





前言
在上一篇文章《Android图形渲染原理(上)》里,我详细的讲解了图像消费者,我们已经了解了Android中的图像元数据是如何被SurfaceFlinger,HWComposer或者OpenGL ES消费的,那么,图像元数据又是怎么生成的呢?这一篇文章就来详细介绍Android中的图像生产者——SKIA,OPenGL ES,Vulkan,他们是Android中最重要的三支画笔。

图像生产者
OpenGL ES
什么是OpenGL呢?OpenGL是一套图像编程接口,对于开发者来说,其实就是一套C语言编写的API接口,通过调用这些函数,便可以调用显卡来进行计算机的图形开发。虽然OpenGL是一套API接口,但它并没有具体的实现这些接口,接口的实现是由显卡的驱动程序来完成的。在前一篇文章中介绍过,显卡驱动是其他模块和显卡沟通的入口,开发者通过调用OpenGL的图像编程接口发出渲染命令,这些渲染命令被称为DrawCall,显卡驱动会将渲染命令翻译能GPU能理解的数据,然后通知GPU读取数据进行操作。OpenGL ES又是什么呢?它是为了更好的适应嵌入式等硬件较差的设备,推出的OpenGL的剪裁版,基本和OpenGL是一致的。Android从4.0开始默认开启硬件加速,也就是默认使用OpenGL ES来进行图形的生成和渲染工作。
我们接着来看看如何使用OpenGL ES。
如何使用OpenGL ES?
想要在Android上使用OpenGL ES,我们要先了解EGL。OpenGL虽然是跨平台的,但是在各个平台上也不能直接使用,因为每个平台的窗口都是不一样的,而EGL就是适配Android本地窗口系统和OpenGL ES桥接层。
OpenGL ES 定义了平台无关的 GL 绘图指令,EGL则定义了控制 displays,contexts 以及 surfaces 的统一的平台接口
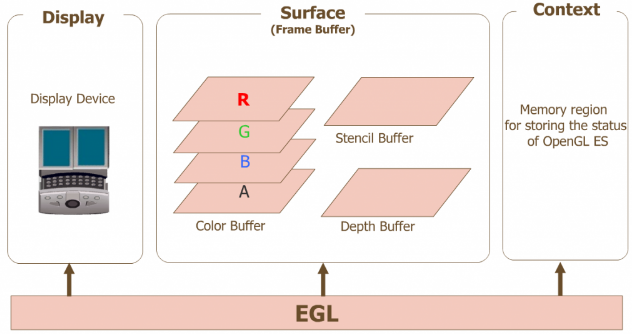
那么如何使用EGL和OpenGL ES生成图形呢?其实比较简单,主要有这三步
EGL初始化Display,Context和Surface
OpenGL ES调用绘制指令
EGL提交绘制后的buffer
我们详细来看一下每一步的流程
1,EGL进行初始化:主要初始化Display,Context 和Surface三个元素就可以了。
Display(EGLDisplay) 是对实际显示设备的抽象
//创建于本地窗口系统的连接EGLDisplay display = eglGetDisplay(EGL_DEFAULT_DISPLAY);//初始化displayeglInitialize(display, NULL, NULL);Context (EGLContext) 存储 OpenGL ES绘图的一些状态信息
/* create an EGL rendering context */context = eglCreateContext(display, config, EGL_NO_CONTEXT, NULL);Surface(EGLSurface)是对用来存储图像的内存区域
//设置Surface配置eglChooseConfig(display, attribute_list, &config, 1, &num_config);//创建本地窗口native_window = createNativeWindow();//创建surfacesurface = eglCreateWindowSurface(display, config, native_window, NULL);初始化完成后,需要绑定上下文
//绑定上下文eglMakeCurrent(display, surface, surface, context);2,OpenGL ES调用绘制指令:主要通过使用 OpenGL ES API ——gl_*(),接口进行绘制图形
//绘制点glBegin(GL_POINTS); glVertex3f(0.7f,-0.5f,0.0f); //入参为三维坐标 glVertex3f(0.6f,-0.7f,0.0f); glVertex3f(0.6f,-0.8f,0.0f);glEnd();//绘制线glBegin(GL_LINE_STRIP); glVertex3f(-1.0f,1.0f,0.0f); glVertex3f(-0.5f,0.5f,0.0f); glVertex3f(-0.7f,0.5f,0.0f);glEnd();//……3,EGL提交绘制后的buffer:通过eglSwapBuffer()进行双缓冲buffer的切换
EGLBoolean res = eglSwapBuffers(mDisplay, mSurface);swapBuffer切换缓冲区buffer后,显卡就会对Buffer中的图像进行渲染处理。此时,我们的图像就能显示出来了。
我们看一个完整的使用流程Demo
#include #include #include #include typedef ... NativeWindowType;extern NativeWindowType createNativeWindow(void);static EGLint const attribute_list[] = { EGL_RED_SIZE, 1, EGL_GREEN_SIZE, 1, EGL_BLUE_SIZE, 1, EGL_NONE};int main(int argc, char ** argv){ EGLDisplay display; EGLConfig config; EGLContext context; EGLSurface surface; NativeWindowType native_window; EGLint num_config; /* get an EGL display connection */ display = eglGetDisplay(EGL_DEFAULT_DISPLAY); /* initialize the EGL display connection */ eglInitialize(display, NULL, NULL); /* get an appropriate EGL frame buffer configuration */ eglChooseConfig(display, attribute_list, &config, 1, &num_config); /* create an EGL rendering context */ context = eglCreateContext(display, config, EGL_NO_CONTEXT, NULL); /* create a native window */ native_window = createNativeWindow(); /* create an EGL window surface */ surface = eglCreateWindowSurface(display, config, native_window, NULL); /* connect the context to the surface */ eglMakeCurrent(display, surface, surface, context); /* clear the color buffer */ glClearColor(1.0, 1.0, 0.0, 1.0); glClear(GL_COLOR_BUFFER_BIT); glFlush(); eglSwapBuffers(display, surface); sleep(10); return EXIT_SUCCESS;}介绍完EGL和OpenGL的使用方式了,我们可以开始看Android是如何通过它进行界面的绘制的,这里会列举两个场景:开机动画,硬件加速来详细的讲解OpenGL ES作为图像生产者,是如何生产,即如何绘制图像的。
OpenGL ES播放开机动画
当Android系统启动时,会启动Init进程,Init进程会启动Zygote,ServerManager,SurfaceFlinger等服务。随着SurfaceFlinger的启动,我们的开机动画也会开始启动。先看看SurfaceFlinger的初始化函数。
//文件-->/frameworks/native/services/surfaceflinger/SurfaceFlinger.cppvoid SurfaceFlinger::init() { ... mStartBootAnimThread = new StartBootAnimThread(); if (mStartBootAnimThread->Start() != NO_ERROR) { ALOGE("Run StartBootAnimThread failed!"); }}//文件-->/frameworks/native/services/surfaceflinger/StartBootAnimThread.cppstatus_t StartBootAnimThread::Start() { return run("SurfaceFlinger::StartBootAnimThread", PRIORITY_NORMAL);}bool StartBootAnimThread::threadLoop() { property_set("service.bootanim.exit", "0"); property_set("ctl.start", "bootanim"); // Exit immediately return false;}从上面的代码可以看到,SurfaceFlinger的init函数中会启动BootAnimThread线程,BootAnimThread线程会通过property_set来发送通知,它是一种Socket方式的IPC通信机制,对Android IPC通信感兴趣的可以看看我的这篇文章《Android进程间通信机制》,这里就不过多讲解了。init进程会接收到bootanim的通知,然后启动我们的动画线程BootAnimation。
了解了前面的流程,我们开始看BootAnimation这个类,Android的开机动画的逻辑都在这个类中。我们先看看构造函数和onFirsetRef函数,这是这个类创建时最先执行的两个函数:
//文件-->/frameworks/base/cmds/bootanimation/BootAnimation.cppBootAnimation::BootAnimation() : Thread(false), mClockEnabled(true), mTimeIsAccurate(false), mTimeFormat12Hour(false), mTimeCheckThread(NULL) { //创建SurfaceComposerClient mSession = new SurfaceComposerClient(); //……}void BootAnimation::onFirstRef() { status_t err = mSession->linkToComposerDeath(this); if (err == NO_ERROR) { run("BootAnimation", PRIORITY_DISPLAY); }}构造函数中创建了SurfaceComposerClient,SurfaceComposerClient是SurfaceFlinger的客户端代理,我们可以通过它来和SurfaceFlinger建立通信。构造函数执行完后就会执行onFirsetRef()函数,这个函数会启动BootAnimation线程
接着看BootAnimation线程的初始化函数readyToRun。
//文件-->/frameworks/base/cmds/bootanimation/BootAnimation.cppstatus_t BootAnimation::readyToRun() { mAssets.addDefaultAssets(); sp dtoken(SurfaceComposerClient::getBuiltInDisplay( ISurfaceComposer::eDisplayIdMain)); DisplayInfo dinfo; //获取屏幕信息 status_t status = SurfaceComposerClient::getDisplayInfo(dtoken, &dinfo); if (status) return -1; // 通知SurfaceFlinger创建Surface,创建成功会返回一个SurfaceControl代理 sp control = session()->createSurface(String8("BootAnimation"), dinfo.w, dinfo.h, PIXEL_FORMAT_RGB_565); SurfaceComposerClient::openGlobalTransaction(); //设置这个layer在SurfaceFlinger中的层级顺序 control->setLayer(0x40000000); //获取surface sp s = control->getSurface(); // 以下是EGL的初始化流程 const EGLint attribs[] = { EGL_RED_SIZE, 8, EGL_GREEN_SIZE, 8, EGL_BLUE_SIZE, 8, EGL_DEPTH_SIZE, 0, EGL_NONE }; EGLint w, h; EGLint numConfigs; EGLConfig config; EGLSurface surface; EGLContext context; //步骤1:获取Display EGLDisplay display = eglGetDisplay(EGL_DEFAULT_DISPLAY); //步骤2:初始化EGL eglInitialize(display, 0, 0); //步骤3:选择参数 eglChooseConfig(display, attribs, &config, 1, &numConfigs); //步骤4:传入SurfaceFlinger生成的surface,并以此构造EGLSurface surface = eglCreateWindowSurface(display, config, s.get(), NULL); //步骤5:构造egl上下文 context = eglCreateContext(display, config, NULL, NULL); //步骤6:绑定EGL上下文 if (eglMakeCurrent(display, surface, surface, context) == EGL_FALSE) return NO_INIT; //……}通过readyToRun函数可以看到,里面主要做了两件事情:初始化Surface,初始化EGL,EGL的初始化流程和上面OpenGL ES使用中讲的流程是一样的,这里就不详细讲了,主要简单介绍一下Surface初始化的流程,详细的流程会在下一篇文章图像缓冲区中讲,它的步骤如下:
创建SurfaceComponentClient
通过SurfaceComponentClient通知SurfaceFlinger创建Surface,并返回SurfaceControl
有了SurfaceControl之后,我们就可以设置这块Surface的层级等属性,并能获取到这块Surface。
获取到Surface后,将Surface绑定到EGL中去
Surface也创建好了,EGL也创建好了,此时我们就可以通过OpenGL来生成图像——也就是开机动画了,我们接着看看线程的执行方法threadLoop函数中是如何播放的动画的。
//文件-->/frameworks/base/cmds/bootanimation/BootAnimation.cppbool BootAnimation::threadLoop(){ bool r; if (mZipFileName.isEmpty()) { r = android(); //Android默认动画 } else { r = movie(); //自定义动画 } //动画播放完后的释放工作 eglMakeCurrent(mDisplay, EGL_NO_SURFACE, EGL_NO_SURFACE, EGL_NO_CONTEXT); eglDestroyContext(mDisplay, mContext); eglDestroySurface(mDisplay, mSurface); mFlingerSurface.clear(); mFlingerSurfaceControl.clear(); eglTerminate(mDisplay); eglReleaseThread(); IPCThreadState::self()->stopProcess(); return r;}函数中会判断是否有自定义的开机动画文件,如果没有就播放默认的动画,有就播放自定义的动画,播放完成后就是释放和清除的操作。默认动画和自定义动画的播放方式其实差不多,我们以自定义动画为例,看看具体的实现流程。
//文件-->/frameworks/base/cmds/bootanimation/BootAnimation.cppbool BootAnimation::movie(){ //根据文件路径加载动画文件 Animation* animation = loadAnimation(mZipFileName); if (animation == NULL) return false; //…… glBlendFunc(GL_SRC_ALPHA, GL_ONE_MINUS_SRC_ALPHA); // 调用OpenGL清理屏幕 glShadeModel(GL_FLAT); glDisable(GL_DITHER); glDisable(GL_SCISSOR_TEST); glDisable(GL_BLEND); glBindTexture(GL_TEXTURE_2D, 0); glEnable(GL_TEXTURE_2D); glTexEnvx(GL_TEXTURE_ENV, GL_TEXTURE_ENV_MODE, GL_REPLACE); glTexParameterx(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_REPEAT); glTexParameterx(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_REPEAT); glTexParameterx(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR); glTexParameterx(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR); //…… //播放动画 playAnimation(*animation); //…… //释放动画 releaseAnimation(animation); return false;}movie函数主要做的事情如下
通过文件路径加载动画
调用OpenGL做清屏操作
调用playAnimation函数播放动画。
停止播放动画后通过releaseAnimation释放资源
我们接着看playAnimation函数
//文件-->/frameworks/base/cmds/bootanimation/BootAnimation.cppbool BootAnimation::playAnimation(const Animation& animation){ const size_t pcount = animation.parts.size(); nsecs_t frameDuration = s2ns(1) / animation.fps; const int animationX = (mWidth - animation.width) / 2; const int animationY = (mHeight - animation.height) / 2; //遍历动画片段 for (size_t i=0 ; i const Animation::Part& part(animation.parts[i]); const size_t fcount = part.frames.size(); glBindTexture(GL_TEXTURE_2D, 0); // Handle animation package if (part.animation != NULL) { playAnimation(*part.animation); if (exitPending()) break; continue; //to next part } //循环动画片段 for (int r=0 ; !part.count || r // Exit any non playuntil complete parts immediately if(exitPending() && !part.playUntilComplete) break; //启动音频线程,播放音频文件 if (r == 0 && part.audioData && playSoundsAllowed()) { if (mInitAudioThread != nullptr) { mInitAudioThread->join(); } audioplay::playClip(part.audioData, part.audioLength); } glClearColor( part.backgroundColor[0], part.backgroundColor[1], part.backgroundColor[2], 1.0f); //按照frameDuration频率,循环绘制开机动画图片纹理 for (size_t j=0 ; j const Animation::Frame& frame(part.frames[j]); nsecs_t lastFrame = systemTime(); if (r > 0) { glBindTexture(GL_TEXTURE_2D, frame.tid); } else { if (part.count != 1) { //生成纹理 glGenTextures(1, &frame.tid); //绑定纹理 glBindTexture(GL_TEXTURE_2D, frame.tid); glTexParameterx(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR); glTexParameterx(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR); } int w, h; initTexture(frame.map, &w, &h); } const int xc = animationX + frame.trimX; const int yc = animationY + frame.trimY; Region clearReg(Rect(mWidth, mHeight)); clearReg.subtractSelf(Rect(xc, yc, xc+frame.trimWidth, yc+frame.trimHeight)); if (!clearReg.isEmpty()) { Region::const_iterator head(clearReg.begin()); Region::const_iterator tail(clearReg.end()); glEnable(GL_SCISSOR_TEST); while (head != tail) { const Rect& r2(*head++); glScissor(r2.left, mHeight - r2.bottom, r2.width(), r2.height()); glClear(GL_COLOR_BUFFER_BIT); } glDisable(GL_SCISSOR_TEST); } // 绘制纹理 glDrawTexiOES(xc, mHeight - (yc + frame.trimHeight), 0, frame.trimWidth, frame.trimHeight); if (mClockEnabled && mTimeIsAccurate && validClock(part)) { drawClock(animation.clockFont, part.clockPosX, part.clockPosY); } eglSwapBuffers(mDisplay, mSurface); nsecs_t now = systemTime(); nsecs_t delay = frameDuration - (now - lastFrame); //ALOGD("%lld, %lld", ns2ms(now - lastFrame), ns2ms(delay)); lastFrame = now; if (delay > 0) { struct timespec spec; spec.tv_sec = (now + delay) / 1000000000; spec.tv_nsec = (now + delay) % 1000000000; int err; do { err = clock_nanosleep(CLOCK_MONOTONIC, TIMER_ABSTIME, &spec, NULL); } while (err<0 && errno == EINTR); } checkExit(); } //休眠 usleep(part.pause * ns2us(frameDuration)); // 动画退出条件判断 if(exitPending() && !part.count) break; } } // 释放纹理 for (const Animation::Part& part : animation.parts) { if (part.count != 1) { const size_t fcount = part.frames.size(); for (size_t j = 0; j < fcount; j++) { const Animation::Frame& frame(part.frames[j]); glDeleteTextures(1, &frame.tid); } } } // 关闭和视频音频 audioplay::setPlaying(false); audioplay::destroy(); return true;}从上面的源码可以看到,playAnimation函数播放动画的原理,其实就是按照一定的频率,循环调用glDrawTexiOES函数,绘制图片纹理,同时调用音频播放模块播放音频。
通过OpenGL ES播放动画的案例就讲完了,我们也了解了通过OpenGL来播放视频的一种方式,我们接着看第二个案例,Activity界面如何通过OpenGL来进行硬件加速,也就是硬件绘制绘制的。
OpenGL ES进行硬件加速
我们知道,Activity界面的显示需要经历Measure测量,Layout布局,和Draw绘制三个过程,而Draw绘制流程又分为软件绘制和硬件绘制,硬件绘制便是通过OpenGL ES进行的。我们直接看看硬件绘制流程里,OpenGL ES是如何来进行绘制的,它的入口在ViewRootImpl的performDraw函数中。
//文件-->/frameworks/base/core/java/android/view/ViewRootImpl.javaprivate void performDraw() { //…… draw(fullRedrawNeeded); //……}private void draw(boolean fullRedrawNeeded) { Surface surface = mSurface; if (!surface.isValid()) { return; } //…… if (!dirty.isEmpty() || mIsAnimating || accessibilityFocusDirty) { if (!dirty.isEmpty() || mIsAnimating || accessibilityFocusDirty) { if (mAttachInfo.mThreadedRenderer != null && mAttachInfo.mThreadedRenderer.isEnabled()) { //…… //硬件渲染 mAttachInfo.mThreadedRenderer.draw(mView, mAttachInfo, this); } else { //…… //软件渲染 if (!drawSoftware(surface, mAttachInfo, xOffset, yOffset, scalingRequired, dirty)) { return; } } } //…… } //……}从上面的代码可以看到,硬件渲染是通过mThreadedRenderer.draw方法进行的,在分析mThreadedRenderer.draw函数之前,我们需要先了解ThreadedRenderer是什么,它的创建要在Measure,Layout和Draw的流程之前,当我们在Activity的onCreate回调中执行setContentView函数时,最终会执行ViewRootImpl的setView方法,ThreadedRenderer就是在这个此时被创建的。
//文件-->/frameworks/base/core/java/android/view/ViewRootImpl.javapublic void setView(View view, WindowManager.LayoutParams attrs, View panelParentView) { synchronized (this) { if (mView == null) { mView = view; //…… if (mSurfaceHolder == null) { enableHardwareAcceleration(attrs); } //…… } }}private void enableHardwareAcceleration(WindowManager.LayoutParams attrs) { mAttachInfo.mHardwareAccelerated = false; mAttachInfo.mHardwareAccelerationRequested = false; // 兼容模式下不开启硬件加速 if (mTranslator != null) return; final boolean hardwareAccelerated = (attrs.flags & WindowManager.LayoutParams.FLAG_HARDWARE_ACCELERATED) != 0; if (hardwareAccelerated) { if (!ThreadedRenderer.isAvailable()) { return; } //…… if (fakeHwAccelerated) { //…… } else if (!ThreadedRenderer.sRendererDisabled || (ThreadedRenderer.sSystemRendererDisabled && forceHwAccelerated)) { //…… //创建ThreadedRenderer mAttachInfo.mThreadedRenderer = ThreadedRenderer.create(mContext, translucent, attrs.getTitle().toString()); if (mAttachInfo.mThreadedRenderer != null) { mAttachInfo.mHardwareAccelerated = mAttachInfo.mHardwareAccelerationRequested = true; } } }}可以看到,当RootViewImpl在调用setView的时候,会开启硬件加速,并通过ThreadedRenderer.create函数来创建ThreadedRenderer。
我们继续看看ThreadedRenderer这个类的实现。
//文件-->/frameworks/base/core/java/android/view/ThreadedRenderer.javapublic static ThreadedRenderer create(Context context, boolean translucent, String name) { ThreadedRenderer renderer = null; if (isAvailable()) { renderer = new ThreadedRenderer(context, translucent, name); } return renderer;}ThreadedRenderer(Context context, boolean translucent, String name) { //…… //创建RootRenderNode long rootNodePtr = nCreateRootRenderNode(); mRootNode = RenderNode.adopt(rootNodePtr); mRootNode.setClipToBounds(false); mIsOpaque = !translucent; //创建RenderProxy mNativeProxy = nCreateProxy(translucent, rootNodePtr); nSetName(mNativeProxy, name); //启动GraphicsStatsService,统计渲染信息 ProcessInitializer.sInstance.init(context, mNativeProxy); loadSystemProperties();}ThreadedRenderer的构造函数中主要做了这两件事情:
1. 通过JNI方法nCreateRootRenderNode在Native创建RootRenderNode,每一个View都对应了一个RenderNode,它包含了这个View及其子view的DisplayList,DisplayList包含了是可以让openGL识别的渲染指令,这些渲染指令被封装成了一条条OP。
//文件-->/frameworks/base/core/jni/android_view_ThreadedRenderer.cppstatic jlong android_view_ThreadedRenderer_createRootRenderNode(JNIEnv* env, jobject clazz) { RootRenderNode* node = new RootRenderNode(env); node->incStrong(0); node->setName("RootRenderNode"); return reinterpret_cast(node);}2. 通过Jni方法nCreateProxy在Native层的RenderProxy,它就是用来跟渲染线程进行通信的句柄,我们看下nCreateProxy的Native实现
//文件-->/frameworks/base/core/jni/android_view_ThreadedRenderer.cppstatic jlong android_view_ThreadedRenderer_createProxy(JNIEnv* env, jobject clazz, jboolean translucent, jlong rootRenderNodePtr) { RootRenderNode* rootRenderNode = reinterpret_cast(rootRenderNodePtr); ContextFactoryImpl factory(rootRenderNode); return (jlong) new RenderProxy(translucent, rootRenderNode, &factory);}//文件-->/frameworks/base/libs/hwui/renderthread/RenderProxy.cppRenderProxy::RenderProxy(bool translucent, RenderNode* rootRenderNode, IContextFactory* contextFactory) : mRenderThread(RenderThread::getInstance()) , mContext(nullptr) { SETUP_TASK(createContext); args->translucent = translucent; args->rootRenderNode = rootRenderNode; args->thread = &mRenderThread; args->contextFactory = contextFactory; mContext = (CanvasContext*) postAndWait(task); mDrawFrameTask.setContext(&mRenderThread, mContext, rootRenderNode);}从RenderProxy构造函数可以看到,通过RenderThread::getInstance()创建了RenderThread,也就是硬件绘制的渲染线程。相比于在主线程进行的软件绘制,硬件加速会新建一个线程,这样能减轻主线程的工作量。
了解了ThreadedRenderer的创建和初始化流程,我们继续回到渲染的流程mThreadedRenderer.draw这个函数中来,先看看这个函数的源码。
//文件-->/frameworks/base/core/java/android/view/ThreadedRenderer.javavoid draw(View view, AttachInfo attachInfo, DrawCallbacks callbacks) { attachInfo.mIgnoreDirtyState = true; final Choreographer choreographer = attachInfo.mViewRootImpl.mChoreographer; choreographer.mFrameInfo.markDrawStart(); //1,构建RootView的DisplayList updateRootDisplayList(view, callbacks); attachInfo.mIgnoreDirtyState = false; //…… 窗口动画处理 final long[] frameInfo = choreographer.mFrameInfo.mFrameInfo; //2,通知渲染 int syncResult = nSyncAndDrawFrame(mNativeProxy, frameInfo, frameInfo.length); //…… 渲染失败的处理}这个流程我们只需要关心这两件事情:
构建DisplayList
绘制DisplayList
经过这两步,界面就显示出来。我们详细看一下这这两步的流程:
构建DisplayList
1,通过updateRootDisplayList函数构建根view的DisplayList,DisplayList在前面提到过,它包含了可以让openGL识别的渲染指令,先看看函数的实现
//文件-->/frameworks/base/core/java/android/view/ThreadedRenderer.javaprivate void updateRootDisplayList(View view, DrawCallbacks callbacks) { Trace.traceBegin(Trace.TRACE_TAG_VIEW, "Record View#draw()"); //构建View的DisplayList updateViewTreeDisplayList(view); if (mRootNodeNeedsUpdate || !mRootNode.isValid()) { //获取DisplayListCanvas DisplayListCanvas canvas = mRootNode.start(mSurfaceWidth, mSurfaceHeight); try { final int saveCount = canvas.save(); canvas.translate(mInsetLeft, mInsetTop); callbacks.onPreDraw(canvas); canvas.insertReorderBarrier(); //合并和优化DisplayList canvas.drawRenderNode(view.updateDisplayListIfDirty()); canvas.insertInorderBarrier(); callbacks.onPostDraw(canvas); canvas.restoreToCount(saveCount); mRootNodeNeedsUpdate = false; } finally { //更新RootRenderNode mRootNode.end(canvas); } } Trace.traceEnd(Trace.TRACE_TAG_VIEW);}updateRootDisplayList函数的主要流程有这几步:
构建根View的DisplayList
合并和优化DisplayList
构建根View的DisplayList
我们先看第一步构建根View的DisplayList的源码。
//文件-->/frameworks/base/core/java/android/view/ThreadedRenderer.javaprivate void updateViewTreeDisplayList(View view) { view.mPrivateFlags |= View.PFLAG_DRAWN; view.mRecreateDisplayList = (view.mPrivateFlags & View.PFLAG_INVALIDATED) == View.PFLAG_INVALIDATED; view.mPrivateFlags &= ~View.PFLAG_INVALIDATED; view.updateDisplayListIfDirty(); view.mRecreateDisplayList = false;}//文件-->/frameworks/base/core/java/android/view/View.javapublic RenderNode updateDisplayListIfDirty() { final RenderNode renderNode = mRenderNode; if (!canHaveDisplayList()) { return renderNode; } //判断硬件加速是否可用 if ((mPrivateFlags & PFLAG_DRAWING_CACHE_VALID) == 0 || !renderNode.isValid() || (mRecreateDisplayList)) { //…… 不需要更新displaylist时,则直接返回renderNode //获取DisplayListCanvas final DisplayListCanvas canvas = renderNode.start(width, height); try { if (layerType == LAYER_TYPE_SOFTWARE) { //如果强制开启了软件绘制,比如一些不支持硬件加速的组件,或者静止了硬件加速的组件,会转换成bitmap后,交给硬件渲染 buildDrawingCache(true); Bitmap cache = getDrawingCache(true); if (cache != null) { canvas.drawBitmap(cache, 0, 0, mLayerPaint); } } else { if ((mPrivateFlags & PFLAG_SKIP_DRAW) == PFLAG_SKIP_DRAW) { //递归子View构建或更新displaylist dispatchDraw(canvas); } else { //调用自身的draw方法 draw(canvas); } } } finally { //讲DisplayListCanvas内容绑定到renderNode上 renderNode.end(canvas); setDisplayListProperties(renderNode); } } else { mPrivateFlags |= PFLAG_DRAWN | PFLAG_DRAWING_CACHE_VALID; mPrivateFlags &= ~PFLAG_DIRTY_MASK; } return renderNode;}可以看到updateDisplayListIfDirty主要做的事情有这几件
获取DisplayListCanvas
判断组件是否支持硬件加速,不支持则转换成bitmap后交给DisplayListCanvas
递归子View执行DisplayList的构建
调用自身的draw方法,交给DisplayListCanvas进行绘制
返回RenderNode
看到这里可能会有人疑问,为什么构建更新DisplayList函数updateDisplayListIfDirty中并没有看到DisplayList,返回对象也不是DisplayList,而是RenderNode?这个DisplayList其实是在Native层创建的,在前面提到过RenderNode其实包含了DisplayList,renderNode.end(canvas)函数会将DisplayList绑定到renderNode中。而DisplayListCanvas的作用,就是在Native层创建DisplayList。那么我们接着看DisplayListCanvas这个类。
//文件-->/frameworks/base/core/java/android/view/RenderNode.javapublic DisplayListCanvas start(int width, int height) { return DisplayListCanvas.obtain(this, width, height);}//文件-->/frameworks/base/core/java/android/view/DisplayListCanvas.javastatic DisplayListCanvas obtain(@NonNull RenderNode node, int width, int height) { if (node == null) throw new IllegalArgumentException("node cannot be null"); DisplayListCanvas canvas = sPool.acquire(); if (canvas == null) { canvas = new DisplayListCanvas(node, width, height); } else { nResetDisplayListCanvas(canvas.mNativeCanvasWrapper, node.mNativeRenderNode, width, height); } canvas.mNode = node; canvas.mWidth = width; canvas.mHeight = height; return canvas;}private DisplayListCanvas(@NonNull RenderNode node, int width, int height) { super(nCreateDisplayListCanvas(node.mNativeRenderNode, width, height)); mDensity = 0; // disable bitmap density scaling}我们通过RenderNode.start方法获取一个DisplayListCanvas,RenderNode会通过obtain来创建或从缓存中获取DisplayListCanvas,这是一种享元模式。DisplayListCanvas的构造函数里,会通过JNI方法nCreateDisplayListCanvas创建native的Canvas,我们接着看一下Native的流程
//文件-->/frameworks/base/core/jni/android_view_DisplayListCanvas.cppstatic jlong android_view_DisplayListCanvas_createDisplayListCanvas(jlong renderNodePtr, jint width, jint height) { RenderNode* renderNode = reinterpret_cast(renderNodePtr); return reinterpret_cast(Canvas::create_recording_canvas(width, height, renderNode));}//文件-->/frameworks/base/libs/hwui/hwui/Canvas.cppCanvas* Canvas::create_recording_canvas(int width, int height, uirenderer::RenderNode* renderNode) { if (uirenderer::Properties::isSkiaEnabled()) { return new uirenderer::skiapipeline::SkiaRecordingCanvas(renderNode, width, height); } return new uirenderer::RecordingCanvas(width, height);}可以看到,java层的DisplayListCanvas对应了native层RecordingCanvas或者SkiaRecordingCanvas
这里简单介绍一下这两个Canvas的区别,在Android8之前,HWUI中通过OpenGL对绘制操作进行封装后,直接送GPU进行渲染。Android 8.0开始,HWUI进行了重构,增加了RenderPipeline的概念,RenderPipeline有三种类型,分别为Skia,OpenGL和Vulkan,分别对应不同的渲染。并且Android8.0开始强化和重视Skia的地位,Android10版本后,所有通过硬件加速的渲染,都是通过SKIA进行封装,然后再经过OpenGL或Vulkan,最后交给GPU渲染。我讲解的源码是8.0的源码,可以看到,其实已经可以通过配置,来开启skiapipeline了。
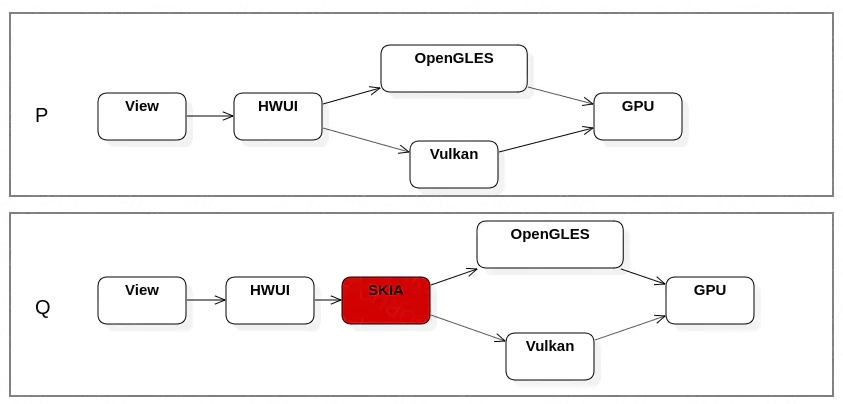
为了更容易的讲解如何通过OpenGL进行硬件渲染,这里我还是以RecordingCanvas来讲解,这里列举几个RecordingCanvas中的常规操作
//文件-->/frameworks/base/libs/hwui/RecordingCanvas.cpp//绘制点void RecordingCanvas::drawPoints(const float* points, int floatCount, const SkPaint& paint) { if (CC_UNLIKELY(floatCount < 2 || paint.nothingToDraw())) return; floatCount &= ~0x1; // round down to nearest two addOp(alloc().create_trivial( calcBoundsOfPoints(points, floatCount), *mState.currentSnapshot()->transform, getRecordedClip(), refPaint(&paint), refBuffer<float>(points, floatCount), floatCount));}struct PointsOp : RecordedOp { PointsOp(BASE_PARAMS, const float* points, const int floatCount) : SUPER(PointsOp) , points(points) , floatCount(floatCount) {} const float* points; const int floatCount;};//绘制线void RecordingCanvas::drawLines(const float* points, int floatCount, const SkPaint& paint) { if (CC_UNLIKELY(floatCount < 4 || paint.nothingToDraw())) return; floatCount &= ~0x3; // round down to nearest four addOp(alloc().create_trivial( calcBoundsOfPoints(points, floatCount), *mState.currentSnapshot()->transform, getRecordedClip(), refPaint(&paint), refBuffer<float>(points, floatCount), floatCount));}struct LinesOp : RecordedOp { LinesOp(BASE_PARAMS, const float* points, const int floatCount) : SUPER(LinesOp) , points(points) , floatCount(floatCount) {} const float* points; const int floatCount;};//绘制矩阵void RecordingCanvas::drawRect(float left, float top, float right, float bottom, const SkPaint& paint) { if (CC_UNLIKELY(paint.nothingToDraw())) return; addOp(alloc().create_trivial( Rect(left, top, right, bottom), *(mState.currentSnapshot()->transform), getRecordedClip(), refPaint(&paint)));}struct RectOp : RecordedOp { RectOp(BASE_PARAMS) : SUPER(RectOp) {}};struct RoundRectOp : RecordedOp { RoundRectOp(BASE_PARAMS, float rx, float ry) : SUPER(RoundRectOp) , rx(rx) , ry(ry) {} const float rx; const float ry;};int RecordingCanvas::addOp(RecordedOp* op) { // skip op with empty clip if (op->localClip && op->localClip->rect.isEmpty()) { // NOTE: this rejection happens after op construction/content ref-ing, so content ref'd // and held by renderthread isn't affected by clip rejection. // Could rewind alloc here if desired, but callers would have to not touch op afterwards. return -1; } int insertIndex = mDisplayList->ops.size(); mDisplayList->ops.push_back(op); if (mDeferredBarrierType != DeferredBarrierType::None) { // op is first in new chunk mDisplayList->chunks.emplace_back(); DisplayList::Chunk& newChunk = mDisplayList->chunks.back(); newChunk.beginOpIndex = insertIndex; newChunk.endOpIndex = insertIndex + 1; newChunk.reorderChildren = (mDeferredBarrierType == DeferredBarrierType::OutOfOrder); newChunk.reorderClip = mDeferredBarrierClip; int nextChildIndex = mDisplayList->children.size(); newChunk.beginChildIndex = newChunk.endChildIndex = nextChildIndex; mDeferredBarrierType = DeferredBarrierType::None; } else { // standard case - append to existing chunk mDisplayList->chunks.back().endOpIndex = insertIndex + 1; } return insertIndex;}可以看到,我们通过RecordingCanvas绘制的图元,都被封装成了一个个能够让GPU能够识别的OP,这些OP都存储在了mDisplayList中。这就回答了前面的疑问,为什么updateDisplayListIfDirty没有看到DisplayList,因为DisplayListCanvas通过调用Natice层的RecordingCanvas,更新了Natice层的mDisplayList。
我们在接着看renderNode.end(canvas)函数,如何将Natice层的DisplayList绑定到renderNode中。
//文件-->/frameworks/base/core/java/android/view/RenderNode.javapublic void end(DisplayListCanvas canvas) { long displayList = canvas.finishRecording(); nSetDisplayList(mNativeRenderNode, displayList); canvas.recycle();}这里通过JNI方法nSetDisplayList进行了DisplayList和RenderNode的绑定,此时,我们就能理解我在前面说的:RenderNode包含了这个View及其子view的DisplayList,DisplayList包含了一条条可以让openGL识别的渲染指令——OP操作,它是一个基本的能让GPU识别的绘制元素。
合并和优化DisplayList
updateViewTreeDisplayList花了比较大精力,将所有的View的DisplayList已经创建好了,DisplayList里的DrawOP树也创建好了,为什么还要在调用canvas.drawRenderNode(view.updateDisplayListIfDirty())这个函数呢?这个函数的主要功能是对前面构建的DisplayList做优化和合并处理,我们看看具体的实现细节。
//文件-->/frameworks/base/core/java/android/view/DisplayListCanvas.javapublic void drawRenderNode(RenderNode renderNode) { nDrawRenderNode(mNativeCanvasWrapper, renderNode.getNativeDisplayList());}//文件-->/frameworks/base/core/jni/android_view_DisplayListCanvas.cppstatic void android_view_DisplayListCanvas_drawRenderNode(jlong canvasPtr, jlong renderNodePtr) { Canvas* canvas = reinterpret_cast(canvasPtr); RenderNode* renderNode = reinterpret_cast(renderNodePtr); canvas->drawRenderNode(renderNode);}//文件-->/frameworks/base/libs/hwui/RecordingCanvas.cppvoid RecordingCanvas::drawRenderNode(RenderNode* renderNode) { auto&& stagingProps = renderNode->stagingProperties(); RenderNodeOp* op = alloc().create_trivial( Rect(stagingProps.getWidth(), stagingProps.getHeight()), *(mState.currentSnapshot()->transform), getRecordedClip(), renderNode); int opIndex = addOp(op); if (CC_LIKELY(opIndex >= 0)) { int childIndex = mDisplayList->addChild(op); // update the chunk's child indices DisplayList::Chunk& chunk = mDisplayList->chunks.back(); chunk.endChildIndex = childIndex + 1; if (renderNode->stagingProperties().isProjectionReceiver()) { // use staging property, since recording on UI thread mDisplayList->projectionReceiveIndex = opIndex; } }}可以看到,最终执行到了RecordingCanvas中的drawRenderNode函数,这个函数会对DisplayList做合并和优化。
绘制DisplayList
经过比较长的篇幅,我们把mThreadedRenderer.draw函数中的第一个流程,构建DisplayList说完,现在开始说第二个流程,nSyncAndDrawFrame进行帧绘制,这个流程结束,我们的界面就能在屏幕上显示出来了。nSyncAndDrawFrame是一个native方法,我们看看它的实现
static int android_view_ThreadedRenderer_syncAndDrawFrame(JNIEnv* env, jobject clazz, jlong proxyPtr, jlongArray frameInfo, jint frameInfoSize) { LOG_ALWAYS_FATAL_IF(frameInfoSize != UI_THREAD_FRAME_INFO_SIZE, "Mismatched size expectations, given %d expected %d", frameInfoSize, UI_THREAD_FRAME_INFO_SIZE); RenderProxy* proxy = reinterpret_cast(proxyPtr); env->GetLongArrayRegion(frameInfo, 0, frameInfoSize, proxy->frameInfo()); return proxy->syncAndDrawFrame();}int RenderProxy::syncAndDrawFrame() { return mDrawFrameTask.drawFrame();}nSyncAndDrawFrame函数调用了RenderProxy的syncAndDrawFrame,syncAndDrawFrame调用了DrawFrameTask.drawFrame()方法
//文件-->/frameworks/base/libs/hwui/renderthread/DrawFrameTask.cppint DrawFrameTask::drawFrame() { LOG_ALWAYS_FATAL_IF(!mContext, "Cannot drawFrame with no CanvasContext!"); mSyncResult = SyncResult::OK; mSyncQueued = systemTime(CLOCK_MONOTONIC); postAndWait(); return mSyncResult;}void DrawFrameTask::postAndWait() { AutoMutex _lock(mLock); mRenderThread->queue(this); mSignal.wait(mLock);}void DrawFrameTask::run() { ATRACE_NAME("DrawFrame"); bool canUnblockUiThread; bool canDrawThisFrame; { TreeInfo info(TreeInfo::MODE_FULL, *mContext); canUnblockUiThread = syncFrameState(info); canDrawThisFrame = info.out.canDrawThisFrame; } // Grab a copy of everything we need CanvasContext* context = mContext; // From this point on anything in "this" is *UNSAFE TO ACCESS* if (canUnblockUiThread) { unblockUiThread(); } if (CC_LIKELY(canDrawThisFrame)) { context->draw(); } else { // wait on fences so tasks don't overlap next frame context->waitOnFences(); } if (!canUnblockUiThread) { unblockUiThread(); }}DrawFrameTask做了两件事情
调用syncFrameState函数同步frame信息
调用CanvasContext.draw()函数进行绘制
同步Frame信息
我们先看看第一件事情,同步Frame信息,它主要的工作是将主线程的RenderNode同步到RenderNode来,在前面讲mAttachInfo.mThreadedRenderer.draw函数中,第一步会将DisplayList构建完毕,然后绑定到RenderNode中,这个RenderNode是在主线程创建的。而我们的DrawFrameTask,是在native层的RenderThread中执行的,所以需要讲数据同步过来。
//文件-->/frameworks/base/libs/hwui/renderthread/DrawFrameTask.cppbool DrawFrameTask::syncFrameState(TreeInfo& info) { ATRACE_CALL(); int64_t vsync = mFrameInfo[static_cast<int>(FrameInfoIndex::Vsync)]; mRenderThread->timeLord().vsyncReceived(vsync); bool canDraw = mContext->makeCurrent(); mContext->unpinImages(); for (size_t i = 0; i < mLayers.size(); i++) { mLayers[i]->apply(); } mLayers.clear(); mContext->prepareTree(info, mFrameInfo, mSyncQueued, mTargetNode); //…… // If prepareTextures is false, we ran out of texture cache space return info.prepareTextures;}这里调用了mContext->prepareTree函数,mContext在下面会详细讲,我们这里先看看这个方法的实现。
//文件-->/frameworks/base/libs/hwui/renderthread/CanvasContext.cppvoid CanvasContext::prepareTree(TreeInfo& info, int64_t* uiFrameInfo, int64_t syncQueued, RenderNode* target) { //…… for (const sp& node : mRenderNodes) { // Only the primary target node will be drawn full - all other nodes would get drawn in // real time mode. In case of a window, the primary node is the window content and the other // node(s) are non client / filler nodes. info.mode = (node.get() == target ? TreeInfo::MODE_FULL : TreeInfo::MODE_RT_ONLY); node->prepareTree(info); GL_CHECKPOINT(MODERATE); } //……}void RenderNode::prepareTree(TreeInfo& info) { bool functorsNeedLayer = Properties::debugOverdraw; prepareTreeImpl(info, functorsNeedLayer);}void RenderNode::prepareTreeImpl(TreeInfo& info, bool functorsNeedLayer) { info.damageAccumulator->pushTransform(this); if (info.mode == TreeInfo::MODE_FULL) { // 同步属性 pushStagingPropertiesChanges(info); } // layer prepareLayer(info, animatorDirtyMask); //同步DrawOpTree if (info.mode == TreeInfo::MODE_FULL) { pushStagingDisplayListChanges(info); } //递归处理子View prepareSubTree(info, childFunctorsNeedLayer, mDisplayListData); // push pushLayerUpdate(info); info.damageAccumulator->popTransform();}同步Frame的操作完成了,我们接着看最后绘制的流程。
进行绘制
图形的硬件渲染,是通过调用CanvasContext的draw方法来进行绘制的,CanvasContext是什么呢?
它是渲染的上下文,CanvasContext可以选择不同的渲染模式进行渲染,这是策略模式的设计。我们看一下CanvasContext的create方法,可以看到,方法中会根据渲染类型,创建不同的渲染管道,总共有三种渲染管道——OpenGL,SKiaGL和SkiaVulkan。
CanvasContext* CanvasContext::create(RenderThread& thread, bool translucent, RenderNode* rootRenderNode, IContextFactory* contextFactory) { auto renderType = Properties::getRenderPipelineType(); switch (renderType) { case RenderPipelineType::OpenGL: return new CanvasContext(thread, translucent, rootRenderNode, contextFactory, std::make_unique(thread)); case RenderPipelineType::SkiaGL: return new CanvasContext(thread, translucent, rootRenderNode, contextFactory, std::make_unique<:skiaopenglpipeline>(thread)); case RenderPipelineType::SkiaVulkan: return new CanvasContext(thread, translucent, rootRenderNode, contextFactory, std::make_unique<:skiavulkanpipeline>(thread)); default: LOG_ALWAYS_FATAL("canvas context type %d not supported", (int32_t) renderType); break; } return nullptr;}我们这里这里只看通过OpenGL进行渲染的OpenGLPipeline
OpenGLPipeline::OpenGLPipeline(RenderThread& thread) : mEglManager(thread.eglManager()) , mRenderThread(thread) {}在OpenGLPipeline的构造函数里面,创建了EglManager,EglManager将我们对EGL的操作全部封装好了,我们看看EglManager的初始化方法
//文件-->/frameworks/base/libs/hwui/renderthread/EglManager.cppvoid EglManager::initialize() { if (hasEglContext()) return; ATRACE_NAME("Creating EGLContext"); //获取 EGL Display 对象 mEglDisplay = eglGetDisplay(EGL_DEFAULT_DISPLAY); LOG_ALWAYS_FATAL_IF(mEglDisplay == EGL_NO_DISPLAY, "Failed to get EGL_DEFAULT_DISPLAY! err=%s", eglErrorString()); EGLint major, minor; //初始化与 EGLDisplay 之间的连接 LOG_ALWAYS_FATAL_IF(eglInitialize(mEglDisplay, &major, &minor) == EGL_FALSE, "Failed to initialize display %p! err=%s", mEglDisplay, eglErrorString()); //…… //EGL配置设置 loadConfig(); //创建EGL上下文 createContext(); //创建离屏渲染Buffer createPBufferSurface(); //绑定上下文 makeCurrent(mPBufferSurface); DeviceInfo::initialize(); mRenderThread.renderState().onGLContextCreated();}在这里我们看到了熟悉的身影,EglManager中的初始化流程和前面所有EGL初始化的流程都是一样的。但在初始化的流程中,我们没看到WindowSurface的设置,只看到了PBufferSurface的创建,它是一个离屏渲染的Buffer,这里简单介绍一下WindowSurface和PbufferSurface
WindowSurface:是和窗口相关的,也就是在屏幕上的一块显示区的封装,渲染后即显示在界面上。
PbufferSurface:在显存中开辟一个空间,将渲染后的数据(帧)存放在这里。
可以看到没有WindowSurface,OpenGL ES渲染的图形是没法显示在界面上的。其实EglManager已经封装了初始化WindowSurface的方法。
//文件-->/frameworks/base/libs/hwui/renderthread/EglManager.cppEGLSurface EglManager::createSurface(EGLNativeWindowType window) { initialize(); EGLint attribs[] = {#ifdef ANDROID_ENABLE_LINEAR_BLENDING EGL_GL_COLORSPACE_KHR, EGL_GL_COLORSPACE_SRGB_KHR, EGL_COLORSPACE, EGL_COLORSPACE_sRGB,#endif EGL_NONE }; EGLSurface surface = eglCreateWindowSurface(mEglDisplay, mEglConfig, window, attribs); LOG_ALWAYS_FATAL_IF(surface == EGL_NO_SURFACE, "Failed to create EGLSurface for window %p, eglErr = %s", (void*) window, eglErrorString()); if (mSwapBehavior != SwapBehavior::Preserved) { LOG_ALWAYS_FATAL_IF(eglSurfaceAttrib(mEglDisplay, surface, EGL_SWAP_BEHAVIOR, EGL_BUFFER_DESTROYED) == EGL_FALSE, "Failed to set swap behavior to destroyed for window %p, eglErr = %s", (void*) window, eglErrorString()); } return surface;}这个surface又是什么时候设置的呢?在activity的界面显示流程中,当我们setView后,ViewRootImpl会执行performTraveserl函数,然后执行Measure测量,Layout布局,和Draw绘制的流程,setView函数在前面讲过,会开启硬件加速,创建ThreadedRenderer,draw函数也讲过,measure,layout的流程就不在这儿说了,它和OpgenGL没关系,其实performTraveserl函数里,同时也设置了EGL的Surface,可见这个函数是多么重要的一个函数,我们看一下。
private void performTraversals() { //…… if (mAttachInfo.mThreadedRenderer != null) { try { //调用ThreadedRenderer initialize函数 hwInitialized = mAttachInfo.mThreadedRenderer.initialize( mSurface); if (hwInitialized && (host.mPrivateFlags & View.PFLAG_REQUEST_TRANSPARENT_REGIONS) == 0) { // Don't pre-allocate if transparent regions // are requested as they may not be needed mSurface.allocateBuffers(); } } catch (OutOfResourcesException e) { handleOutOfResourcesException(e); return; } } //……}boolean initialize(Surface surface) throws OutOfResourcesException { boolean status = !mInitialized; mInitialized = true; updateEnabledState(surface); nInitialize(mNativeProxy, surface); return status;}ThreadedRenderer的initialize函数调用了native层的initialize方法。
static void android_view_ThreadedRenderer_initialize(JNIEnv* env, jobject clazz, jlong proxyPtr, jobject jsurface) { RenderProxy* proxy = reinterpret_cast(proxyPtr); sp surface = android_view_Surface_getSurface(env, jsurface); proxy->initialize(surface);}void RenderProxy::initialize(const sp& surface) { SETUP_TASK(initialize); args->context = mContext; args->surface = surface.get(); post(task);}void CanvasContext::initialize(Surface* surface) { setSurface(surface);}void CanvasContext::setSurface(Surface* surface) { ATRACE_CALL(); mNativeSurface = surface; bool hasSurface = mRenderPipeline->setSurface(surface, mSwapBehavior); mFrameNumber = -1; if (hasSurface) { mHaveNewSurface = true; mSwapHistory.clear(); } else { mRenderThread.removeFrameCallback(this); }}从这里可以看到,EGL的Surface在很早之前就已经设置好了。
此时我们的流程中,EGL的初始化工作都已经完成了,现在可以开始绘制了,我们回到DrawFrameTask::run的draw流程上来
void CanvasContext::draw() { SkRect dirty; mDamageAccumulator.finish(&dirty); mCurrentFrameInfo->markIssueDrawCommandsStart(); Frame frame = mRenderPipeline->getFrame(); SkRect windowDirty = computeDirtyRect(frame, &dirty); //调用OpenGL的draw函数 bool drew = mRenderPipeline->draw(frame, windowDirty, dirty, mLightGeometry, &mLayerUpdateQueue, mContentDrawBounds, mOpaque, mLightInfo, mRenderNodes, &(profiler())); waitOnFences(); bool requireSwap = false; //交换缓冲区 bool didSwap = mRenderPipeline->swapBuffers(frame, drew, windowDirty, mCurrentFrameInfo, &requireSwap); mIsDirty = false; //……}这里调用mRenderPipeline的draw方法,其实就是调用了OpenGL的draw方法,然后调用mRenderPipeline->swapBuffers进行缓存区交换,
//文件-->/frameworks/base/libs/hwui/renderthread/OpenGLPipeline.cppbool OpenGLPipeline::draw(const Frame& frame, const SkRect& screenDirty, const SkRect& dirty, const FrameBuilder::LightGeometry& lightGeometry, LayerUpdateQueue* layerUpdateQueue, const Rect& contentDrawBounds, bool opaque, const BakedOpRenderer::LightInfo& lightInfo, const std::vector< sp >& renderNodes, FrameInfoVisualizer* profiler) { //…… //BakedOpRenderer用于替代之前的OpenGLRenderer BakedOpRenderer renderer(caches, mRenderThread.renderState(), opaque, lightInfo); frameBuilder.replayBakedOps(renderer); //调用GPU进行渲染 drew = renderer.didDraw(); //…… return drew;}bool OpenGLPipeline::swapBuffers(const Frame& frame, bool drew, const SkRect& screenDirty, FrameInfo* currentFrameInfo, bool* requireSwap) { GL_CHECKPOINT(LOW); // Even if we decided to cancel the frame, from the perspective of jank // metrics the frame was swapped at this point currentFrameInfo->markSwapBuffers(); *requireSwap = drew || mEglManager.damageRequiresSwap(); if (*requireSwap && (CC_UNLIKELY(!mEglManager.swapBuffers(frame, screenDirty)))) { return false; } return *requireSwap;}至此,通过OpenGL ES进行硬件渲染的主要流程结束了。看完了两个例子,是不是对OpenGL ES作为图像生产者是如何生产图像已经了解了呢?我们接着看下一个图像生产者Skia。
Skia
Skia是谷歌开源的一款跨平台的2D图形引擎,目前谷歌的Chrome浏览器、Android、Flutter、以及火狐浏览器、火狐操作系统和其它许多产品都使用它作为图形引擎,它作为Android系统第三方软件,放在external/skia/ 目录下。虽然Android从4.0开始默认开启了硬件加速,但不代表Skia的作用就不大了,其实Skia在Android中的地位是越来越重要了,从Android 8开始,我们可以选择使用Skia进行硬件加速,Android 9开始就默认使用Skia来进行硬件加速。Skia的硬件加速主要是通过 copybit 模块调用OpenGL或者SKia来实现分。

由于Skia的硬件加速也是通过Copybit模块调用的OpenGL或者Vulkan接口,所以我们这儿只说说Skia通过cpu绘制的,也就是软绘的方式。还是老规则,先看看Skia要如何使用
如何使用Skia?
OpenGL ES的使用要配合EGL,需要初始化Display,surface,context等,用法还是比较繁琐的,Skia在使用上就方便很多了。掌握Skia绘制三要素:画板SKCanvas 、画纸SiBitmap、画笔Skpaint,我们就能很轻松的用Skia来绘制图形。
下面详细的解释Skia的绘图三要素
1. SKBitmap用来存储图形数据,它封装了与位图相关的一系列操作
SkBitmap bitmap = new SkBitmap();//设置位图格式及宽高bitmap->setConfig(SkBitmap::kRGB_565_Config,800,480);//分配位图所占空间bitmap->allocPixels();2. SKCanvas 封装了所有画图操作的函数,通过调用这些函数,我们就能实现绘制操作。
//使用前传入bitmapSkCanvas canvas(bitmap);//移位,缩放,旋转,变形操作translate(SkiaScalar dx, SkiaScalar dy);scale(SkScalar sx, SkScalar sy);rotate(SkScalar degrees);skew(SkScalar sx, SkScalar sy);//绘制操作drawARGB(u8 a, u8 r, u8 g, u8 b....) //给定透明度以及红,绿,兰3色,填充整个可绘制区域。drawColor(SkColor color...) //给定颜色color, 填充整个绘制区域。drawPaint(SkPaint& paint) //用指定的画笔填充整个区域。drawPoint(...)//根据各种不同参数绘制不同的点。drawLine(x0, y0, x1, y1, paint) //画线,起点(x0, y0), 终点(x1, y1), 使用paint作为画笔。drawRect(rect, paint) //画矩形,矩形大小由rect指定,画笔由paint指定。drawRectCoords(left, top, right, bottom, paint),//给定4个边界画矩阵。drawOval(SkRect& oval, SkPaint& paint) //画椭圆,椭圆大小由oval矩形指定。//……其他操作3. Skpaint用来设置绘制内容的风格,样式,颜色等信息
setAntiAlias: 设置画笔的锯齿效果。setColor: 设置画笔颜色 setARGB: 设置画笔的a,r,p,g值。setAlpha: 设置Alpha值 setTextSize: 设置字体尺寸。setStyle: 设置画笔风格,空心或者实心。setStrokeWidth: 设置空心的边框宽度。getColor: 得到画笔的颜色 getAlpha: 得到画笔的Alpha值。我们看一个完整的使用Demo
void draw() { SkBitmap bitmap = new SkBitmap(); //设置位图格式及宽高 bitmap->setConfig(SkBitmap::kRGB_565_Config,800,480); //分配位图所占空间 bitmap->allocPixels(); //使用前传入bitmap SkCanvas canvas(bitmap); //定义画笔 SkPaint paint1, paint2, paint3; paint1.setAntiAlias(true); paint1.setColor(SkColorSetRGB(255, 0, 0)); paint1.setStyle(SkPaint::kFill_Style); paint2.setAntiAlias(true); paint2.setColor(SkColorSetRGB(0, 136, 0)); paint2.setStyle(SkPaint::kStroke_Style); paint2.setStrokeWidth(SkIntToScalar(3)); paint3.setAntiAlias(true); paint3.setColor(SkColorSetRGB(136, 136, 136)); sk_sp blob1 = SkTextBlob::MakeFromString("Skia!", SkFont(nullptr, 64.0f, 1.0f, 0.0f)); sk_sp blob2 = SkTextBlob::MakeFromString("Skia!", SkFont(nullptr, 64.0f, 1.5f, 0.0f)); canvas->clear(SK_ColorWHITE); canvas->drawTextBlob(blob1.get(), 20.0f, 64.0f, paint1); canvas->drawTextBlob(blob1.get(), 20.0f, 144.0f, paint2); canvas->drawTextBlob(blob2.get(), 20.0f, 224.0f, paint3);}这个Demo的效果如下

了解了Skia如何使用,我们接着看两个场景:Skia进行软件绘制,Flutter界面绘制
Skia进行软件绘制
在上面我讲了通过使用OpenGL渲染的硬件绘制方式,这里会接着讲使用Skia渲染的软件绘制方式,虽然Android默认开启了硬件加速,但是由于硬件加速会有耗电和内存的问题,一些系统应用和常驻应用依然是使用的软件绘制的方式,软绘入口还是在draw方法中。
//文件-->/frameworks/base/core/java/android/view/ViewRootImpl.javaprivate void performDraw() { //…… draw(fullRedrawNeeded); //……}private void draw(boolean fullRedrawNeeded) { Surface surface = mSurface; if (!surface.isValid()) { return; } //…… if (!dirty.isEmpty() || mIsAnimating || accessibilityFocusDirty) { if (!dirty.isEmpty() || mIsAnimating || accessibilityFocusDirty) { if (mAttachInfo.mThreadedRenderer != null && mAttachInfo.mThreadedRenderer.isEnabled()) { //…… //硬件渲染 mAttachInfo.mThreadedRenderer.draw(mView, mAttachInfo, this); } else { //…… //软件渲染 if (!drawSoftware(surface, mAttachInfo, xOffset, yOffset, scalingRequired, dirty)) { return; } } } //…… } //……}我们来看看drawSoftware函数的实现
private boolean drawSoftware(Surface surface, AttachInfo attachInfo, int xoff, int yoff, boolean scalingRequired, Rect dirty) { // Draw with software renderer. final Canvas canvas; //…… canvas = mSurface.lockCanvas(dirty); //…… mView.draw(canvas); //…… surface.unlockCanvasAndPost(canvas); //…… return true;}drawSoftware函数的流程主要为三步
通过mSurface.lockCanvas获取Canvas
通过draw方法,将根View及其子View遍历绘制到Canvas上
通过surface.unlockCanvasAndPost将绘制内容提交给surfaceFlinger进行合成
Lock Surface
我们先来看第一步,这个Canvas对应着Native层的SKCanvas。
//文件-->/frameworks/base/core/java/android/view/Surface.javapublic Canvas lockCanvas(Rect inOutDirty) throws Surface.OutOfResourcesException, IllegalArgumentException { synchronized (mLock) { checkNotReleasedLocked(); if (mLockedObject != 0) { throw new IllegalArgumentException("Surface was already locked"); } mLockedObject = nativeLockCanvas(mNativeObject, mCanvas, inOutDirty); return mCanvas; }}lockCanvas函数中通过JNI函数nativeLockCanvas,创建Nativce层的Canvas,nativeLockCanvas的入参mNativeObject对应着Native层的Surface,关于Surface和Buffer的知识,在下一篇图形缓冲区中会详细简介,这里不做太多介绍。我们直接着看nativeLockCanvas的实现。
static jlong nativeLockCanvas(JNIEnv* env, jclass clazz, jlong nativeObject, jobject canvasObj, jobject dirtyRectObj) { sp surface(reinterpret_cast(nativeObject)); if (!isSurfaceValid(surface)) { doThrowIAE(env); return 0; } Rect dirtyRect(Rect::EMPTY_RECT); Rect* dirtyRectPtr = NULL; if (dirtyRectObj) { dirtyRect.left = env->GetIntField(dirtyRectObj, gRectClassInfo.left); dirtyRect.top = env->GetIntField(dirtyRectObj, gRectClassInfo.top); dirtyRect.right = env->GetIntField(dirtyRectObj, gRectClassInfo.right); dirtyRect.bottom = env->GetIntField(dirtyRectObj, gRectClassInfo.bottom); dirtyRectPtr = &dirtyRect; } ANativeWindow_Buffer outBuffer; //1,获取用来存储图形绘制的buffer status_t err = surface->lock(&outBuffer, dirtyRectPtr); if (err < 0) { const char* const exception = (err == NO_MEMORY) ? OutOfResourcesException : "java/lang/IllegalArgumentException"; jniThrowException(env, exception, NULL); return 0; } SkImageInfo info = SkImageInfo::Make(outBuffer.width, outBuffer.height, convertPixelFormat(outBuffer.format), outBuffer.format == PIXEL_FORMAT_RGBX_8888 ? kOpaque_SkAlphaType : kPremul_SkAlphaType, GraphicsJNI::defaultColorSpace()); SkBitmap bitmap; ssize_t bpr = outBuffer.stride * bytesPerPixel(outBuffer.format); bitmap.setInfo(info, bpr); if (outBuffer.width > 0 && outBuffer.height > 0) { //将上一个buffer里的图形数据复制到当前bitmap中 bitmap.setPixels(outBuffer.bits); } else { // be safe with an empty bitmap. bitmap.setPixels(NULL); } //2,创建一个SKCanvas Canvas* nativeCanvas = GraphicsJNI::getNativeCanvas(env, canvasObj); //3,给SKCanvas设置Bitmap nativeCanvas->setBitmap(bitmap); //如果指定了脏区,则设定脏区的区域 if (dirtyRectPtr) { nativeCanvas->clipRect(dirtyRect.left, dirtyRect.top, dirtyRect.right, dirtyRect.bottom, SkClipOp::kIntersect); } if (dirtyRectObj) { env->SetIntField(dirtyRectObj, gRectClassInfo.left, dirtyRect.left); env->SetIntField(dirtyRectObj, gRectClassInfo.top, dirtyRect.top); env->SetIntField(dirtyRectObj, gRectClassInfo.right, dirtyRect.right); env->SetIntField(dirtyRectObj, gRectClassInfo.bottom, dirtyRect.bottom); } sp lockedSurface(surface); lockedSurface->incStrong(&sRefBaseOwner); return (jlong) lockedSurface.get();}nativeLockCanvas主要做了这几件事情
通过surface->lock函数获取绘制用的Buffer
根据Buffer信息创建SKBitmap
根据SKBitmap,创建并初始化SKCanvas
通过nativeLockCanvas,我们就创建好了SKCanvas了,并且设置了可以绘制图形的bitmap,此时我们就可以通过SKCanvas往bitmap里面绘制图形,mView.draw()函数,就做了这件事情。
绘制
我们接着看看View中的draw()函数
//文件-->/frameworks/base/core/java/android/view/View.javapublic void draw(Canvas canvas) { final int privateFlags = mPrivateFlags; final boolean dirtyOpaque = (privateFlags & PFLAG_DIRTY_MASK) == PFLAG_DIRTY_OPAQUE && (mAttachInfo == null || !mAttachInfo.mIgnoreDirtyState); mPrivateFlags = (privateFlags & ~PFLAG_DIRTY_MASK) | PFLAG_DRAWN; int saveCount; //1,绘制背景 if (!dirtyOpaque) { drawBackground(canvas); } final int viewFlags = mViewFlags; boolean horizontalEdges = (viewFlags & FADING_EDGE_HORIZONTAL) != 0; boolean verticalEdges = (viewFlags & FADING_EDGE_VERTICAL) != 0; if (!verticalEdges && !horizontalEdges) { // 2,绘制当前view的图形 if (!dirtyOpaque) onDraw(canvas); // 3,绘制子view的图形 dispatchDraw(canvas); drawAutofilledHighlight(canvas); // Overlay is part of the content and draws beneath Foreground if (mOverlay != null && !mOverlay.isEmpty()) { mOverlay.getOverlayView().dispatchDraw(canvas); } //4,绘制decorations,如滚动条,前景等 Step 6, draw decorations (foreground, scrollbars) onDrawForeground(canvas); // 5,绘制焦点的高亮 drawDefaultFocusHighlight(canvas); if (debugDraw()) { debugDrawFocus(canvas); } // we're done... return; } //……}draw函数中做了这几件事情
绘制背景
绘制当前view
遍历绘制子view
绘制前景
我们可以看看Canvas里的绘制方法,这些绘制方法都是JNI方法,并且一一对应着SKCanvas中的绘制方法
//文件-->/frameworks/base/graphics/java/android/graphics/Canvas.java//……private static native void nDrawBitmap(long nativeCanvas, int[] colors, int offset, int stride, float x, float y, int width, int height, boolean hasAlpha, long nativePaintOrZero);private static native void nDrawColor(long nativeCanvas, int color, int mode);private static native void nDrawPaint(long nativeCanvas, long nativePaint);private static native void nDrawPoint(long canvasHandle, float x, float y, long paintHandle);private static native void nDrawPoints(long canvasHandle, float[] pts, int offset, int count, long paintHandle);private static native void nDrawLine(long nativeCanvas, float startX, float startY, float stopX, float stopY, long nativePaint);private static native void nDrawLines(long canvasHandle, float[] pts, int offset, int count, long paintHandle);private static native void nDrawRect(long nativeCanvas, float left, float top, float right, float bottom, long nativePaint);private static native void nDrawOval(long nativeCanvas, float left, float top, float right, float bottom, long nativePaint);private static native void nDrawCircle(long nativeCanvas, float cx, float cy, float radius, long nativePaint);private static native void nDrawArc(long nativeCanvas, float left, float top, float right, float bottom, float startAngle, float sweep, boolean useCenter, long nativePaint);private static native void nDrawRoundRect(long nativeCanvas, float left, float top, float right, float bottom, float rx, float ry, long nativePaint);//……Post Surface
软件绘制的最后一步,通过surface.unlockCanvasAndPost将绘制内容提交给surfaceFlinger绘制,将绘制出来的图形提交给SurfaceFlinger,然后SurfaceFlinger作为消费者处理图形后,我们的界面就显示出来了。
public void unlockCanvasAndPost(Canvas canvas) { synchronized (mLock) { checkNotReleasedLocked(); if (mHwuiContext != null) { mHwuiContext.unlockAndPost(canvas); } else { unlockSwCanvasAndPost(canvas); } }}private void unlockSwCanvasAndPost(Canvas canvas) { if (canvas != mCanvas) { throw new IllegalArgumentException("canvas object must be the same instance that " + "was previously returned by lockCanvas"); } if (mNativeObject != mLockedObject) { Log.w(TAG, "WARNING: Surface's mNativeObject (0x" + Long.toHexString(mNativeObject) + ") != mLockedObject (0x" + Long.toHexString(mLockedObject) +")"); } if (mLockedObject == 0) { throw new IllegalStateException("Surface was not locked"); } try { nativeUnlockCanvasAndPost(mLockedObject, canvas); } finally { nativeRelease(mLockedObject); mLockedObject = 0; }}这里调用了Native函数nativeUnlockCanvasAndPost,我们接着往下看。
static void nativeUnlockCanvasAndPost(JNIEnv* env, jclass clazz, jlong nativeObject, jobject canvasObj) { sp surface(reinterpret_cast(nativeObject)); if (!isSurfaceValid(surface)) { return; } // detach the canvas from the surface Canvas* nativeCanvas = GraphicsJNI::getNativeCanvas(env, canvasObj); nativeCanvas->setBitmap(SkBitmap()); // unlock surface status_t err = surface->unlockAndPost(); if (err < 0) { doThrowIAE(env); }}在这里,surface->unlockAndPost()函数就会将Skia绘制出来的图像传递给SurfaceFlinger进行合成。通过skia进行软件绘制的流程已经讲完了,至于如何通过Surface获取缓冲区,在缓冲区绘制完数据后,surface->unlockAndPost()又如何通知SurfaceFlinger,这一点在下一篇文章的图形缓冲区中会详细的讲解。
可以看到,Skia软件绘制的流程比硬件绘制要简单很多,我们接着看看Skia进行Flutter绘制的案例。
Skia进行Flutter的界面绘制
在讲解Flutter如何通过Skia生产图像之前,先简单介绍一下Flutter,Flutter的架构分为Framework层,Engine层和Embedder三层。
Framework层使用dart语言实现,包括UI,文本,图片,按钮等Widgets,渲染,动画,手势等。
Engine使用C++实现,主要包括渲染引擎Skia, Dart虚拟机和文字排版Tex等模块。
Embedder是一个嵌入层,通过该层把Flutter嵌入到各个平台上去,Embedder的主要工作包括渲染Surface设置, 线程设置,以及插件等

了解了Flutter的架构,我们在接着了解Flutter显示一个界面的流程。我们知道在Android中,显示一个界面需要将XML界面布局解析成ViewGroup,然后再经过测量Measure,布局Layout和绘制Draw的流程。Flutter和Android的显示不太一样,它会将通过Dart语言编写的Widget界面布局转换成ElementTree和Render ObjectTree。ElementTree相当于是ViewGroup,Render ObjectTree相当于是经过Measure和Layout流程之后的ViewGroup。这种模式在很多场景上都有使用,比如Webview,在渲染界面时,也会创建一颗Dom树,render树和RenderObject,这样的好处是可以通过Diff比较改变过的组件,然后渲染时,只对改变过的组件做渲染,同时对跨平台友好,可以通过这种树的形式来抽象出不同平台的公共部分。
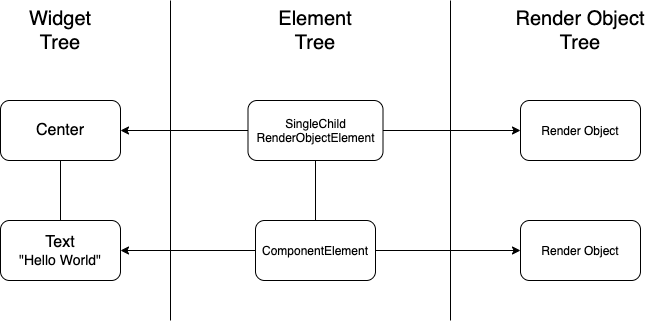
讲完了上面两个背景,我们直接来看Flutter是如何使用Skia来绘制界面的。
下面是一个Flutter页面的Demo
import 'package:flutter/material.dart';void main() => runApp(MyApp());class MyApp extends StatelessWidget { @override Widget build(BuildContext context) { return MaterialApp( title: 'Flutter Demo', theme: ThemeData( primarySwatch: Colors.blue, ), home: const MyHomePage(title: 'Flutter Demo Home Page'), ); }}这个页面是一个WidgetTree,相当于我们Activity的xml,widget树会转换成ElementTree和RenderObjectTree,我们看看入口函数runApp时如何进行树的转换的。
//文件-->/packages/flutter/lib/src/widgetsvoid runApp(Widget app) { WidgetsFlutterBinding.ensureInitialized() ..scheduleAttachRootWidget(app) ..scheduleWarmUpFrame();}void scheduleAttachRootWidget(Widget rootWidget) { Timer.run(() { attachRootWidget(rootWidget); });}void attachRootWidget(Widget rootWidget) { _readyToProduceFrames = true; _renderViewElement = RenderObjectToWidgetAdapter( container: renderView, debugShortDescription: '[root]', child: rootWidget, ).attachToRenderTree(buildOwner, renderViewElement as RenderObjectToWidgetElement);}接着看attachToRenderTree函数
RenderObjectToWidgetElementattachToRenderTree(BuildOwner owner, [RenderObjectToWidgetElement element]) { if (element == null) { owner.lockState(() { element = createElement(); //创建rootElement element.assignOwner(owner); //绑定BuildOwner }); owner.buildScope(element, () { //子widget的初始化从这里开始 element.mount(null, null); // 初始化子Widget前,先执行rootElement的mount方法 }); } else { ... } return element; }void mount(Element parent, dynamic newSlot) { super.mount(parent, newSlot); _renderObject = widget.createRenderObject(this); attachRenderObject(newSlot); _dirty = false;}从代码中可以看到,Widget都被转换成了Element,Element接着调用了mount方法,在mount方法中,可以看到Widget又被转换成了RenderObject,此时Widget Tree的ElementTree和RenderObject便都生成完了。
前面提到了RenderObject类似于经过了Measure和Layout流程的ViewGroup,RenderObject的Measure和Layout就不在这儿说了,那么还剩一个流程Draw流程,同样是在RenderObject中进行的,它的入口在RenderObject的paint函数中。
// 绘制入口,从 view 根节点开始,逐个绘制所有子节点@override void paint(PaintingContext context, Offset offset) { if (child != null) context.paintChild(child, offset); }可以看到,RenderObject通过PaintingContext来进行了图形的绘制,我们接着来了解一下PaintingContext是什么。
//文件-->/packages/flutter/lib/src/rendering/object.dartimport 'dart:ui' as ui show PictureRecorder;class PaintingContext extends ClipContext { @protected PaintingContext(this._containerLayer, this.estimatedBounds) final ContainerLayer _containerLayer; final Rect estimatedBounds; PictureLayer _currentLayer; ui.PictureRecorder _recorder; Canvas _canvas; @override Canvas get canvas { if (_canvas == null) _startRecording(); return _canvas; } void _startRecording() { _currentLayer = PictureLayer(estimatedBounds); _recorder = ui.PictureRecorder(); _canvas = Canvas(_recorder); _containerLayer.append(_currentLayer); } void stopRecordingIfNeeded() { if (!_isRecording) return; _currentLayer.picture = _recorder.endRecording(); _currentLayer = null; _recorder = null; _canvas = null;}可以看到,PaintingContext是绘制的上下文,前面讲OpenGL进行硬件加速时提到的CanvasContext,它也是绘制的上下文,里面封装了Skia,Opengl或者Vulkan的渲染管线。这里的PaintingContext则封装了Skia。
我们可以通过CanvasContext的get canvas函数获取Canvas,它调用了_startRecording函数中,函数中创建了PictureRecorder和Canvas,这两个类都是位于dart:ui库中,dart:ui位于engine层,在前面架构中提到,Flutter分为Framewrok,Engine和embened三层,Engine中包含了Skia,dart虚拟机和Text。dart:ui就是位于Engine层的。
我们接着去Engine层的代码看看Canvas的实现。
//文件-->engine-master\lib\ui\canvas.dart Canvas(PictureRecorder recorder, [ Rect? cullRect ]) : assert(recorder != null) { // ignore: unnecessary_null_comparison if (recorder.isRecording) throw ArgumentError('"recorder" must not already be associated with another Canvas.'); _recorder = recorder; _recorder!._canvas = this; cullRect ??= Rect.largest; _constructor(recorder, cullRect.left, cullRect.top, cullRect.right, cullRect.bottom); }void _constructor(PictureRecorder recorder, double left, double top, double right, double bottom) native 'Canvas_constructor';这里Canvas调用了Canvas_constructor这一个native方法,我们接着看这个native方法的实现。
//文件-->engine-master\lib\ui\painting\engine.ccstatic void Canvas_constructor(Dart_NativeArguments args) { UIDartState::ThrowIfUIOperationsProhibited(); DartCallConstructor(&Canvas::Create, args);}fml::RefPtr Canvas::Create(PictureRecorder* recorder, double left, double top, double right, double bottom) { if (!recorder) { Dart_ThrowException( ToDart("Canvas constructor called with non-genuine PictureRecorder.")); return nullptr; } fml::RefPtr canvas = fml::MakeRefCounted( recorder->BeginRecording(SkRect::MakeLTRB(left, top, right, bottom))); recorder->set_canvas(canvas); return canvas;}Canvas::Canvas(SkCanvas* canvas) : canvas_(canvas) {}可以看到,这里通过PictureRecorder->BeginRecording创建了SKCanvas,这其实是SKCanvas的另外一种使用方式,这里我简单的介绍一个使用demo。
Picture createSolidRectanglePicture( Color color, double width, double height){ PictureRecorder recorder = PictureRecorder(); Canvas canvas = Canvas(recorder); Paint paint = Paint(); paint.color = color; canvas.drawRect(Rect.fromLTWH(0, 0, width, height), paint); return recorder.endRecording();}这个demo的效果如下图,它创建Skia的方式就和Flutter创建Skia的方式是一样的。

此时,我们的SKCanvas创建好了,并且直接通过PaintingContext的get canvas函数就能获取到,那么获取到SKCanvas后直接调用Canvas的绘制api,就可以将图像绘制出来了。
Flutter界面显示的全流程是比较复杂的,Flutter是完全是自建的一套图像显示流程,无法通过Android的SurfaceFlinger进行图像合成,也无法使用Android的Gralloc模块分配图像缓冲区,所以它需要有自己的图像生产者,有自己的图形消费者,也有自己的图形缓冲区,这里面就有非常多的流程,比如如何接收VSync,如何处理及合成Layer,如何创建图像缓冲区,这里只是对Flutter的图像生产者的部分做了一个初步的介绍,关于Flutter更深入一步的细节,就不在这里继续讲解了。后面我会专门写一系列文章来详细讲解Flutter。
Vulkan
与OpenGL相比,Vulkan可以更详细的向显卡描述你的应用程序打算做什么,从而可以获得更好的性能和更小的驱动开销,作为OpenGL的替代者,它设计之初就是为了跨平台实现的,可以同时在Windows、Linux和Android开发。甚至在Mac OS系统上运行。Android在7.0开始,便增加了对Vulkan的支持,Vulkan一定是未来的趋势,因为它比OpenGL的性能更好更强大。下面我们就了解一下,如何使用Vulkan来生产图像。
如何使用Vulkan?
Vulkan的使用和OpenGL类似,同样是三步:初始化,绘制,提交buffer下面来看一下具体的流程
1,初始化Vulkan实例,物理设备和任务队列以及Surface
创建Instances实例
VkInstanceCreateInfo instance_create_info = { VK_STRUCTURE_TYPE_INSTANCE_CREATE_INFO, nullptr, 0, &application_info, 0, nullptr, static_cast<uint32_t>(desired_extensions.size()), desired_extensions.size() > 0 ? &desired_extensions[0] : nullptr };VkInstance inst;VkResult result = vkCreateInstance( &instance_create_info, nullptr, &inst );初始化物理设备,也就是我们的显卡设备,Vulkna的设计是支持多GPU的,这里选择第一个设备就行了。
uint32_t extensions_count = 0; VkResult result = VK_SUCCESS; //获取所有可用物理设备,并选择第一个result = vkEnumerateDeviceExtensionProperties( physical_device, nullptr, &extensions_count, &available_extensions[0]); if( (result != VK_SUCCESS) || (extensions_count == 0) ) { std::cout << "Could not get the number of device extensions." << std::endl; return false; }获取queue,Vulkan的所有操作,从绘图到上传纹理,都需要将命令提交到队列中
uint32_t queue_families_count = 0; //获取队列簇,并选择第一个queue_families.resize( queue_families_count ); vkGetPhysicalDeviceQueueFamilyProperties( physical_device, &queue_families_count, &queue_families[0] ); if( queue_families_count == 0 ) { std::cout << "Could not acquire properties of queue families." << std::endl; return false; }初始化逻辑设备,在选择要使用的物理设备之后,我们需要设置一个逻辑设备用于交互。
VkResult result = vkCreateDevice( physical_device, &device_create_info, nullptr, &logical_device ); if( (result != VK_SUCCESS) || (logical_device == VK_NULL_HANDLE) ) { std::cout << "Could not create logical device." << std::endl; return false; } return true;上述初始完毕后,接着初始化Surface,然后我们就可以使用Vulkan进行绘制了
#ifdef VK_USE_PLATFORM_WIN32_KHR //创建WIN32的surface,如果是Android,需要使用VkAndroidSurfaceCreateInfoKHRVkWin32SurfaceCreateInfoKHR surface_create_info = { VK_STRUCTURE_TYPE_WIN32_SURFACE_CREATE_INFO_KHR, nullptr, 0, window_parameters.HInstance, window_parameters.HWnd }; VkResult result = vkCreateWin32SurfaceKHR( instance, &surface_create_info, nullptr, &presentation_surface );2,通过vkCmdDraw函数进行图像绘制
void vkCmdDraw( //在Vulkan中,像绘画命令、内存转换等操作并不是直接通过方法调用去完成的,而是需要把所有的操作放在Command Buffer里 VkCommandBuffer commandBuffer, uint32_t vertexCount, //顶点数量 uint32_t instanceCount, // 要画的instance数量,没有:置1 uint32_t firstVertex,// vertex buffer中第一个位置 和 vertex Shader 里gl_vertexIndex 相关。 uint32_t firstInstance);// 同firstVertex 类似。3,提交buffer
if (vkQueueSubmit(graphicsQueue, 1, &submitInfo, VK_NULL_HANDLE) != VK_SUCCESS) { throw std::runtime_error("failed to submit draw command buffer!");}我在这里比较浅显的介绍了Vulkan的用法,但上面介绍的只是Vulkan的一点皮毛,Vulkan的使用比OpenGL要复杂的很多,机制也复杂很多,如果想进一步了解Vulkan还是得专门去深入研究。虽然只介绍了一点皮毛,但已经可以让我们去了解Vulkan这一图像生产者,是如何在Android系统中生产图像的,下面就来看看吧。
Vulkan进行硬件加速
在前面讲OpenGL 进行硬件加速时,提到了CanvasContext,它会根据渲染的类型选择不同的渲染管线,Android是通过Vulkan或者还是通过OpenGL渲染,主要是CanvasContext里选择的渲染管线的不同。
CanvasContext* CanvasContext::create(RenderThread& thread, bool translucent, RenderNode* rootRenderNode, IContextFactory* contextFactory) { auto renderType = Properties::getRenderPipelineType(); switch (renderType) { case RenderPipelineType::OpenGL: return new CanvasContext(thread, translucent, rootRenderNode, contextFactory, std::make_unique(thread)); case RenderPipelineType::SkiaGL: return new CanvasContext(thread, translucent, rootRenderNode, contextFactory, std::make_unique<:skiaopenglpipeline>(thread)); case RenderPipelineType::SkiaVulkan: return new CanvasContext(thread, translucent, rootRenderNode, contextFactory, std::make_unique<:skiavulkanpipeline>(thread)); default: LOG_ALWAYS_FATAL("canvas context type %d not supported", (int32_t) renderType); break; } return nullptr;}我们这里直接看SkiaVulkanPipeline。
//文件->/frameworks/base/libs/hwui/pipeline/skia/SkiaVulkanPipeline.cppSkiaVulkanPipeline::SkiaVulkanPipeline(renderthread::RenderThread& thread) : SkiaPipeline(thread), mVkManager(thread.vulkanManager()) {}SkiaVulkanPipeline的构造函数中初始化了VulkanManager,VulkanManager是对Vulkan使用的封装,和前面讲到的OpenGLPipeline中的EglManager类似。我们看一下VulkanManager的初始化函数。
//文件-->/frameworks/base/libs/hwui/renderthread/VulkanManager.cppvoid VulkanManager::initialize() { if (hasVkContext()) { return; } auto canPresent = [](VkInstance, VkPhysicalDevice, uint32_t) { return true; }; mBackendContext.reset(GrVkBackendContext::Create(vkGetInstanceProcAddr, vkGetDeviceProcAddr, &mPresentQueueIndex, canPresent)); //……}初始化函数中我们主要关注GrVkBackendContext::Create方法。
// Create the base Vulkan objects needed by the GrVkGpu objectconst GrVkBackendContext* GrVkBackendContext::Create(uint32_t* presentQueueIndexPtr, CanPresentFn canPresent, GrVkInterface::GetProc getProc) { //…… const VkInstanceCreateInfo instance_create = { VK_STRUCTURE_TYPE_INSTANCE_CREATE_INFO, // sType nullptr, // pNext 0, // flags &app_info, // pApplicationInfo (uint32_t) instanceLayerNames.count(), // enabledLayerNameCount instanceLayerNames.begin(), // ppEnabledLayerNames (uint32_t) instanceExtensionNames.count(), // enabledExtensionNameCount instanceExtensionNames.begin(), // ppEnabledExtensionNames }; ACQUIRE_VK_PROC(CreateInstance, VK_NULL_HANDLE, VK_NULL_HANDLE); //1,创建Vulkan实例 err = grVkCreateInstance(&instance_create, nullptr, &inst); if (err < 0) { SkDebugf("vkCreateInstance failed: %d\n", err); return nullptr; } uint32_t gpuCount; //2,查询可用物理设备 err = grVkEnumeratePhysicalDevices(inst, &gpuCount, nullptr); if (err) { //…… } //…… gpuCount = 1; //3,选择物理设备 err = grVkEnumeratePhysicalDevices(inst, &gpuCount, &physDev); if (err) { //…… } //4,查询队列簇 uint32_t queueCount; grVkGetPhysicalDeviceQueueFamilyProperties(physDev, &queueCount, nullptr); if (!queueCount) { //…… return nullptr; } SkAutoMalloc queuePropsAlloc(queueCount * sizeof(VkQueueFamilyProperties)); // now get the actual queue props VkQueueFamilyProperties* queueProps = (VkQueueFamilyProperties*)queuePropsAlloc.get(); //5,选择队列簇 grVkGetPhysicalDeviceQueueFamilyProperties(physDev, &queueCount, queueProps); //…… // iterate to find the graphics queue const VkDeviceCreateInfo deviceInfo = { VK_STRUCTURE_TYPE_DEVICE_CREATE_INFO, // sType nullptr, // pNext 0, // VkDeviceCreateFlags queueInfoCount, // queueCreateInfoCount queueInfo, // pQueueCreateInfos (uint32_t) deviceLayerNames.count(), // layerCount deviceLayerNames.begin(), // ppEnabledLayerNames (uint32_t) deviceExtensionNames.count(), // extensionCount deviceExtensionNames.begin(), // ppEnabledExtensionNames &deviceFeatures // ppEnabledFeatures }; //6,创建逻辑设备 err = grVkCreateDevice(physDev, &deviceInfo, nullptr, &device); if (err) { SkDebugf("CreateDevice failed: %d\n", err); grVkDestroyInstance(inst, nullptr); return nullptr; } auto interface = sk_make_sp(getProc, inst, device, extensionFlags); if (!interface->validate(extensionFlags)) { SkDebugf("Vulkan interface validation failed\n"); grVkDeviceWaitIdle(device); grVkDestroyDevice(device, nullptr); grVkDestroyInstance(inst, nullptr); return nullptr; } VkQueue queue; grVkGetDeviceQueue(device, graphicsQueueIndex, 0, &queue); GrVkBackendContext* ctx = new GrVkBackendContext(); ctx->fInstance = inst; ctx->fPhysicalDevice = physDev; ctx->fDevice = device; ctx->fQueue = queue; ctx->fGraphicsQueueIndex = graphicsQueueIndex; ctx->fMinAPIVersion = kGrVkMinimumVersion; ctx->fExtensions = extensionFlags; ctx->fFeatures = featureFlags; ctx->fInterface.reset(interface.release()); ctx->fOwnsInstanceAndDevice = true; return ctx;}可以看到,GrVkBackendContext::Create中所作的事情就是初始化Vulkan,初始化的流程和前面介绍如何使用Vulkan中初始化流程都是一样的,这些都是通用的流程。
初始化完成,我们接着看看Vulkan如何绑定Surface,只有绑定了Surface,我们才能使用Vulkan进行图像绘制。
//文件-->/frameworks/base/libs/hwui/renderthread/VulkanManager.cppVulkanSurface* VulkanManager::createSurface(ANativeWindow* window) { initialize(); if (!window) { return nullptr; } VulkanSurface* surface = new VulkanSurface(); VkAndroidSurfaceCreateInfoKHR surfaceCreateInfo; memset(&surfaceCreateInfo, 0, sizeof(VkAndroidSurfaceCreateInfoKHR)); surfaceCreateInfo.sType = VK_STRUCTURE_TYPE_ANDROID_SURFACE_CREATE_INFO_KHR; surfaceCreateInfo.pNext = nullptr; surfaceCreateInfo.flags = 0; surfaceCreateInfo.window = window; VkResult res = mCreateAndroidSurfaceKHR(mBackendContext->fInstance, &surfaceCreateInfo, nullptr, &surface->mVkSurface); if (VK_SUCCESS != res) { delete surface; return nullptr; } SkDEBUGCODE(VkBool32 supported; res = mGetPhysicalDeviceSurfaceSupportKHR( mBackendContext->fPhysicalDevice, mPresentQueueIndex, surface->mVkSurface, &supported); // All physical devices and queue families on Android must be capable of // presentation with any // native window. SkASSERT(VK_SUCCESS == res && supported);); if (!createSwapchain(surface)) { destroySurface(surface); return nullptr; } return surface;}可以看到,这个创建了VulkanSurface,并绑定了ANativeWindow,ANativeWindow是Android的原生窗口,在前面介绍OpenGL进行硬件渲染时,也提到过createSurface这个函数,它是在performDraw被执行的,在这里就不重复说了。
接下来就是调用Vulkan的api进行绘制的图像的流程
bool SkiaVulkanPipeline::draw(const Frame& frame, const SkRect& screenDirty, const SkRect& dirty, const FrameBuilder::LightGeometry& lightGeometry, LayerUpdateQueue* layerUpdateQueue, const Rect& contentDrawBounds, bool opaque, bool wideColorGamut, const BakedOpRenderer::LightInfo& lightInfo, const std::vector>& renderNodes, FrameInfoVisualizer* profiler) { sk_sp backBuffer = mVkSurface->getBackBufferSurface(); if (backBuffer.get() == nullptr) { return false; } SkiaPipeline::updateLighting(lightGeometry, lightInfo); renderFrame(*layerUpdateQueue, dirty, renderNodes, opaque, wideColorGamut, contentDrawBounds, backBuffer); layerUpdateQueue->clear(); // Draw visual debugging features if (CC_UNLIKELY(Properties::showDirtyRegions || ProfileType::None != Properties::getProfileType())) { SkCanvas* profileCanvas = backBuffer->getCanvas(); SkiaProfileRenderer profileRenderer(profileCanvas); profiler->draw(profileRenderer); profileCanvas->flush(); } // Log memory statistics if (CC_UNLIKELY(Properties::debugLevel != kDebugDisabled)) { dumpResourceCacheUsage(); } return true;}最后通过swapBuffers提交绘制内容
void VulkanManager::swapBuffers(VulkanSurface* surface) { if (CC_UNLIKELY(Properties::waitForGpuCompletion)) { ATRACE_NAME("Finishing GPU work"); mDeviceWaitIdle(mBackendContext->fDevice); } SkASSERT(surface->mBackbuffers); VulkanSurface::BackbufferInfo* backbuffer = surface->mBackbuffers + surface->mCurrentBackbufferIndex; GrVkImageInfo* imageInfo; SkSurface* skSurface = surface->mImageInfos[backbuffer->mImageIndex].mSurface.get(); skSurface->getRenderTargetHandle((GrBackendObject*)&imageInfo, SkSurface::kFlushRead_BackendHandleAccess); // Check to make sure we never change the actually wrapped image SkASSERT(imageInfo->fImage == surface->mImages[backbuffer->mImageIndex]); // We need to transition the image to VK_IMAGE_LAYOUT_PRESENT_SRC_KHR and make sure that all // previous work is complete for before presenting. So we first add the necessary barrier here. VkImageLayout layout = imageInfo->fImageLayout; VkPipelineStageFlags srcStageMask = layoutToPipelineStageFlags(layout); VkPipelineStageFlags dstStageMask = VK_PIPELINE_STAGE_BOTTOM_OF_PIPE_BIT; VkAccessFlags srcAccessMask = layoutToSrcAccessMask(layout); VkAccessFlags dstAccessMask = VK_ACCESS_MEMORY_READ_BIT; VkImageMemoryBarrier imageMemoryBarrier = { VK_STRUCTURE_TYPE_IMAGE_MEMORY_BARRIER, // sType NULL, // pNext srcAccessMask, // outputMask dstAccessMask, // inputMask layout, // oldLayout VK_IMAGE_LAYOUT_PRESENT_SRC_KHR, // newLayout mBackendContext->fGraphicsQueueIndex, // srcQueueFamilyIndex mPresentQueueIndex, // dstQueueFamilyIndex surface->mImages[backbuffer->mImageIndex], // image {VK_IMAGE_ASPECT_COLOR_BIT, 0, 1, 0, 1} // subresourceRange }; mResetCommandBuffer(backbuffer->mTransitionCmdBuffers[1], 0); VkCommandBufferBeginInfo info; memset(&info, 0, sizeof(VkCommandBufferBeginInfo)); info.sType = VK_STRUCTURE_TYPE_COMMAND_BUFFER_BEGIN_INFO; info.flags = 0; mBeginCommandBuffer(backbuffer->mTransitionCmdBuffers[1], &info); mCmdPipelineBarrier(backbuffer->mTransitionCmdBuffers[1], srcStageMask, dstStageMask, 0, 0, nullptr, 0, nullptr, 1, &imageMemoryBarrier); mEndCommandBuffer(backbuffer->mTransitionCmdBuffers[1]); surface->mImageInfos[backbuffer->mImageIndex].mImageLayout = VK_IMAGE_LAYOUT_PRESENT_SRC_KHR; // insert the layout transfer into the queue and wait on the acquire VkSubmitInfo submitInfo; memset(&submitInfo, 0, sizeof(VkSubmitInfo)); submitInfo.sType = VK_STRUCTURE_TYPE_SUBMIT_INFO; submitInfo.waitSemaphoreCount = 0; submitInfo.pWaitDstStageMask = 0; submitInfo.commandBufferCount = 1; submitInfo.pCommandBuffers = &backbuffer->mTransitionCmdBuffers[1]; submitInfo.signalSemaphoreCount = 1; // When this command buffer finishes we will signal this semaphore so that we know it is now // safe to present the image to the screen. submitInfo.pSignalSemaphores = &backbuffer->mRenderSemaphore; // Attach second fence to submission here so we can track when the command buffer finishes. mQueueSubmit(mBackendContext->fQueue, 1, &submitInfo, backbuffer->mUsageFences[1]); // Submit present operation to present queue. We use a semaphore here to make sure all rendering // to the image is complete and that the layout has been change to present on the graphics // queue. const VkPresentInfoKHR presentInfo = { VK_STRUCTURE_TYPE_PRESENT_INFO_KHR, // sType NULL, // pNext 1, // waitSemaphoreCount &backbuffer->mRenderSemaphore, // pWaitSemaphores 1, // swapchainCount &surface->mSwapchain, // pSwapchains &backbuffer->mImageIndex, // pImageIndices NULL // pResults }; mQueuePresentKHR(mPresentQueue, &presentInfo); surface->mBackbuffer.reset(); surface->mImageInfos[backbuffer->mImageIndex].mLastUsed = surface->mCurrentTime; surface->mImageInfos[backbuffer->mImageIndex].mInvalid = false; surface->mCurrentTime++;}这些流程都和OpenGL是一样的,初始化,绑定Surface,绘制,提交,所以就不细说了,对Vulkan有兴趣的,可以深入的去研究。至此Android中的另一个图像生产者Vulkan生产图像的流程也讲完了。
结尾
OpenGL,Skia,Vulkan都是跨平台的图形生产者,我们不仅仅可以在Android设备上使用,我们也可以在IOS设备上使用,也可以在Windows设备上使用,使用的流程基本和上面一致,但是需要适配设备的原生窗口和缓冲,所以掌握了Android是如何绘制图像的,我们也具备了掌握其他任何设备上是如何绘制图像的能力。
在下一篇文章中,我会介绍Android图像渲染原理的最后一部分:图像缓冲区。这三部分如果都能掌握,我们基本就能掌握Android中图像绘制的原理了。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









