







前言
Java中volatile这个热门的关键字,在面试中经常会被提及,在各种技术交流群中也经常被讨论,但似乎讨论不出一个完美的结果,带着种种疑惑,准备从JVM、C++、汇编的角度重新梳理一遍。
volatile的两大特性:禁止重排序、内存可见性。
概念是知道了,但还是很迷糊,它们到底是如何实现的?
本文会涉及到一些汇编方面的内容,如果多看几遍,应该能看懂。
重排序
为了理解重排序,先看一段简单的代码public class VolatileTest { int a = 0; int b = 0; public void set() { a = 1; b = 1; } public void loop() { while (b == 0) continue; if (a == 1) { System.out.println("i'm here"); } else { System.out.println("what's wrong"); } }}VolatileTest类有两个方法,分别是set()和loop(),假设线程B执行loop方法,线程A执行set方法,会得到什么结果?
答案是不确定,因为这里涉及到了编译器的重排序和CPU指令的重排序。
编译器重排序
编译器在不改变单线程语义的前提下,为了提高程序的运行速度,可以对字节码指令进行重新排序,所以代码中a、b的赋值顺序,被编译之后可能就变成了先设置b,再设置a。
因为对于线程A来说,先设置哪个,都不影响自身的结果。
CPU指令重排序
CPU指令重排序又是怎么回事?
在深入理解之前,先看看x86的cpu缓存结构。
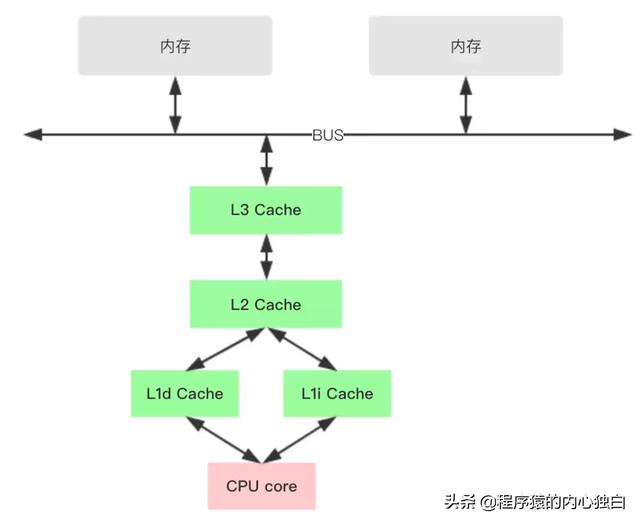
1、各种寄存器,用来存储本地变量和函数参数,访问一次需要1cycle,耗时小于1ns;
2、L1 Cache,一级缓存,本地core的缓存,分成32K的数据缓存L1d和32k指令缓存L1i,访问L1需要3cycles,耗时大约1ns;
3、L2 Cache,二级缓存,本地core的缓存,被设计为L1缓存与共享的L3缓存之间的缓冲,大小为256K,访问L2需要12cycles,耗时大约3ns;
4、L3 Cache,三级缓存,在同插槽的所有core共享L3缓存,分为多个2M的段,访问L3需要38cycles,耗时大约12ns;
当然了,还有平时熟知的DRAM,访问内存一般需要65ns,所以CPU访问一次内存和缓存比较起来显得很慢。
对于不同插槽的CPU,L1和L2的数据并不共享,一般通过MESI协议保证Cache的一致性,但需要付出代价。
在MESI协议中,每个Cache line有4种状态,分别是:
1、M(Modified)
这行数据有效,但是被修改了,和内存中的数据不一致,数据只存在于本Cache中</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 145
145











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









