



 本文探讨了vb6中实现union数据结构,并深入解析了Redis底层数据结构SDS的特点,包括常量时间获取长度、防止缓冲区溢出、减少内存再分配、二进制安全性以及链表结构的优化特性,如双端、无环和带长度计数器的设计。
本文探讨了vb6中实现union数据结构,并深入解析了Redis底层数据结构SDS的特点,包括常量时间获取长度、防止缓冲区溢出、减少内存再分配、二进制安全性以及链表结构的优化特性,如双端、无环和带长度计数器的设计。
Redis本身是一个基于C语言开发的内存数据库,它包含String、Set、List、Hash、Set、ZSet等数据类型。那么它底层的数据结构是什么样的呢?简单而言,redis的数据结构包含简单动态字符串、链表、字典、跳跃表、整数集合、压缩列表等。简单动态字符串Redis没有直接用C语言的字符串,而是自己构建了一种名为【简单动态字符串】(Simple Dynamic String, SDS)的抽象类型,并将SDS作为Redis的默认字符串类型表示。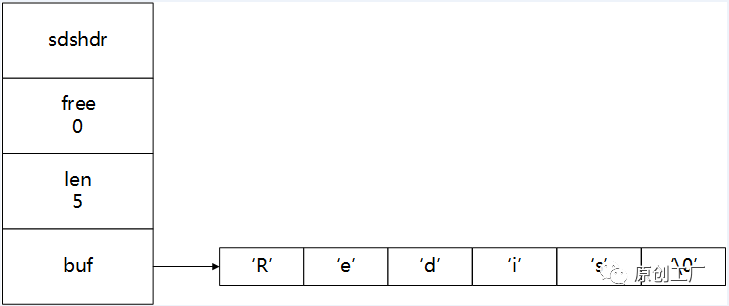 这样做的好处是:
这样做的好处是: 链表Redis构建了链表的实现。
链表Redis构建了链表的实现。
struct sdshdr{ //记录buf数组中已使用字节的数量 //等于 SDS 保存字符串的长度 int len; //记录 buf 数组中未使用字节的数量 int free; //字节数组,用于保存字符串 char buf[];}- 常量复杂度获取字符串长度,直接读取len属性,而不需要通过遍历计数
- 杜绝缓冲区溢出。C语言在strcat函数进行拼接时,如果没有分配足够长度的内存空间,就会造成缓冲区溢出。而对于SDS数据类型,在进行字符修改时,会首先根据len属性检查内存空间是否满足需求,如果不满足,会进行空间扩展。
- 减少修改字符串的内存重新分配次数。C语言不记录字符串的长度,如果要修改字符串,必须要重新分配内存。SDS通过len和free属性的存在,对于修改字符串SDS实现了空间预分配和惰性空间释放2种策略:
- 二进制安全。SDS的API都是以二进制的方式来处理buf中的元素,并且SDS不是以空字符串来判断是否结束,而是以len属性表示的长度来判断字符串是否结束。
- 兼容部分C字符串函数。
链表Redis构建了链表的实现。typedef struct listNode{ //前置节点 struct listNode *prev; //后置节点 struct listNode *next; //节点的值 void *value; }listNodetypedef struct list{ //表头节点 listNode *head; //表尾节点 listNode *tail; //链表所包含的节点数量 unsigned long len; //节点值复制函数 void (*free) (void *ptr); //节点值释放函数 void (*free) (void *ptr); //节点值对比函数 int (*match) (void *ptr,void *key);}list;- 双端:具有前置节点和后置节点的引用
- 无环:表头节点的prev指针和表尾的next指针都指向NULL,对链表的访问都是以NULL结束
- 带链表长度计数器:通过len属性获取链表长度
- 多态:链表节点使用void * 指针来保存节点值,可以保存不同类型的值
typedef struct dictht{ //哈希表数组 dictEntry **table; //哈希表大小 unsigned long size; //哈希表大小掩码,用于计算索引值 //总是等于 size-1 unsigned long sizemask; //该哈希表已有节点的数量 unsigned long used;}dicthttypedef struct dictEntry{ //键 void *key; //值 union{ void *val; uint64_tu64; int64_ts64; }v; //指向下一个哈希表节点,形成链表 struct dictEntry *next;}dictEntrytypedef struct zskiplistNode { //层 struct zskiplistLevel{ //前进指针 struct zskiplistNode *forward; //跨度 unsigned int span; }level[]; //后退指针 struct zskiplistNode *backward; //分值 double score; //成员对象 robj *obj;} zskiplistNodetypedef struct zskiplist{ //表头节点和表尾节点 structz skiplistNode *header, *tail; //表中节点的数量 unsigned long length; //表中层数最大的节点的层数 int level;}zskiplist;
















 3243
3243

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









