






Nvidia 再出重磅!官方开源了语音识别模型 nvidia/parakeet-tdt-0.6b-v2,该模型目前在 Open ASR Leaderboard 上稳居榜首,实力不容小觑。
一款600M参数的语音模型,竟然能在1秒内转录60分钟的音频,这背后究竟隐藏着怎样的技术力量?更让人兴奋的是,它采用了CC-BY-4.0许可证,允许商业使用,这无疑为众多企业和开发者带来了前所未有的机遇和便利。
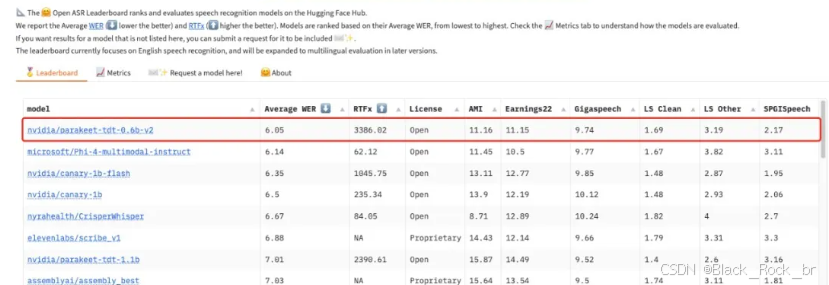
nvidia/parakeet-tdt-0.6b-v2 是一款基于 FastConformer-TDT 架构打造的自动语音识别(ASR)模型,参数规模达 600 万,专为英语语音转文字任务设计。该模型不仅能够识别语音内容,还能自动添加标点符号、区分大小写,并提供精确的时间戳预测功能。

使用场景
该模型适用于开发人员、研究人员、学者以及需要语音到文本功能的应用程序构建者。具体来说,它在以下领域有着广泛的应用前景:
对话式AI
开发人员可以利用该模型为聊天机器人和虚拟助手提供更精准的语音识别能力,使其能够更自然地与用户进行交互。例如,智能客服系统可以通过该模型快速准确地理解客户的语音指令,从而提供更高效的服务。
语音助手
对于语音助手的开发者而言,该模型能够显著提升语音指令的识别速度和准确性。无论是智能家居设备、智能手机还是车载系统,用户都可以通过语音指令快速获取信息或控制设备,极大地提高了用户体验。
转录服务
在转录服务领域,该模型可以大幅提高工作效率。无论是会议记录、讲座内容还是采访音频,该模型都能在短时间内完成高质量的转录,为媒体、教育和企业等行业提供了强大的支持。
字幕生成
对于视频内容创作者和媒体公司来说,该模型可以自动为视频生成字幕,节省大量时间和人力成本。无论是电影、电视剧还是在线课程,准确的字幕生成能够提升内容的可访问性和国际化程度。
语音分析平台
研究人员和企业可以利用该模型对语音数据进行深入分析。例如,在市场调研中,通过分析客户反馈的语音数据,企业可以更好地了解客户需求和市场趋势;在医疗领域,该模型可以帮助分析患者的语音症状,辅助诊断和治疗。
总之,这款模型凭借其卓越的性能和广泛的应用场景,为开发人员、研究人员、学者以及各类应用程序构建者提供了强大的工具,极大地推动了语音技术在各个领域的创新和发展。
体验:
https://huggingface.co/spaces/nvidia/parakeet-tdt-0.6b-v2
本地使用:
我自己用macbook 所以这里贴出:
macOS 平台
对于 macOS 平台来说,我们可以通过安装 parakeet-mlx 这个库,来使用 nvidia/parakeet-tdt-0.6b-v2 模型。
最简单的方式,是通过安装 CLI 的方式来运行 parakeet-mlx。
对于 macOS 平台来说,我们可以通过安装 parakeet-mlx 这个库,来使用 nvidia/parakeet-tdt-0.6b-v2 模型。
最简单的方式,是通过安装 CLI 的方式来运行 parakeet-mlx。
uv tool install parakeet-mlx -U
成功安装 parakeet-mlx CLI 之后,就可以在命令行中直接转录音频文件:
# Basic transcription
parakeet-mlx audio.mp3
# Multiple files with word-level timestamps of VTT subtitle
parakeet-mlx *.mp3 --output-format vtt --highlight-words
# Generate all output formats
parakeet-mlx audio.mp3 --output-format all
parakeet-mlx 也提供了 Python API,方便我们快速集成到已有的应用中。
1.安装依赖
pip install parakeet-mlx -U
# or
uv add parakeet-mlx -U
2.转录音频文件
from parakeet_mlx import from_pretrained
model = from_pretrained("mlx-community/parakeet-tdt-0.6b-v2")
result = model.transcribe("audio_file.wav")
print(result.text)
需要注意的是,from_pretrained 方法也支持本地的路径。当转录成功后,我们可以通过 result.sentences 来获取包含时间戳的文本。
from parakeet_mlx import from_pretrained
model = from_pretrained("mlx-community/parakeet-tdt-0.6b-v2")
result = model.transcribe("audio_file.wav")
print(result.sentences)
# [AlignedSentence(text="Hello World.", start=1.01, end=2.04, duration=1.03, tokens=[...])]快来试试吧!

















 569
569

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









