





昨天开始看text matching的一个很好的资源,有文献有讲解有代码
今天看了DRCN的网络结构部分,代码部分还在进行中...
贴上原作者的地址:
文本匹配模型之DRCN - Welcome to AI Worldterrifyzhao.github.io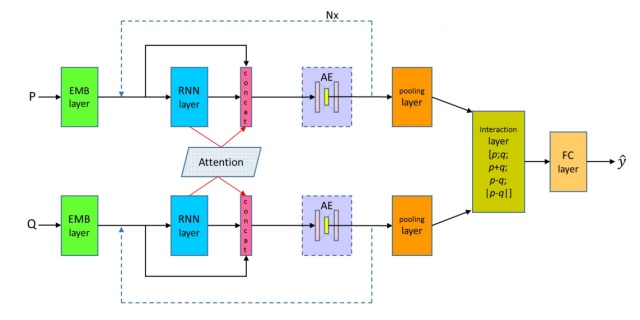

W2V的源码阅读记录---20190815
word2vec_dynamic.py
0.基础函数
list.extend(list2)
#把list2的每个值都加到list的末尾collections.deque()
#生成双端队列,方便从两端appendnp.random.choice的用法
# 参数意思分别 是从a 中以概率P,随机选择3个, p没有指定的时候相当于是一致的分布
#TF的函数接口
tf.name_scope(‘inputs’) 总结:
1. `tf.variable_scope`和`tf.get_variable`必须要搭配使用 (全局scope除外),为share提供支持。
2. `tf.Variable`可以单独使用,也可以搭配`tf.name_scope`使用,给变量分类命名,模块化。
- `tf.Variable`和`tf.variable_scope`搭配使用不伦不类,不是设计者的初衷
'''
tf.random_uniform((6, 6), minval=low,maxval=high,dtype=tf.float32)))
返回6*6的矩阵,产生于low和high之间,产生的值是均匀分布的。
tf.nn.embedding_lookup(embeddings, train_inputs)
#作用是查找embeddings矩阵中,index为[train_inputs]的向量tf.summary.scalar(‘mean’,mean)
#显示标量信息,用于收集一维标量
loss = tf.reduce_mean( tf.nn.nce_loss())
mean_0 关于NCEloss的实现:
_compute_sampled_logits: 通过这个函数计算出正样本和采样出的负样本对应的output和label;
sigmoid_cross_entropy_with_logits: 通过 sigmoid cross entropy来计算output和label的loss,从而进行反向传播。这个函数把最后的问题转化为了num_sampled+num_real个两类分类问题,然后每个分类问题用了交叉熵的损伤函数,也就是logistic regression常用的损失函数。TF里还提供了一个softmax_cross_entropy_with_logits的函数,和这个有所区别。
优化器
#SGD
tf.multiply(x, y, name=None) 和 tf.matmul()
tf计算图Graph最后步骤
# Merge all summaries.
计算图的训练
tf模型保存
saver1. word2vec_basic(log_dir) —–> load_data()
1. 编码
df1 = pd.read_csv('input/train.csv', encoding='utf-8-sig')
df1 2. re.sub()正则
segments = list(
map(
lambda x: list(jieba.cut(re.sub("[!,。?、~@#¥%&*().,::|/`()_;+;…-s]", "", x))), df_sentences))
'''
re.sub(pattern, repl, string, count=0, flags=0)
pattern,表示正则中的模式字符串。
反斜杠加数字(N),则对应着匹配的组(matched group)
比如6,表示匹配前面pattern中的第6个group
repl,就是replacement,被替换,的字符串的意思。repl可以是字符串,也可以是函数。
'''
str.replace(old, new[, max])
str.strip()对于这个函数要记住3点:
- 默认删除行首或者行尾的空白符(包括'n', 'r', 't', ' ')
- 从行首行尾开始逐次判断删除
- lstrip() rstrip()
s匹配任意空白字符,等价于 [tnrf].
S匹配任意非空字符
[Pp]ython匹配 "Python" 或 "python"
rub[ye]匹配 "ruby" 或 "rube"
[aeiou]匹配中括号内的任意一个字母
[0-9]匹配任何数字。类似于 [0123456789]
[a-z]匹配任何小写字母[A-Z]匹配任何大写字母
[a-zA-Z0-9]匹配任何字母及数字
[^aeiou]除了aeiou字母以外的所有字符
[^0-9]匹配除了数字外的字符
3.map()
map(function, iterable, ...)
#这里,是把['','','']通过lambda依次取出str进行re.sub()和jieba.lcut()
'''
所以,整个语句最后输出segments是[
[],[]
],每个子list中存放的是str(分词后的)
'''
2. word2vec_basic —> bulid_dataset(words, min_count)
把行输入处理成dataset
1.collections.Counter(words).most_common()
collection3.W2V的step2
vocabulary 4.W2V的step3
为skip-gram生成训练batch
num_skips:表示选择挤兑数据,如skip_window是2,与target有关的就是4个,当num_skips==3,随机选择三个词与target组队训练
generate_batch(batch_size, num_skips, skip_window)—-》 return batch,labels
5.W2V的step4
建立计算图,用于训练skip-gram模型
6.W2V的step5
开始训练
with 














 5332
5332











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









