






1. Async I/O介绍
由上文可以发现,需要解决维表join的问题,我们可以采用两种方式来进行,一是Async I/O,二是AsyncSourceTable,今天我们先来聊一下Async I/O吧。
异步方法,通常是用来提供系统吞吐的一种方式,与同步方法不同的在于其支持的qps会高很多,同理,在flink去查找外部维表的过程中需要引入外部数据库来进行查询,那么无可避免,在大多数情况下,I / O访问是一个耗时的过程,这使得单个operator的TPS远远低于内存中计算的TPS,特别是对于流作业而言。而低延迟是每个用户都会关心的问题,特别是对于流作业。启动多个线程可能是解决此问题的一种选择,但是缺点也很明显:最终用户的编程模型可能会变得更加复杂,因为他们必须在operator中实现多线程model。此外,他们必须注意与多线程模型与checkpoint进行协调。肯定会引入很多问题,下来就flink支持的异步IO我们具体展开。
1.1 异步处理原理
流中的记录在异步处理中如何与checkpoint进行交互是我们必须去关注的一个问题,下图将展示具体的流程:
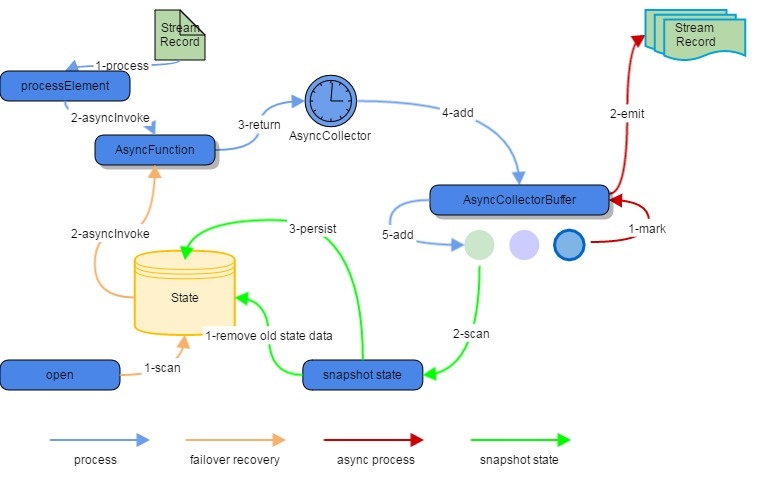
从上图可以看出,具体的操作流程如下:
- 蓝色线条为正常的异步处理流程,从异步接受到异步的function后,之后再按照‘顺序’收集到异步collector中,之后添加到异步buffer中;
- 红色部分是异步处理的环节,会将异步完成的buffer标记好,最后异步发送到流中去;
- 绿色的线条是状态保存的流程,先在state中去清除掉旧的状态,然后异步buffer阶段将完成的buffer的记录状态同步到快照中,快照下来持久化到state中,即完成该阶段;
- 橙色部分是用于失败处理试的流程,在发生处理失败时,会从open方法里初始化state中存储的状态信息,然后获取状态信息后,重新进行异步function,进行数据重新查询。
接着,我们看一下具体的类的执行顺序图:
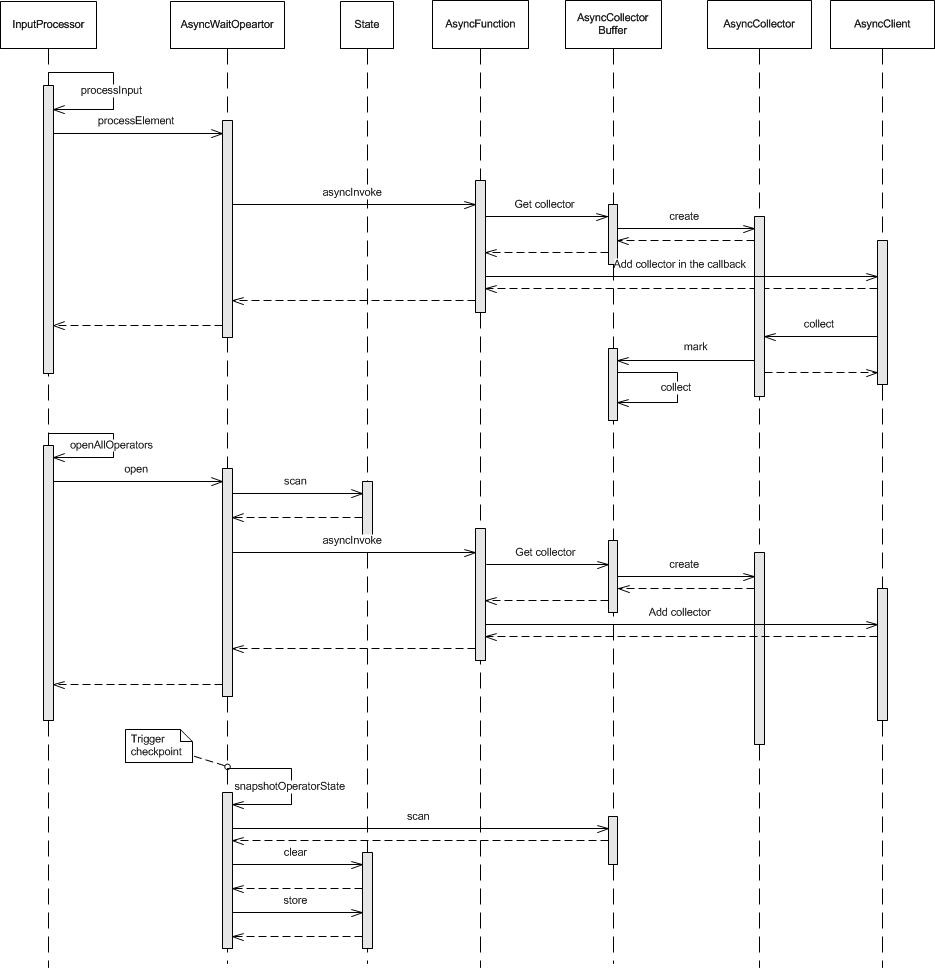
其实可以发现,处理的流程是与上图完全一致的,只是通过类执行的顺序,会对细节更多的了解。
1.2 异步function
AsyncFunction 在AsyncWaitOperator中充当用户函数,AsyncWaitOperator类似于StreamFlatMap算子,有open()、 processElement(StreamRecord <IN>record)、 processWatermark(Watermark mark)等方法。用户创建的AsyncFunction,asyncInvoke方法内必须是异步操作方法。所以这部分大家需要注意下,不能再是常规的同步客户端方式啦,在这里,我尝试用过同步的客户端来实现异步方法的调用,但很不幸,失败了,会产生netty的rpc调用问题,大概猜想是因为异步方法发送过后,并没立马查询,而同步方法则是立刻查询完返回结果,而后正常的异步方法查询时发现这个结果已经success啦,从而本次查询会出问题。
在AsyncWaitOperator中,所有record都会被异步function的asyncInvoke方法处理名之后,AsyncCollector会收集这些完成record,下来将这个集合会被添加到AsyncCollectorBuffer中。这里的collector其实就是一个future对象,他会在我们处理完回调时或者产生异常回调时产生作用,对啦,它里面还可以收集错误或者失败的信息,但这些逻辑需要大家在回调方法中完成。
1.3 异步CollectorBuffer
AsyncCollectorBuffer保留所有AsyncCollector,并将结果发送到下一个节点。在调用AsyncCollector.collect()时,将在AsyncCollectorBuffer中放置一个标记,用于标记已完成的AsyncCollectors。一旦AsyncCollector获得异步的结果,就会发出一个名为Emitter的线程,然后根据有序或无序的设置尝试发出结果。
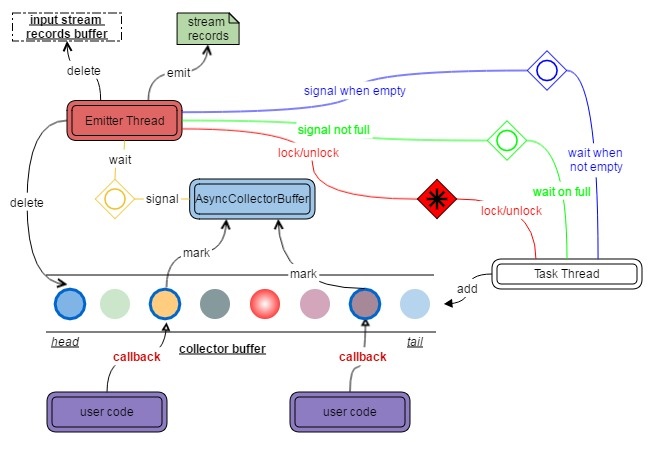
Ordered/Unordered
根据用户的配置来决定,保证或不保证元素的输出顺序。如果不能保证,则之后将已完成AsyncCollectors更早的发出。Emitter Thread
发送线程等待AsyncCollectors直至完成。在发送时,它将按以下方式处理缓冲区中的task:
有序模式:如果缓冲区中的第一个任务完成,则Emitter将收集其结果,然后继续执行第二个任务。如果第一个任务尚未完成,等待第一个完成后再收集。
无序模式:检查缓冲区中所有完成的任务,并从缓冲区中最早的watermark之前的那些任务中收集结果。
该发送线程和任务线程都将通过获取/释放锁来唯一地 获取访问权限。当所有任务完成时向任务线程发出信号,通知它所有数据都已处理,并且可以关闭操作员。从缓冲区中删除一些任务后,发出信号任务线程。将异常传播到任务线程。
Task Thread
与发射线程访问AsyncCollectorBuffer的方式不同的是任务线程用于获取并向缓冲区添加新的AsyncCollector,在缓冲区已满时进行等待。
Watermark
所有水印也将保留在AsyncCollectorBuffer中。当且仅当所有AsyncCollectors在当前老水印之前发出之后,才会发出新的水印。
1.4 异步容错
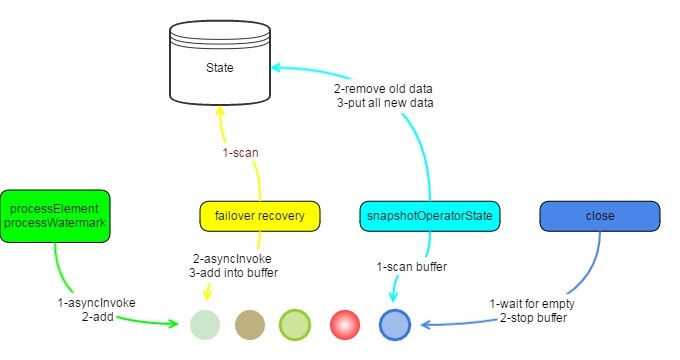
所有输入的StreamRecords将被保留在状态中。作为在处理中将每个输入流记录存储到state中的替代,AsyncWaitOperator将发送到AsyncCollectorBuffer的所有输入流记录到state中并且同时去做operator的状态快照。保留这些记录之前,将首先去清除该状态下的旧数据。当所有barrier到达该operator后,checkpoint便会开始进行。
在恢复operator的状态时,operator将扫描该状态下的所有元素,获取AsyncCollectors,调用AsyncFunction.asyncInvoke()并将它们重新放入AsyncCollectorBuffer中,至此,异常恢复成功,具体图示如下。
2. AsyncFunction异步实现
2.1 概念介绍
以上是flink1.2阿里贡献给flink社区的Async I/O,目前1.9版本或多或少会有些变化,但基本原理来看,异步的思想和方式没变。具体例子我们下来会给出,下面就当前版本的异步IO展开。
在我们的使用场景中,需要从外部数据库查询以来获取关联的用户维度信息,之后对该维度信息做处理。比如我们访问普通的MySQL数据库,那么常规实现方式是向MYSQL数据库发送用户a的查询请求,然后等待结果返回,在这之前,我们无法发送用户b的查询请求。这是一种同步访问的模式,如下图左边所示。
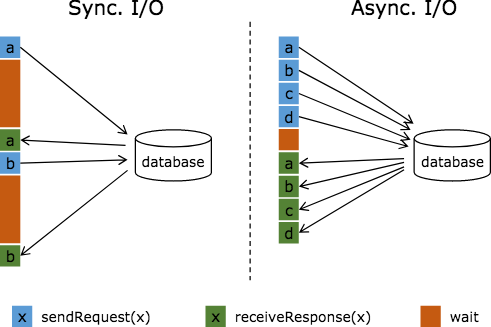
如果要利用我们上文讲的异步function来做,那么显然是先发送请求,别管结果,等后续再异步的收集到的结果发送出来即可。很重要的一个前提是,我们要有一个能够异步请求数据库的client,上文也有提及。之前说过自己实现线程池可以实现,但自己实现难免有所瑕疵,所以稳妥起见还是调用flink已经有的功能更靠谱一些。
2.2 顺序及容错
那么下来我们介绍1.9的Async I/O以下两个参数是异步操作中需要着重点出的:
Timeout:超时定义异步请求在被视为失败之前可能需要多长时间。此参数可防止死亡/失败请求。
Capacity:此参数定义可以同时进行的异步请求数。尽管异步I / O方法通常会带来更好的吞吐量,但异步I / O 的操作仍然可能成为流应用程序的瓶颈。限制并发请求的数量可确保操作不会不断累积,积压增加的待处理请求,一旦容量耗尽,它将触发反压。
超时处理
当异步I / O请求超时时,默认情况下会引发异常并重新启动作业。如果要处理超时,可以覆盖该AsyncFunction#timeout方法。
结果顺序
AsyncDataStream还是有orderWait和unorderWait两种方法:
有序:消息的发送顺序与接受到的顺序相同(包括 watermark ),也就是消息记录是先进先出的,这和1.2
的一样。异步请求完成后立即发出结果记录。在异步I / O运算符之后,流中记录的顺序与以前不同。在这种情况下,保留流顺序。结果记录的发出顺序与触发异步请求的顺序相同(运算符输入记录的顺序)。为此,运算符缓冲结果记录,直到其所有先前记录被发出(或超时)。这通常会在检查点中引入一些额外的延迟和一些开销,因为与无序模式相比,记录或结果在检查点状态下保持更长的时间。使用AsyncDataStream.orderedWait(...)此模式。-
无序:异步请求完成后立即发出结果记录。在异步I / O运算符之后,流中记录的顺序与以前不同。当使用处理时间作为基本时间特性时,此模式具有最低延迟和最低开销。使用AsyncDataStream.unorderedWait(...)此模式。这个看起来,跟1.2有些差异,主要是EventTime上,其实乍一看也是无序的,但这里的无序需要注意watermark的边界,也就是一个时间段内的消息是无序的。
- 在时间采用ProcessingTime的情况下,返回结果是完全无序的。
- 在时间采用EventTime的情况下,watermark 不能越过记录,反之亦然。也就是说watermark 建立了一个顺序的边界。在两个watermark 之间的消息的发送是无序的,但是在watermark之后的消息不能先于该watermark之前的消息发送。这意味着,我们将无序的方式转化成延迟相同且性能开销相同情况下的顺序模式。
注意事项
AsyncFunction不是为多线程,这个点大家需要注意下具体使用中的区别。它有且只存在一个instance,AsyncFunction并且对于流的相应分区中的每个记录顺序调用它,除非该asyncInvoke(...)方法快速返回回调函数的结果,否则它将不会产生异步I/O所应该得到的结果.例如,以下模式会导致阻塞asyncInvoke(...)函数,从而使异步行为无效:
- 使用其查找/查询方法调用阻塞的数据库客户端,直到收到结果为止,比如之前我在异步方法里使用同步的hbase客户端查询rowkey;
- 阻止/等待asyncInvoke(...)方法内异步客户端返回的future-type对象,自己逻辑里wait,直至有结果才notify。
2.3 源码追溯
根据AsyncDataStream.scala中的orderedWait和UnorderedWait方法,我们可以继续追踪到根据AsyncDataStream.java中的对应方法addOperator(),从而会得到一个核心类AsyncWaitOperator,其实这两个方法实际就是在创建该对象的一个实例。以下code是如何创建该实例的逻辑。
/**
* AsyncDataStream.scala中的orderedWait和UnorderedWait方法:
*/
public static <IN, OUT> SingleOutputStreamOperator<OUT> orderedWait(
DataStream<IN> in,
AsyncFunction<IN, OUT> func,
long timeout,
TimeUnit timeUnit,
int capacity) {
return addOperator(in, func, timeUnit.toMillis(timeout), capacity, OutputMode.ORDERED);
}
public static <IN, OUT> SingleOutputStreamOperator<OUT> unorderedWait(
DataStream<IN> in,
AsyncFunction<IN, OUT> func,
long timeout,
TimeUnit timeUnit,
int capacity) {
return addOperator(in, func, timeUnit.toMillis(timeout), capacity, OutputMode.UNORDERED);
}
/**
* AsyncDataStream.java中的addOperator方法:
*/
private static <IN, OUT> SingleOutputStreamOperator<OUT> addOperator(
DataStream<IN> in,
AsyncFunction<IN, OUT> func,
long timeout,
int bufSize,
OutputMode mode) {
TypeInformation<OUT> outTypeInfo = TypeExtractor.getUnaryOperatorReturnType(
func,
AsyncFunction.class,
0,
1,
new int[]{1, 0},
in.getType(),
Utils.getCallLocationName(),
true);
// create transform
AsyncWaitOperator<IN, OUT> operator = new AsyncWaitOperator<>(
in.getExecutionEnvironment().clean(func),
timeout,
bufSize,
mode);
return in.transform("async wait operator", outTypeInfo, operator);
}下来,我们看下这个类里面的一些逻辑,看下具体的调用关系。从AsyncWaitOperator类的成员变量上可以发现以下几个是比较重要的:
- OutputMode:该operator的输出模式,即有序和无序;
- StreamElementQueue:存储当前流里面正在处理的elem的异步队列;
- StreamElementQueueEntry:尚未被添加到queue中的待异步完成的elem队列;
- Emitter:将异步完成的队列数据发送出去。
StreamElementQueueEntry可以被认为还未完成的含有异步回调的elem队列,它允许队列元素完成时注册回调。这个抽象类包含两个实现类,分别是代表水印的WatermarkQueueEntry和代表数据元素的WatermarkQueueEntry。通过源代码,可以发现,他们核心方法都是集中在CompletableFuture上,最终也是通过该对象来返回我们的查询结果。具体的类图如下:
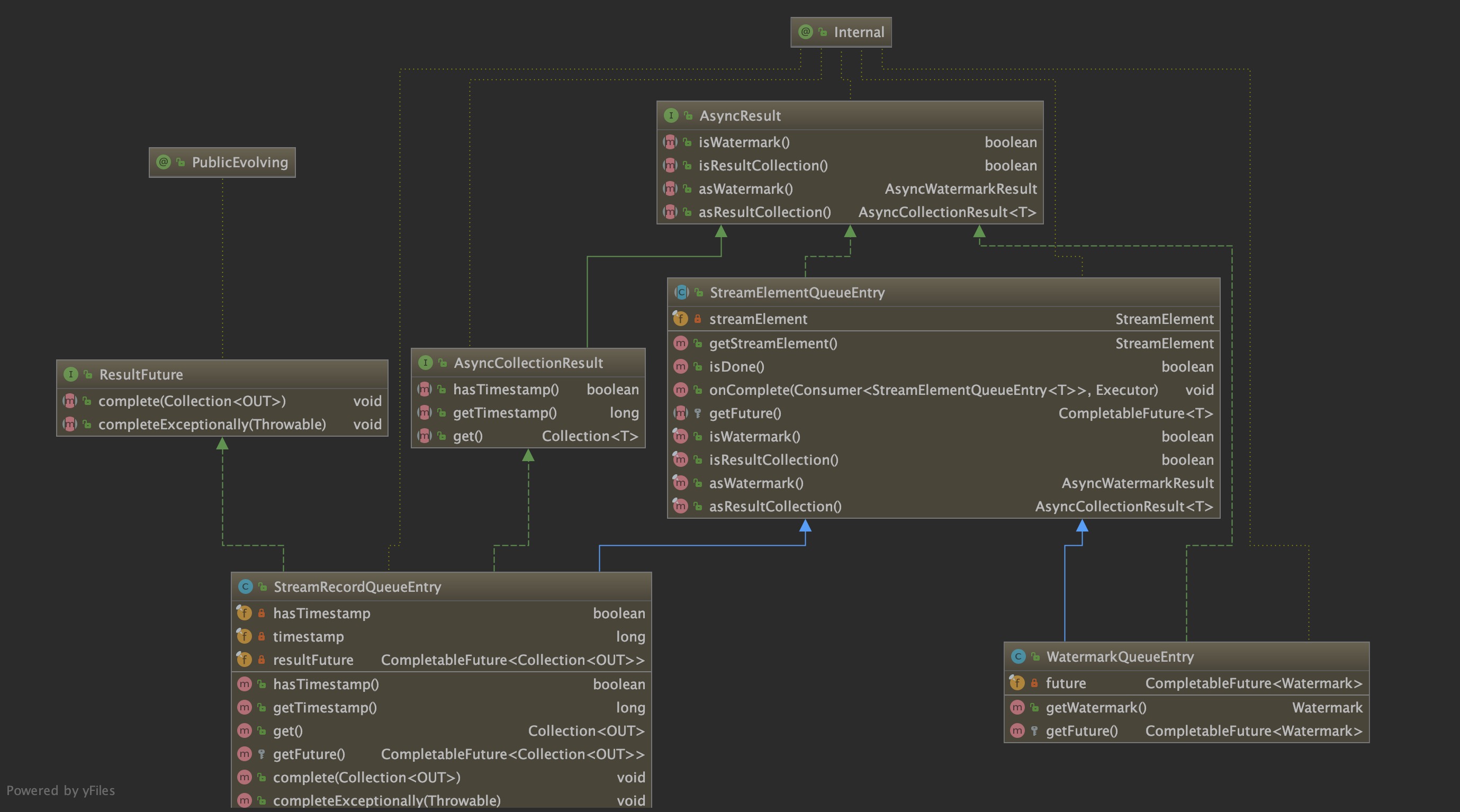
## 2.4 原理解析
根据AsyncWaitOperator类中执行流程,我们可以按照异步方式的实现原理结合顺序性yiji上文提及的time、watermark等方面来分析record是如何来进行流转的。
异步实现方式
首先,先看下异步方式实现方式:
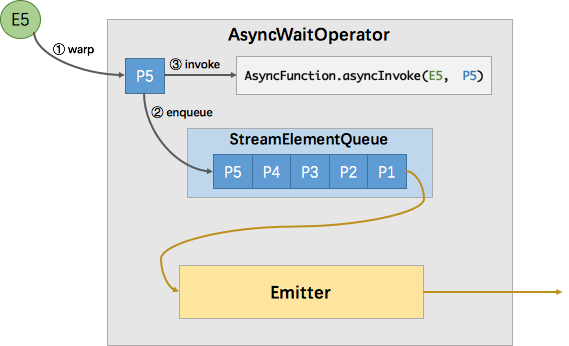
- 在E5消息进入operator后,它会被包装成StreamRecordQueueEntry--P5,即一个将来有值的异步抽象。
- 下来会把它放入到streamelementqueue队列中,最后调用asyncfunction.asyncinvoke方法,该方法会向外部服务发起一个异步的请求,并注册回调。
- 该回调会在异步请求成功返回时调用StreamRecordQueueEntry.complete()方法将返回的结果交给框架处理。如果返回结果出现异常则调用StreamRecordQueueEntrycompleteExceptionally()方法。
- 在该队列完成后,Emitter 就会从队列中拉取完成的element,并从其中取出消息发送给下游。
顺序模式
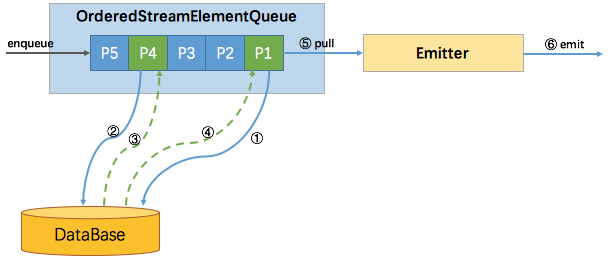
根据上文中提到的顺序模式,我们来分别讨论下在不同时间情况下的顺序问题。
有序时: 我们在EventTime和ProcessingTime时都一样,只需要将元素按照来的顺序放到OrderedStreamElementQueue中即可。只有当队列中的队头P1元素请求异步返回结果后,才会触发Emitter输出,后面的P4请求先返回结果也只能等待P1~P3发送后才能发送。
ProcessingTime无序时: 从图中可以看出,目前没有watermark介入,不需要我们考虑WatermarkQueueEntry中有关消息的顺序性问题,所以通过完成和未完成两个队列就能实现,所以新进入的元素包装成StreamRecordQueueEntry后放到uncompletedQueue中,当uncompletedQueue中的任一元素返回数据后,则将其移动到completedQueue中,并通知Emitter来拉取元素。
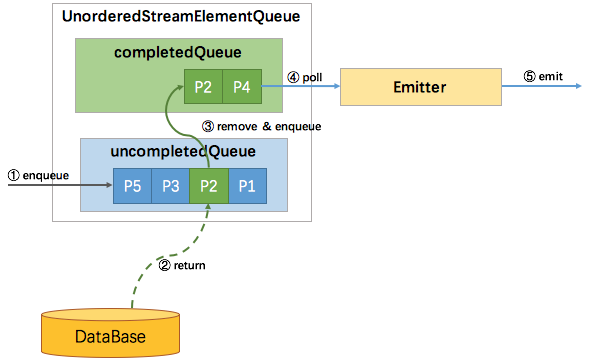
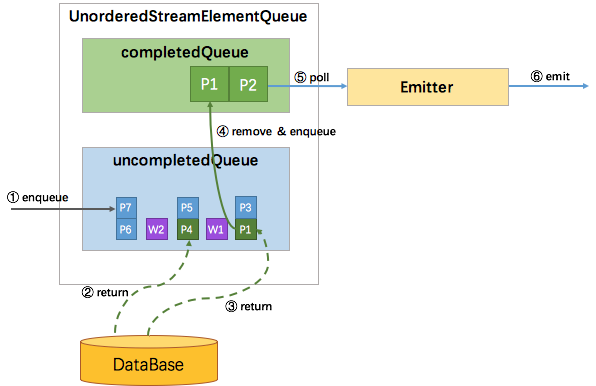
EventTime无序时:
eventtime中会持有watermark,所以需要处理record与watermark之间的顺序,在两个watermark之间,我们需要处理的元素会变成一个个元素集,而watermark也会被包装成WatermarkQueueEntry来按照进入uncompletedQueue的顺序放置到uncompletedQueue中。那么如此情况下,watermark便成为了消息顺序的边界,在处于队列中队首的集合中的元素返回后,才会将该元素移动到completedQueue中去。等队首集合全部完成后,再发送watermark-W1,下来才能发送W1后面的P4-P5集合元素。这样就保证了当这个watermark发送之前,它前面的所有异步请求都发送。这样看起来watermark作为一个顺序性的控制要素来存在的,在两个watermark之间,其实数据是无序的,而从总体来看,却是有序的。
也就是说由watermark的顺序性保证了总体的顺序,而乱序仅发生在区间之内。
容错:
异步I/O的检查点通过AsyncWaitOperator.snapshotState来做,其载体是StreamElementQueue,已经完成回调并且已经发往下游的元素是不需要快照的。所以该队列中存储的是已完成异步请求但还未发送到Emitter的元素,加上未完成回调的元素,就是上述队列中的所有元素。该快照的执行逻辑如下:
- 清空原有的状态存储;
- 遍历队列中的所有element,从中取出 StreamElement(record或 watermark)并放入状态存储
partitionableState中; - 执行快照操作;
恢复的时候,类似于上述的容错恢复情况,先从state中读取所有的元素再次处理一遍,这里面已完成异步请求但尚未发送到Emitter的元素在失败恢复后,会重复请求外部服务,但每个回调的结果只会被发往下游一次。
3. 异步加载Hbase
在完成所有的异步IO原理及流程后,下来我们聚焦于具体的实现上,这里,一般来讲维度表不会太大,所有理论上我们可以放到MySQL这种关系型数据库中,但考虑到由于并发问题,这里还是尽量避免使用。着重会考虑下redis和hbase两种kv的数据库,使用hbase的场景是存储字段较多时,而redis适用于简单的数据结构。下来在第三章和第四章就这两者来实现。
class AsyncIOHbaseFunction(zk: String, tableName: String, maxSize: Long, ttl: Long) extends RichAsyncFunction[Row, Row] with Serializable {
private val config: Config = ConfigFactory.load()
private var hbaseClient: HBaseClient = _
private var cache: Cache[String, String] = _
// 初始化hbase 并添加lru缓存
override def open(parameters: Configuration): Unit = {
hbaseClient = new HBaseClient(config.getString("zkAddress"))
cache = CacheBuilder.newBuilder()
.maximumSize(maxSize)
.expireAfterWrite(ttl, TimeUnit.SECONDS)
.build()
}
// 异步获取hbase中的数据,先去缓存中查找
override def asyncInvoke(input: Row, resultFuture: ResultFuture[Row]): Unit = {
val key = parseKey(input)
log.info(String.format("get dimension key : %s", key))
val value = cache.getIfPresent(key)
if (null != value) {
val totalRow = fillData(input, value)
resultFuture.complete(Collections.singleton(totalRow).asScala)
} else {
val get = new GetRequest(tableName, key)
hbaseClient.get(get).addCallbacks(new Callback[String, util.ArrayList[KeyValue]] {
override def call(t: util.ArrayList[KeyValue]): String = {
val v = parseRs(t)
cache.put(key, v)
val totalRow = fillData(input, v)
log.info(String.format("get dimension attr in hbase success: %s", totalRow.toString))
resultFuture.complete(Collections.singleton(totalRow).asScala)
"complete async find ! "
}
}, new Callback[String, Exception] {
override def call(t: Exception): String = {
val errorException = String.format("get dimension attribute from hbase error: %s", t.toString)
t.printStackTrace()
resultFuture.complete(Collections.singleton(Row.of(errorException)).asScala)
"complete async error ! "
}
})
}
}
}4. 异步加载Redis
class AsyncIORedisFunction(host: String, pwd: String, maxSize: Long, ttl: Int) extends RichAsyncFunction[Row, Row]
with Serializable {
private var redisClient: RedisClient = _
private var cache: Cache[String, String] = _
// 初始化hbase 并添加lru缓存
override def open(parameters: Configuration): Unit = {
super.open(parameters)
//初始化redis参数
val config: RedisOptions = new RedisOptions
config.setHost(host)
config.setSelect(7)
config.setAuth(pwd)
config.setConnectTimeout(ttl)
val vo = new VertxOptions()
vo.setEventLoopPoolSize(10)
vo.setWorkerPoolSize(20)
val vertx = Vertx.vertx(vo)
redisClient = RedisClient.create(vertx, config)
//创建guava cache
cache = CacheBuilder.newBuilder()
.maximumSize(maxSize)
.expireAfterWrite(ttl, TimeUnit.SECONDS)
.build()
}
// 异步获取redis中的数据,先去缓存中查找
override def asyncInvoke(input: Row, resultFuture: ResultFuture[Row]): Unit = {
try {
val key = parseKey(input)
val value = cache.getIfPresent(key)
if ( null != value) {
resultFuture.complete(Collections.singletonList(Row.of(input,value)).asScala)
return
} else {
redisClient.get(key, new Handler[AsyncResult[String]] {
override def handle(e: AsyncResult[String]): Unit = {
if (e.succeeded) {
val result = e.result
if (result == null) {
resultFuture.complete(null)
return
} else {
cache.put(key, result)
resultFuture.complete(Collections.singletonList(Row.of(input,value)).asScala)
}
}
else if (e.failed) {
resultFuture.complete(null)
return
}
}
})
return
}
} catch {
case e: Exception => e.printStackTrace()
}
}
private def parseKey(input: Row): String = {
val userId = input.getField(0)
val time = input.getField(1)
s"$userId-$time"
}
private def fillData(input: String, value: String): String = {
""
}
}5.主逻辑
//使用异步I/O的方式来进行维表查询
val asyncHbase = new AsyncIOHbaseFunction(zk, dimTableName, maxSize, ttl)
var hbaseSideStream: DataStream[Row] = null
try {
if (orderFlag)
hbaseSideStream = AsyncDataStream
.orderedWait(stuStateStream, asyncHbase, 6000L, TimeUnit.MILLISECONDS, 20)
.uid("order-async-join")
.name("orderAsyncJoin")
.setParallelism(midParallelism)
else
hbaseSideStream = AsyncDataStream
.unorderedWait(stuStateStream, asyncHbase, 6000L, TimeUnit.MILLISECONDS, 20)
.uid("unorder-async-join")
.name("unOrderAsyncJoin")
.setParallelism(midParallelism)
} catch {
case e: Exception => log.error(s"get Async I/O error: $e")
}
//注册成表进行SQL查询
val sideSchema = sideTypeInfo.getFieldNames.mkString(",") + ",proctime.proctime"
tableEnv.registerDataStream("hbase_side_input", hbaseSideStream, sideSchema)
tableEnv.sqlQuery("select * from hbase_side_input")
table.addSink(new UserLayHbaseSink(mutatorMap,labTable,family,qualifier))
.setParallelism(sinkParallelism)
.uid("labSink")
.name("label-sink")后记
本篇主要是结合了flink1.2和1.9的两种异步IO的实现方式来展开阐述,其中必然会有理解不到位的地方,各位大佬还请见谅,如果有问题的地方,直接私信联系。后续一篇会结合flink1.9中的blink-planner来讲述LookupTableSource在维表join中的一些使用。感谢捧场,回见,您嘞!\(^∀^)メ(^∀^)ノ
参考文章:https://www.jianshu.com/p/98ffb9ad0177http://wuchong.me/blog/2017/05/17/flink-internals-async-io/https://cwiki.apache.org/confluence/pages/viewpage.action?pageId=65870673















 960
960











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









