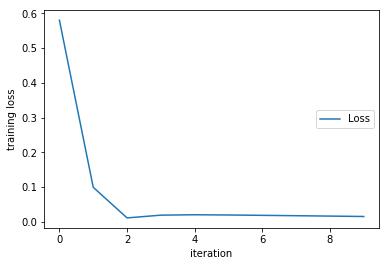
02 使用验证集来检验训练成果
你以为就靠一个收敛就能解决一切问题吗?没那么简单。
深度学习常常会遇到一个问题——过拟合。训练的时候学习效果很好,但是拿到其它地方测试发现效果就不行了。
就是说,并不一定是学习效果最好的时候才停止。那如何来判断停止的时机呢?
有学者提出了验证集。
就是说,把训练集分为2部分,比如70%用来训练,30%用来验证。就像下面的代码。
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.33, random_state=seed)
然后在训练时加入验证的参数,就像这样:
autoencoder.fit(train_data, train_data,
epochs=50,
batch_size=128,
shuffle=True,
validation_data=(noisy_imgs, data_test)
)
然后就是观察验证曲线,什么时候验证的loss值最小,就选那一次的训练模型进行测试应用。
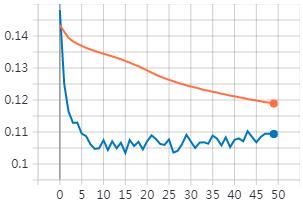
比如下图,上面是训练曲线,下面是验证曲线。学习15次的效果就已经比较好了。
03 使用测试集来检验训练成果
随着研究的广泛开展和对学习效果的极致追求,我们渐渐发现了一个问题——有时候从验证曲线看到的最优值并不是真实预测过程的最好效果。比如这种情况:对大尺度数据进行深度学习去噪。
先说结论:最优方法是通过测试效果来决定迭代的次数。
具体怎样做的呢?比如这样的案例:一张大的二维数据,比如300*300,像这样的:
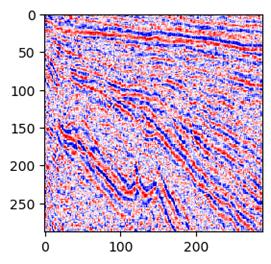
为了训练效率,我们一般是要切割为小数据块的,比如切割成28*28,像这样的:

当对这样的小块进行50次训练后,曲线是这样的(上为训练loss,下为验证loss):
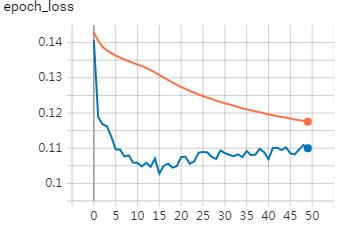
那第15次迭代的网络模型用来做真实数据的预测效果是这样的:
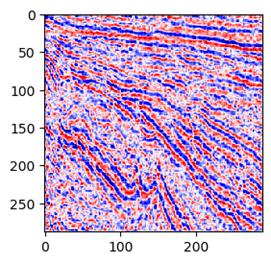
接下来,我们要写测试代码。
首先,在训练代码中增加回调函数,如MyCallback():
autoencoder.fit(train_data, train_data,
epochs=50,
batch_size=128,
shuffle=True,
validation_data=(noisy_imgs,data_test),
callbacks=[TensorBoard(log_dir='tmp/autoencoder'),MyCallback()])
然后,自己在回调函数中写测试效果的代码,比如以PSNR来检验预测效果。
class MyCallback(Callback):
def on_epoch_end(self, epoch, logs={}):
reconstructed = autoencoder.predict(noisy_imgs)
。。。。。。
这样在训练50次后,可以看到测试的曲线是这样的(PSNR值越大越好):
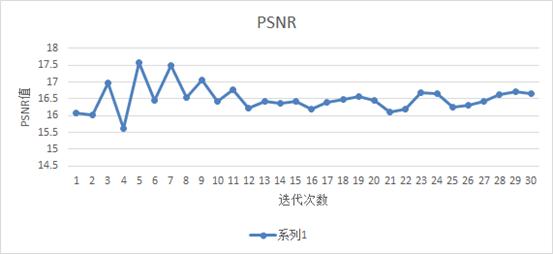
这样看来,学习迭代5次就足够了。效果是这样的:
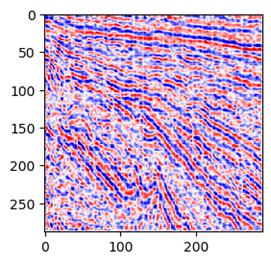
04 小结
为什么会出现上面的问题呢?初步判断和局部与全局学习有关系,具体的原因还待以后来研究。
看来深度学习的复杂性远远超乎我们想象。不过本着实事求是的态度总没有错。我们的目标就是用网络模型做出更好的预测效果,所以能实现这个目标的方法都是好方法。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









