









卷积神经网络
当你听到说深度学习打破了某项新技术障碍,那么十有八九就会涉及到卷积神经网络。它们也被称作CNNs或着ConvNets,是深层神经网络领域的主力。它们已经学会对图像进行分类,在某些情况下甚至超过了人类。如果有一个方法证明了这种假设,那就是CNN。
为了帮助指导你理解卷积神经网络,我们讲采用一个非常简化的例子:确定一幅图像是包含有"X"还是"O"?

这个例子足够说明CNN背后的原理,同时它足够简单,能够避免陷入不必要的细节。在CNN中有这样一个问题,就是每次给你一张图,你需要判断它是否含有"X"或者"O"。并且假设必须两者选其一,不是"X"就是"O"。理想的情况就像下面这个样子:

对于计算机来说,只要图像稍稍有一点变化,不是标准的,那么要解决这个问题还是不是那么容易的:

计算机要解决上面这个问题,一个比较天真的做法就是先保存一张"X"和"O"的标准图像(就像前面给出的例子),然后将其他的新给出的图像来和这两张标准图像进行对比,看看到底和哪一张图更匹配,就判断为哪个字母。但是这么做的话,其实是非常不可靠的,因为计算机还是比较死板的。在计算机的“视觉”中,一幅图看起来就像是一个二维的像素数组(可以想象成一个棋盘),每一个位置对应一个数字。在我们这个例子当中,像素值"1"代表白色,像素值"-1"代表黑色。

当比较两幅图的时候,如果有任何一个像素值不匹配,那么这两幅图就不匹配,至少对于计算机来说是这样的。
对于这个例子,计算机认为上述两幅图中的白色像素除了中间的3*3的小方格里面是相同的,其他四个角上都不同:

因此,从表面上看,计算机判别右边那幅图不是"X",两幅图不同,得出结论:
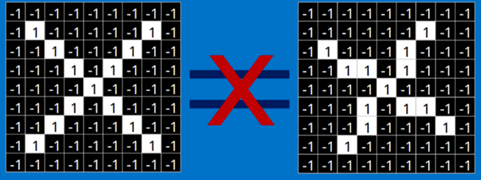
但是这么做,显得太不合理了。理想的情况下,我们希望,对于那些仅仅只是做了一些像平移,缩放,旋转,微变形等简单变换的图像,计算机仍然能够识别出图中的"X"和"O"。就像下面这些情况,我们希望计算机依然能够很快并且很准的识别出来:

这也就是CNN出现所要解决的问题
Features
对于CNN来说,它是一块一块地来进行比对。它拿来比对的这个“小块”我们称之为Features(特征)。在两幅图中大致相同的位置找到一些粗糙的特征进行匹配,CNN能够更好的看到两幅图的相似性,相比起传统的整幅图逐一比对的方法。

每一个feature就像是一个小图(就是一个比较小的有值的二维数组)。不同的Feature匹配图像中不同的特征。在字母"X"的例子中,那些由对角线和交叉线组成的features基本上能够识别出大多数"X"所具有的重要特征。

这些features很有可能就是匹配任何含有字母"X"的图中字母X的四个角和它的中心。那么具体到底是怎么匹配的呢?如下:





看到这里是不是有了一点头目呢。但其实这只是第一步,你知道了这些Features是怎么在原图上面进行匹配的。但是你还不知道在这里面究竟进行的是怎样的数学计算,比如这个下面3*3的小块到底干了什么?

接下来就跟进介绍里面的数学操作,也就是我们常说的“卷积”操作。
卷积操作(Convolution)


当给你一张新的图时,CNN并不能准确地知道这些features到底要匹配原图的哪些部分,所以它会在原图中每一个可能的位置进行尝试。这样在原始整幅图上每一个位置进行匹配计算,我们相当于把这个feature变成了一个过滤器。这个我们用来匹配的过程就被称为卷积操作,这也就是卷积神经网络名字的由来。
这个卷积操作背后的数学知识其实非常的简单。要计算一个feature和其在原图上对应的某一小块的结果,只需要简单地将两个小块内对应位置的像素值进行乘法运算,然后将整个小块内乘法运算的结果累加起来,最后再除以小块内像素点总个数即可。如果两个像素点都是白色(也就是值均为1),那么1*1 = 1,如果均为黑色,那么(-1)*(-1) = 1。不管哪种情况,每一对能够匹配上的像素,其相乘结果为1。类似地,任何不匹配的像素相乘结果为-1。如果一个feature(比如n*n)内部所有的像素都和原图中对应一小块(n*n)匹配上了,那么它们对应像素值相乘再累加就等于n2,然后除以像素点总个数n2,结果就是1。同理,如果每一个像素都不匹配,那么结果就是-1。具体过程如下:







对于中间部分,也是一样的操作:



最后整张图算完,大概就像下面这个样子:

然后换用其他feature进行同样的操作,最后得到的结果就是这样了:

为了完成我们的卷积,我们不断地重复着上述过程,将feature和图中每一块进行卷积操作。最后通过每一个feature的卷积操作,我们会得到一个新的二维数组。这也可以理解为对原始图像进行过滤的结果,我们称之为feature map,它是每一个feature从原始图像中提取出来的“特征”。其中的值,越接近为1表示对应位置和feature的匹配越完整,越是接近-1,表示对应位置和feature的反面匹配越完整,而值接近0的表示对应位置没有任何匹配或者说没有什么关联。

这样我们的原始图,经过不同feature的卷积操作就变成了一系列的feature map。我们可以很方便,直观地将这整个操作视为一个单独的处理过程。在CNN中,我们称之为卷积层(convolution layer),这样你可能很快就会想到后面肯定还有其他的layer。没错,后面会提到。我们可以将卷积层看成下面这个样子:

因此可想而知,CNN其实做的操作也没什么复杂的。但是尽管我们能够以这一点篇幅就描述了CNN的工作,其内部的加法,乘法和除法操作的次数其实会增加地很快。从数学的角度来说,它们会随着图像的大小,每一个filter的大小和filter的数目呈线性增长。由于有这么多因素的影响,很容易使得这个问题的计算量变得相当的庞大,这也难怪很多微处理器制造商现在都在生产制造专业的芯片来跟上CNN计算的需求。
池化(Pooling)
CNN中使用的另一个有效的工具被称为“池化(Pooling)”。池化可以将一幅大的图像缩小,同时又保留其中的重要信息。池化背后的数学顶多也就是小学二年级水平。它就是将输入图像进行缩小,减少像素信息,只保留重要信息。通常情况下,池化都是2*2大小,比如对于max-pooling来说,就是取输入图像中2*2大小的块中的最大值,作为结果的像素值,相当于将原始图像缩小了4倍。(注:同理,对于average-pooling来说,就是取2*2大小块的平均值作为结果的像素值。)
对于本文的这个例子,池化操作具体如下:



不足的外补“0”


经过最大池化操作(比如2*2大小)之后,一幅图就缩小为原来的四分之一了:

然后对所有的feature map执行同样的操作,得到如下结果:

因为最大池化(max-pooling)保留了每一个小块内的最大值,所以它相当于保留了这一块最佳的匹配结果(因为值越接近1表示匹配越好)。这也就意味着它不会具体关注窗口内到底是哪一个地方匹配了,而只关注是不是有某个地方匹配上了。这也就能够看出,CNN能够发现图像中是否具有某种特征,而不用在意到底在哪里具有这种特征。这也就能够帮助解决之前提到的计算机逐一像素匹配的死板做法。
当对所有的feature map执行池化操作之后,相当于一系列输入的大图变成了一系列小图。同样地,我们可以将这整个操作看作是一个操作,这也就是CNN中的池化层(pooling layer),如下:

通过加入池化层,可以很大程度上减少计算量,降低机器负载。
激活函数Relu (Rectified Linear Units)
这是一个很小但是很重要的操作,叫做Relu(Rectified Linear Units),或者修正线性单元。它的数学公式也很简单。对于输入的负值,输出全为0,对于正值,原样输出。下面我们看一下本文的例子中relu激活函数具体操作:


最后,对整幅图操作之后,结果如下:

同样地,在CNN中,我们这一系列操作视为一个操作,那么就得到Relu Layer,如下:

Deep Learning
最后,我们将上面所提到的卷积,池化,激活放在一起,就是下面这个样子:

然后,我们加大网络的深度,增加更多的层,就得到深度神经网络了:

全连接层(Fully connected layers)
在激活层后,计算的每个值都将去投票:

然后,我们就可以统计,x与O分别获得的票数了

特征值给X或O投票

根据结果判定为"X":
在这个过程中,我们定义这一系列操作为”全连接层“(Fully connected layers):(1)在这个过程中,所有特征值组成一个投票队列

全连接层也能够有很多个,如下:

综合上述所有结构,我们就有了一个投票体系。这一整个过程,从前到后,被称作“向前传播”。

得到一组输出,然后通过反向传播来不断纠正错误,进行学习。
以上为卷积神经网络的基本算法思想。















 2327
2327











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









