





在数据分析过程中,首先就是对数据进行清洗和处理,而使用 python 进行处理的朋友们,对 pandas 包肯定是熟悉不过的了。pandas 的功能很强大,基本的数据处理操作都可以找到对应函数去使用,想全面了解的朋友可以查看相关文档。在这里,通过这篇文章分享整理了自己平时常用的函数和经验:
1.数据查看
数据量过大时,直接打印变量无法全面进行展示,这时候可以通过函数对数据框中前后几条数据进行查看,方便我们初步去了解数据的一个大体情况:
import 
1.1 查看数据前/后几行
data.head(3) #不写几行默认5行
data.tail(2)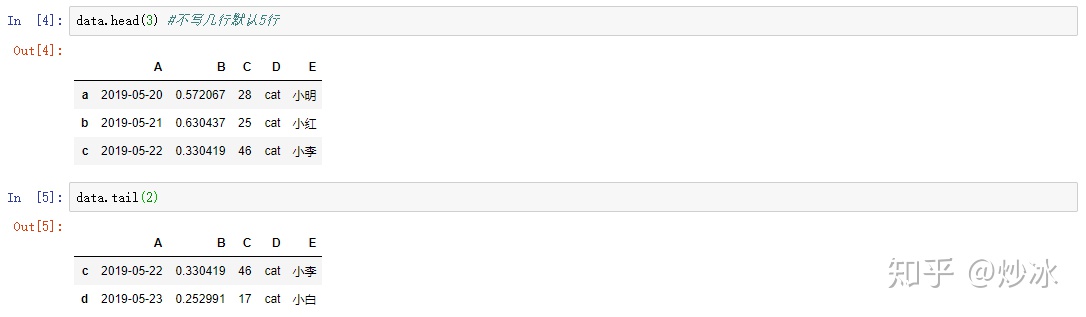
1.2 查看数据索引
data.index
1.3 查看列名
data.columns
1.4 查看数据类型
data.dtypes
1.5 查看数据的基本分布情况
只对数值类型的字段有作用,包括了计数,均值,标准差,最大最小值和四分位数
data.describe()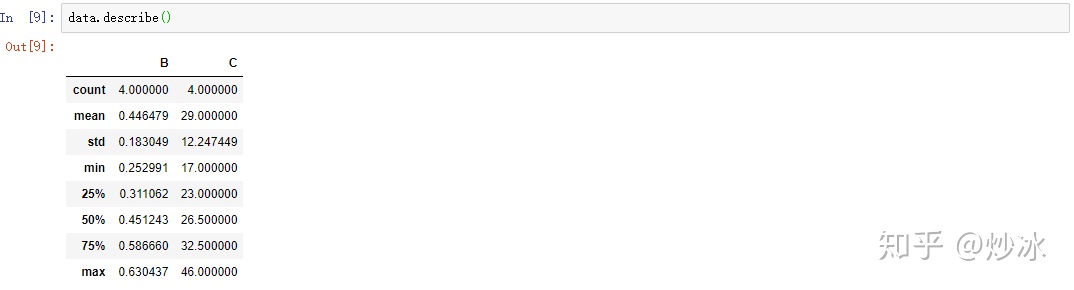
2. 数据筛选
数据切片是处理函数中经常需要使用到的操作,相类似于 sql 语句中的 select。ps:同样使用以上面数据框 data 作为示例,下同。
2.1 列切片
data['A']
data[['A', 'B']] # 同时选择多列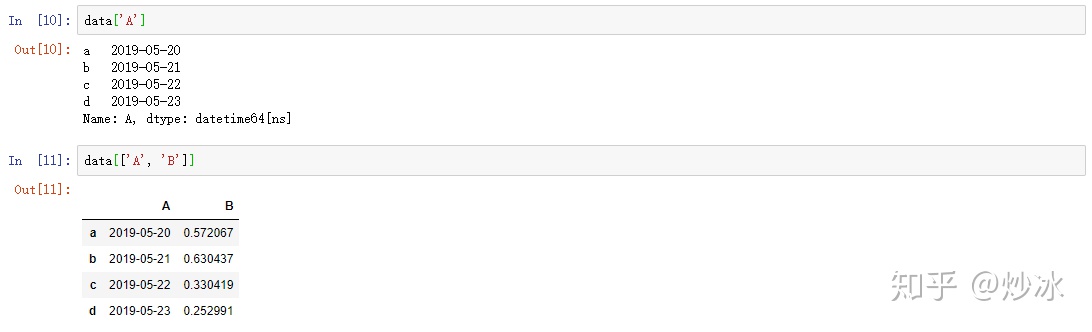
2.2 行切片
data[2:4] # 选择第2到第三3行
data['b':'c'] # 选择多行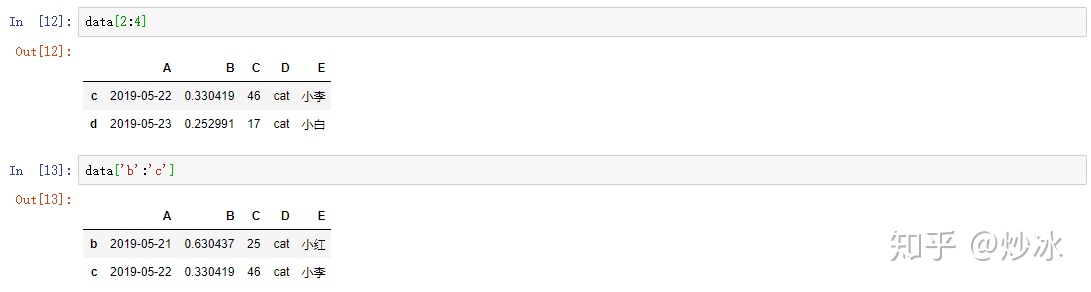
2.3 同时对行列进行切片
# 通过标签进行筛选
data.loc['a':'c', ['A', 'C']]
data.loc[['a','c'], ['A', 'C']]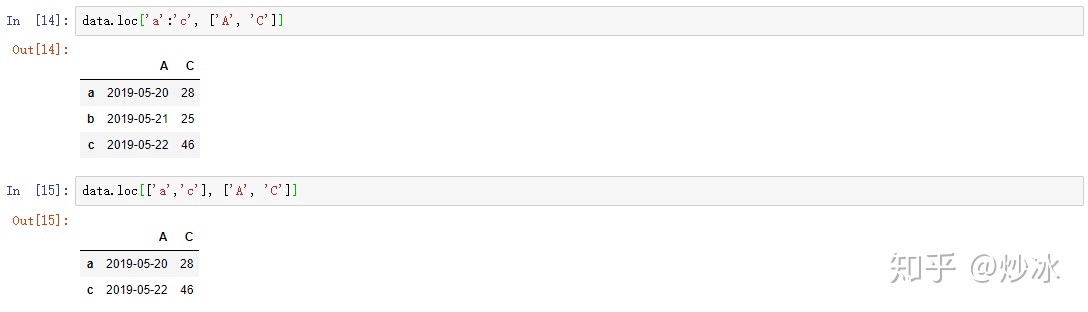
# 通过位置进行筛选
data.iloc[3] # 不指定列的话,默认是选择行,单独选择某一行的话返回的不是一个数据框
data.iloc[2:4] # 返回一个数据框
data.iloc[:, 1] # 选择单列,返回的不是一个数据框
data.iloc[:, 1:3] # 选择多列
data.iloc[[1, 2, 3], [0, 2]] # 选择不连续的多行多列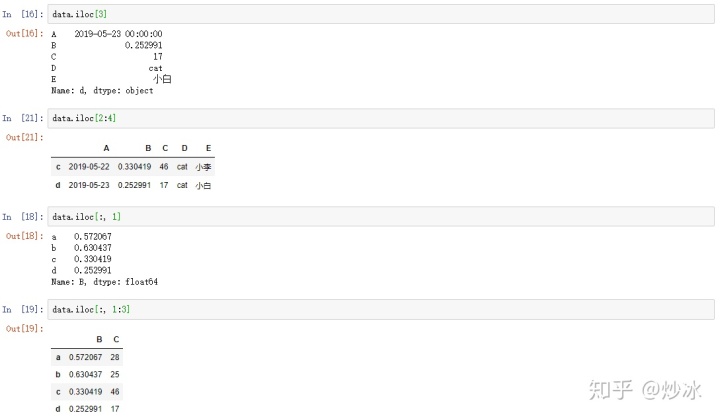

2.4 条件筛选
# 单条件
data[data['C'] >= 30 ]
# 单列多条件
data[data['E'].isin(['小白', '小明'])]
# 多列多条件
data.loc[(data['B']>0.5) & (data['C']<30)]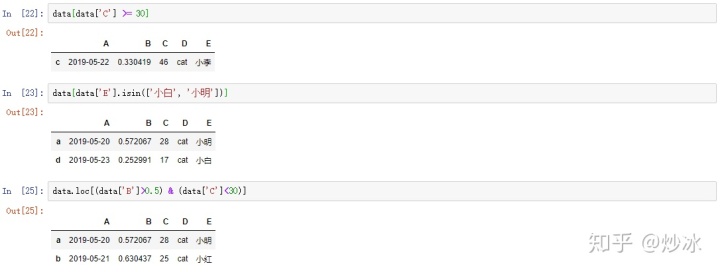
3. 数据增加
3.1 添加新的列
# 增加一列同样的值
data['F'] = 1
# 增加一列不一致的值(可以是series也可以是list)
data['G'] = pd.Series([11, 22, 33, 44], index=['a', 'b', 'c', 'd'])
data['H'] = [1, 2, 3, 4]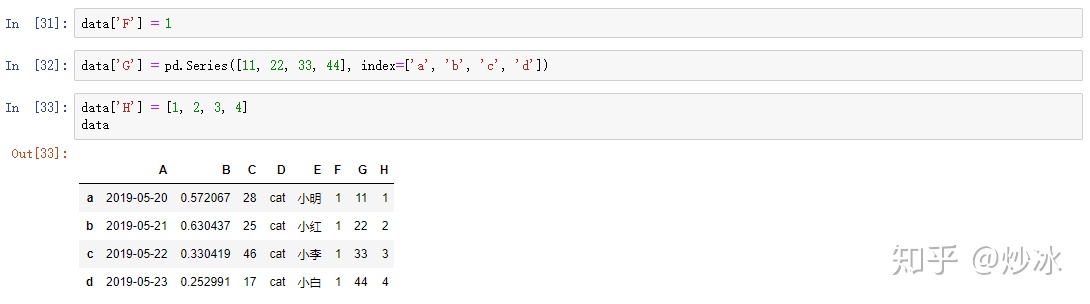
3.2 添加新的行
append:
data.append(data.iloc[2:4])
data.append(data.iloc[3], ignore_index=True) #参数ignore_index=True,索引重新排列, 默认是False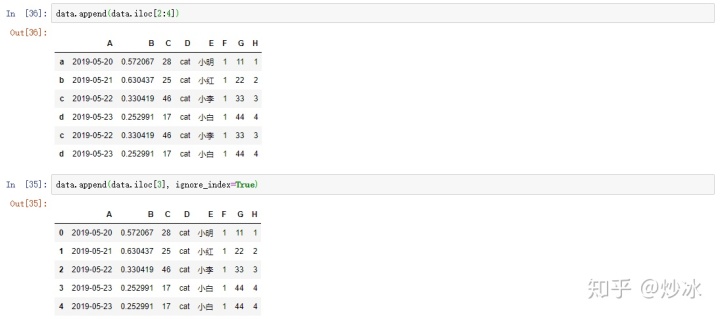
concat: 同样有ignore_index参数,可以有字段不一致的情况。PS:合并的对象必须是dataframe
pd.concat([data, data.iloc[1:3]], ignore_index=True)
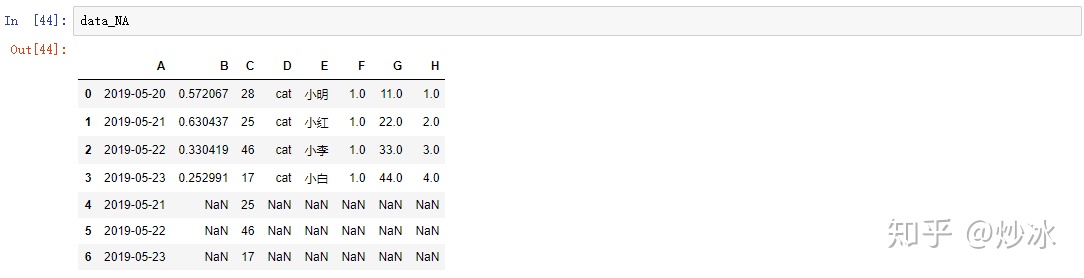
data_NA = pd.concat([data, data.iloc[[1, 2, 3], [0, 2]]], ignore_index=True)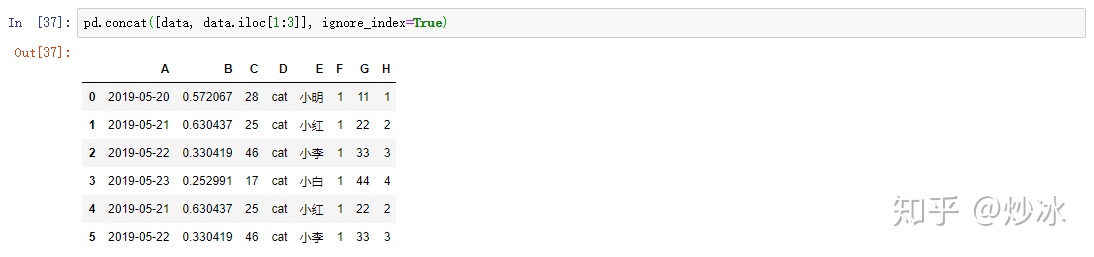
3.3 数据连接
merge: 两个数据表连接,类似于 sql 语句中的 join,字段可以不一致
pd.merge(data, data.iloc[[1, 2, 3], [0, 2]], on='A')
4. 数据修改
dataframe 中的数据都是可以进行修改的,具体如下所示:
# 修改某一列
data['F'] = data['F'] + 1
# 修改某个值
data['F'].iloc[2] = 23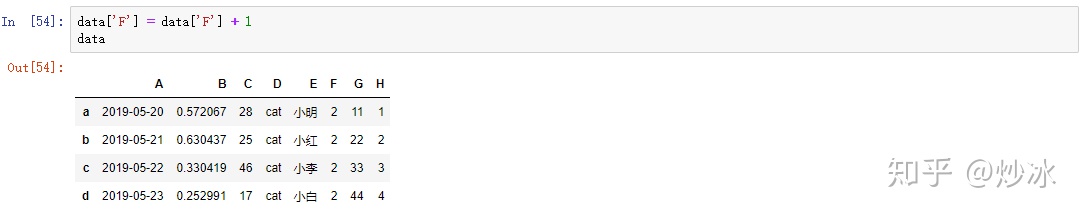


5. 数据删除
5.1 删除列
data_drop = data.drop('A', axis=1) # 此时的data仍然是完整的
5.2 删除行
data_drop = data.drop('a', axis=0) # 对于满足条件的索引列表进行删除
6. 常见数据的读入写出
6.1 Excel
# 读入
data = pd.read_excel('data.xlsx', encoding='utf8')
# 写出
data.to_excel('data.xlsx', encoding='utf8', index=None)6.2 CSV
# 读入
data = pd.read_csv('data.csv', encoding='utf8')
# 写出
data.to_csv('data.csv', encoding='utf8', index=None)6.3 txt
def load_data(file_path, encoding='utf8'):
"""
导入数据
:param file_path: 数据存放路径
:return: 返回数据列表
"""
f = open(file_path, encoding=encoding)
data = []
for line in f.readlines():
row = [] # 记录每一行
lines = line.strip().split("t") # 各字段按制表符切割
for x in lines:
row.append(x)
data.append(row)
f.close()
return data
data = load_data('data.txt', encoding='utf8')
data = pd.DataFrame(data[1:], columns=data[0]) # 第一行为字段名7. 处理异常值、重复值
7.1 NA
# 查看nan值分布的情况
pd.isna(data_NA)
pd.isna(data_NA['H'])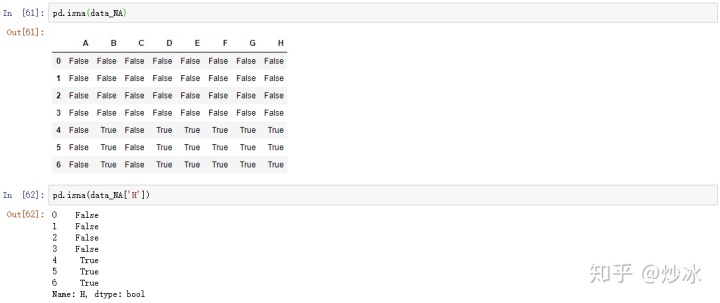
# 将nan填充成指定的值
data_NA['B'] = data_NA['B'].fillna(0)
data_NA = data_NA.fillna(0)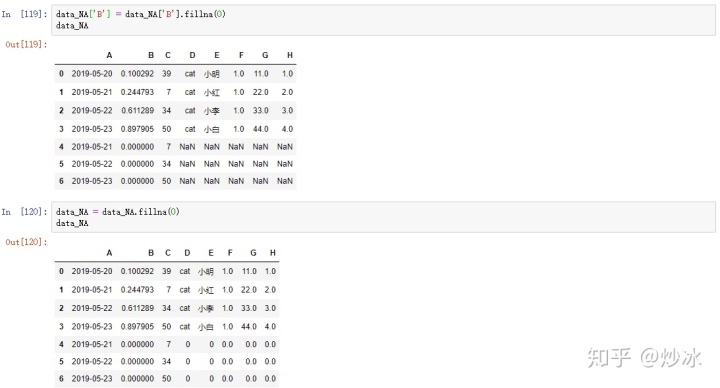
# 将数据中nan的数据全部替换成None,这样int类型或str类型的数据入mysql数据库的时候都显示是null
data_NA = pd.concat([data, data.iloc[[1, 2, 3], [0, 2]]], ignore_index=True)
data_NA_1 = data_NA.where(data_NA.notnull(), None)

# 删除nan值
data_NA.dropna(how='any', axis=0) # 只要出现 nan 的行就删除, 删除列则改为 axis=1
data_NA.dropna(subset=['B']) # 对指定列出现 nan 的行进行删除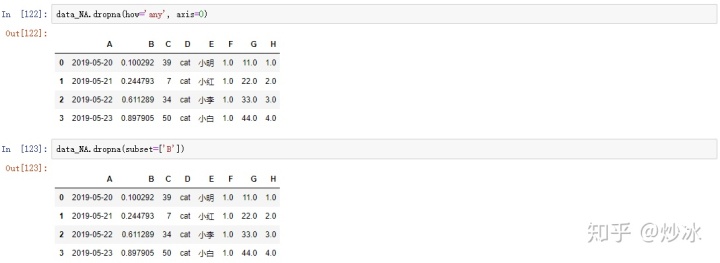
7.2 重复值
# 查看重复数据
data.duplicated()
data.duplicated(['D'])
# 对全部字段进行去重
data_dropdup = data.drop_duplicates()
# 对指定字段进行去重操作
data_dropdup = data.drop_duplicates(['C', 'F']) 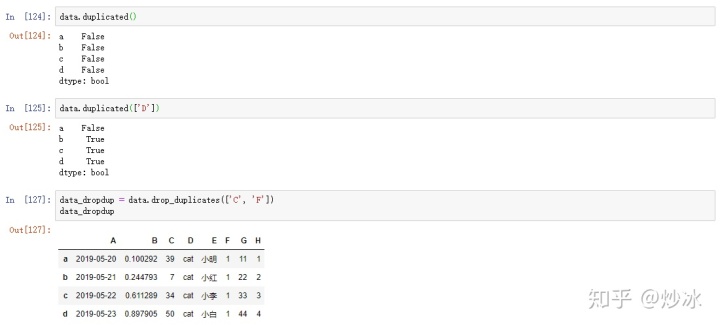
8. dataframe 的属性
8.1 数据框的索引重排列
适用于数据框筛选、合并等导致索引不连续的情况
data = data.reset_index(drop=True)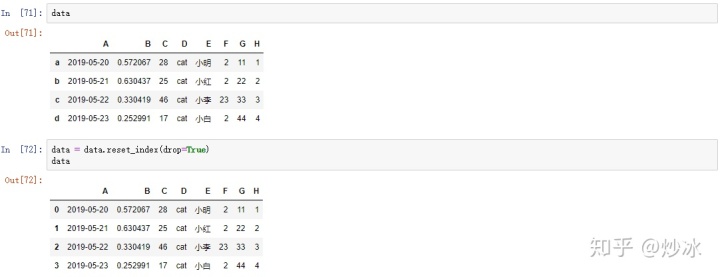
8.2 数据框的列名修改
data.columns = ['A1', 'B1', 'C1', 'D1', 'E1', 'F1', 'G1', 'H1']
8.3 修改数据框或者指定列的类型
data['B1'] = data['B1'].astype('int') # int 类型导致小数点后面被舍弃了
9. mysql数据库操作
import sqlalchemy
# 读取
conn = sqlalchemy.create_engine('mysql+pymysql://用户名:密码@IP/数据库名?charset='数据库编码')
da = pd.read_sql("SELECT * FROM 表名;",conn) #双引号里可以放入sql语句
Ps:若是类似LIKE '%文字%' 的结构,则需要改成LIKE '%%文字%%'
# 写入
pd.io.sql.to_sql(dataframe, '表名', conn, schema='数据库名', if_exists='append', index=False) # index=False表示不把索引写入10. 遍历计算
只将遍历计算作用在某一列上
data['G1'] = data['G1'].astype(str).apply(lambda x : 'ZZ'+str(x)) # spply里面可以定义匿名函数
直接将整个dataframe的每一列都套用函数进行遍历计算
data = data.apply(lambda x : str(x)+1) # 只能用于当操作可以适用于每个字段的类型的情况11. 分组和统计个数
import pandas as pd
import numpy as np
data = pd.DataFrame({'H':np.random.randint(2, 8, size=10),
'J':np.random.randint(0, 5, size=10),
'K':np.random.uniform(size=10)})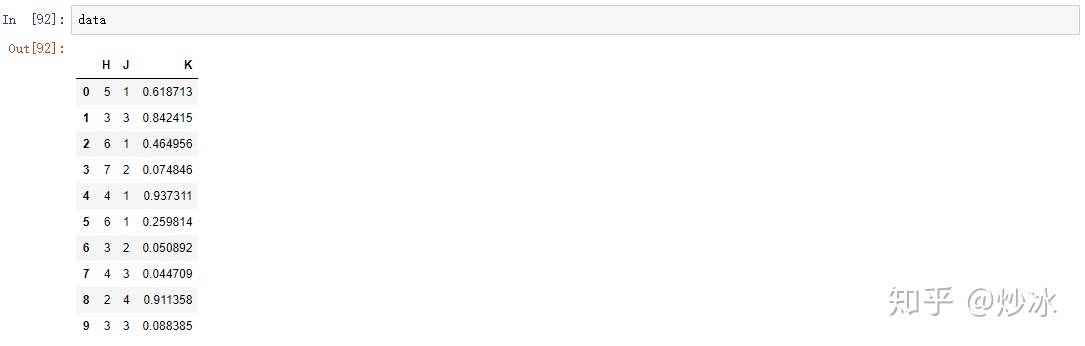
# 分组
data.groupby('H').sum() # 对H进行分组并展示剩余数值类型列的和
data.groupby('H')['J'].sum() # 对H进行分组并展示相对应的J列的和
data.groupby(['H', 'J']).sum() # 对H,J进行分组并展示相对应的剩余数值类型列的和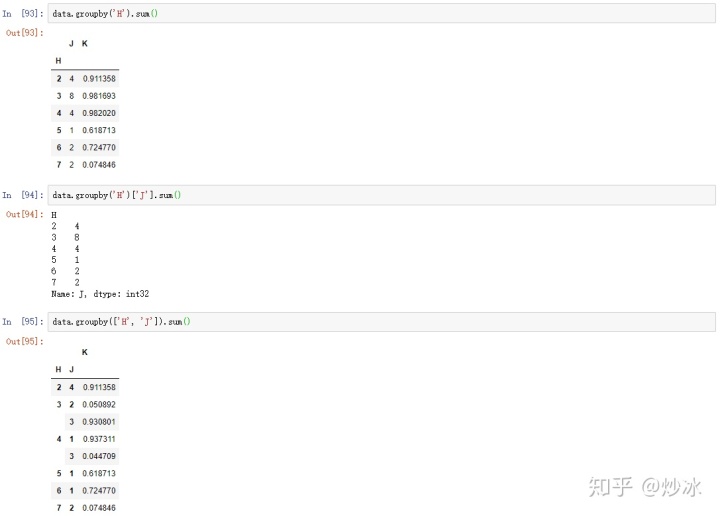
# 统计data中H列每个值出现的次数
result1 = data['H'].value_counts() # 按照计数量的大小排序
以下和上面得到结果一致
result2 = data.groupby('H')['H'].count() # 对H进行分组并展示相对应的H列的个数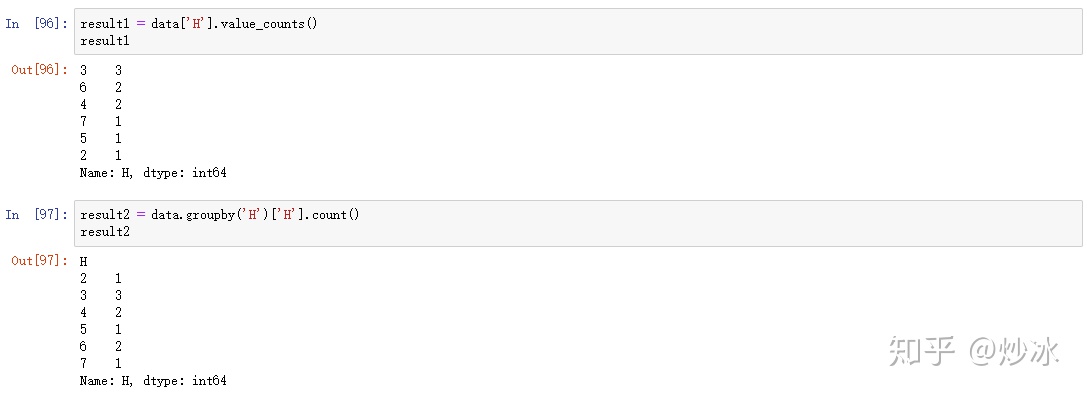
12. 数据塑性——长宽表变换
import pandas as pd
import numpy as np
data_start = pd.DataFrame({
"城市":["广州","深圳","上海","杭州","北京"],
"销售1部":[877,932,970,340,234],
"销售2部":[453,899,290,213,555],
"销售3部":[663,380,223,900,330],
"销售4部":[505,800,200,252,330] })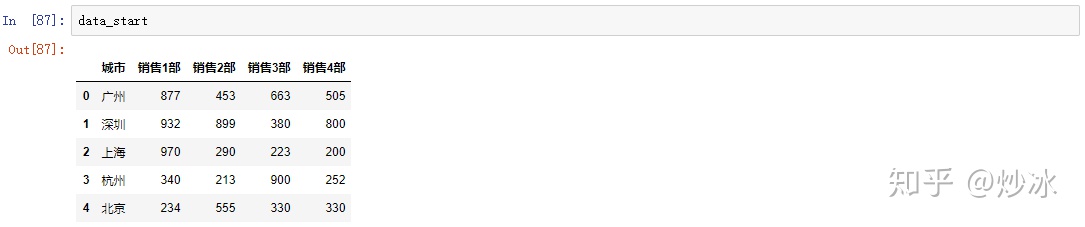
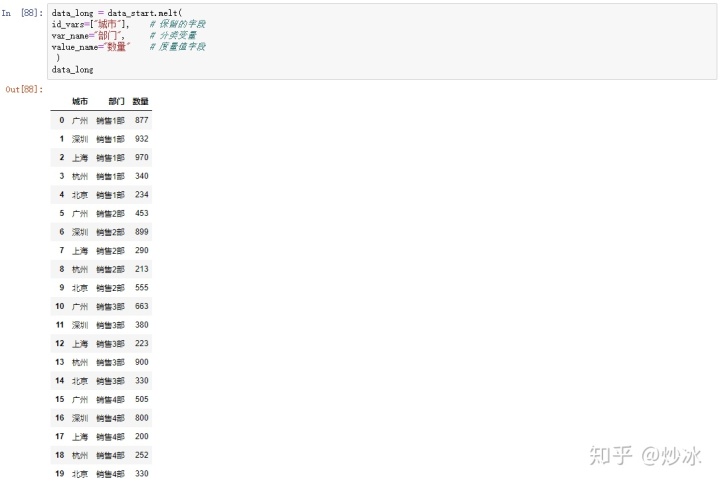
12.1 宽变长
在数据分析中,经常需要长表数据去绘制图表或者训练模型,而当你拿到的数据数汇总后的表格时,便可以采用宽表转长表的方式
data_long = data_start.melt(
id_vars=["城市"], # 保留的字段
var_name="部门", # 分类变量
value_name="数量" # 度量值字段
)
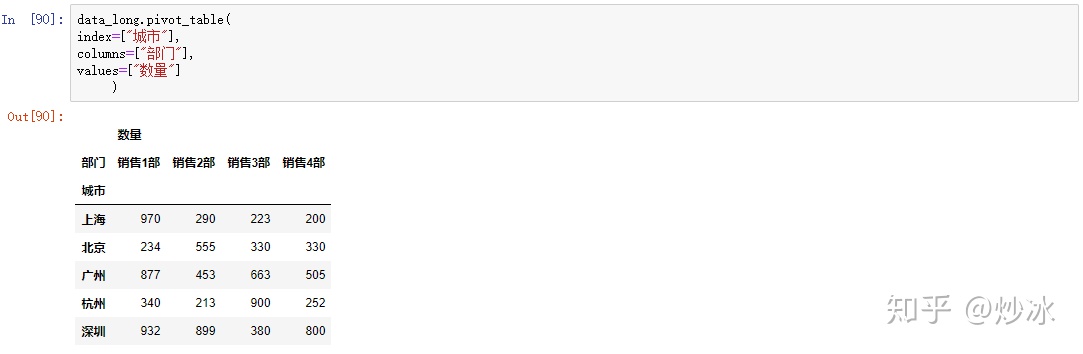
12.2 长变宽
用于数据汇总,比较不常用
data_long.pivot_table(
index=["城市"], #行(可以是多类别变量)
columns=["部门"], #列(可以是多类别变量)
values=["数量"] #值
)
关于 pandas 数据处理的常用操作就分享到这里啦,有其他常用便捷的方法欢迎在下方留言哦~
如果对你有用的话,随手点个赞哟














 4433
4433











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









